基于DeepSeek构建个人级与企业级大模型本地知识库
大模型最典型最成熟的应用非知识库莫属了,构建本地大模型知识库的主流技术组件组合通常围绕检索增强生成(RAG)框架展开,涵盖前端交互、向量存储、嵌入模型、推理大模型等核心模块。本文介绍基于大模型构建本地知识库的技术原理,特别是RAG原理,并演示操作个人用的基于轻量版Cherry studio及企业级Dify的知识库构建方案,通过本文档的学习,您可以建设自己个人的或企业级的知识库。
作者:Ken(作者为人工智能产业从业者,欢迎咨询合作)
大模型最典型最成熟的应用非知识库莫属了,构建本地大模型知识库的主流技术组件组合通常围绕检索增强生成(RAG)框架展开,涵盖前端交互、向量存储、嵌入模型、推理大模型等核心模块。本文介绍基于大模型构建本地知识库的技术原理,特别是RAG原理,并演示操作个人用的基于轻量版Cherry studio及企业级Dify的知识库构建方案,通过本文档的学习,您可以建设自己个人的或企业级的知识库。
第一部分 RAG简介
一、开场:上下文窗口的“军备竞赛”
如今,大语言模型领域正上演一场激烈的“军备竞赛”。各大厂商纷纷在上下文窗口长度上“卷”得飞起,不断刷新记录,如上下文长度主要集中在128K和1M两个档次。其中,Qwen 2.5-1M和智谱AI的GLM-4-Long等模型已经达到了1M的上下文长度。在这种背景下,RAG技术的未来也受到了质疑。随着上下文窗口越来越大,有人认为RAG技术可能会逐渐“淘汰”,甚至有人问:现在还需要在RAG技术上投入精力吗?
二、大模型的“双刃剑”:强大与脆弱
要理解RAG技术的重要性,我们首先需要弄清楚大语言模型是怎么训练出来的。大语言模型的训练需要海量的数据,这些数据来自金融、医疗、智能制造、教育等各个行业。通过特定的训练方法,这些模型就像一个“超级大脑”,具备了各种各样的能力。
然而,这个“超级大脑”也有它的弱点。大语言模型就像是一个“知识渊博但容易走神的学生”,虽然学到了很多知识,但有时候会因为各种原因给出不准确的答案。比如,当你问它关于《三体》的问题时,它可能会“一本正经地胡说八道”。这种问题在一些不太严谨的场景中或许无伤大雅,但在需要“靠谱答案”的场景下,比如政务咨询机器人,这种“信口开河”的行为就会带来严重的后果,因为大模型能记住的东西实在是有限,即使是1M,也不算多。
三、RAG技术:给大模型“开外挂”
(一)RAG技术的“使命”
RAG技术就像是大语言模型的“智能外挂”,专门帮助大模型找到最相关的知识,从而提升生成结果的质量。它通过检索增强的方式,帮助模型在有限的上下文窗口中,找到最相关的知识片段,从而生成更精准、更有针对性的答案。
(二)RAG技术的工作原理
RAG技术的工作原理可以简单这么理解,过程如下图所示:
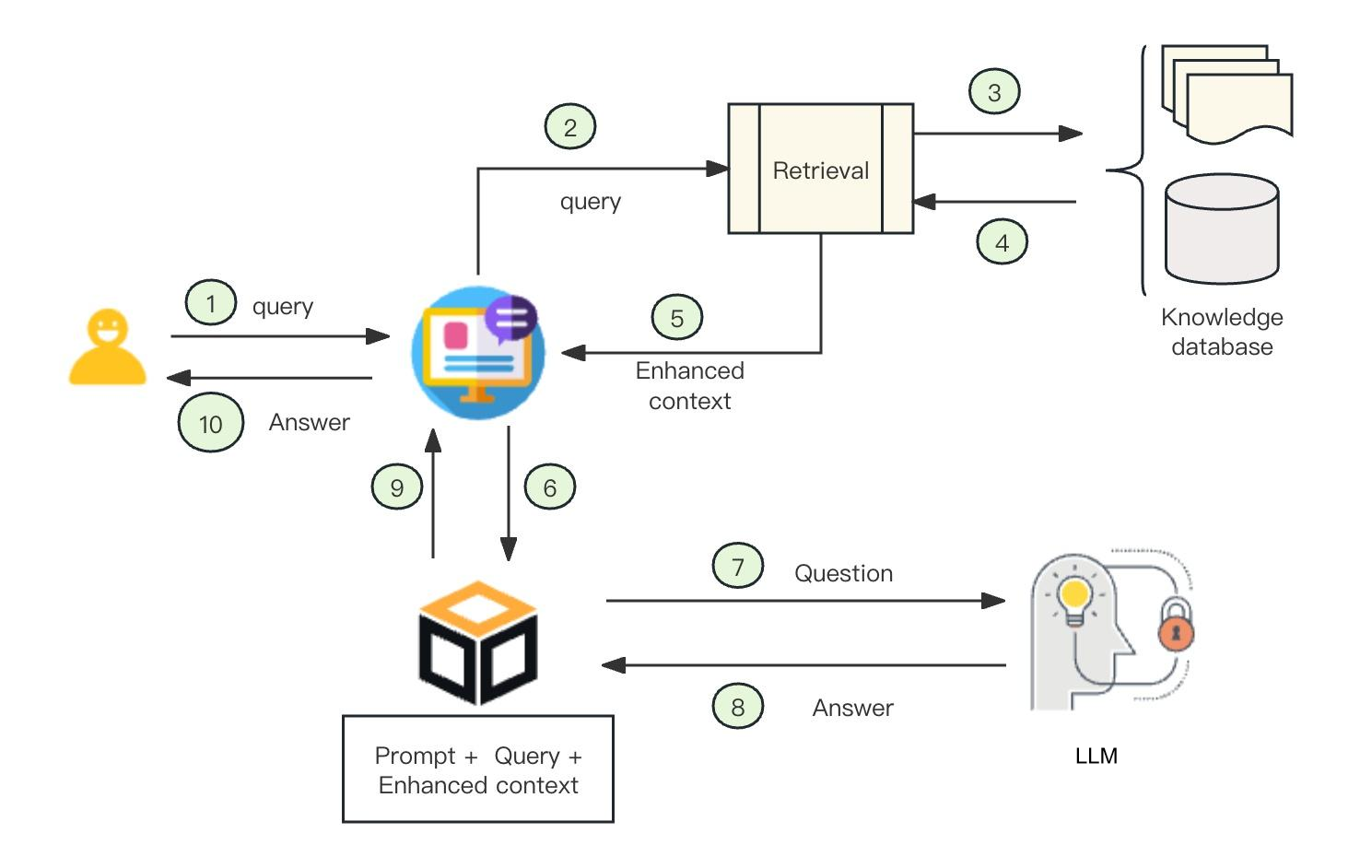
本图片来源于互联网
- 用户向前端应用输入提示词。
- 前端应用生成查询语句。
- 从向量数据库(存了很多私有知识,已经提交向量化)进行检索。
- 返回基于提示词增强的上下文。
- 将增强后的上下文返回给应用。
- 应用将用户的提示词、增强的上下文、查询语句进行合并。
- 将合并后的完整上下文作为提示词提交给大模型LLM。
- 大模型LLM返回答案给应用。
- 应用将答案返回给前端界面。
- 前端界面将答案返回给用户。
其中最重要的步骤是向量检索和提示词增强,以下做进一步介绍:
向量检索(Retreval):将文本“拆解”成一个个小片段,然后对这些片段进行向量化处理,是不是很难处理呀,莫慌,现在有很多词嵌入大模型可以直接将文本切片向量化。在输入端也将问题文本生成一个向量。通过计算问题向量和片段向量之间的相似度,RAG技术可以像“拼图”一样,快速找出与问题最相关的片段。
提示词增强(Prompt+Query+Enchanced context):将问题和检索到的相关片段“打包”,一起作为提示词输入给大语言模型。这样,模型就能在生成答案时,参考这些精准的知识片段,从而避免“胡编乱造”。
(三)RAG技术的“妙用”
RAG技术的出现,就像是给大语言模型安装了一个“过滤器”。它能够有效减少无关信息的干扰,让模型生成的答案更加精准、更有价值。比如,当用户问“天空为什么是蓝色的”时,RAG技术可以快速从海量的科学资料中,找到与光学、气象学相关的片段,而不是把所有科学知识一股脑地塞给模型。
四、RAG与上下文窗口:不是对手,是“队友”
很多人误以为,随着上下文窗口越来越大,RAG技术就会逐渐失去价值。但实际上,RAG技术与上下文窗口之间并不是“对手”,而是“队友”。
(一)“互补”的关系
大模型的上下文窗口为RAG技术提供了基础的处理能力,而RAG技术则通过检索相关知识,弥补了大模型在有限窗口内知识覆盖不足的问题。RAG技术就像是大模型的“外挂”,帮助大模型在有限的上下文窗口中更好地发挥其能力。
(二)为什么不是“对手”
即使大模型的上下文窗口不断增大,RAG技术也不会被完全替代。因为大模型窗口的增大并不能完全解决其对长文本理解不准确的问题,而且在一些特殊业务场景下,如医疗领域,对结果的准确性要求极高,RAG技术通过检索相关知识,能够进一步提高模型输出结果的准确性。
我们可以通过一个案例来理解这一点。假设你有一个问题想问我,但很不幸,我没有给出你想要的答案。我们需要分析为什么没有给出正确的答案,这里可能有三种不同的情况:
第一种情况:你可能没有问清楚,没有让我明白你到底想做什么。所以,接下来的步骤是把问题整理成一种我能听得懂的、更详细的方式传递给我,这样我才有机会帮到你。这个过程本质上对应于“提示工程”。如果我们通过提示工程的方法解决了问题,那就可以结束了。
第二种情况:我可能欠缺相关领域的知识。比如,如果你问我一个AI+建筑的问题,虽然我对AI比较熟悉,但对建筑不太熟悉。尽管我服务过很多其他行业的企业,掌握了一定的方法论,但因为缺乏相关知识,我目前可能帮不到你。此时,正确的方案是向我讲清楚问题,并围绕问题提供建筑行业的相关背景知识,让我至少明白问题的背景、场景以及要解决的问题本身。这些相关知识我们称之为“上下文”。有了这些上下文,我可能就能帮到你了。这实际上对应于RAG(Retrieval-Augmented Generation,检索增强生成)的使用场景。
第三种情况:可能是我自身的能力不足。这涉及到我的解决方案能力和方法论需要提升。所以,此时我可能需要反过来提升自己,因为基于现有的能力,即便你给我提供了很详细的背景知识,我可能也无法帮到你。等我提升自己之后,再反过来帮你,才有可能给你一个正确的回复。这第三种情况实际上对应于模型的微调,即不要抱怨外部环境,而是先重点提升自己。微调本身是对大模型本身的改造,但第一种和第二种情况其实并没有对大模型进行任何改造。
在工程实践中,我们的做事方式通常是先从提示工程开始,然后到RAG,最后才是模型微调。一开始就进行微调是不可取的。
第二部分 本地知识库主流技术选型
一、基于大模型的本地知识库建设所需技术组件
(一)前端交互框架
常用的大模型前端框架(主要列开源的)有Open Web UI、Cherry Studio、ChatBox、ComfyUI的对比表格:
|
框架名称 |
应用介绍 |
缺点 |
适用场景 |
|
Open Web UI |
可扩展、功能丰富、易用的自托管Web UI,可脱机操作,支持Ollama和OpenAI兼容API等各种LLM运行器。有直观界面、响应式设计、快速响应、无痛安装、多彩主题、代码语法高亮等特性,支持本地和远程RAG集成、Web浏览功能、提示preset支持等众多功能 |
可能存在与某些特定LLM或插件兼容性问题;功能丰富导致初次使用时学习成本略高 |
AI开发测试环境搭建,方便开发者快速测试不同模型;知识检索与分析,利用其功能对网络和本地知识进行检索分析 |
|
Cherry Studio |
专注于智能对话交互,具备丰富的对话管理功能,可处理复杂对话逻辑,提供个性化对话体验,可能集成特定领域知识和工具,以支持更专业的对话场景 |
可能在跨领域通用性上表现一般,针对非特定领域的对话可能效果不佳;依赖特定的训练数据和模型,数据更新不及时可能影响对话质量 |
智能客服领域,如电商平台、金融机构的客服机器人;智能助手场景,像政务咨询助手、医疗咨询助手等,为用户提供专业、个性化的对话服务 |
|
ChatBox |
主要功能为聊天交互,界面简洁直观,强调与用户的即时通讯和互动。提供预设聊天模板和话术,方便快速搭建聊天机器人等应用,具备一定的自然语言理解和自动回复能力 |
自然语言处理深度可能有限,对于复杂语义和多轮对话的处理可能不够精准;功能相对较为基础,对于复杂业务场景的支持可能不足 |
即时通讯类应用,如社交软件中的聊天机器人;信息查询场景,如在企业内部工具中快速查询信息,为员工提供便捷的信息获取渠道 |
|
ComfyUI |
以用户界面的舒适性和易用性为突出特点,界面设计注重用户体验,操作流程简单便捷。功能侧重于提供常用工具和功能模块,方便用户进行简单的文本处理、可视化展示等操作 |
功能相对有限,对于复杂的文本处理任务和高级可视化需求可能无法满足;可扩展性可能不如一些专业的大型框架 |
个人用户的文本处理场景,如撰写文章、编辑文档等;小型团队的知识管理平台搭建,方便团队成员进行知识共享和整理 |
(二)工作流知识管理
以下是常见的大模型支持工作流的知识库工具的对比表格,包括 RAGFlow、FastGPT、Dify.ai、AnythingLLM、MaxKB、AutoGen :
|
名称 |
功能介绍 |
优点 |
弱点 |
|
RAGFlow |
基于深度文档理解,支持从复杂格式的非结构化数据中提取信息,支持多种文本模板和自动化 RAG 工作流。 |
深度文档理解能力强,支持多种文档格式和复杂布局提供多种文本模板,结果可控可解释支持多种大语言模型和向量模型,易于集成和扩展 |
对文档处理的细节(如表格和图片)处理仍有待完善 |
|
FastGPT |
开箱即用的知识库问答系统,支持数据处理、模型调用和可视化工作流编排。 |
数据处理和模型调用便捷,支持多种非结构化数据可视化工作流编排,易于构建复杂问答场景高效向量检索,优化大规模数据检索效率 |
学习成本较低,但定制化和扩展性需要一定技术基础 |
|
Dify.ai |
多功能 AI 应用构建平台,支持多种大语言模型和插件扩展。 |
支持多种大语言模型和插件扩展对话管理功能强大,可自定义对话流和应用场景提供可视化对话配置和工作流管理 |
需要一定的技术背景进行模型管理和插件集成 |
|
AnythingLLM |
将本地文档或数据源整合进知识库,支持智能检索和对话。 |
高度灵活的任务适配性,支持多轮对话和复杂语境推理文档管理功能强大,支持多种文件格式支持实时在线学习,能够持续更新知识 |
对计算资源需求高,部署成本较大可解释性较差,难以追踪决策逻辑 |
|
MaxKB |
专注于特定领域的知识图谱构建工具,适合精确查询和基于事实推断。 |
数据表示直观,便于专家审核和验证查询效率高,适合已知模式下的问题求解支持因果分析等复杂功能扩展 |
扩展到未知领域时面临挑战,依赖预定义的本体框架维护工作量大,随着知识点增加而变得复杂 |
|
AutoGen |
支持多智能体协作,可与 LLM 集成,支持代码执行和调试,提供低代码接口。 |
支持多智能体协作,灵活性高与多种 LLM 无缝集成支持代码执行和调试,适合动态代码生成提供 AutoGen Studio,方便低代码开发 |
需要 Python 3.10 或更高版本对初学者有一定学习曲线 |
这些工具各有特点,适用于不同的场景和需求。您可以根据具体需求选择合适的工具。
(三)向量数据库
|
数据库 |
核心特点 |
适用场景 |
开源/商业 |
代表用户 |
|
Milvus |
高性能分布式架构,支持万亿级向量检索,多种索引算法(HNSW、IVF) |
大规模企业级应用(如电商推荐、金融风控)、需要高吞吐低延迟的场景 |
开源(Apache 2.0) |
快手、京东、Shopify |
|
Pinecone |
全托管云服务,无需运维,内置混合检索(向量+关键词),支持实时更新 |
中小团队快速上线、无运维资源的场景,注重开发效率而非成本 |
商业付费 |
ChatGPT Plugins、Grammarly |
|
Chroma |
轻量级内存数据库,API简单易用,适合快速原型开发,支持本地化部署 |
个人开发者实验、小规模知识库(如文档问答)、需要快速迭代的场景 |
开源(Apache 2.0) |
初创团队、AI教育项目 |
|
Qdrant |
高性能+强扩展性,支持多向量混合检索(文本+图像),提供云托管服务 |
多模态场景(如商品图文搜索)、需要灵活扩展的垂直领域应用 |
开源(商业托管版) |
欧洲AI初创公司 |
|
Weaviate |
内置向量生成模块(可对接BERT、CLIP),支持语义与结构化数据联合查询 |
需要结合知识图谱的复杂场景(如医药研发)、自动化数据嵌入的端到端方案 |
开源(商业支持) |
德国电信、荷兰政府项目 |
|
Pgvector |
PostgreSQL扩展,传统SQL与向量检索无缝集成,支持ACID事务 |
企业已有PostgreSQL生态、需要同时处理结构化数据与向量检索的场景(如用户画像+推荐系统) |
开源(PostgreSQL插件) |
传统企业IT系统改造项目 |
|
Elasticsearch |
原生支持向量搜索(8.0+版本),与全文检索深度整合,生态工具链成熟 |
日志分析+语义检索混合场景(如运维知识库)、已有ES技术栈的团队 |
开源(商业版增强) |
微软、Uber |
|
DingoDB |
开源分布式多模向量数据库,通过信通院备案 |
多模态数据支持、高效的向量检索能力、分布式事务与高可用性、统一SQL引擎、弹性扩展能力、开源开放、实时索引优化 |
开源 |
国内央国企、互联网公司 |
- Milvus
(1)核心优势
分布式架构:支持横向扩展,单集群可处理PB级数据,适用于超大规模RAG场景(如全网级知识库)。
高性能检索:通过GPU加速和量化技术(如SQ8)实现毫秒级响应,适合高并发在线服务。
多模态支持:2023年推出的2.3版本新增非结构化数据处理能力,支持图像、音频向量混合检索。
(2)典型应用
电商平台:京东使用Milvus实现10亿级商品向量实时推荐。
生物医药:处理蛋白质结构向量搜索,加速药物发现流程。
(3)避坑指南
部署复杂度高,需Kubernetes运维经验,建议使用Zilliz Cloud托管版降低门槛。
- Pinecone(商业化标杆)
(1)核心优势
零运维:自动处理索引构建、版本管理和集群扩展,开发者只需调用API。
混合检索:独创的“稀疏-稠密”双引擎,同时优化关键词匹配和语义相似度(适合法律/医疗等专业术语场景)。
实时更新:支持向量数据秒级生效,适合动态知识库(如新闻资讯类应用)。
(2)成本分析
起步价$70/月(100万向量),适合日均查询量<1万次的场景,超大规模成本指数级上升。
(3)典型案例
ChatGPT Plugins:利用Pinecone实现插件知识的快速检索增强。
- Chroma(轻量级利器)
(1)核心优势
极简API:5行代码即可完成向量入库和检索,学习曲线近乎为零。
内存模式:支持直接加载Python对象,适合Jupyter Notebook快速实验。
LangChain深度集成:内置文档分块、嵌入流水线,与主流RAG框架无缝对接。
(2)局限性
数据持久化依赖外部存储(如DuckDB),集群能力弱,不适合生产级高可用场景。
(3)适用场景
个人开发者构建PDF问答机器人,教育机构演示RAG基础原理。
- Qdrant(云原生新秀)
(1)技术亮点
多向量支持:允许单个数据对象关联多个向量(如商品的主图+细节图向量),提升检索精度。
过滤条件优化:支持在向量检索时附加业务规则(如“价格<100元”),减少后处理开销。
混合云部署:提供Qdrant Cloud托管服务,同时支持本地化私有部署。
(2)性能对比
在HNSW基准测试中,Qdrant的吞吐量比Milvus高15%-20%,但内存占用更大。
(3)典型用户
欧洲电商平台使用Qdrant实现跨语言商品搜索(支持50+语种向量对齐)。
- Pgvector(传统企业改造首选)
(1)核心价值
SQL原生支持:直接使用SELECT ... ORDER BY embedding <=> $1进行向量检索,无需学习新语法。
事务一致性:保证向量插入与业务数据的原子性,避免出现“检索到未提交数据”的脏读问题。
生态兼容:可利用PostgreSQL的流复制、分区表等企业级功能。
(2)性能优化
通过pg_embedding插件支持HNSW索引,检索速度提升10倍以上。
(3)适用案例
银行客户画像系统:在已有用户表中新增向量字段,实现“属性过滤+相似用户推荐”二合一查询。
- DingoDB(DataCanvas开源向量数据库)
DingoDB是九章云极DataCanvas自主设计和研发的开源分布式多模向量数据库。它集成了在线强一致性、关系型语义和向量语义,是一款独特的多模数据库产品。此外,DingoDB具备出色的水平扩展和缩放能力,能轻松满足企业级的高可用需求。提供多种语言接口,完美兼容MySQL协议,为用户提供极大的灵活性和便利。无论在功能、性能还是易用性方面,DingoDB均展现了全面而突出的优势,为用户的数据管理提供了前所未有的体验。官网地址:https://www.dingodb.com/#/home。
以下是关于DingoDB的技术亮点、核心价值和适用场景的总结:
(1)技术亮点
多模态数据支持
DingoDB支持结构化、半结构化和非结构化数据的统一管理,能够存储和查询表格数据、JSON文档、向量等多种类型的数据。
高效的向量检索能力
内置多种向量索引(如HNSW、IVF等),支持高效的向量相似度检索,并且可以进行向量与标量的混合检索。
分布式事务与高可用性
基于Percolator模型实现分布式事务,保证数据一致性;支持多副本存储策略,确保高可用性和数据可靠性。
统一SQL引擎
提供与MySQL兼容的SQL接口,支持结构化和非结构化数据的联合查询,降低用户的学习和迁移成本。
弹性扩展能力
支持在线动态扩缩容,能够灵活应对业务增长。
开源开放
完整开放数据库源代码,提供丰富的多语言SDK及详尽的开发文档。
实时索引优化
支持实时数据写入和实时索引构建,确保数据检索的无延迟体验。
(2)核心价值
多模态数据融合存储
DingoDB能够将不同模态的数据进行整合和管理,提供联合分析的服务能力,极大地简化了数据整合和集成的复杂性。
强大的向量检索与分析能力
在向量检索领域表现出色,能够解决相似性搜索、聚类分析和推荐系统等复杂问题,为用户提供精确的查询结果和个性化的推荐服务。
企业级高可用性与可靠性
通过分布式存储和多副本机制,确保数据的高可用性和可靠性,满足企业级应用的需求。
灵活的扩展性与易用性
支持水平扩展,能够轻松容纳大规模数据集,同时提供丰富的接口和工具链,降低运维成本。
(3)适用场景
企业知识库建设
提供向量化存储,支持语义精准搜索与联合分析,帮助构建智能化知识库,提升知识分享效率。
大模型记忆体
作为大模型的辅助存储,管理Prompt数据,提升查询响应速度和用户体验。
实时决策支持
支持高频Serving计算能力,适用于实时风控、营销、推荐等亚秒级决策场景。
多模态数据分析
支持音频、视频、文本等非结构化数据的向量化存储和联合分析,可应用于风险预测、舆情监测、智能客服等场景。
AI应用与推荐系统
作为向量数据库支持推荐系统、图像检索等AI应用。
物联网与时序数据处理
支持高效的时间序列数据存储和分析,能够处理海量IoT设备数据。
(四)嵌入模型(Embedding Model)
MTEB(Massive Text Embedding Benchmark)是一个用于评估文本嵌入(Embedding)模型的综合性基准测试平台,可通过以下地址访问:https://huggingface.co/spaces/mteb/leaderboard。通过多任务和多数据集的组合,MTEB可以全面衡量不同Embedding模型在各种自然语言处理(NLP)任务中的表现,如文本分类、语义检索、文本聚类等。
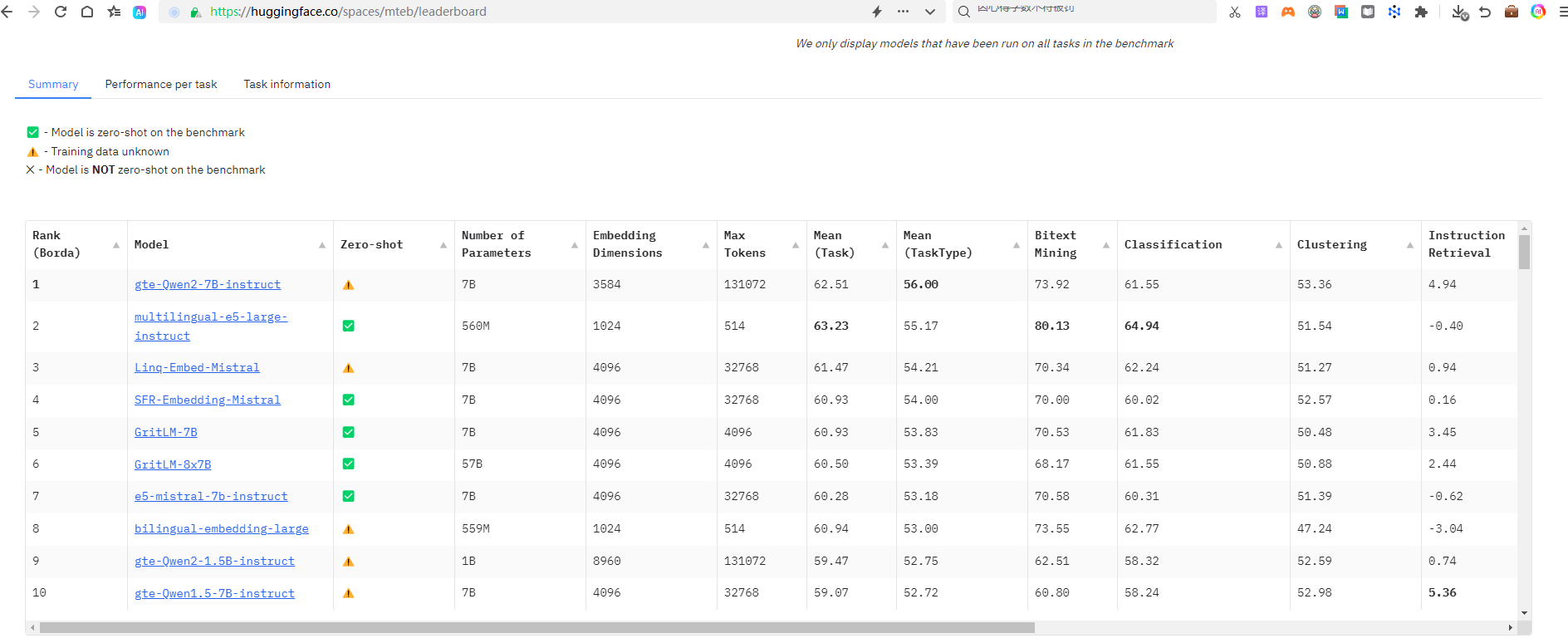
排名依据如下:
除了按照下载量和测评结果,还需要考量比如模型的性能、处理速度,vector维度大小等。下面我总结了一些不同维度进行选型的标准,主要包括以下几个方面:
模型性能:这是最重要的标准之一。性能优异的Embedding模型能够提供更准确的向量表示,从而提高信息检索的准确性和生成文本的质量。
处理速度:模型的计算效率也非常关键。处理速度快的模型可以在实际应用中显著提升系统的响应速度,从而改善用户体验。
向量维度大小:Embedding向量的维度大小直接影响到模型的存储和计算成本。较高的维度可以捕捉更多的细节信息,但也会增加计算开销。因此,需要在维度大小和性能之间找到一个平衡点。
适用性:不同的Embedding模型在不同的应用场景下表现各异。选择适合具体任务的模型可以显著提升效果。例如,对于文本生成任务,某些模型可能比其他模型表现更优。
训练数据和方法:Embedding模型的训练数据和方法也会影响其性能和适用性。基于大规模、高质量语料训练的模型通常具有更好的泛化能力。
可扩展性:在处理大量数据或需要频繁更新模型的场景中,模型的可扩展性至关重要。可扩展性好的模型可以更方便地进行扩展和更新。
兼容性:考虑Embedding模型与现有系统和工具的兼容性,以确保模型能够无缝集成到现有工作流中。
社区和支持:选择有活跃社区和良好支持的Embedding模型,可以更方便地获取帮助和资源,解决使用过程中遇到的问题。
选择合适的Embedding模型是开发RAG应用的关键之一。上述11个Embedding模型各有优势,开发者可以根据实际应用场景和资源情况,选择最适合的模型进行应用。在实际操作中,结合任务的需求,对这些模型进行微调与优化,也能进一步提升RAG系统的性能。
(五)推理大模型(LLM)
Ollama + Qwen2.5
Ollama提供本地模型管理,Qwen2.5在中文场景表现优异,支持128K长上下文,适合企业私有化部署。
LangChain + DeepSeek-R1
结合国产大模型DeepSeek-R1的本地推理能力,LangChain提供灵活的工作流编排。
Llama2 / Llama3
国际主流开源模型,需搭配中文微调版本(如Llama2-Chinese)提升本地化效果。
(六)RAG框架与工具链
LangChain / LangChain4j
提供文档加载、分块、嵌入、检索全流程支持,适配多种向量数据库和大模型,适合开发者定制化需求。
Haystack
模块化设计,支持复杂NLP管道(如问答、摘要),适合需要多任务协同的场景。
RAGFlow
提供预配置的RAG管道,简化开发流程,适合快速部署。
二、典型技术组合方案
方案1:轻量级本地知识库
组件组合:
DeepSeek-R1-Distill-Llama-70B + AnythingLLM(前端) + Chroma(向量库) + BGE嵌入模型
优势:
部署简单,资源占用低,适合个人或小型团队快速搭建。
方案2:企业级高并发系统
组件组合:
DeepSeek-R1(推理) + Milvus(向量库) + LangChain(RAG框架) + FlagEmbedding(嵌入) + ChatWiki(前端)
优势:
支持大规模数据检索与高并发请求,适合金融、医疗等对准确性和安全性要求高的场景。
当然,以上只是列出的两种不同级别的知识库的方案,实际上需要按自己的预算及效果预期来选择硬件资源和相关大模型软件。还可以选择更多的搭配,如:
用DeepSeek-R1和AntSK打造企业级本地知识库。
第三部分 基于DeepSeek R1 API+Cherry Studio构建本地个人知识库实操
一、知识库所需相关软件
我们前边讲了构建本地知识库,需要前端交互框架、向量数据库、嵌入模型、推理大模型、甚至是RAG框架和工具链。这里我们选择以下配置进行演示:
前端交互框架:Cherry Studio。
向量数据库:libsql(自带)
嵌入模型:可选bge-m3、bge-large-zh-v1.5、bce-embedding-base_v1等。
推理大模型:我们选DeepSeek R1,当然可以选择DeepSeek R1的在线API,由于其访问量巨大,存在不稳定的情况,我们也可以调用第三方的API(他们就是部署了一下DeepSeek R1),也可以私有化部署,如果只是重点测试知识库的能力,可以暂时先调外部大模型的API,等真正到了实用阶段,我们可以本地部署DeepSeek R1大模型并开放API。
二、Cherry Studio操作说明
为了快速上手,我们此部分不提前部署本地大模型,直接采用在线的大模型DeepSeek-R1的API,我们选择当下比较火的硅基流动。
(1)选择基模型/服务
我们到九章云极申请API。参考文章:九章云极AlayaNeW上线DeepSeek-R1原装满血API,凭速度与实力杜绝灵感浪费
用户需访问https://www.alayanew.com,登录 Alaya NeW 官网。在官网页面右上角,能找到 “注册” 按钮,点击它即可进入注册流程。
使用用户名和密码登录Alaya NeW平台后,悬停在右上角头像处,在弹出的窗口选择“访问管理”页签,进入访问令牌配置页面,如下图所示。
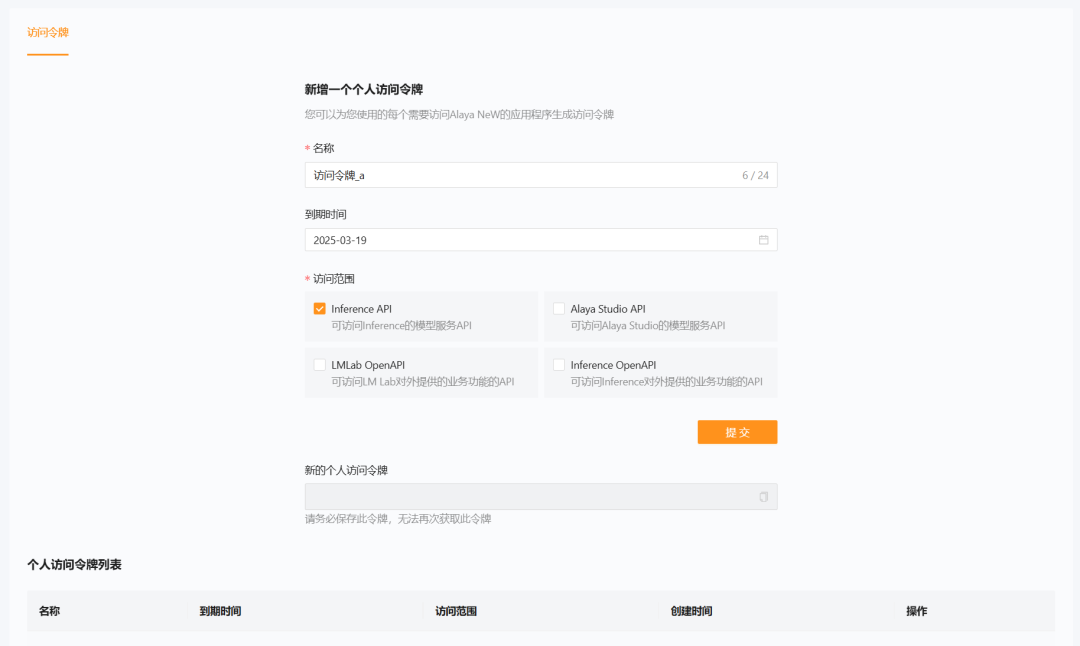
按照页面提示输入配置参数,例如访问令牌名称、到期时间、访问范围需勾选Inference API,单击“提交”按钮即可获取访问令牌,如下图所示。
将获取的API密钥与API地址(如下图)拷贝输入到Cherry Studio。在Cherry Studio设置页面进行设置。
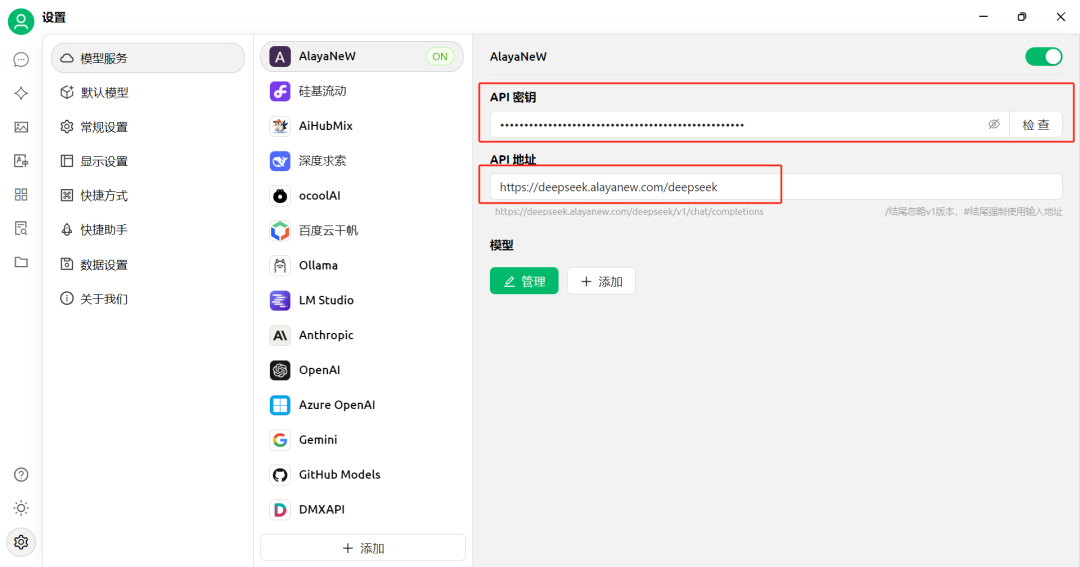
选择模型(基模型与嵌入模型)。
(2)上传私有语料(支持pdf、docx、pptx、xlsx、txt、md)
新建知识库并上传私有语料。
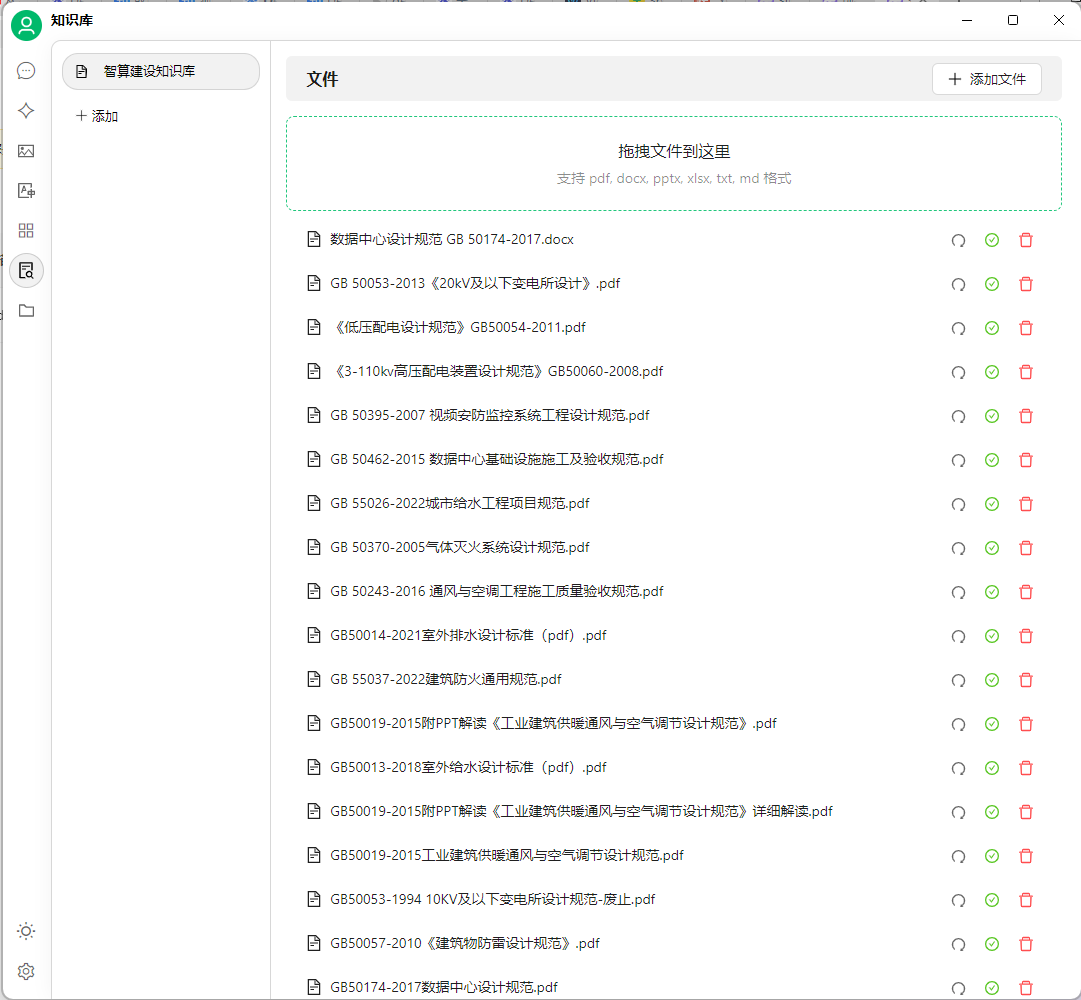
如图所示上传后出现一个对钩,表示文档已经向量化,其向量化是依靠我们之前选择的嵌入大模型。
(2)可创建应用(主要是通过提示词来创建):
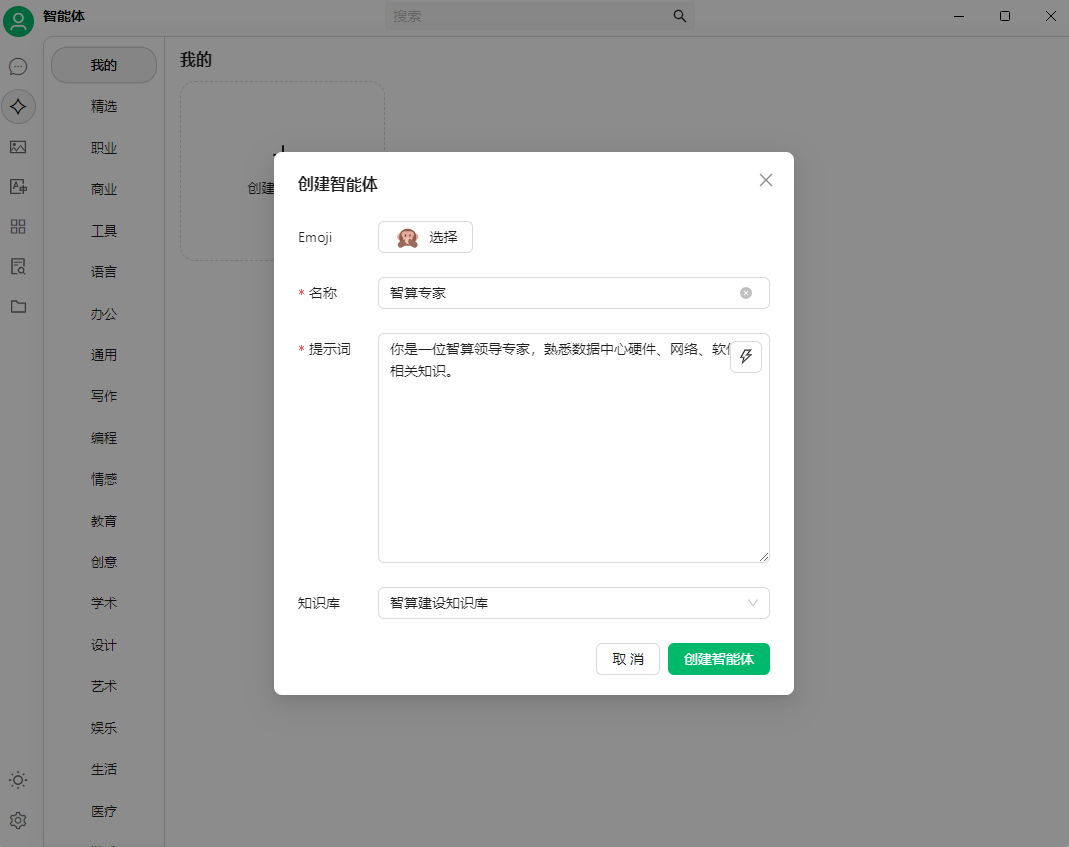
(3)使用智能体
总结一下,Cherry Studio的交互原理如下,有没有发现,这个时序图跟我们之前讲的RAG是不是基本一样,其实原理都是一样的,懂了一个就全懂了。
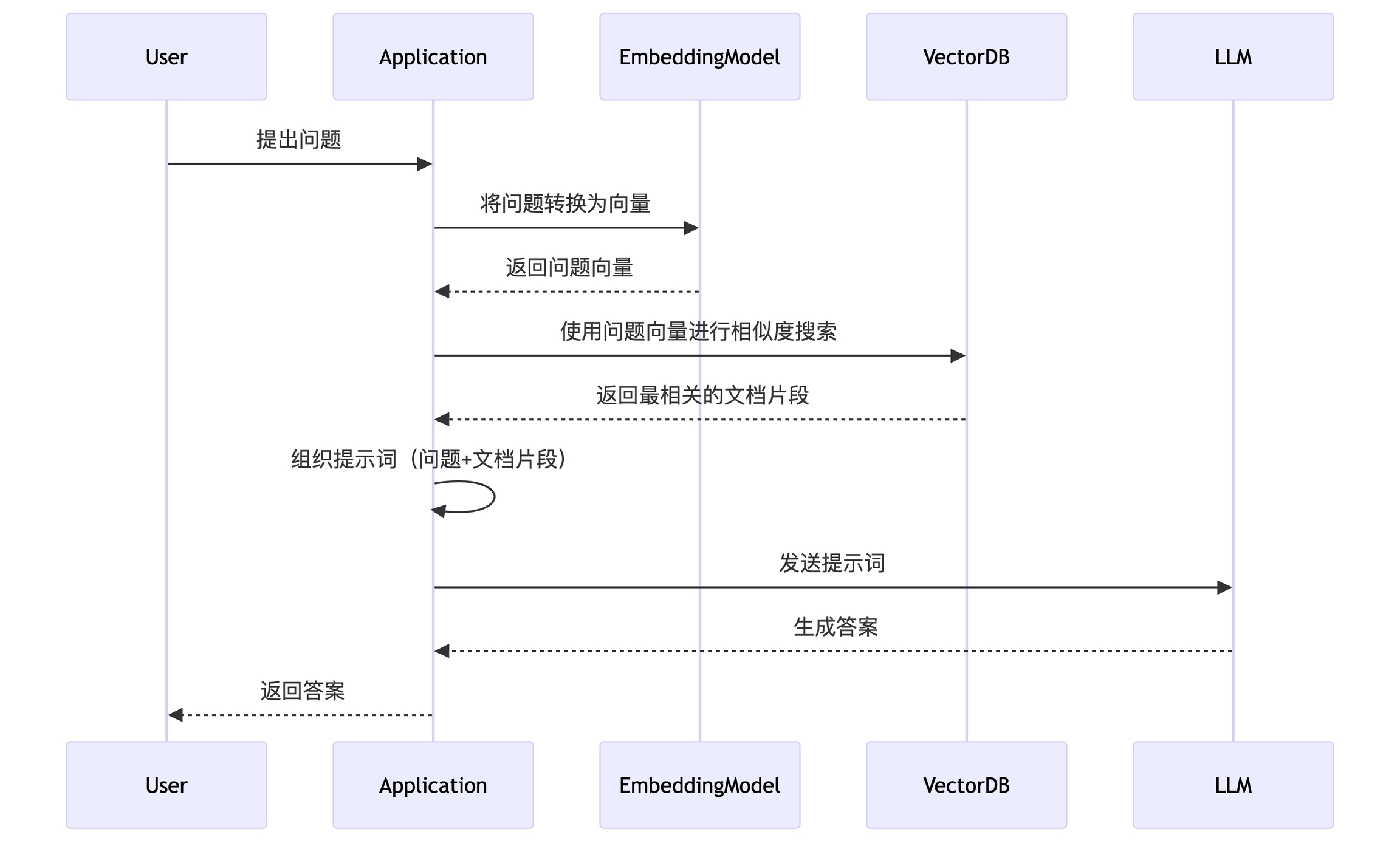
其中内置的VectorDB为libsql(可参考LibSQL: SQLite for Modern Applications)
更多教程可以参考:项目简介 | CherryStudio。
第四部分 基于Dify构建企业级智能客服Agent(智能体)
上述的智能体虽然可以满足一般要求,但基本只能实现知识问答,如果需要构建更复杂的应用,则需要使用支持工作流的Agent开发工具,如在线的有Coze(字节提供),个人用用还可以,但对于企业用户来讲,出于安全要求,私有数据或保密数据是不能上传到网上的,需要自己搭建本地的Agent开发工具。下边我们基于Dify构建智能客服智能体为例。您也可以移动步使用Dify构建带业务数据的智能客服 | Alaya docs进行学习。这里还有更多的实战操作内容。
Dify是一个开源易用的LLMOps平台,即使你不具备深奥的AI知识,也能快速构建属于自己的AI应用,不仅如此,Dify还提供知识库管理、Prompt编排等功能,为你构建的AI应用锦上添花。
Dify对接了各个大模型供应商,提供包括DeepSeek系列、Qwen系列、GPT系列、Claude系列等等在内的一系列模型,未来还会有更多开源的模型也将加入到该行列中,让你能够自由切换应用的模型。
本部分将演示如何部署Dify并基于自身业务数据构建一个AI智能客服。
一、前置条件
已开通容器云集群,如未开通请开通弹性集群容器
Docker环境,Docker环境安装请参考安装Docker
连接弹性容器集群,参考使用指南->弹性容器集群->快速开始
符合自身需求的业务数据
二、镜像准备
(一)拉取官方镜像
Linux(Shell)/Windows(PowerShell)
$images = @(
"postgres:15-alpine"
"redis:6-alpine"
"semitechnologies/weaviate:1.19.0"
"langgenius/dify-sandbox:0.2.10"
"ubuntu/squid:latest"
"langgenius/dify-api:0.12.1"
"langgenius/dify-web:0.12.1"
"nginx:latest"
)
$images | ForEach-Object { docker pull $_ }这里定义了一个数组 $images,包含了多个 Docker 镜像的名称和版本。每个镜像名称是一个字符串,例如 postgres:15-alpine 表示 PostgreSQL 的 15 版本,基于 Alpine Linux。使用 ForEach-Object 遍历数组并执行 docker pull 命令。启动Docker后,直接在Powershell中粘贴运行,就可以批量拉取上述镜像文件到本地了。
提示:docker pull默认是从Docker官方源拉取,需要能上外网(科学);如果没有科学上网,需要配/etc/docker/daemon.json,增加国内源:
{
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.1panel.live/",
"https://docker.m.daocloud.io",
"https://hub-mirror.c.163.com"
]
}如果还是下不下来的,可以直接到以下站点拉取:渡渡鸟镜像同步站
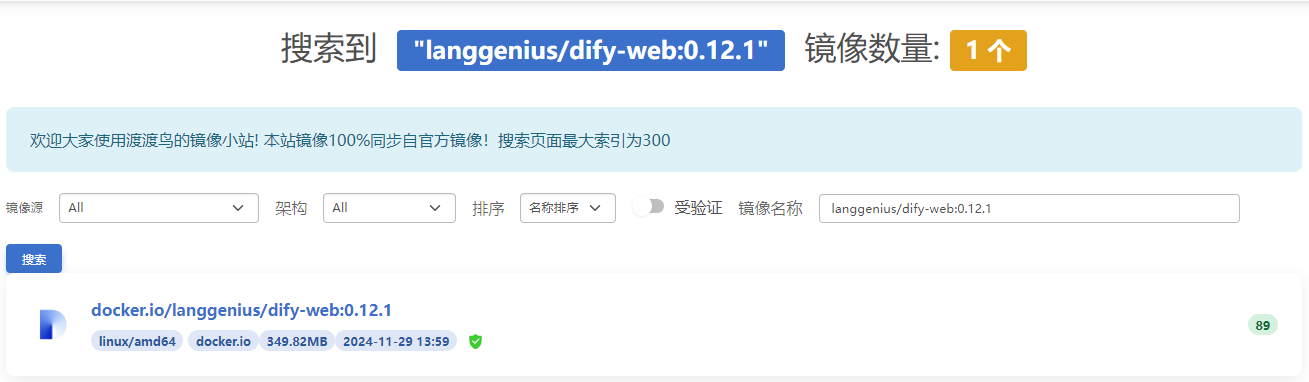
点击查询到的镜像名称:
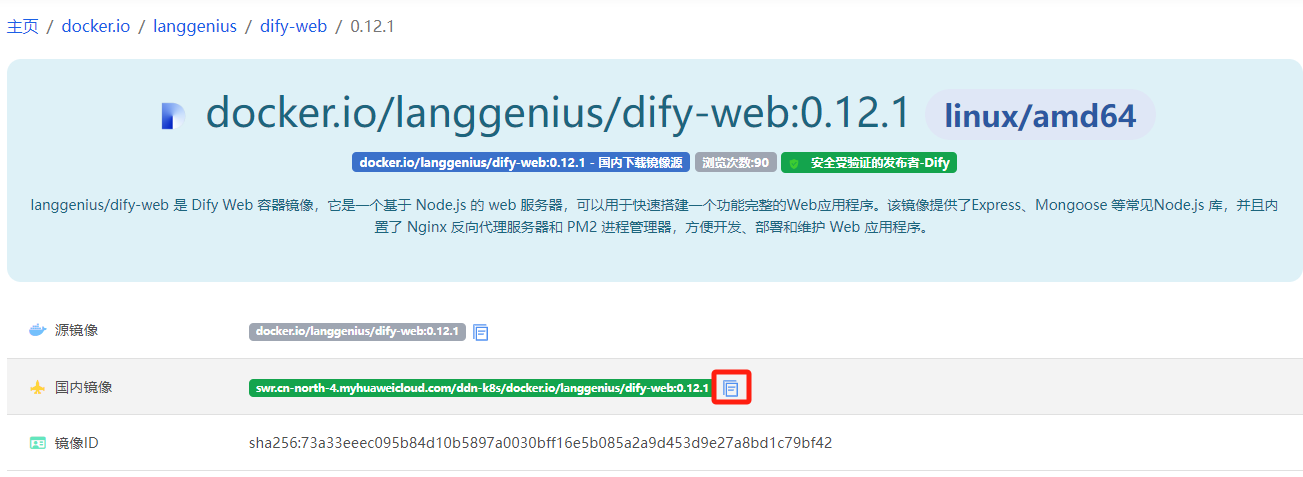
复制地址,然后docker pull + 上边复制的地址。
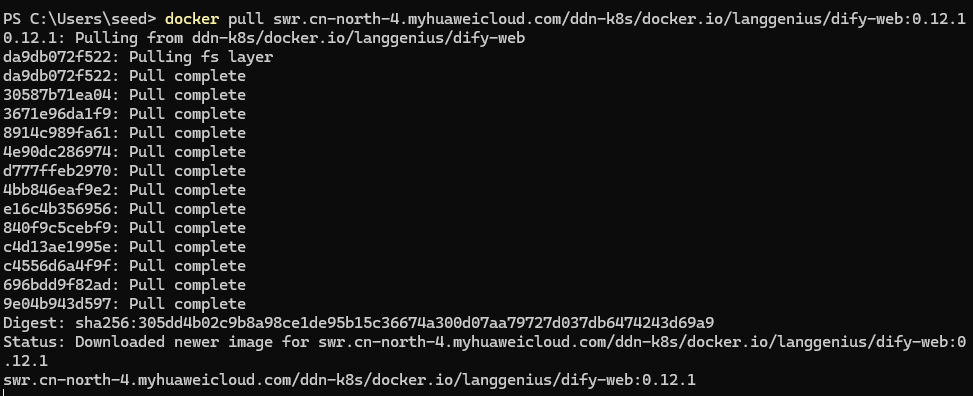
(二)推送镜像到镜像仓库
用户名密码:查看开通镜像仓库时的通知短信
镜像仓库地址:参考镜像仓库的使用(提前开通镜像仓库)
镜像仓库地址:由 镜像仓库访问域名/项目 组成,从资源管理-大容量存储-镜像仓库页面查看。
这里只演示一个,其他类似。
docker login registry.hd-01.alayanew.com:8443 -u your-username -p your-password
docker tag [换成本地镜像仓库地址]/dify-postgres:test [换成服务器私有仓库地址]/dify-postgres:test
docker push [换成服务器私有仓库地址]/dify-postgres:test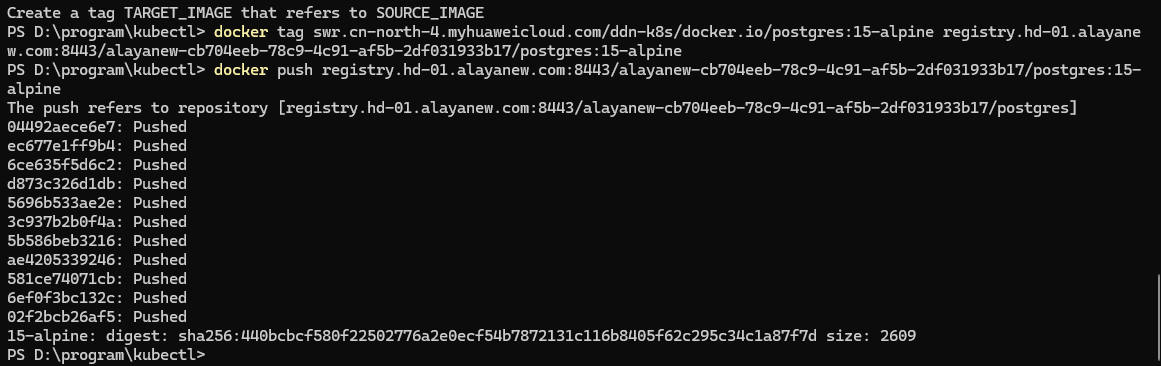
docker tag:
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/postgres:15-alpine registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/postgress:15-alpine
docker tag redis:6-alpine registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/redis:latest
docker tag semitechnologies/weaviate:1.19.0 registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/weaviate:latest
docker tag langgenius/dify-sandbox:0.2.10 registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-sandbox:latest
docker tag nginx registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/nginx:latest
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ubuntu/squid registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/ubuntu/squid:latest
docker tag langgenius/dify-api:0.12.1 registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-api:latest
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/langgenius/dify-web:0.12.1 registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-web:latestdocker push:
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/postgress:15-alpine
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/redis:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/weaviate:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-sandbox:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/nginx:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/ubuntu/squid:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-api:latest
docker push registry.hd-01.alayanew.com:8443/alayanew-cb704eeb-78c9-4c91-af5b-2df031933b17/dify-web:latest三、部署Dify
先用最简单的方式部署Dify,请点击此处获取配置文件dify.yaml(百度网盘 请输入提取码,仍无法下载的话可联系本文作者:微信号 seedzhang获取)。这个配置文件是把所有的组件用脚本串起来,配置信息都写在一块,执行后一键新建相关Pod并完成配置。
获取到配置文件后,需要修改镜像。 全局替换配置文件中的镜像为您本人镜像仓库的镜像,每个镜像都要替换一下,建议搜索"image",一个一个改,例如:
containers:
- name: dify-redis
image: registry.hd-01.alayanew.com:8443/alayanew-dab57f9b-35**********/dify-redis:test另外,需要修改一下dockerconfigjson,参照说明文档。
将以下json文件转成64位ascii码(即用你的用户名、密码,邮件信息生成一长串字符)。
{
"auths": {
"镜像仓库访问域名": {
"username": "your-username",
"password": "your-harbor-password",
"email": "your-email"
}
}
}用生成后的内容替换dify.yaml中dockerconfigjson冒号后边部分的值(下图ew0KICAGg....这一串)。
apiVersion: v1
kind: Secret
metadata:
name: dify-harbor-secret
namespace: dify
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: ew0KICAgICJhdXRocyI6IHsNCiAgICAgICJyZWdpc3RyeS5oZC0wMS5hbGF5YW5ldy5jb206ODQ0MyI6IHsNCiAgICAgICAgInVzZXJuYW1lIjogInpoYW5nZmVuZyIsDQogICAgICAgICJwYXNzd29yZCI6ICJNOWpkREltcXlnIiwNCiAgICAgICAgImVtYWlsIjogInpoYW5nZmVuZ0B6ZXR5dW4uY29tIg0KICAgIH0NCiAgfQ0KfQ==感叹一下,会写配置文件的都是高手。修改完配置文件后,执行kubectl apply -f dify.yaml命令,再通过kubectl get pod -n dify查看pod是否都起来了,如下图所示所有pod的状态都是Running即可:
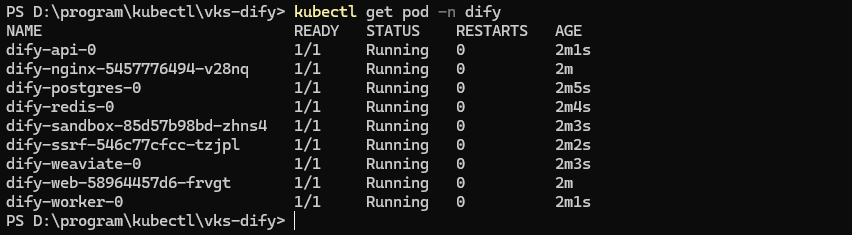
如何出错,可以执行 kubectl delete -f diff.yaml 后再重复上述操作。
完成Dify的一键启动,感受脚本的强大。
Dify成功启动后,执行kubectl describe serviceexporter dify-web-se -n dify即可获得网页链接(紧跟在url字样后),如下图所示:
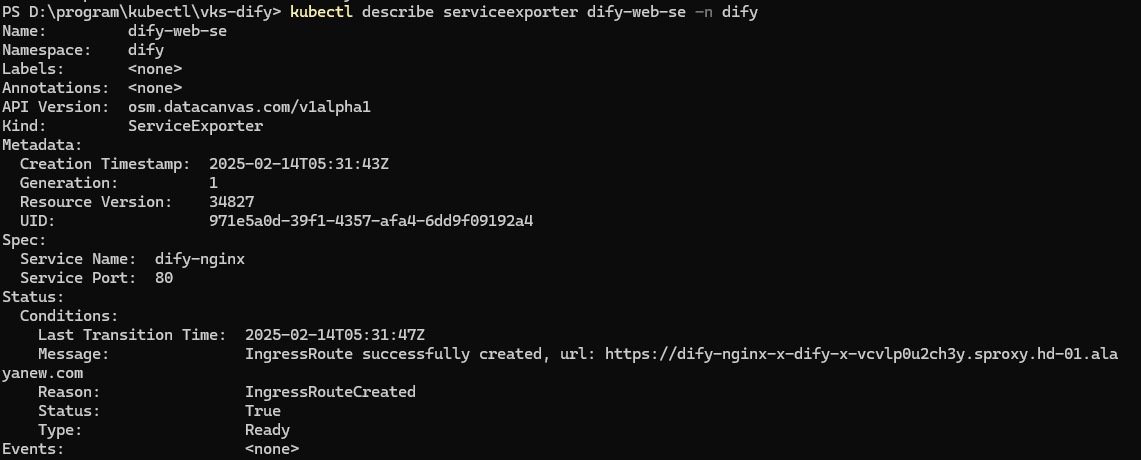
在浏览器中填写该链接,如上图中的https://dify-nginx-x-dify-x-vcvlp0u2ch3y.sproxy.hd-01.alayanew.com/,加上22443端口https://dify-nginx-x-dify-x-vcvlp0u2ch3y.sproxy.hd-01.alayanew.com:22443/即可进入Dify的Web页面,首次登录需要设置邮箱和密码,登录后进入如下界面:
四、Dify应用
(一)申请大模型厂商的API-KEY
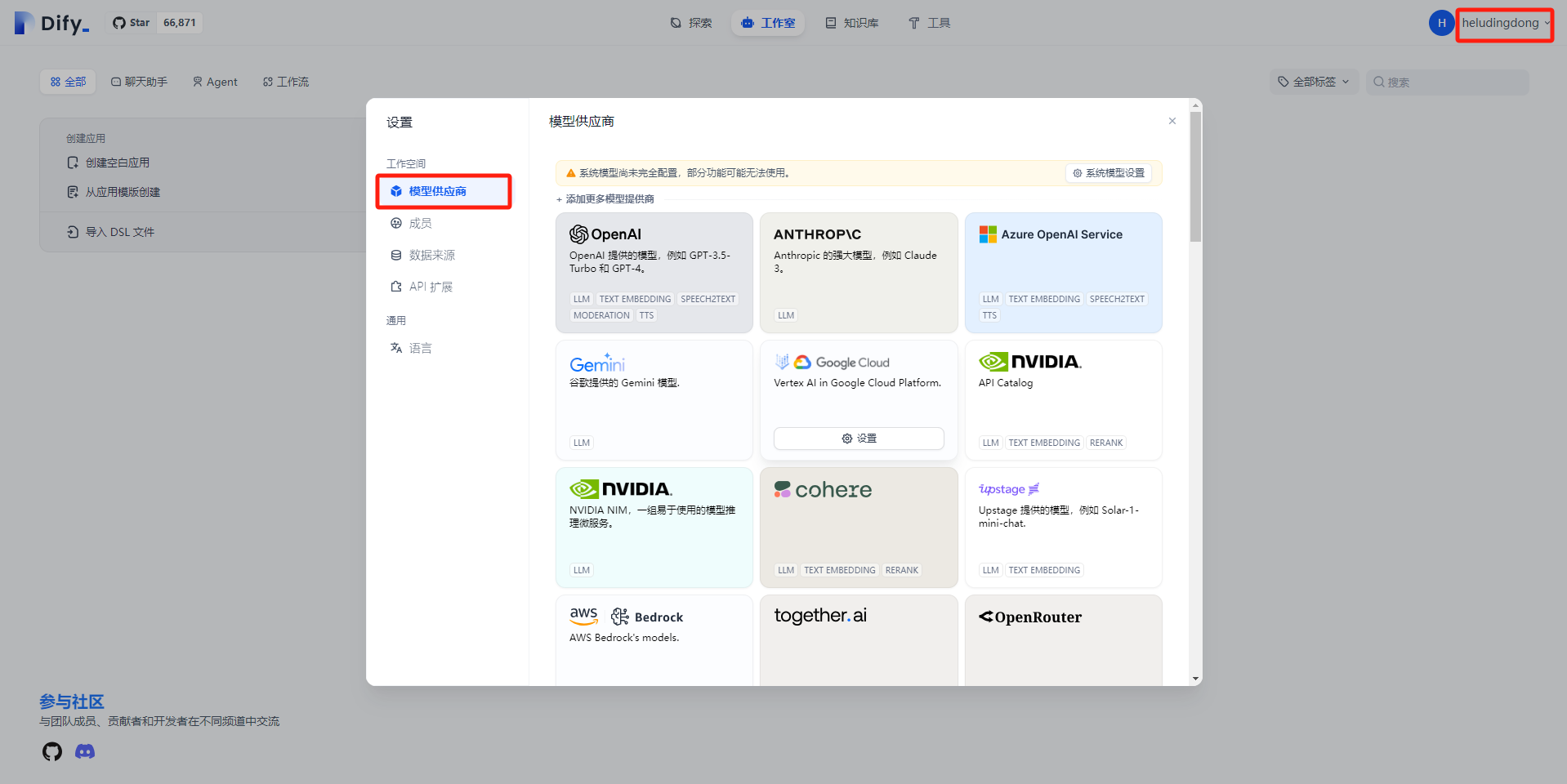
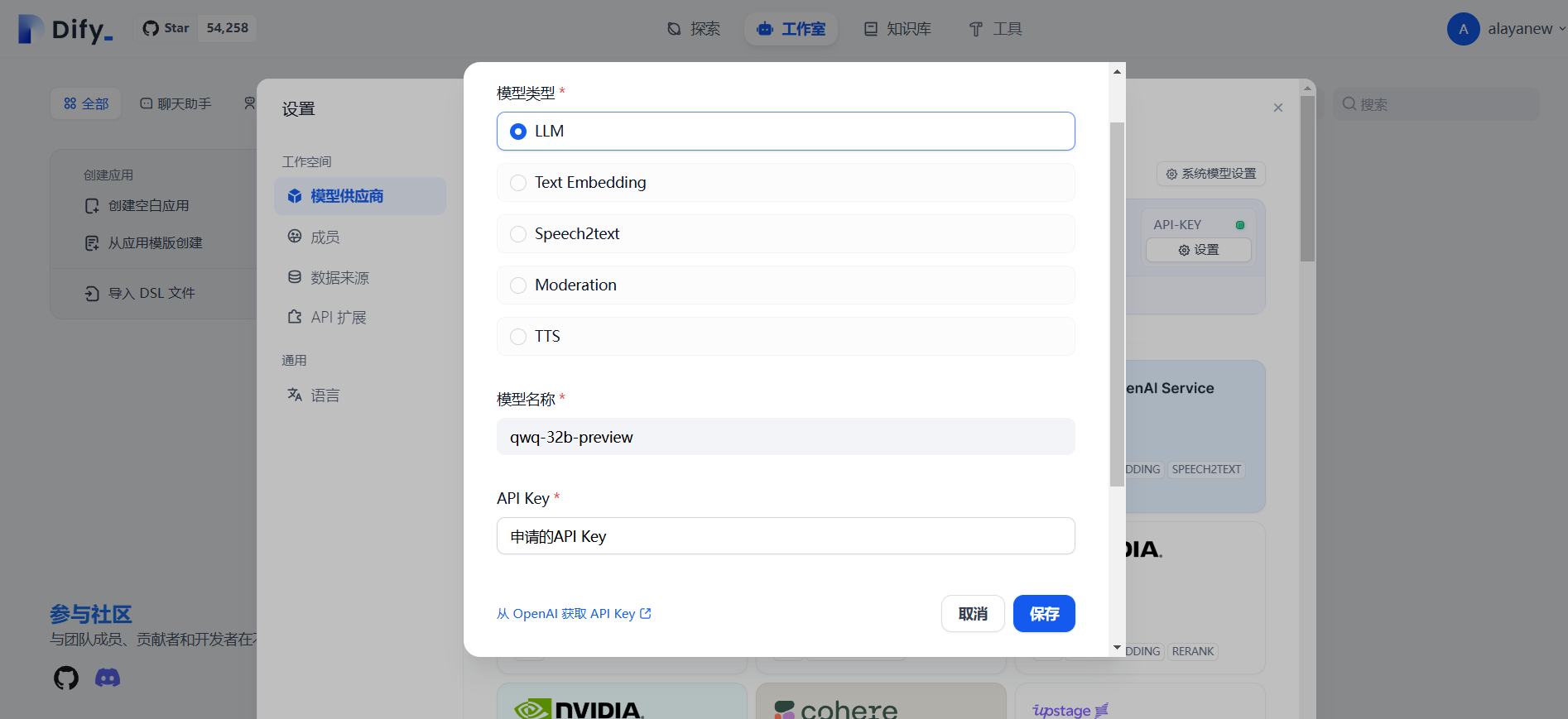
1.每一次大模型信息的调用都需要消耗对应的token,需要通过各个大模型供应商的官方渠道申请对应的API Key。API Key申请成功后,在【设置】->【模型供应商】选择对应的供应商,然后【添加模型】,模型类型、模型名称都要以模型供应商的为准,最后填入申请的API Key,【保存】即可。
2.如果要使用DeepSeek-R1的在线API,可参照本文第三部分Cherry Studio相关章节的介绍,如果想本地化部署满血版的DeepSeek-R1,可参考从零开始:满血版 DeepSeek-R1 私有化部署实战指南,需要根据下图所指【添加模型】。
以讯飞星火为例:
(1)配置API
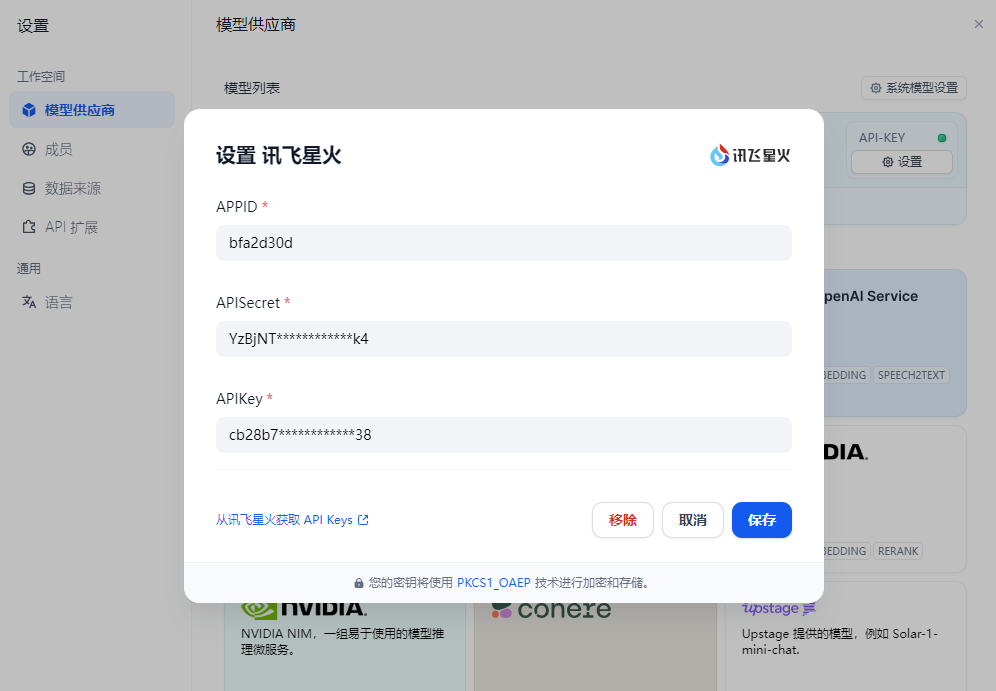
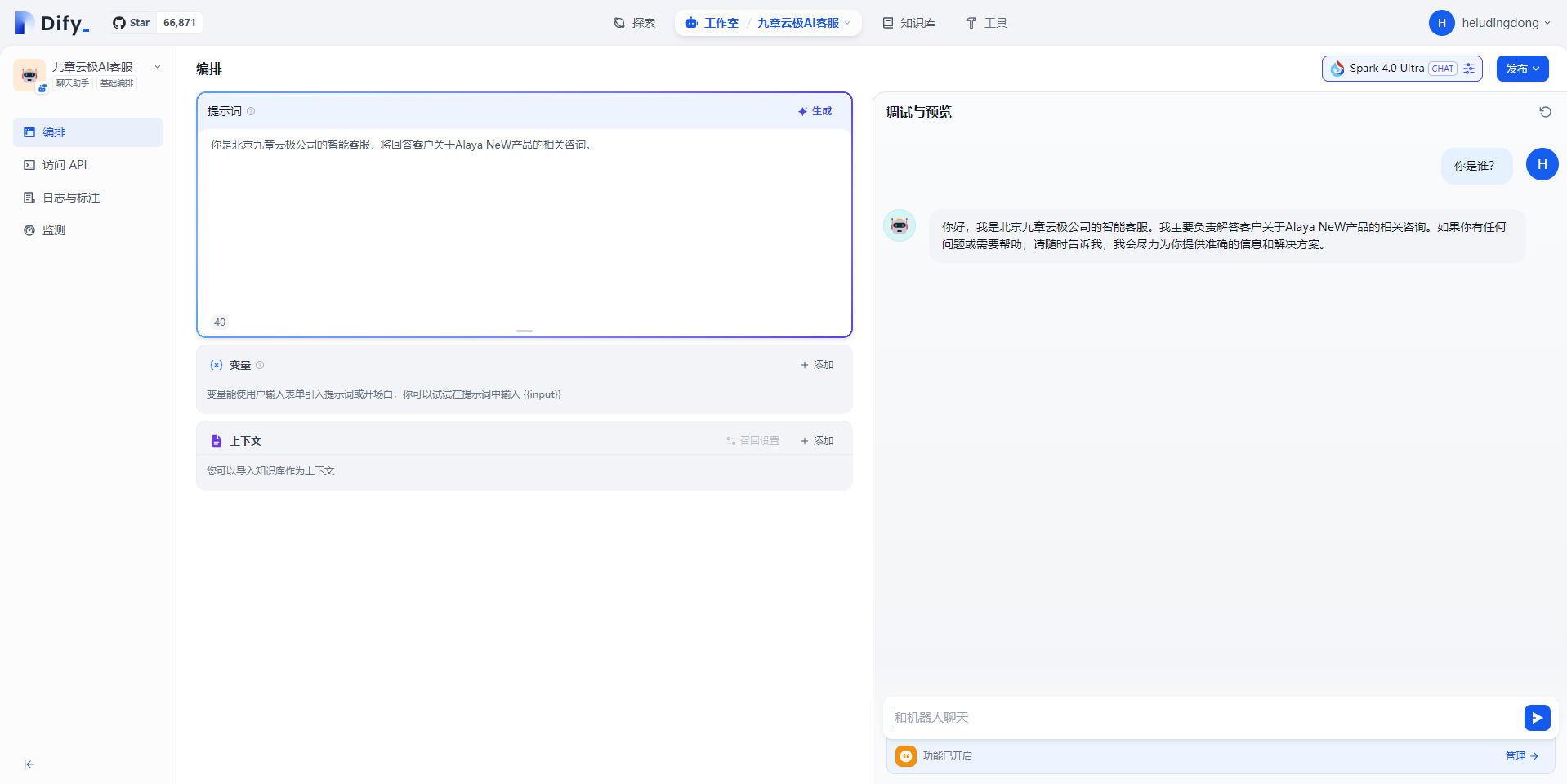
(2)测试效果
以DeepSeek API为例:到官网注册并获取API信息(不要用我的,余额不多了)。
(1)配置API
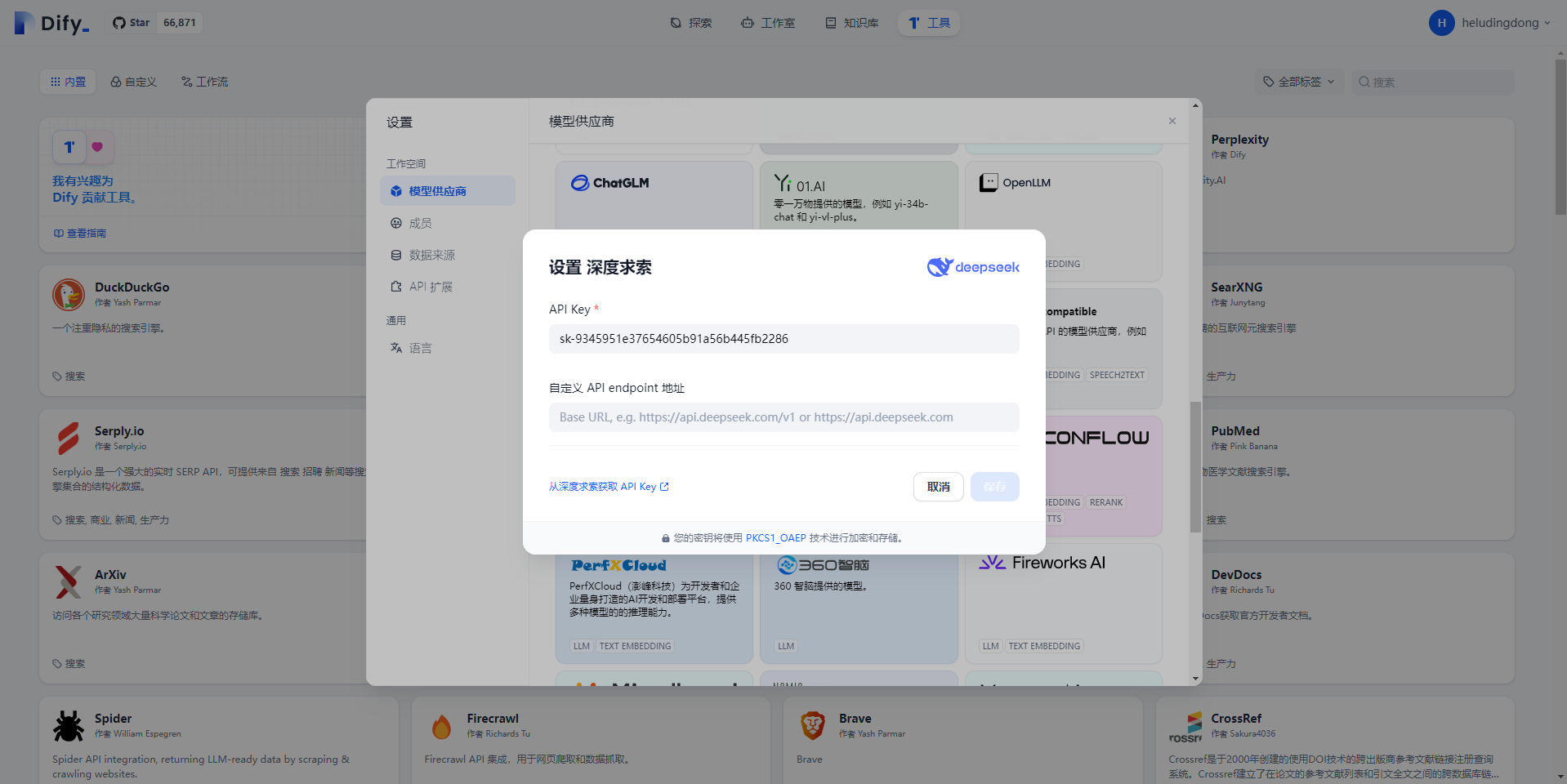
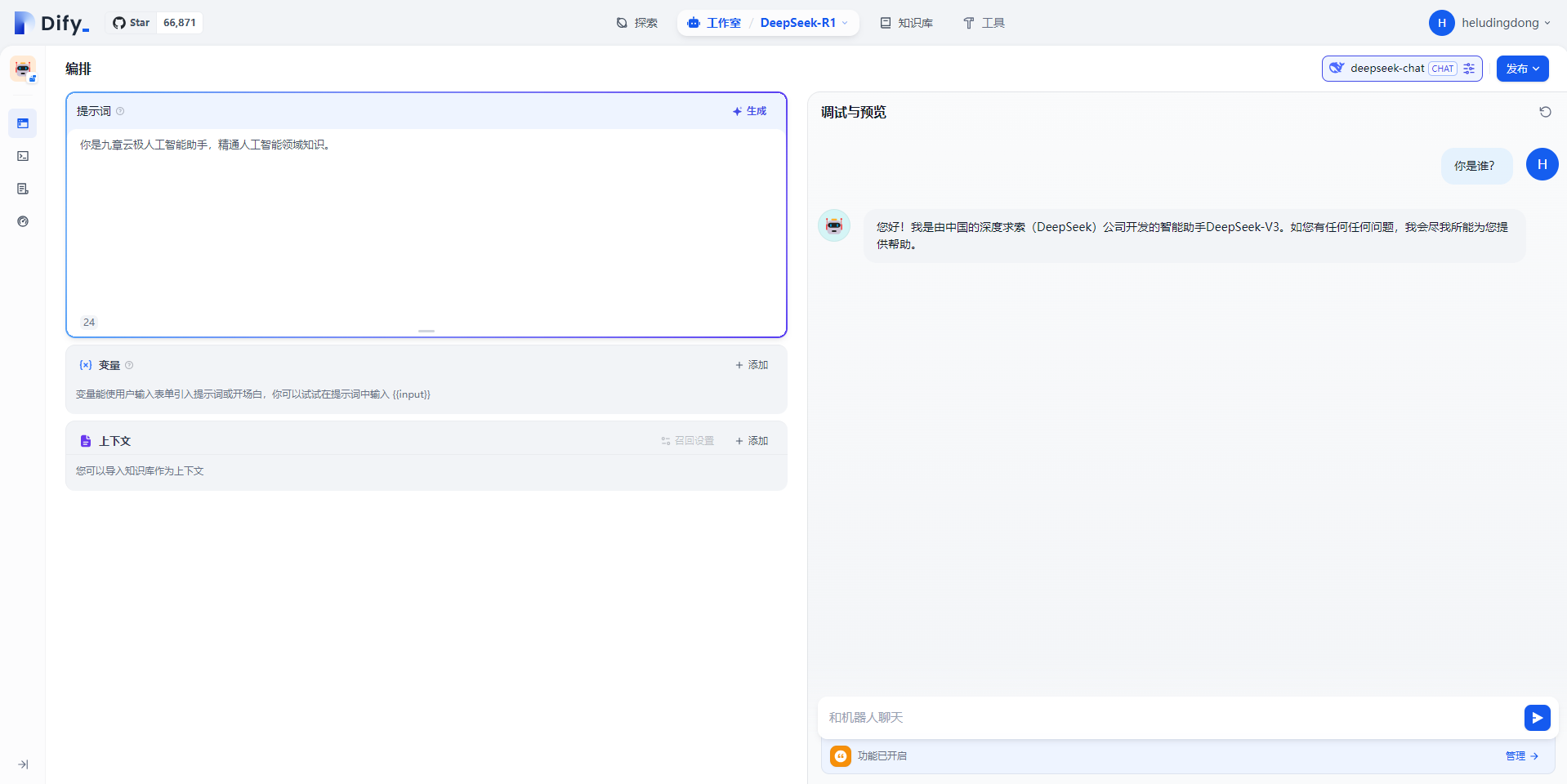
(2)测试效果
官网的API如果经常调线,也可以找第三方的,如硅基流动的API,不过个人感觉有点慢。
我们还需接入一个Embedding大模型的API,以便可以进行词向量化操作,可以自己部署也可以调用三方API。
(二)创建知识库
在【知识库】中可以构建包含自己业务数据的知识。
1.首先选择数据源,可以从现有的文件、Notion以及Web站点导入,也可以直接创建一个空的知识库。
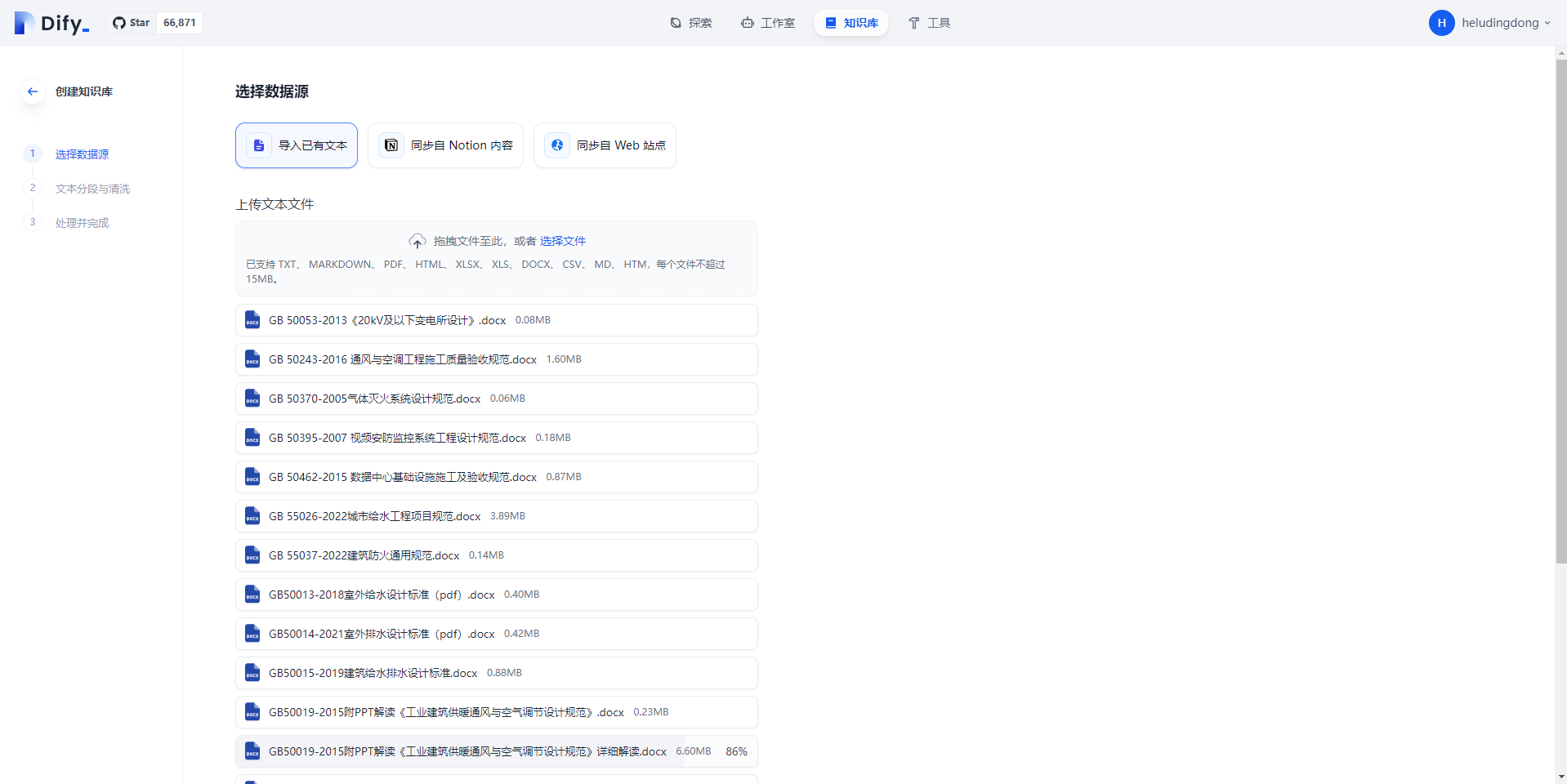
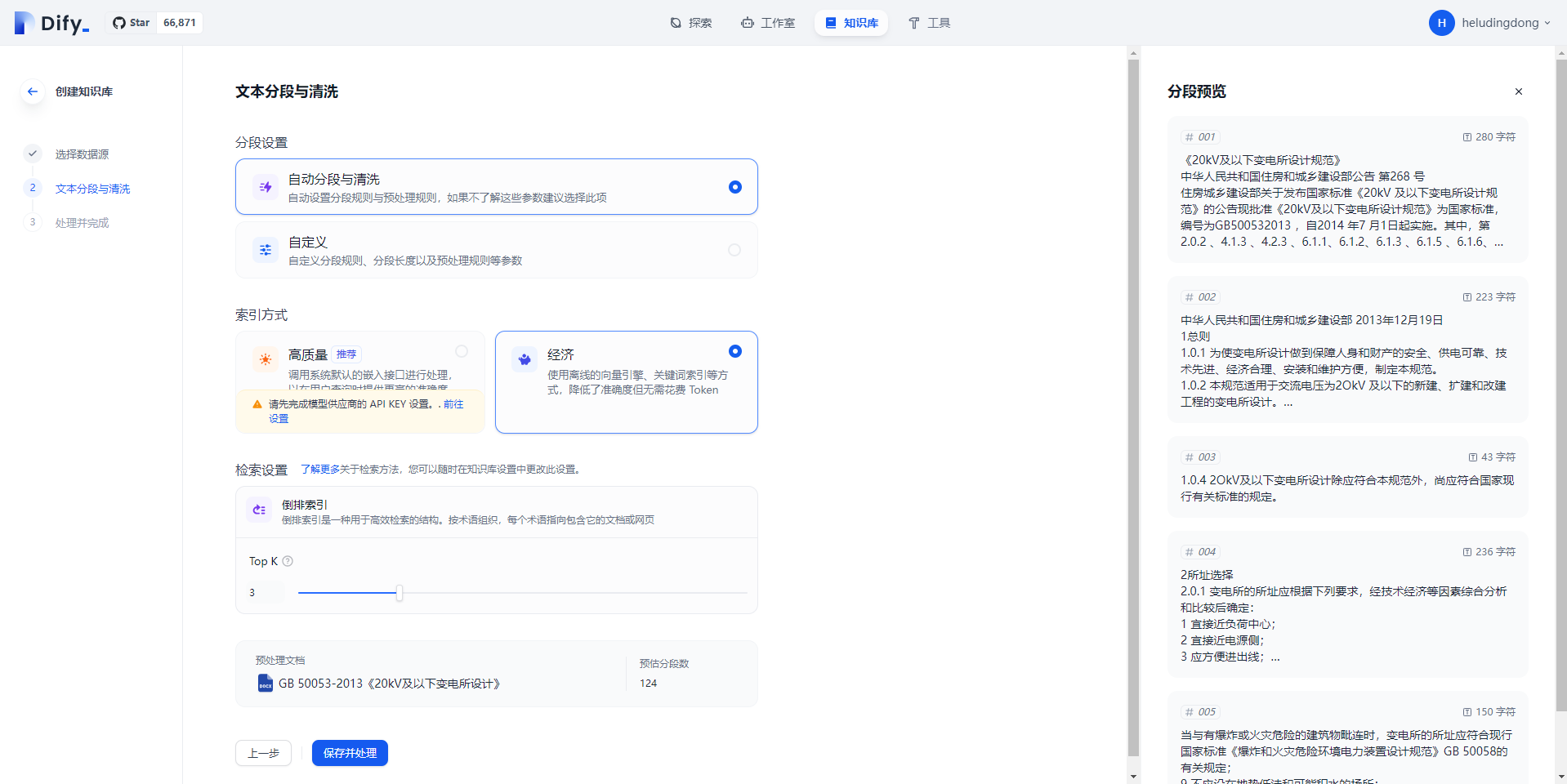
2.然后可以将相关业务数据的文档上传到知识库中,Dify会帮助你完成文本的分段与清洗,索引方式有高质量和经济两种,我们推荐使用高质量的方式(需申请模型供应商的API Key),虽然它会消耗一定的token,但是能够大大提高准确性。
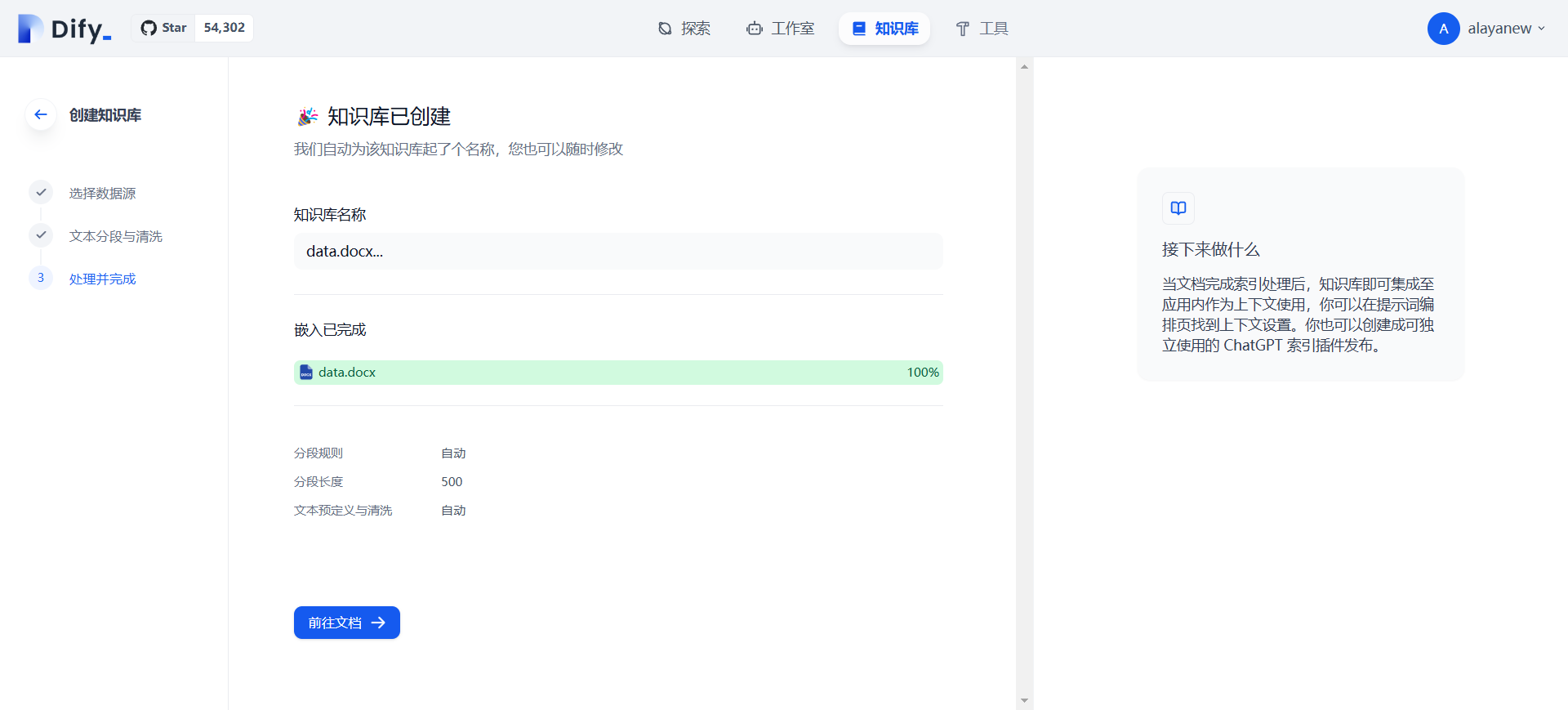
3.最后【保存并处理】,等待文本嵌入后即可完成知识库的创建。
(三)创建应用
Dify启动后,可以在【工作室】中,选择【创建空白应用】,基于使用场景选择【应用类型】以及【编排方法】,填写应用的【名称】与【描述】,即可完成基础应用的【创建】。
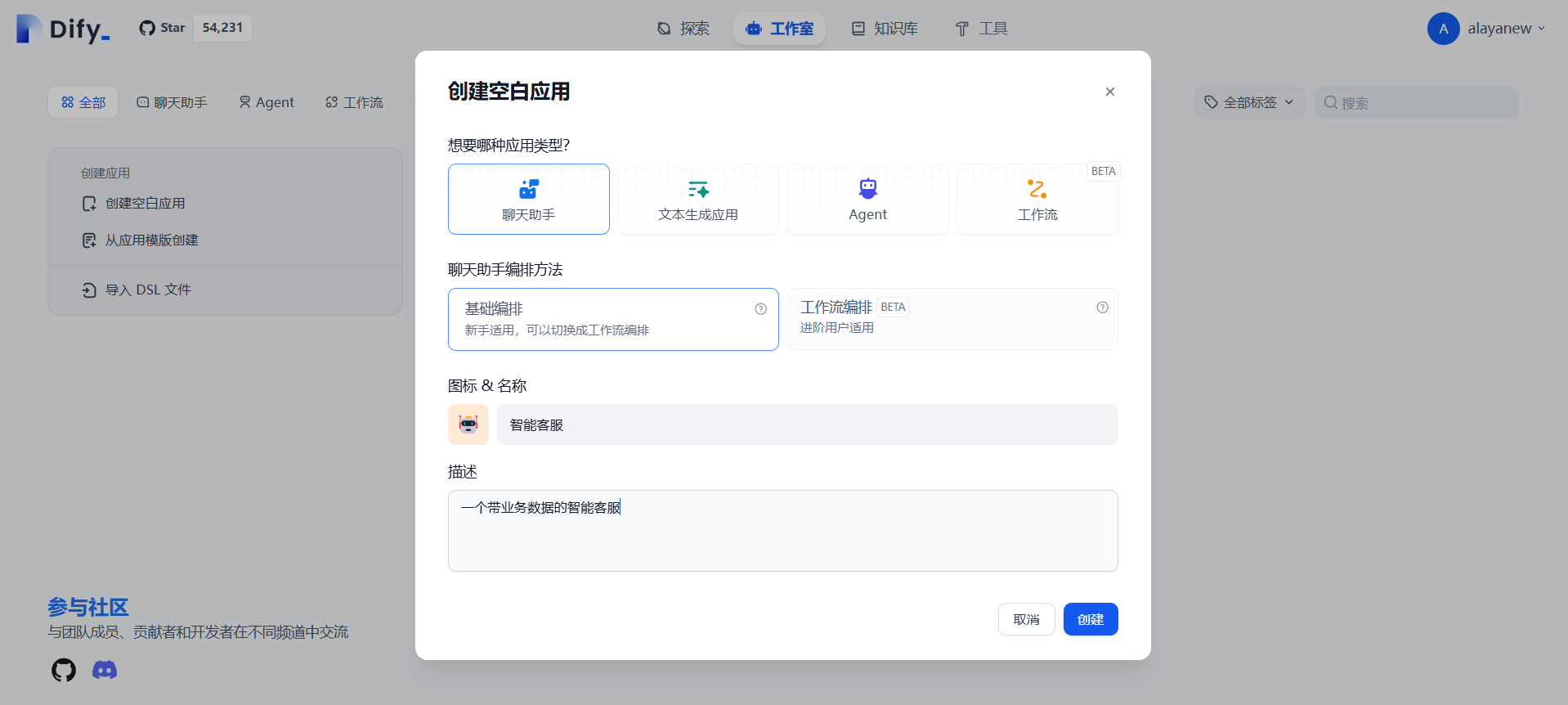
应用创建完成,可以进行Prompt编排、添加开场白、绑定知识库、模型选择以及对话聊天。
Prompt编排:让应用扮演智能客服的角色与用户进行交流,可以对应用进行限定,如使用的语气、回答问题的范围等。添加开场白:旨在用户打开聊天窗口时,应用会先与用户打招呼,增加聊天的亲切感。绑定知识库:添加上传的业务数据知识库。模型选择:选择不同供应上的模型,在此基础上调节该模型的参数。对话聊天:在一系列初始化完成后,可以基于业务数据对应用进行问答。
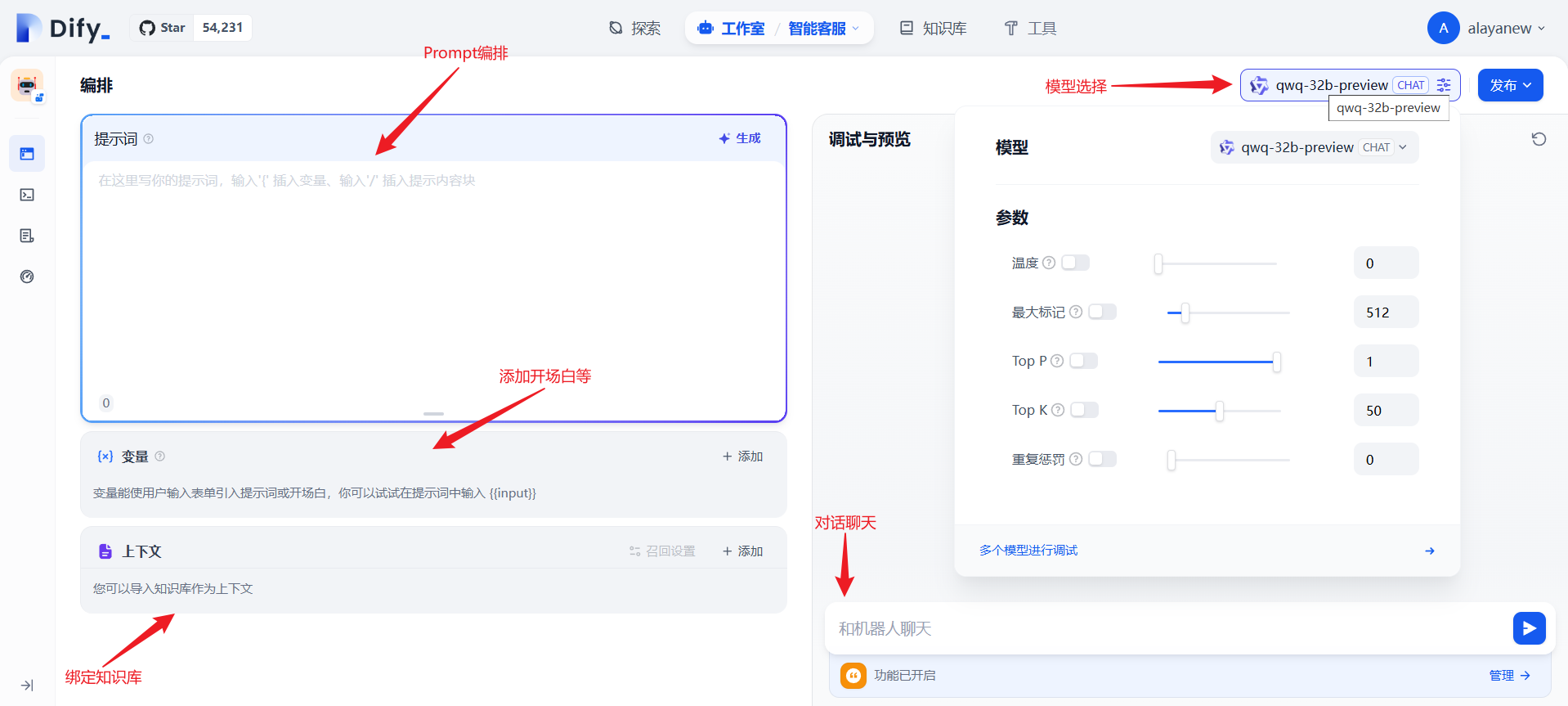
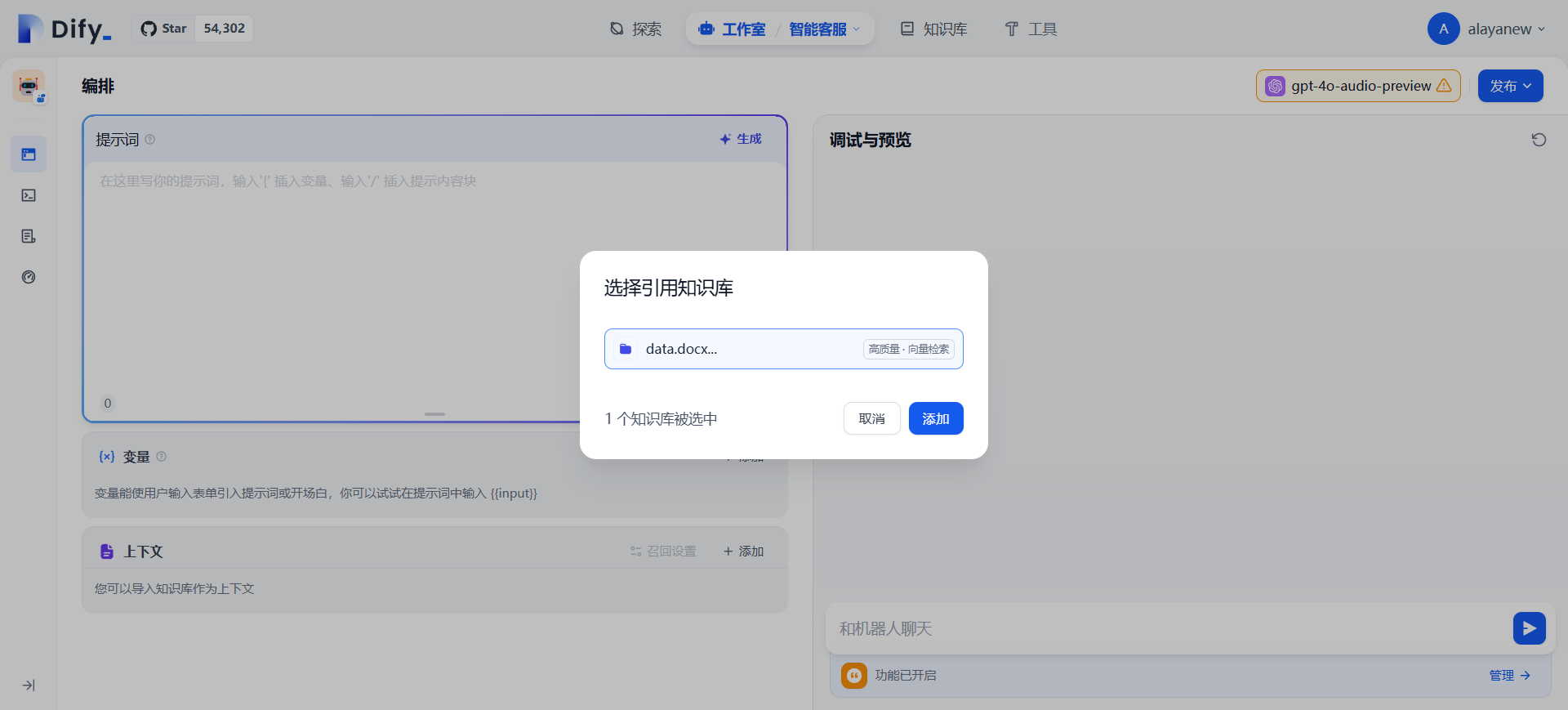
(四)应用绑定知识库
我们回到创建的应用,在上下文处【添加】,【选择】创建好的业务数据相关的知识库,【添加】后即可完成知识库的绑定。
(五)调试智能客服并发布
通过对话聊天向应用发送信息,看其表现是否符合预期,如果符合预期,就可以【发布】应用了。
第五部分 总结
通过本文的介绍,相信大家对基于大模型的知识库建设有了一定的认识,并且无论是个人使用还是企业使用,都可以按照本文档的操作说明落地项目建设。但是,技术和产品更新换代实在太快了,需要保持持续的学习下实践,希望大家可以跟我们一起,积极学习进步。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)