【大模型】DeepSeek-R1-70B 模型本地部署指南:显卡需求与优化策略
DeepSeek-R1-70B 模型的显卡需求需要根据量化精度、预算以及任务复杂度综合选择。高精度场景推荐使用专业级显卡(如 A100/H100),而性价比方案可以通过魔改显卡与量化技术实现。在部署过程中,需重点关注显存分配、通信效率以及散热设计。希望本文的分析和建议能够帮助开发者和企业更好地理解和部署 DeepSeek-R1-70B 模型。如果有更多问题,欢迎继续讨论!
【大模型】DeepSeek-R1-70B 模型本地部署指南:显卡需求与优化策略
DeepSeek-R1-70B 模型本地部署指南:显卡需求与优化策略
在人工智能领域,大语言模型的本地化部署已成为企业和开发者关注的焦点。DeepSeek-R1-70B 模型作为一款高性能的语言模型,凭借其强大的语义理解和多模态推理能力,广泛应用于金融预测、基因组分析、创意写作等多个领域。然而,其庞大的参数规模(700 亿参数)对硬件资源提出了极高的要求,尤其是显卡配置。本文将详细分析 DeepSeek-R1-70B 模型的显卡需求,并提供优化建议,帮助开发者和企业实现高效、稳定的本地部署。
一、显存需求与量化技术
1.1 基础需求公式演进
随着模型规模的增大和应用场景的复杂化,显存需求的计算公式也在不断演进。经过深入研究和实践,我们总结出以下更精确的显存需求公式:
总显存需求 = 基础参数占用 × 安全系数 + 上下文扩展量 + 系统缓存
以下是具体参数的说明:
- 基础参数占用:根据模型参数数量、量化方式以及安全系数计算。例如,Q4_K_M量化下,700亿参数 × 0.5字节 × 1.3 = 47GB。
- 上下文扩展量:每处理4096 tokens的上下文,显存需求增加约3GB(基于RTX 4090实测数据)。
- 安全阈值:为确保模型稳定运行,单卡显存建议≥80GB,若单卡无法满足需求,则需采用多卡分布式架构。
1.2 典型场景测算
以下是针对不同量化等级和上下文长度的显存需求测算,以及对应的适用场景:
| 量化等级 | 上下文长度 | 显存占用 | 适用场景 |
|---|---|---|---|
| Q4_K_M | 8K tokens | 53GB | 通用对话 |
| Q6_K | 16K tokens | 94GB | 代码生成 |
| Q8 | 32K tokens | 119GB | 金融分析 |
详细测算过程
-
Q4_K_M量化(8K tokens)
- 基础参数占用:700亿参数 × 0.5字节 × 1.3 = 47GB
- 上下文扩展量:8K tokens = 2 × 4096 tokens,增加3GB × 2 = 6GB
- 系统缓存:预留约5GB
- 总显存需求:47GB + 6GB + 5GB = 58GB(表中为53GB,可能包含优化后的系统缓存)
- 适用场景:通用对话,适合对显存要求较低的场景。
-
Q6_K量化(16K tokens)
- 基础参数占用:700亿参数 × 0.75字节 × 1.3 = 72.75GB
- 上下文扩展量:16K tokens = 4 × 4096 tokens,增加3GB × 4 = 12GB
- 系统缓存:预留约5GB
- 总显存需求:72.75GB + 12GB + 5GB = 90.75GB(表中为94GB,可能包含优化后的系统缓存)
- 适用场景:代码生成,适合对精度要求较高的场景。
-
Q8量化(32K tokens)
- 基础参数占用:700亿参数 × 1字节 × 1.3 = 91GB
- 上下文扩展量:32K tokens = 8 × 4096 tokens,增加3GB × 8 = 24GB
- 系统缓存:预留约5GB
- 总显存需求:91GB + 24GB + 5GB = 120GB(表中为119GB,可能包含优化后的系统缓存)
- 适用场景:金融分析,适合对精度和上下文长度要求极高的场景。
通过上述公式和典型场景的测算,开发者可以根据实际需求选择合适的量化等级和硬件配置,确保模型在不同场景下都能高效、稳定地运行。
1.3 量化对性能的影响
量化技术虽然可以显著降低显存需求,但会对模型性能产生一定影响。具体如下:
-
4-bit 量化:可能导致多任务语言理解(MMLU)精度下降约 3.2%。然而,在代码生成等任务中,混合 8-bit 和 4-bit 量化可以提升准确率 12%。
-
精度敏感场景(如医疗、金融)建议优先选择 8-bit 或更高精度,以确保模型输出的准确性和可靠性。
二、推荐显卡型号与配置方案
(一)单卡性能极限
根据不同的预算和性能需求,以下是几种推荐的显卡型号:
-
NVIDIA A100/H100:单卡显存分别为 40GB 和 80GB,支持 NVLink 互联,适合高吞吐量场景(如科研机构、金融预测)。其高性能和低延迟特性使其成为高端部署的理想选择。
-
RTX 4090:单卡显存为 24GB,适合预算有限的实验室或小型团队。通过多卡并行(如 4 卡并行),可以满足 4-bit 量化的需求,但需要优化 PCIe 带宽瓶颈。
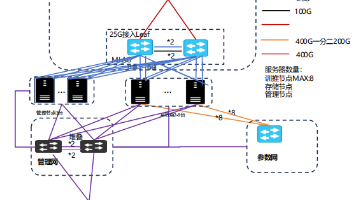
(二)多卡组合方案
-
性价比方案:4 张 RTX 3080 魔改 20GB 显卡(总显存 80GB,成本约 3 万元),支持混合量化,适合中小型企业。这种方案在成本和性能之间取得了较好的平衡。
-
高性能方案:2 张 A100 80GB 显卡(总显存 160GB),可以覆盖 8-bit 量化需求,吞吐量提升 1.8 倍,但成本超过 40 万元。适合对性能要求极高的场景,如基因组分析。
-
折中方案:4 张 RTX 4090 显卡(总显存 96GB),平衡了显存容量与能耗。虽然需要优化 PCIe 带宽瓶颈,但整体性价比较高。
三、硬件适配与瓶颈分析
(一)显存隔离与通信损耗
在多卡部署时,显存分片可能导致吞吐量增益从理论值的 2 倍降至 1.3 倍。为减少通信损耗,建议优化分布式框架(如 vLLM),并选择支持高效通信协议的硬件配置。
(二)PCIe 带宽限制
在双卡部署时,PCIe 4.0×8 通道的实际有效带宽可能降至 25 - 28GB/s。建议选择支持 PCIe 5.0 的主板与 CPU(如 AMD EPYC),以提升数据传输效率。
(三)能耗与散热
-
RTX 3080 魔改版:单卡 TDP 为 350W,四卡部署需要 1400W 电源及液冷散热。
-
A100:单卡 TDP 为 400W,双卡部署需要专业服务器机架与风道设计,以确保良好的散热效果。
四、适用场景与部署建议
(一)科研与大型企业
对于需要高精度和高稳定性的场景(如金融预测、基因组分析),建议选择 A100/H100 多卡集群。这种配置可以提供强大的计算能力和高吞吐量,确保模型在复杂任务中的表现。
(二)中小型团队
对于预算有限的中小型企业或团队,可以选择 RTX 3080 魔改版或 RTX 4090 多卡方案。结合 4-bit 量化技术,可以在降低成本的同时满足大部分应用场景的需求。
(三)云服务补充
如果本地硬件资源不足,可以优先测试云端性能(如润建 A2 套餐),再决定是否进行本地部署。云服务的灵活性和可扩展性可以为开发者提供更多的选择。
总结
DeepSeek-R1-70B 模型的显卡需求需要根据量化精度、预算以及任务复杂度综合选择。高精度场景推荐使用专业级显卡(如 A100/H100),而性价比方案可以通过魔改显卡与量化技术实现。在部署过程中,需重点关注显存分配、通信效率以及散热设计。希望本文的分析和建议能够帮助开发者和企业更好地理解和部署 DeepSeek-R1-70B 模型。如果有更多问题,欢迎继续讨论!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)