腾讯元宝接入Deepseek,为什么比其他平台更好用
通俗点讲:这些平台就像是使用同一个大脑(Deepseek-R1 671B)的学生,这些学生被分到了不同的学校(平台),每个学校教学方式(应用开发)不一样,最后教出来的学生特点也不一样。微信有8000万创作者,产生的内容质量会别的平台好一个档次,而其他平台拿不到微信公众号的内容,只能用公域的数据做微调。所以总结下来,AI的发展,不光要基座模型强,开发应用的能力也要足够强,而这一点是中国企业的强项。:
这篇文章主要讲两个点:
1. 腾讯元宝中Deepseek的使用;
2. 讲一下为什么每个平台的Deepseek表现不一致?
腾讯元宝在2 月 13 日发布更新,并宣布 DeepSeek R1 模型联网、满血上线。
使用方式支持APP,网页端。
这里我用网页端测试了一个题目,本山大叔小品《卖拐3》中的脑筋急转弯【过年了一个农夫家有一头猪和一只驴,是先杀猪好!还是先杀驴好!】。
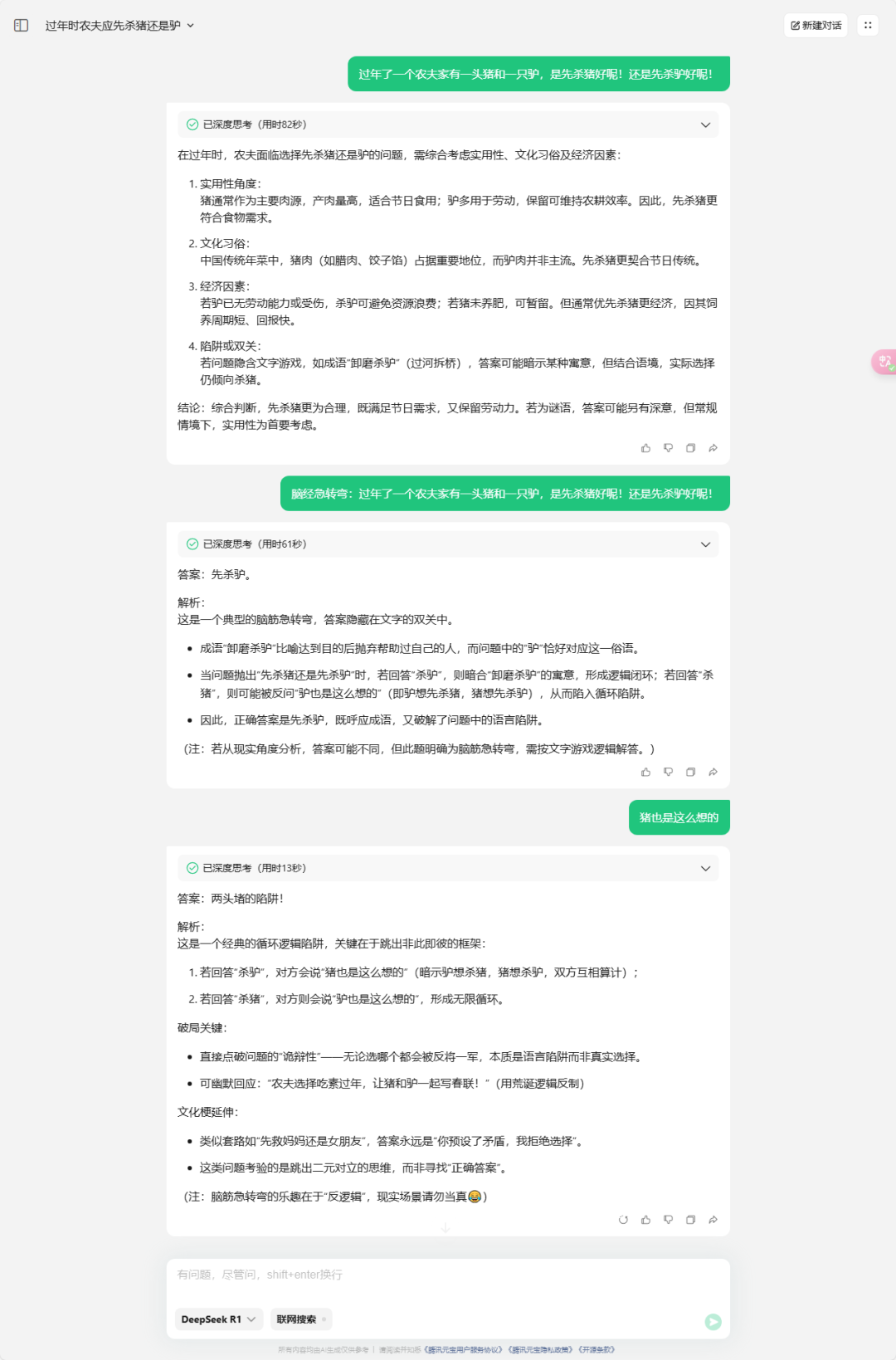
问题输入后回答很快,而且现在已经上线三天了,速度仍然很快。
这说明腾讯的算力非常充足,不会出现其他平台卡顿的情况。
然后是另一个重要功能的测试,联网功能,这里我问了哪吒电影的实时票房;

可以看到,我是11点问的问题,给出的回答中时间截止到了当天10点。
联网搜索时元宝会将引用的文章链接也给出来。
这样做的好处是可以避免“AI幻觉”,让用户得到数据可以溯源验证。
对于数据准确性有要求的行业,这一点非常重要。
并且,Deepseek官网也目前没有这个功能。

体验了三天,进行了7次对话,20次问答。
综合体验,非常强。
是无限接近甚至超过官方的一个平台。
其他的平台可以选择放弃掉了,
纳米搜索只能在移动端使用,
秘塔搜索的回答更偏向公文写作,对话操作页面比较繁琐,
POE每天限次数、要收费。
其他用API接入的方式套路太多,要注册,要实名,部署也很麻烦。
接着讲第二点
同样部署的是Deepseek 671B模型为什么每个平台的表现不一致,响应速度和答案质量都不一样。
拿这四个平台举例,
纳米搜索:有360浏览器的底子在,各种问题都能答个差不多
秘塔搜索:很明显偏向学术研究,其他问他不太行
钉钉:适用于企业场景如数据分析、流程优化、会议纪要生成等
元宝:依赖于微信生态,公众号文章的质量非常高,各种问题的回答都不错
而为什么不一样,就要从大模型应用的开发过程来讲了,
注意:是大模型应用,不是大模型的训练
这个是拿到基座模型后做应用开发时要经历的步骤。

概括的讲,大公司要让自己的大模型产品给大量的网民使用,拿到基座模型后要经历三个阶段

微调:使用不同的参数给大模型投喂过滤后的数据
应用功能开发:检查用户的输入,分析用户的特征,检查给用户输出,过滤敏感词,
部署:提高GPU利用率,减少推理时占用的显存
通俗点讲:这些平台就像是使用同一个大脑(Deepseek-R1 671B)的学生,这些学生被分到了不同的学校(平台),每个学校教学方式(应用开发)不一样,最后教出来的学生特点也不一样。

所以总结下来,AI的发展,不光要基座模型强,开发应用的能力也要足够强,而这一点是中国企业的强项。
同时,一点使用建议是遇到关键问题时,建议多平台交叉验证,就像查资料时多看几本书。
从目前接入Deepseek的平台实际表现来看,表现优劣各不相同,但要说体验最好的,我觉得就是元宝,无论是软件的交互还是模型的调教。
而元宝为什么会比其他平台表现好?
我认为,
最核心的点是:数据,微信有8000万创作者,产生的内容质量会别的平台好一个档次,而其他平台拿不到微信公众号的内容,只能用公域的数据做微调。
借用N多名人说过的话,
“数据是21世纪的石油和金矿”
技术上的差距可以弥补,数据才是每个公司的护城河。
而数据本身来自于用户,最终要用之于用户。
如何使用数据,
我说,
向前走是时代与科技做的选择,
而谋利还是谋幸福是人类自己要做的选择题。
END

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)