DeepSeek技术系列之解析DeepSeek MOE
当全球AI竞赛陷入"万亿参数内卷"时,DeepSeek用仅557万美元训练成本打造出性能比肩GPT-4的模型。这背后隐藏着一个颠覆性事实:参数利用率比参数规模更重要。DeepSeek MoE通过架构层面的三重革新,将每个参数的价值挖掘效率提升300%,正在改写大模型的效率法则。
——从参数堆砌到组织艺术的范式跃迁
当全球AI竞赛陷入"万亿参数内卷"时,DeepSeek用仅557万美元训练成本打造出性能比肩GPT-4的模型。这背后隐藏着一个颠覆性事实:参数利用率比参数规模更重要。DeepSeek MoE通过架构层面的三重革新,将每个参数的价值挖掘效率提升300%,正在改写大模型的效率法则。
一、什么是DeepSeek MOE?
DeepSeekMoE是一种创新的大规模语言模型架构,通过整合专家混合系统(Mixture of Experts, MoE)、改进的注意力机制和优化的归一化策略,在模型效率与计算能力之间实现了新的平衡。
传统大模型的困局
想象一位必须精通所有学科的超级教授:他既要懂量子物理,又要会写十四行诗,还要能调试Python代码。这就是传统稠密模型(Dense Model)的困境——每个参数都参与所有任务,导致90%的计算资源被浪费
MoE的破局逻辑
DeepSeek采用的混合专家模型(Mixture of Experts)如同组建专科医院
-
专家网络
犹如一家医院的256个"专科医生",分别擅长心脏内科、内分泌内科、呼吸内科、神经内科等细分领域
-
路由机制
犹如医院的智能"分诊台",将"患者"(输入数据)分配给最合适的2-4位专家
-
组合策略
综合专家意见形成最终诊断(输出)
二、DeepSeek MoE的架构设计哲学
传统MOE架构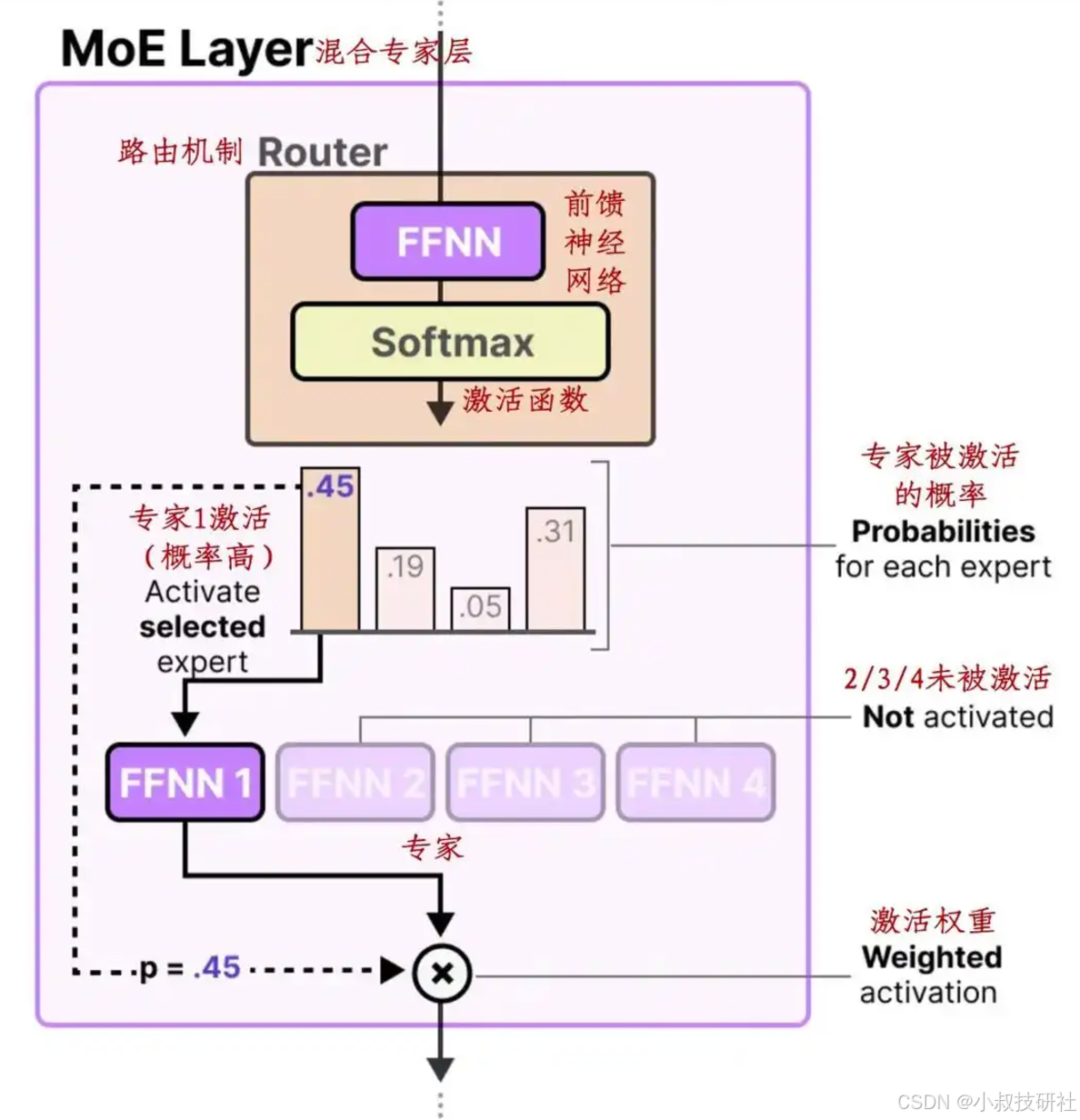
传统MoE架构下每个路由专家(DeepSeek-V3 MoE架构图中蓝色部分)学习知识,通常导致模型在处理陌生任务时表现不佳,面临知识交叉和知识冗余等问题。
DeepSeek MOE架构
与传统MoE架构不同,DeepSeekMoE采用细粒度专家划分,对专家网络进行差异化设计,允许不同参数规模或架构,并将部分专家划分为共享专家,共享专家数量较少且相对固定,其始终处于被激活状态,可以被多个任务共同使用,负责整合不同数据源的共同知识。
-
细粒度专家划分
传统MoE的专家如同综合科室,每个要处理多种任务。DeepSeek的创新在于:这相当于把"内科"细分为心血管、呼吸、消化等亚专科,让专业度实现指数级提升
-
将每个专家拆分为16个微专家,隐层维度压缩至1/16
-
通过动态组合形成"虚拟专家委员会",如「古诗韵律+宋词格律」组合处理诗词创作
-
在代码生成任务中,该设计使准确率提升17%
-
-
双通道知识处理
DeepSeek创造性地将专家分为两类:

这种架构实现了:
知识分层处理:共享专家构建基础认知框架(类似人脑基底核),路由专家专注高阶技能(类似新皮层)
计算资源优化:共享专家无需路由计算,使推理延迟降低23%
-
动态负载均衡:智能流量调度系统
在MoE架构的训练过程中,由于路由策略的影响,不同专家接收到的训练数据分布往往不均衡,导致负载不平衡问题加剧,形成计算瓶颈。与传统引入辅助损失的解决方法不同,DeepSeek-V3采用无辅助损失负载均衡(Auxiliary-Loss-Free Load Balancing),通过动态调整专家间的负载分配,确保训练过程中各专家的负载均衡。此外,为防止单个序列出现极端负载不平衡的情况,DeepSeek-V3还采用序列级辅助补充损失策略(Complementary Sequence-Wise Auxiliary Loss),促使每个序列上的专家负载实现均衡。
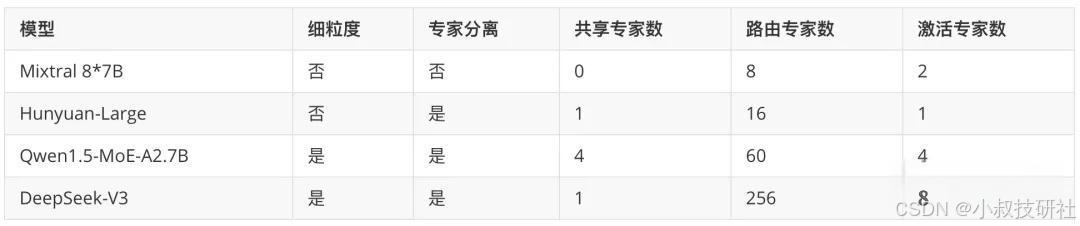
下表是部分开源 MoE 模型的对比情况:
三、工程实践:突破训练与推理的隐形天花板
-
混合精度训练范式
-
FP8+DualPipe双流水线:关键路径保留FP16精度,非关键路径采用FP8压缩,配合双流水线异步执行,训练吞吐量提升2.1倍
-
梯度补偿技术:针对低精度计算引入残差补偿模块,使FP8训练收敛稳定性提升40%
-
-
MLA注意力机制革新
-
KV缓存压缩:通过低秩联合压缩技术,将16k上下文长度的KV缓存从48GB压缩至2.3GB
-
查询矩阵优化:对Q矩阵进行隐空间投影,使注意力计算FLOPs减少57%
-
-
多令牌预测(MTP)架构
-
前瞻式解码:同时预测后续3个token,通过路径剪枝算法避免错误累积
-
训练加速:数据利用率提升1.8倍,在代码生成任务中实现单卡每秒37token的推理速度
-
四、性能实测:重新定义效率基准
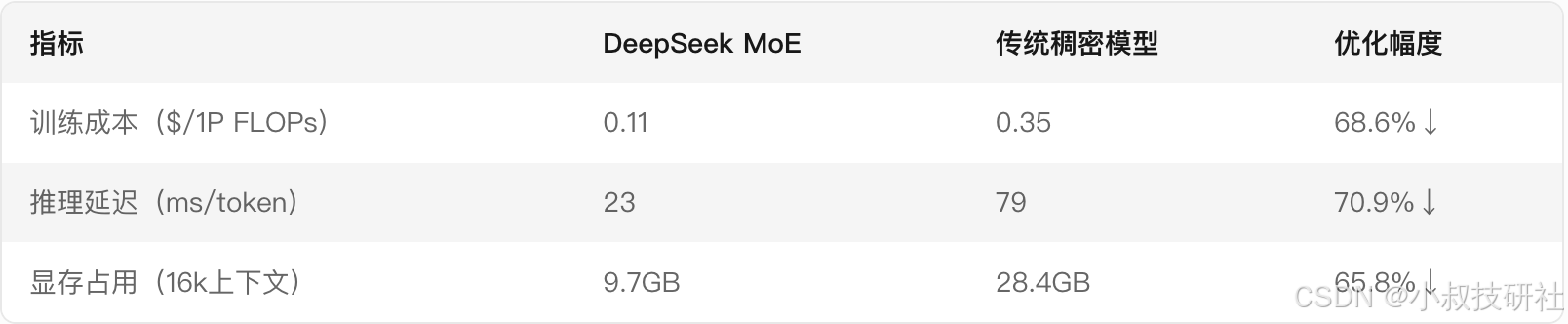
成本效益对比:
五、MOE范式的新启示
DeepSeek MOE的成功验证了三个核心洞见:
-
稀疏性价值
智能的涌现不仅依赖参数规模,更取决于参数的动态组织效率
-
硬件-算法共生
下一代AI架构必须从计算范式层面重构,而非简单适配现有硬件
-
生态位理论:
专家网络的进化方向应遵循"适者激活"原则,模仿生物系统的分工机制
文末总结:
DeepSeek MOE的技术实践,本质上是在探索人工智能的“计算进化论”——当模型架构能够像生物系统那样,通过动态分工和自适应重组来应对环境变化时,我们或许正在见证一个新时代的来临:从暴力计算走向智能计算。这场由稀疏化引发的范式革命,正在重新定义AI模型的scaling law,也为通向AGI开辟了一条更符合物理定律的实现路径。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)