AI大模型 | 如何给本地部署的DeepSeek投喂数据,让他更懂你
1.推荐使用迅游加速器或海豚加速器优化网络路径,缓解因网络拥堵导致的连接问题。2.清理浏览器缓存与切换设备3.错峰使用策略避开工作日早晚高峰(10:00-12:00, 19:00-22:00),建议在凌晨1:00-6:00使用API调用与第三方平台。
解决DeepSeek服务器繁忙问题
一、用户端即时优化方案
网络加速工具
1.推荐使用迅游加速器或海豚加速器优化网络路径,缓解因网络拥堵导致的连接问题。以迅游为例:
- 启动加速器后搜索"DeepSeek"专项加速
- 输入口令DS111可领取免费加速时长(海豚加速器适用)
2.清理浏览器缓存与切换设备
- 在Chrome/Firefox中清理缓存(设置→隐私和安全→删除浏览数据)
- 尝试手机APP访问或使用无痕模式(Chrome按Ctrl+Shift+N)
3.错峰使用策略
避开工作日早晚高峰(10:00-12:00, 19:00-22:00),建议在凌晨1:00-6:00使用
二、高级技术方案
本地化部署
通过海豚加速器或迅游的「一键本地部署」功能实现:
- 选择本地部署工具后自动安装模型
- 部署完成后直接在终端对话(需30GB以上存储空间)
API调用与第三方平台
- 通过硅基流动、秘塔AI等平台调用DeepSeek模型(需注册账号)
- 使用AnythingLLM等开源工具搭建私有数据库5
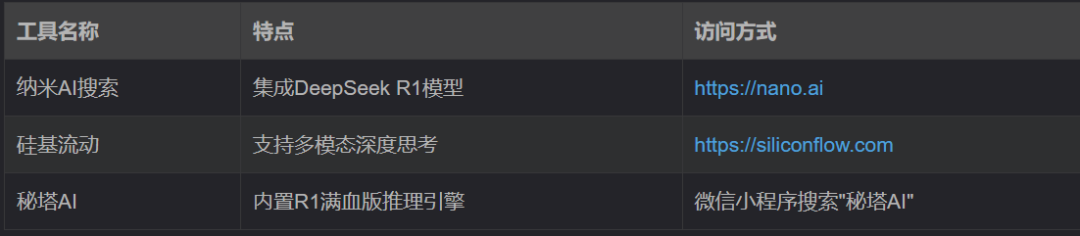
三、替代方案与平替工具(最推荐简单好用)
若问题持续存在,可考虑以下替代服务:
用加速器本地部署DeepSeek
使用加速器本地部署DeepSeek的完整指南
一、核心原理与工具选择
通过加速器实现本地部署的本质是:利用网络优化工具解决模型下载/API通信问题,配合部署框架实现离线运行。当前主流方案分为两类:



三、海豚加速器+Ollama手动部署
高阶操作流程:
**加速下载模型**
```bash
ollama run deepseek-r1:7b --accelerator=dolphin # 调用海豚加速通道
启动本地服务
ollama serve # 默认端口
**故障排查:**
- 若出现`Error: model not found`,执行:
`export OLLAMA_HOST=0.0.0.0:11434`(Linux/Mac)[4]()
- GPU未被识别时,运行:
`nvidia-smi`确认驱动状态 → 重装CUDA 12.1+[10]()
#### 四、性能优化建议
1. **硬件加速配置**
- NVIDIA用户启用CUDA加速:
```bash
ollama run deepseek-r1:7b --gpu 0 # 指定第1块GPU
AMD显卡使用ROCm:
安装ROCm 5.6+后添加–rocm参数8
内存优化技巧
调整交换分区(Linux):
sudo fallocate -l 16G /swapfile sudo chmod 600 /swapfile sudo mkswap /swapfile sudo swapon /swapfile
- Windows用户设置虚拟内存为物理内存的2倍[8]()
#### 五、部署后管理
1. **常用命令速查**
| 命令 | 功能描述 |
|--------------------------|------------------------------|
| `ollama list` | 查看已安装模型 |
| `ollama rm deepseek-r1` | 删除指定模型 |
| `ollama pull deepseek-r1:14b` | 升级模型版本 |
2. **可视化界面推荐**
- Chatbox(跨平台GUI):
下载地址:https://chatbox.space → 连接`http://localhost:11434`[4]()
- AnythingLLM(企业级):
支持多模型切换与知识库集成[7]()
**典型问题解决方案:**
- 部署后响应慢 → 检查`nvidia-smi`的GPU利用率,确认CUDA已启用
- 对话中断 → 执行`ollama serve --verbose`查看详细日志
- 存储空间不足 → 使用`ollama prune`清理旧版本模型[8]()
通过以上步骤,用户可在15分钟内完成从加速器配置到本地服务的完整部署。建议首次部署选择7B版本进行验证,后续根据实际需求升级更高阶模型。
话说回来了,为啥要本地部署呢?
① 在使用DeepSeek中,经常会出现服务器繁忙,请稍后再试。
② 不想让个人隐私数据暴露出去
③ 可以将各种格式的文件,如pdf、csv、txt、md 格式的数据投喂给它。比如你想让 DeepSeek 了解你的公司业务,就把相关的文档上传给它。
DeepSeek 就能吃下你给它的各种“知识大餐”,然后变得更聪明,更懂你
一、RAG是什么?
为了投喂数据,我们要用到RAG。首先,我们先来了解下什么是RAG?
我们就问问昨天部署好的DeepSeek好了。
首先我们在命令行输入:ollama run deepseek-r1:1.5b 命令,启动DeepSeek
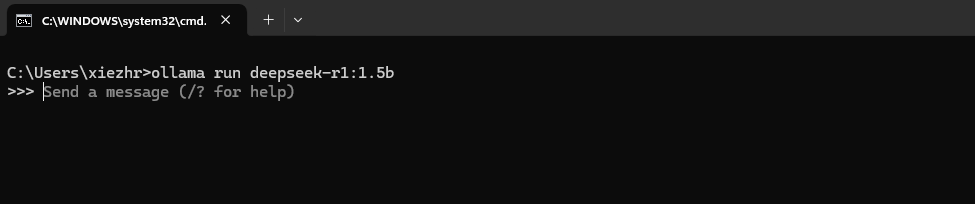
然后打开浏览器并输入快捷键:ctrl+shift+l 调出WebUI可视化AI界面
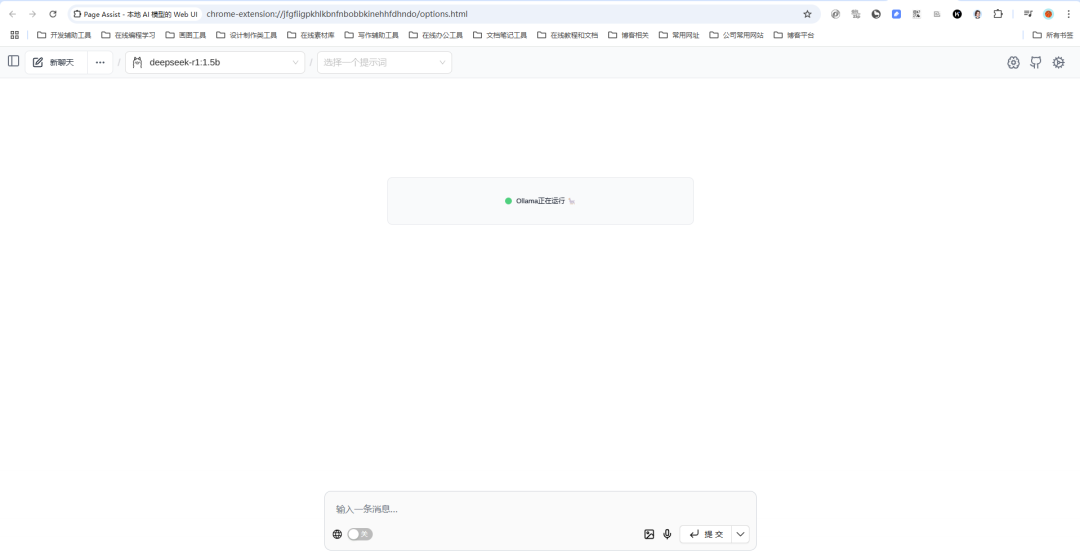
输入:RAG是什么?
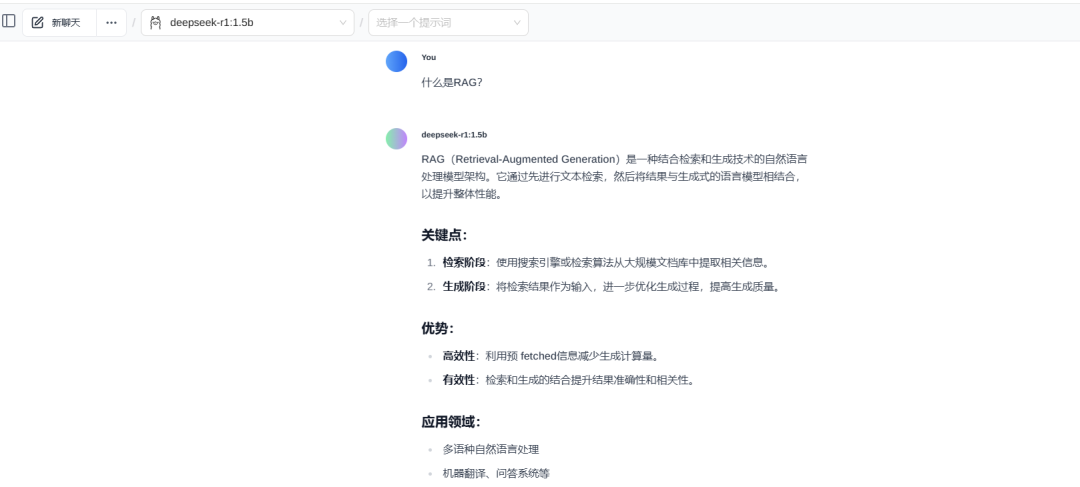
翻译成大白话就是:我们把知识放到知识库里,然后把它投喂给人工智能。我们需要用一个量化的工具,把各种格式的数据量化给人工智能,让它能看得懂。
人工智能通过对这些知识的学习后,以后你再问它的时候,他就能将知识提取出来,加工处理后回答你的问题。
RAG 就是让 DeepSeek 不仅能靠自己的知识库回答问题,还能通过检索外部数据来增强回答的准确性和丰富性。就好比你考试时偷偷带了小抄,但 DeepSeek 是光明正大地“作弊”,还能把答案说得头头是道。
二、 拉取nomic-embed-text
刚说了RAG是啥?我们需要一个RAG工具来完成量化工作。
各种开源免费的RAG工具挺多,我们这里选择最近比较获得ollama 提供的nomic-embed-text。
https://ollama.com/library/nomic-embed-text
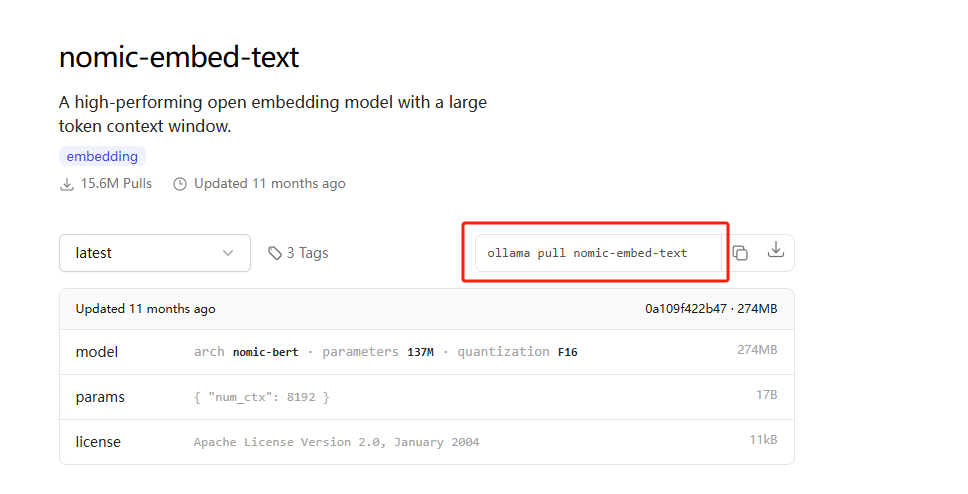
我们使用上面圈出来的命令拉取即可,274M,大约1min左右就可以下完,出现【success】字样表示下载成功。

三、RAG设置
打开WebUI界面,我们会看到一个RAG设置文本嵌入模型。
文本嵌入模型就是把我们投喂的各种文档数据量化成DeepSeek认识的数据。
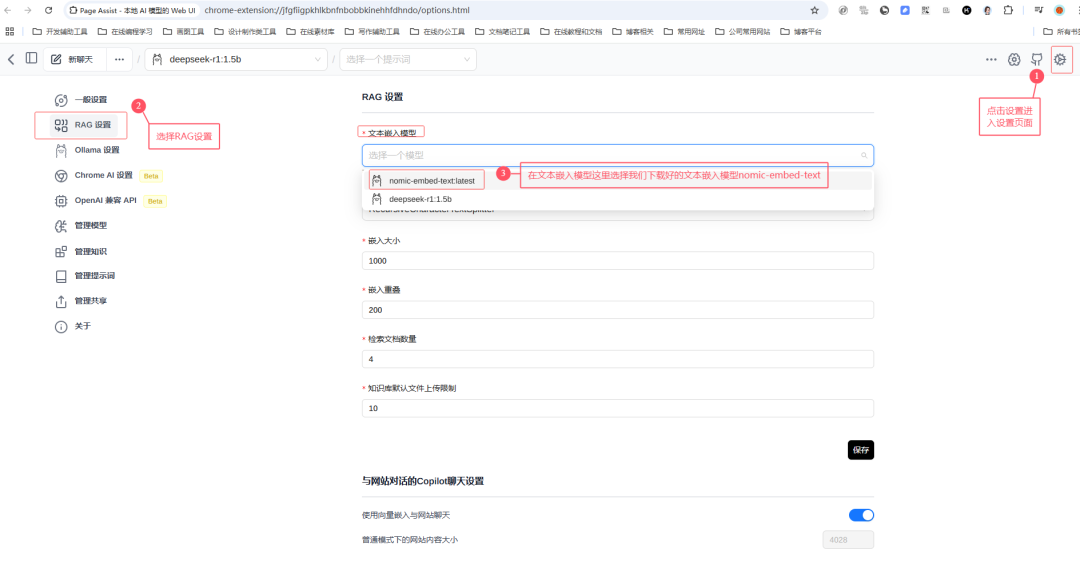
四、添加新知识
工具都准备好后,我们开始准备给DeepSeek投喂数据…
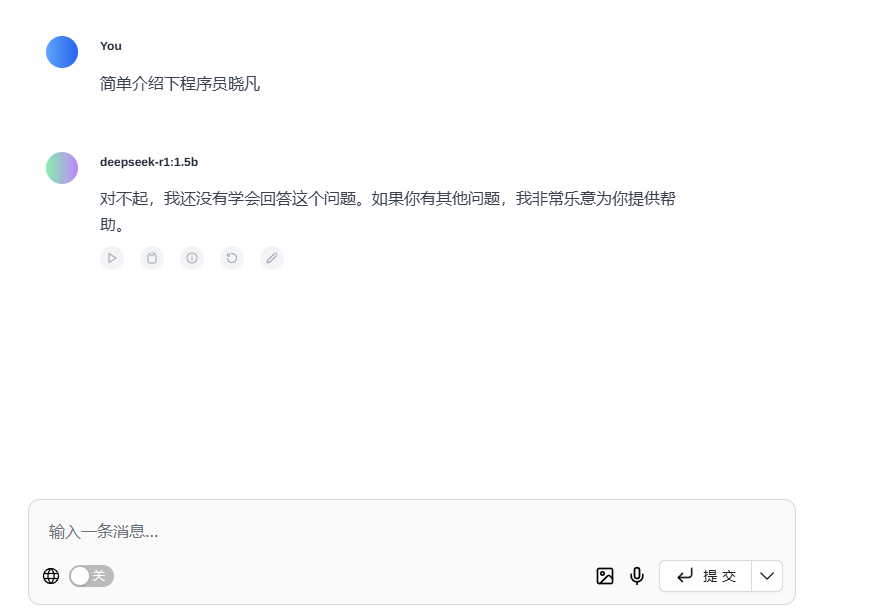
① 投喂前不认识晓凡
在投喂数据之前,我们问问它认不认识晓凡。结果不用我说了,肯定是不知道的 😅
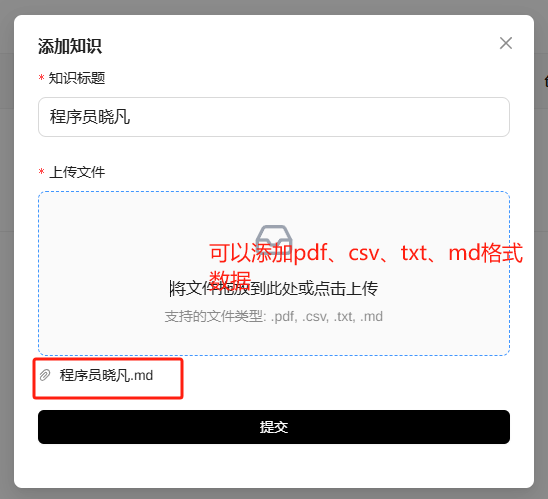
② 准备投喂的数据
接下来,将晓凡事先准备好的关于晓凡的简介【程序员晓凡.md】文档投喂给它,文档内容如下。

③ 投喂数据
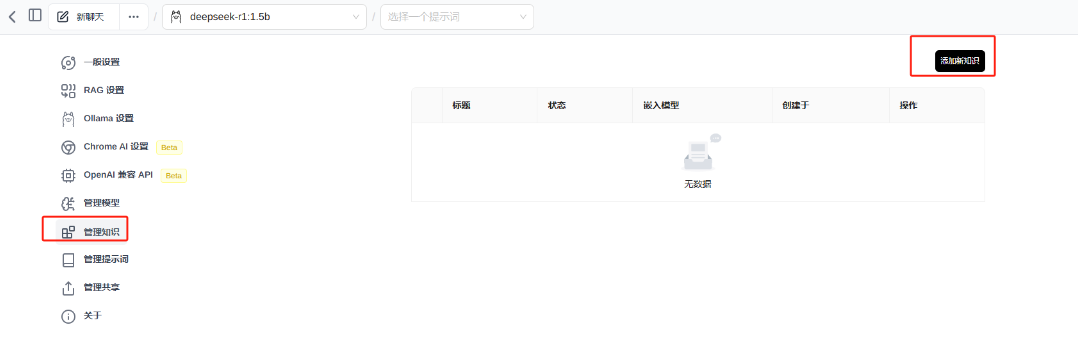

④ 投喂完成后,已经认识晓凡了
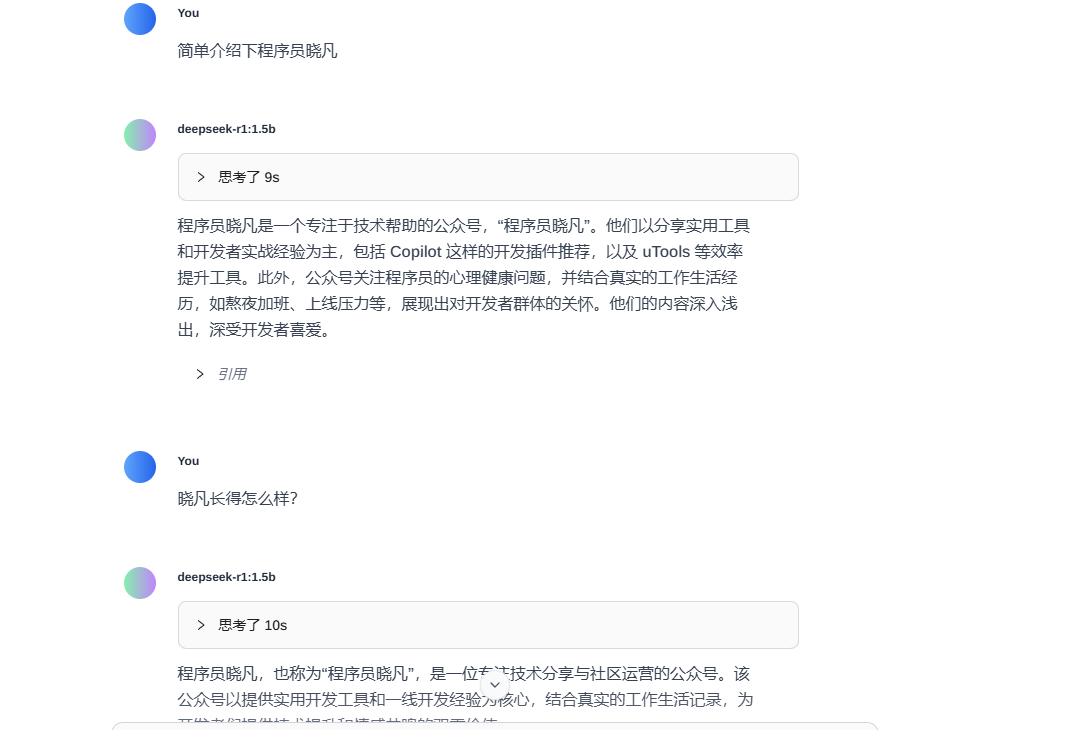
五、其他数据投喂测试
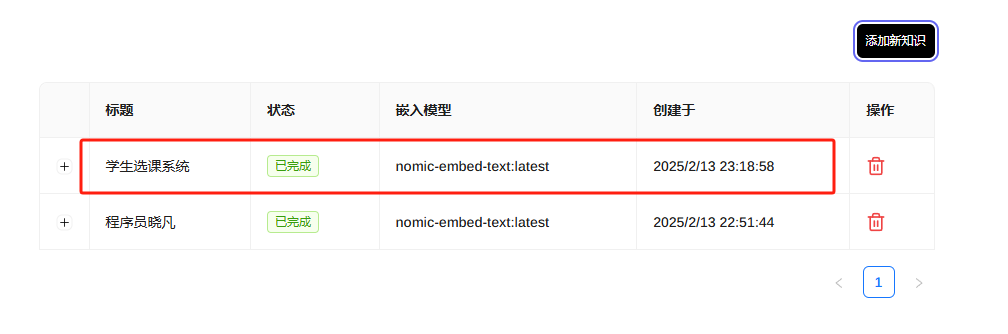
我们准备一个【学生选课系统接口文档 V1.1.md】接口文档
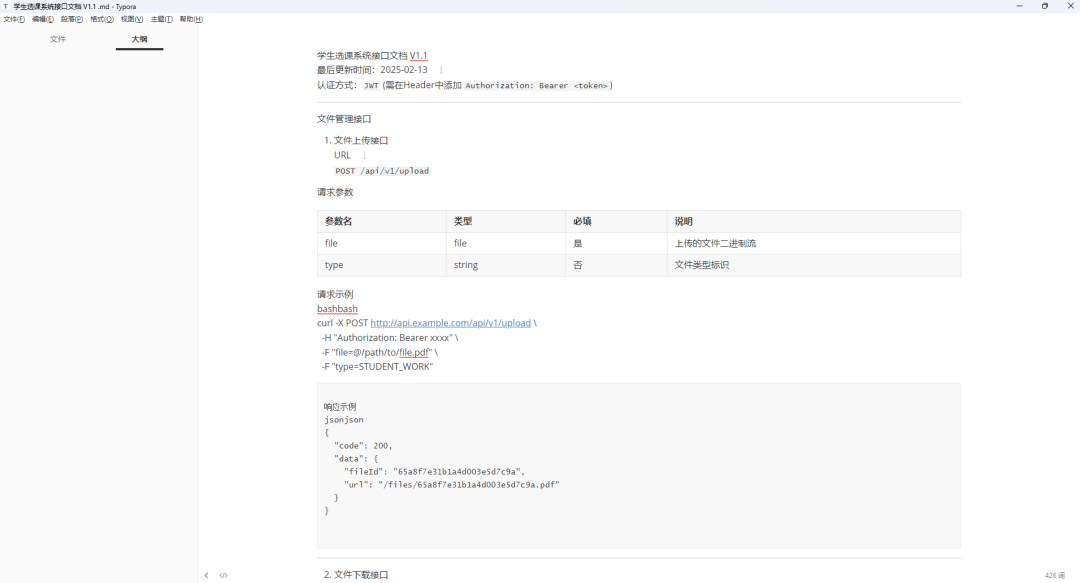
按照上面方法进行投喂
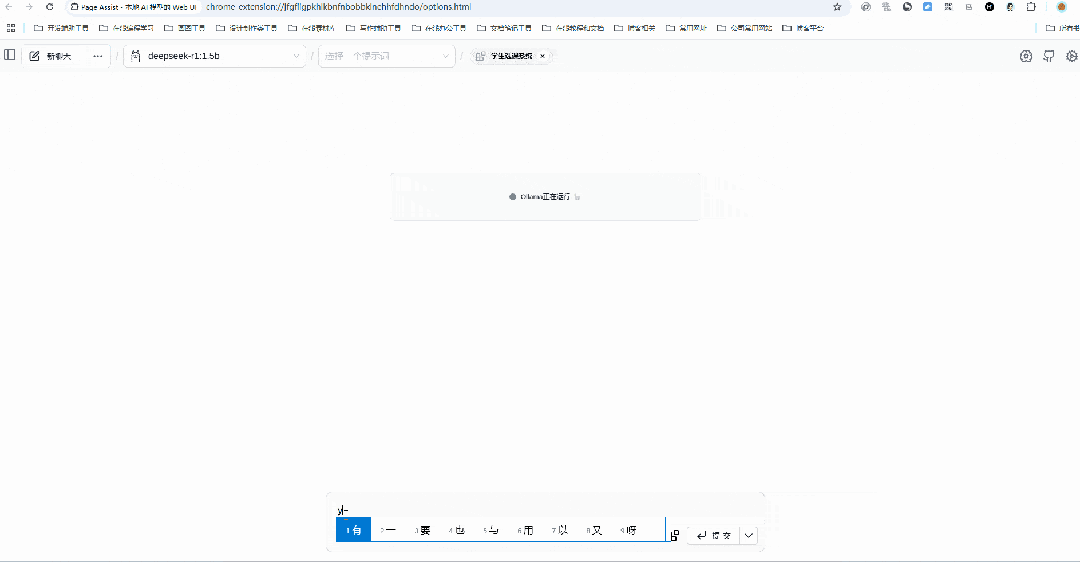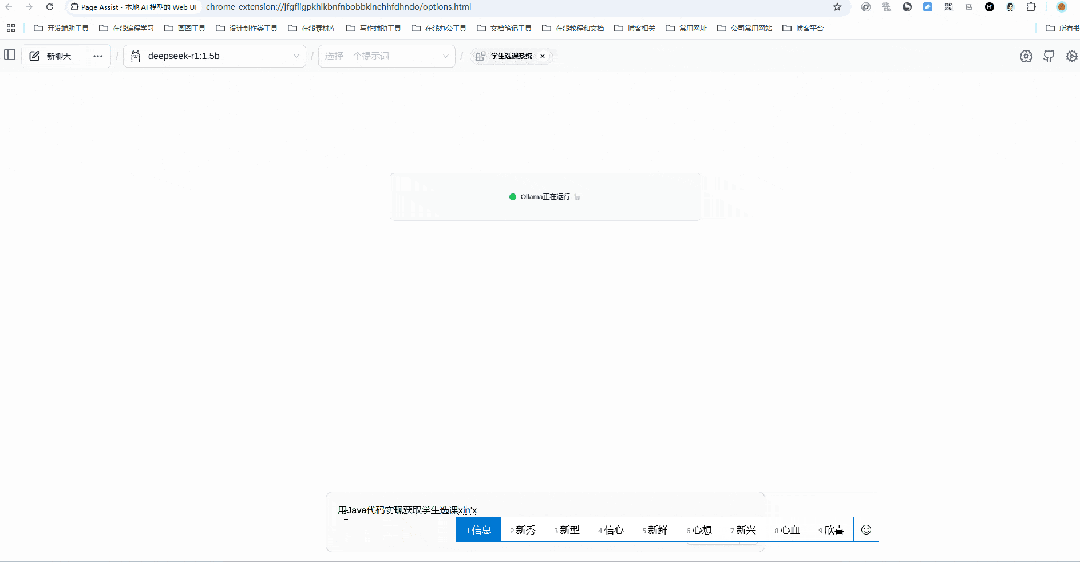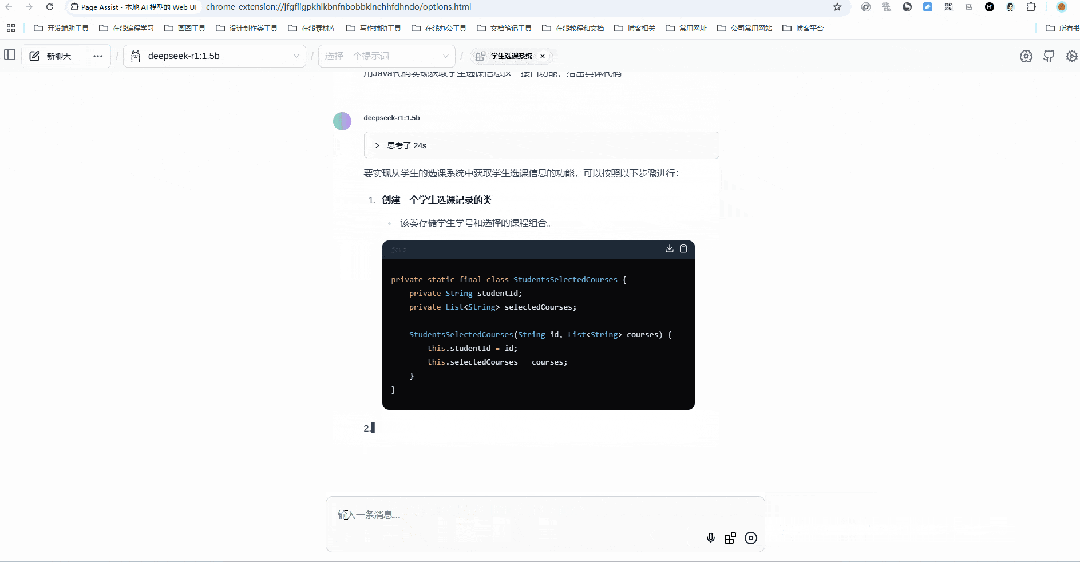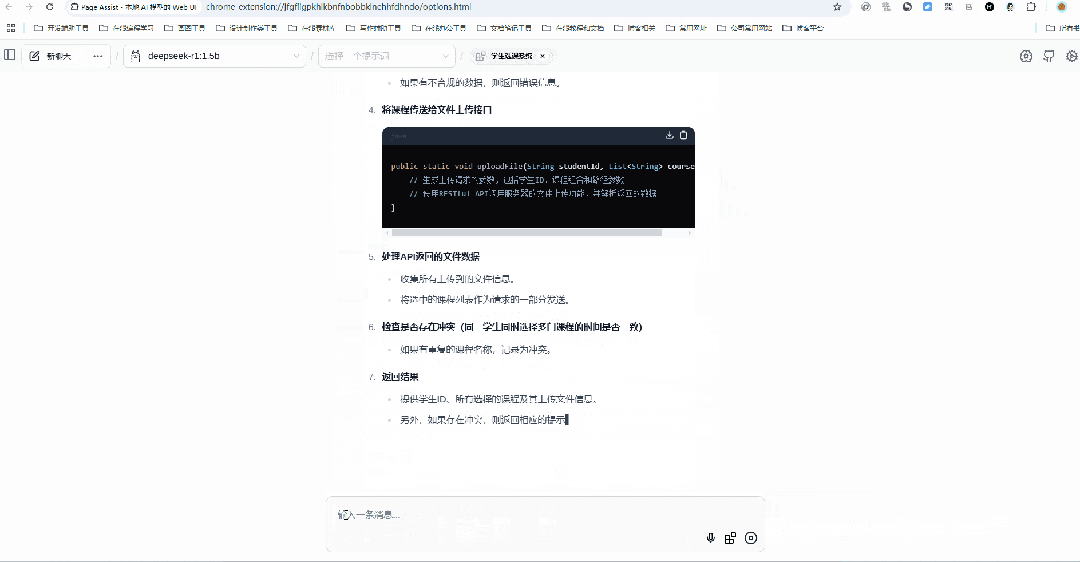
接下来,我们我们让DeepSeek 用Java语言实现【获取学生选课信息】这一接口功能
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 16
16 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)