DeepSeek-R1、Qwen2.5为什么要引入YARN?
PI 的旋转角度计算公式可以重写为:YARN 的原论文中从更加理论的角度分析了 PI 的这一问题。
目前的较为流行的支持长序列的模型比如 Qwen2.5、DeepSeek-R1 等模型都在训练中引入了 YARN 来做上下文扩展。
本文主要就是按照原论文的结构对 YARN 进行介绍,穿插一些我个人的理解,希望本文能够帮助读者更好的理解旋转位置编码以及 YARN 的原理。
YARN 的全称是 Yet Another RoPE Extention,顾名思义,YARN 是对 RoPE 的一种扩展,应用 YARN 后只需在少量的长文本数据上微调即可实现模型上下文长度的扩展。
了解 YARN 的前提是首先得了解 RoPE 是怎么做到将位置信息注入 LLM 中的。
01
RoPE
1.RoPE 简介

应用 RoPE 后得到的新向量为:
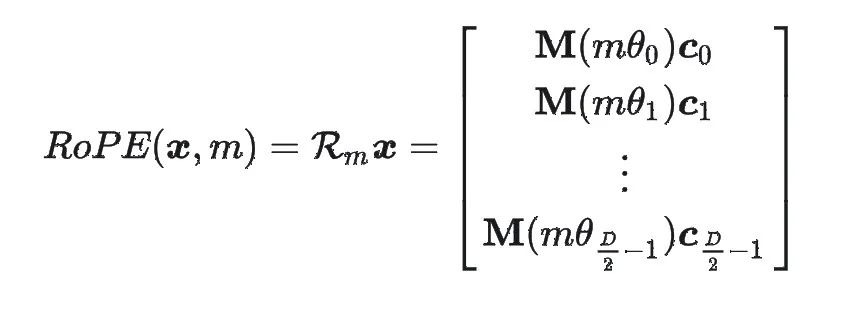

2.RoPE 的优点
绝对位置:RoPE 本身的形式向输入向量添加了绝对位置信息。
相对位置:应用 RoPE 后的向量在进行内积运算时相当于考虑了输入向量的相对位置信息。
考虑位置 m 处的向量 q 与位置 n 处的向量 k,二者应用 RoPE 后的内积为:
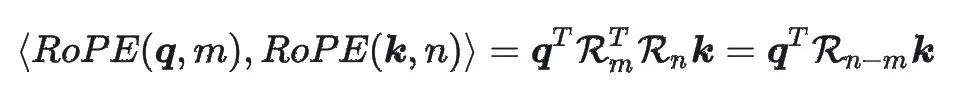
远程衰减:给定向量维度 D,特定 b 的取值能够使得应用 RoPE 后的向量内积具有远程衰减性质,即:对于两个固定的向量,他们之间的相对距离越远,内积值越小。
形式简单,与当前 attention 机制的结合非常自然。
3.RoPE 的参数化
RoPE 的核心其实就是根据位置 m 与分组 d 来确定旋转角度,可以把 RoPE 的旋转角度抽象成以下的函数。
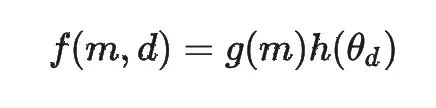

RoPE 中的隐含的高低频分量的概念

02
上下文长度拓展
上面我们简单的介绍了一下 RoPE,下面让我们来考虑使用 RoPE 训练完的模型如何进行上下文长度拓展。本节中,我们将介绍对 RoPE 的一些改进方案,并逐步过度到 YARN。

1.内插与外推
我们考虑一下一维的情况。假设原先我们的模型支持四个位置,分别用 [0,4) 区间中的 0、1、2、3 来表示,现在我们希望模型能够支持 8 个不同的位置,我们应该怎么办呢?
有两种直观的方法可以做到这一点:
-
保持相邻点的间隔为 1 不变,将取值范围从 [0,4) 直接将取值范围扩展至 [0,8) 即可,这就是所谓的外推(extrapolation)。
-
维持原先的区间不变,从原区间取更多的点来表示新的位置,此时我们的取值范围维持 [0,4),但相邻点之间的间隔从 1 缩小到了 0.5,这就是所谓的内插(interpolation)
参考下图(括号内数字为位置,括号外数字为表示该位置的实际数值):
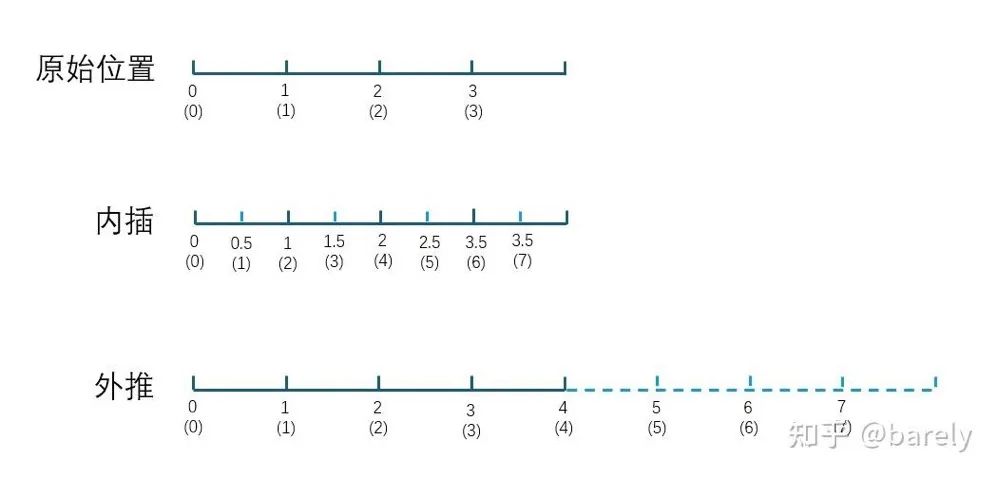
内插 vs 外推
考虑完 1 维的简单情形,下面让我们由易到难看看几种不同的对 RoPE 进行改动以进行上下文长度拓展方法,每种方法都是对前一种方案的改进,最终我们将会得到 YARN。
2.Position Interpolation(PI)
方法介绍如下:

存在的问题:PI 的思想非常直观,就是位置编号上的完全内插,实现起来非常简单。但 PI 存在一定的问题。
PI 的旋转角度计算公式可以重写为:

YARN 的原论文中从更加理论的角度分析了 PI 的这一问题。
Deep neural networks have trouble learning high frequency information if the input dimension is low and the corresponding embeddings lack high frequency components.
Stretching the RoPE embeddings indiscriminately results in the loss of important high frequency details which the network needs in order to resolve tokens that are both very similar and very close together

简而言之,PI 存在的问题是:根据 NTK 理论,输入特征中高频分量的分布对模型十分重要,而 PI 的做法导致输入中的高频分量的分布发生了较大的变化,对模型的性能有损害。
3.NTK-aware Interpolation
针对上述对于 PI 的缺陷分析,研究人员提出了 NTK-aware Interpolation。
方法介绍:既然 NTK 理论告诉我们,模型对高频分量的分布敏感,那么我们应该尽量保持高频分量的分布不变,而在低频分量的部分做插值,也就是****高频外推,低频内插。

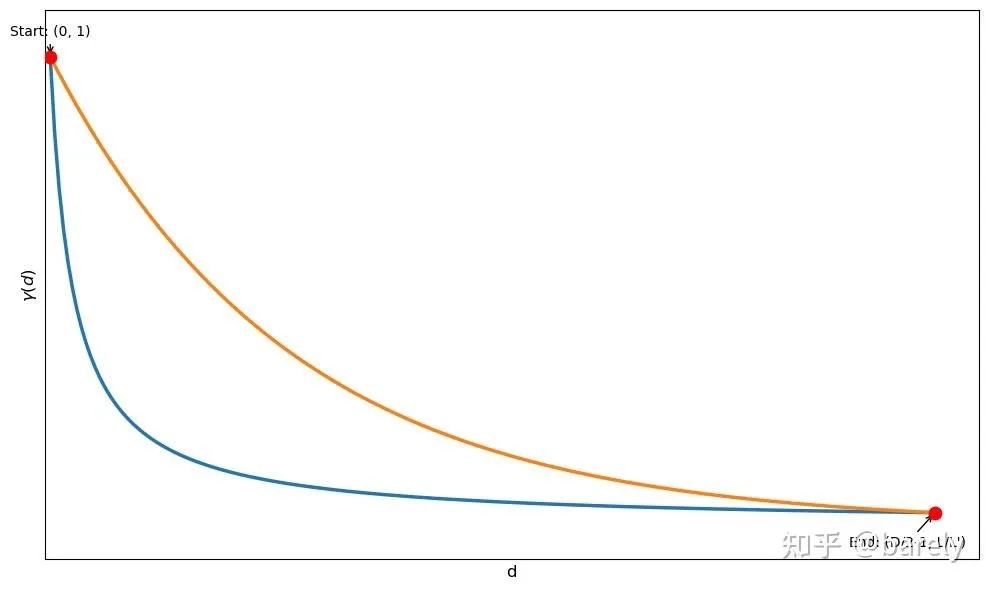
多种曲线均符合“高频外推,低频内插的原则”

存在的问题:NTK-aware 看上去很优美,考虑到了频率与内外插程度应当是相关联的,并用一个拟合出的指数函数来将分组 d(也就是频率)与内外插的程度联系起来,但这样的建模足够精细吗?答案是否定的。

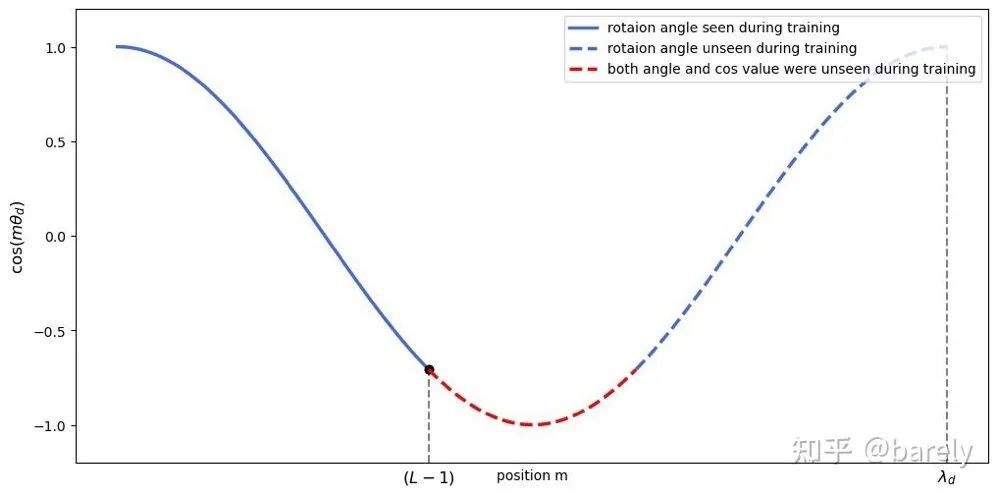
对于足够低频的分量,外推会引入分布外的旋转矩阵
让我们从数学上推导一下哪些分量出现了过度的外推,不感兴趣的可以直接跳过,看下一节:
哪些分量出现了外推?
所谓外推就是值域出现了扩大,即,最大旋转角度在扩展后超过了原先的最大旋转角度,即:
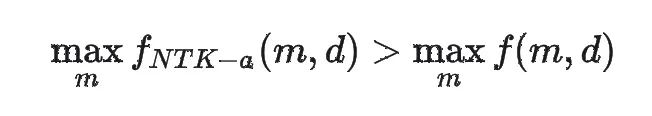
代入具体的函数形式,我们可以得到:
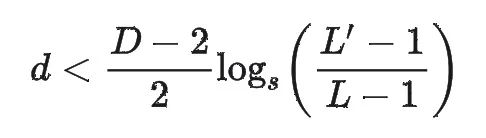
哪些分量不应该外推?
如前所述,对于波长大于原最大序列长度的那些低频分量,我们不应该对他们进行外推,即:
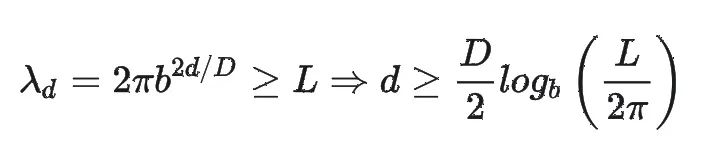

4.NTK-by-parts Interpolation
在上一节中我们分析了 NTK-aware 插值方法存在的问题,在某些极端低频的分量上进行了过度的外推,导致模型性能下降。
同理,我们可以考虑在哪些分量我们或许可以做完全的外推。根据 NTK 理论,模型对高频分量的分布敏感,因此对足够高频的分量应该尽量保持其频率不变,需要完全的外推。
NTK-by-parts 就是基于这样的思想提出的,对于足够低频的分量做完全的内插,对足够高频的分量做完全的外推,而对中间部分的分量,既外推也内插。

在实际应用时,α 与 β 的取值是一个与预训练模型有关的超参,需要实验确定。
5.YARN
终于,在讲了 3 种层层递进的对 RoPE 进行长度拓展的方法后来到了我们的终极方法 YARN。
如果前面几种方法你基本都理解了,那么看到这里的你可以松一口气了。因为 YARN 的本体就是 NTK-by-parts,只是 YARN 在 NTK-by-parts 的基础上额外增加了一个 attention-scaling 的机制。
用原文作者给出的直观表示:YARN = NTK-by-parts + attention-scaling
所谓的 attention-scaling 就是在计算 attention 的环节,YARN 会额外对 attention score(也就是 query 和 key 向量的内积)除以一个常数 t。
形式上,了解对比学习或者 LLM 生成过程的同学应该挺熟悉的,这相当于对 attention 的计算过程加了个温度系数。

03
Coding环节
Talk is cheap, show me the code.
讲了这么多理论,还是得动手实践一下来检验自己的理解。目前使用 YARN 的知名度最高的开源模型当属 DeepSeek-R1 了,你能完成以下的编程练习来实现一个 YARN 使得你的实现与 DeepSeek-R1 的结果一致吗?
有以下两点需要注意:
-
DeepSeek-R1 中 YARN 的实现在中间频率分量部分的插值处理与 YARN 的原文不大一样,需要你读一下 DeepSeek-R1 的源码
-
YARN 的计算并不涉及到模型权重,因此你并不需要 clone 完整的权重,只需用以下命名 clone 不带权重的部分即可
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-R1
下面是题目,你需要补全 DeepseekV3YarnRotaryEmbeddingReproduce 类中关于 cos 与 sin cache 的计算逻辑。
import math``import torch``import torch.nn as nn``from transformers import AutoModelForCausalLM, AutoConfig``class DeepseekV3YarnRotaryEmbeddingReproduce(nn.Module):` `def __init__(self, config):` `# Parameter names are consistent with the formula in this post. Change them if you want.` `# RoPE params` `self.b = config.rope_theta` `self.L = config.rope_scaling["original_max_position_embeddings"]` `self.D = config.hidden_size` `# YARN Params` `self.s = config.rope_scaling["factor"]` `self.L_sharp = self.L * self.s` `self.alpha = config.rope_scaling["beta_slow"]` `self.beta = config.rope_scaling["beta_fast"]` `# Cos & Sin Cache calculation` `cos_cached = torch.zeros([self.L_sharp, self.D // 2], dtype=torch.float32)` `sin_cached = torch.zeros([self.L_sharp, self.D // 2], dtype=torch.float32)` `# TODO: add your codes here` `self.register_buffer("cos_cached", cos_cache)` `self.register_buffer("sin_cached", sin_cache)` `def forward(self, x=None, seq_len=None):` `cos = self.cos_cache[:seq_len]` `sin = self.sin_cache[:seq_len]` `return cos, sin``if __name__ == "__main__":` `config = AutoConfig.from_pretrained(` `"YOUR_DeepSeek_R1_path", # 替换成本地的DeepSeek-R1代码路径` `trust_remote_code=True,` `first_k_dense_replace=1,` `num_hidden_layers=1` `)` `ds_v3_yarn = AutoModelForCausalLM.from_config(` `config,` `trust_remote_code=True` `).model.layers[0].self_attn.rotary_emb` `yarn_rep = DeepseekV3YarnRotaryEmbeddingReproduce(config)` `cos_ref, sin_ref = ds_v3_yarn.cos_cached, ds_v3_yarn.sin_cached` `cos_rep, sin_rep = yarn_rep.cos_cached, yarn_rep.sin_cached` `assert torch.allclose(cos_ref, cos_rep, atol=1e-6), f"Cosine not equal."` `assert torch.allclose(sin_ref, sin_rep, atol=1e-6), f"Sine not equal."` `print("Congratulations!")
来源:https://zhuanlan.zhihu.com/p/25241219397
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)