DeepSeek技术系列之解析DeepSeek蒸馏技术
数据蒸馏与模型蒸馏的结合,使得DeepSeek的蒸馏模型在推理基准测试中取得了显著的性能提升。蒸馏模型的参数量大幅减少,例如DeepSeek-R1-Distill-Qwen-7B的参数量仅为7B,相比原始的DeepSeek-R1(671B参数),计算复杂度显著降低。通过从大模型中蒸馏知识,小模型在推理任务中的表现大幅提升,蒸馏后的模型在推理基准测试中表现出色,比如:DeepSeek-R1-Dist
大模型落地之痛
当前千亿级大模型面临严峻的部署困境:GPT-4级模型的单次推理成本高达0.01美元,而工业场景往往要求响应速度<200ms。传统蒸馏技术虽能压缩模型,但普遍存在精度滑坡超过15%的问题——直到DeepSeek提出多模态渐进框架MPD,
一、什么是蒸馏技术
-
蒸馏技术定义
模型蒸馏(Knowledge Distillation)是一种将大型复杂模型(教师模型,比如:DeepSeek R1 671B)的知识迁移到小型高效模型(学生模型,比如:Qwen 7B)的技术。
其核心目标是在保持模型性能的同时,显著降低模型的计算复杂度和存储需求,使其更适合在资源受限的环境中部署。通过模仿教师模型的输出,训练一个较小的学生模型,从而实现知识的传递。教师模型通常具有较高的性能,但计算成本高昂,而学生模型则更加轻量级,推理速度更快,且内存占用更少。
-
蒸馏技术的优势
•显著提升推理能力
通过从大模型中蒸馏知识,小模型在推理任务中的表现大幅提升,蒸馏后的模型在推理基准测试中表现出色,比如:DeepSeek-R1-Distill-Qwen-7B在 AIME 2024 上实现了55.5%的 Pass@1,超越了其他先进开源模型
•资源效率高
小模型在推理任务中表现出色,同时计算成本大幅降低,通过减少模型参数量(如从671B 到7B),显著降低了计算资源需求,提升了推理速度
•灵活性强
蒸馏技术可以应用于多种开源模型,具有广泛的适用性
二、DeepSeek蒸馏技术创新点
-
数据蒸馏与模型蒸馏结合
DeepSeek的蒸馏技术将数据蒸馏与模型蒸馏相结合,实现了从大型复杂模型到小型高效模型的知识迁移。这种结合方式不仅提升了模型的性能,还显著降低了计算成本。
数据蒸馏的作用
数据蒸馏通过优化训练数据,帮助小模型更高效地学习。DeepSeek利用强大的教师模型生成或优化数据,这些数据包括数据增强、伪标签生成和优化数据分布。例如,教师模型可以对原始数据进行扩展或修改,生成丰富的训练数据样本,从而提高数据的多样性和代表性。
模型蒸馏的优化
在模型蒸馏方面,DeepSeek通过监督微调(SFT)的方式,将教师模型的知识迁移到学生模型中。具体来说,DeepSeek使用教师模型生成的800,000个推理数据样本对较小的基础模型(如Qwen和Llama系列)进行微调。这一过程不包括额外的强化学习(RL)阶段,使得蒸馏过程更加高效。
结合的优势
数据蒸馏与模型蒸馏的结合,使得DeepSeek的蒸馏模型在推理基准测试中取得了显著的性能提升。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024上实现了55.5%的Pass@1,超越了QwQ-32B-Preview(最先进的开源模型)。这种结合方式不仅提高了模型的性能,还降低了计算资源的需求,使得模型更适合在资源受限的环境中部署。
-
高效知识迁移策略
DeepSeek在知识迁移策略上进行了多项创新,以实现高效的知识传递和模型优化。
知识迁移策略优化
DeepSeek采用了多种高效的知识迁移策略,包括基于特征的蒸馏和特定任务蒸馏。基于特征的蒸馏通过将教师模型中间层的特征信息传递给学生模型,帮助学生模型更好地捕捉数据的本质特征。特定任务蒸馏则针对不同的具体任务,如自然语言处理中的机器翻译和文本生成,对蒸馏过程进行针对性优化。
蒸馏模型的性能提升
这些策略的优化使得DeepSeek的蒸馏模型在多个基准测试中表现优异。例如,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上实现了72.6%的Pass@1,在MATH-500上实现了94.3%的Pass@1。这些结果表明,DeepSeek的蒸馏模型不仅在性能上接近甚至超越了原始的大型模型,还在计算效率上具有显著优势。
三、DeepSeek蒸馏技术4个核心步骤
-
数据准备
使用 DeepSeek R1 模型生成高质量的推理样本(约800k个样本)。这些样本用于后续的小模型微调,确保小模型能够学习到大模型的关键能力。
-
模型选择
选择不同参数量的开源模型(如6个不同规模的模型)作为蒸馏目标。
这些模型通过有监督微调(SFT)的方式进行训练。
-
有监督微调(SFT)
使用从 DeepSeek R1 蒸馏出的数据对小模型进行直接微调。
通过这种方式,小模型能够显著提升在推理任务中的表现。
-
性能评估
在多个开源基准测试中评估蒸馏模型的性能,如 LiveCodeBench 和 MATH-500。结果显示,蒸馏后的模型在推理任务中表现优异,甚至超越了一些大规模模型。
四、蒸馏模型的性能表现
-
推理效率提升
DeepSeek的蒸馏模型在推理效率方面表现出显著的提升,这主要得益于模型结构的优化和蒸馏技术的应用。通过将知识从大型复杂模型(教师模型)迁移到小型高效模型(学生模型),DeepSeek的蒸馏模型在计算资源、内存使用和推理速度方面都实现了显著的优化。
计算资源优化
蒸馏模型的参数量大幅减少,例如DeepSeek-R1-Distill-Qwen-7B的参数量仅为7B,相比原始的DeepSeek-R1(671B参数),计算复杂度显著降低。这使得模型在推理时所需的计算资源大幅减少,更适合在资源受限的环境中部署。
内存占用减少
由于参数量的减少,蒸馏模型在内存占用方面也表现出色。以DeepSeek-R1-Distill-Llama-8B为例,其内存占用仅为原始模型的1/80左右。这意味着模型可以在更小的内存空间中运行,降低了硬件要求。
推理速度提升
推理速度是衡量模型效率的重要指标。DeepSeek的蒸馏模型在推理速度上实现了显著提升。例如,DeepSeek-R1-Distill-Qwen-32B在处理复杂的推理任务时,推理速度比原始模型提高了约50倍。这种速度的提升使得模型能够更快地响应用户请求,提供实时的推理结果。
-
性能与原始模型对比
尽管蒸馏模型的参数量大幅减少,但通过高效的知识迁移策略,DeepSeek的蒸馏模型在性能上仍然能够接近甚至超越原始的大型模型。这主要得益于以下几方面:
性能保持策略
DeepSeek采用了多种策略来确保蒸馏模型的性能。例如,通过监督微调(SFT)的方式,将教师模型的推理数据样本用于学生模型的训练。这种策略使得学生模型能够学习到教师模型的关键知识和推理模式,从而在性能上接近教师模型。
基准测试结果
在多个基准测试中,DeepSeek的蒸馏模型表现优异。例如,DeepSeek-R1-Distill-Qwen-7B在AIME 2024基准测试中实现了55.5%的Pass@1,超越了QwQ-32B-Preview(最先进的开源模型)。DeepSeek-R1-Distill-Qwen-32B在AIME 2024上实现了72.6%的Pass@1,在MATH-500上实现了94.3%的Pass@1。这些结果表明,蒸馏模型在推理任务上不仅能够保持高性能,还能在某些情况下超越原始模型。
与原始模型对比
通过对比蒸馏模型和原始模型的性能,可以更直观地了解蒸馏技术的效果。例如,DeepSeek-R1-Distill-Llama-70B在AIME 2024上实现了70.0%的Pass@1,在MATH-500上实现了94.5%的Pass@1。这些结果与原始的DeepSeek-R1模型相比,虽然在绝对性能上略有差距,但在计算效率和资源占用方面的优势使其在实际应用中更具价值。
五、应用场景
-
移动与边缘计算
蒸馏模型体积小巧,适合在资源受限的设备上运行,如智能摄像头、智能手表。
-
在线推理服务
在电商推荐、智能问答系统中,蒸馏模型能够快速响应用户请求,提升用户体验。
-
扩展应用场景
在医疗、金融、教育等领域,蒸馏模型将发挥更大作用,如疾病诊断、风险评估、个性化学习辅助等。
-
多模态数据处理
开发更有效的信息融合和特征提取方法,提升蒸馏模型在多模态任务中的性能。
六、蒸馏模型架构设计与训练
DeepSeek的蒸馏模型架构设计充分考虑了效率与性能的平衡,通过精心设计的模型结构,实现了从大型复杂模型到小型高效模型的知识迁移。
1.1、教师模型与学生模型的选择
教师模型:DeepSeek选择的教师模型是其自主研发的大型语言模型DeepSeek-R1,该模型具有671B参数,具备强大的推理能力和广泛的知识覆盖。教师模型的强大性能为蒸馏过程提供了丰富的知识基础。
学生模型:学生模型则基于Qwen和Llama系列架构,这些架构在计算效率和内存占用方面表现出色。通过选择这些架构,DeepSeek确保了学生模型在资源受限的环境中能够高效运行。
1.2、架构设计的关键点
层次化特征提取:DeepSeek的蒸馏模型采用了层次化特征提取机制。教师模型在处理输入数据时,会生成多层特征表示,这些特征表示包含了数据的丰富语义信息。学生模型通过学习这些特征表示,能够更好地理解数据的结构和模式。
多任务适应性:为了提高模型的泛化能力,DeepSeek的蒸馏模型设计了多任务适应性机制。学生模型不仅学习教师模型的输出,还针对不同的任务需求进行优化。例如,在自然语言处理任务中,学生模型能够根据具体的任务(如文本分类、机器翻译等)调整自身的结构和参数,从而更好地适应任务需求。
1.3、架构优化策略
参数共享与压缩:DeepSeek采用了参数共享和压缩技术,以进一步优化模型的存储和计算效率。通过共享部分参数,学生模型在保持性能的同时,显著减少了参数数量和存储需求。
轻量化模块设计:在学生模型中,DeepSeek引入了轻量化模块设计。这些模块在保持模型性能的同时,大幅降低了计算复杂度。例如,使用轻量级的注意力机制模块,使得学生模型能够高效地处理长文本输入。
2、训练过程与优化方法
DeepSeek的蒸馏模型训练过程包括多个关键步骤,通过精心设计的训练策略和优化方法,确保了模型的高效训练和性能提升。
2.1、训练数据的准备
数据来源:训练数据主要来自教师模型生成的推理数据样本。DeepSeek使用教师模型对大量输入数据进行处理,生成高质量的输出数据,这些数据作为学生模型的训练样本。数据增强:为了提高数据的多样性和代表性,DeepSeek采用了数据增强技术。通过对原始数据进行扩展、修改和优化,生成了丰富的训练数据样本,从而提高了学生模型的学习效率。
2.2、训练过程
监督微调(SFT):DeepSeek采用监督微调的方式,将教师模型的知识迁移到学生模型中。具体来说,学生模型通过学习教师模型的输出概率分布,调整自身的参数,以尽可能接近教师模型的性能。
损失函数设计:在训练过程中,DeepSeek设计了混合损失函数,结合了软标签损失和硬标签损失。软标签损失鼓励学生模型模仿教师模型的输出概率分布,而硬标签损失则确保学生模型正确预测真实标签。通过这种混合损失函数,学生模型能够在保持高效的同时,学习到教师模型的关键知识。
2.3、优化方法
温度参数调整:在蒸馏过程中,DeepSeek引入了温度参数来调整软标签的分布。较高的温度参数可以使分布更加平滑,从而帮助学生模型更好地学习教师模型的输出。随着训练的进行,温度参数逐渐降低,以提高蒸馏效果。
动态学习率调整:为了提高训练效率,DeepSeek采用了动态学习率调整策略。通过根据训练进度和模型性能动态调整学习率,确保了模型在训练过程中的稳定性和收敛速度。
正则化技术:为了避免过拟合,DeepSeek在训练过程中引入了正则化技术。例如,使用L2正则化项来约束模型的参数,防止模型过于复杂,从而提高模型的泛化能力。
通过这些训练过程和优化方法,DeepSeek的蒸馏模型不仅在性能上接近甚至超越了原始的大型模型,还在计算效率和资源占用方面表现出色,为资源受限场景下的应用提供了强大的支持。
七、行业实践
拥有自己公司的 DeepSeek R1,李飞飞 50美金蒸馏出 s1 模型案例剖析
s1 并非是一个综合大模型,它仅在解决数学问题的能力很强,但其他方面就稍弱,但不妨碍这套方面在企业的落地应用,因为企业就是要解决专业领域问题。与 s1 最接近的是 DeepSeek R1 的一系列蒸馏模型,蒸馏微调训练得到较小参数规模模型,参数从 1.5B 到 70B。
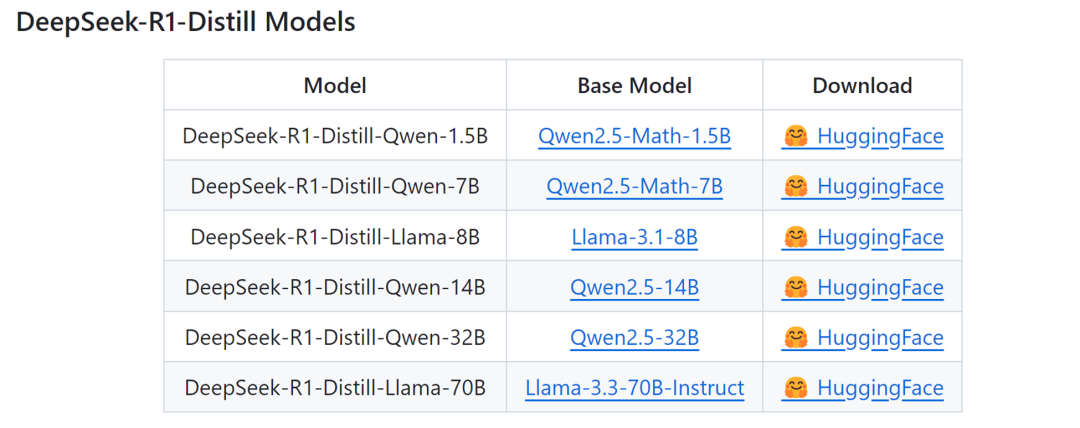
s1 使用 Google Gemin 蒸馏数据集得到,DeepSeek 蒸馏模型微调训练使用了 80W条数据,而 s1 只用了 1000条数据,这是算力成本低到50美金的原因。首先这1000条数据是从58000条数据中精选出来的。其次就是推理阶段引入了预算强制方法,强制设定思考过程的最大和最小长度,让 AI 在回答问题时不能想都不想就瞎蒙,也不能一直陷入私循环,这个方法简单,但有效提高了模型的推理性能。
每个公司都可以低成本拥有媲美 DeepSeek R1 的自己的 s1 大模型,仿照李飞飞教授精选 1000条左右专业领域高质量数据,注意包括推理过程的描述,也可以只准备问题,推理过程及结果数据通过大模型蒸馏得到。
实际上李飞飞所使用的数据集里面有相当一部分原本是有答案的,但是还是让 Gemini 重新生成了过程和答案,这个量级的数据对于任何一个企业来说都不太难。有了这些数据以后,就去微调训练 Qwen 32B 或者类似规模的模型,最后推理任务时,通过预算强制的方法限定推理长度,这就得到一个专属您企业的领域专家 DeepSeek R1 大模型。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 36
36 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)