七问 Deepseek R1! 用益智谜题强化学习提升数学竞赛水平!
原文:https://zhuanlan.zhihu.com/p/25355823769其实,复现r1的时候。我们脑海里会自然而然涌现以下七个问题:GRPO未必就是最合适的RL算法?RL应该如何调参实现稳定训练?RL数据如何组织,课程学习还有用吗?从Zero开始和冷启动起手,到底有多大区别?为什么不选instruct模型开始RL呢?只要随着RL稳定进行,我们总能观察到输出长度的近似线性增长,那什么时
原文:https://zhuanlan.zhihu.com/p/25355823769
其实,复现r1的时候。我们脑海里会自然而然涌现以下七个问题:
-
GRPO未必就是最合适的RL算法?RL应该如何调参实现稳定训练?RL数据如何组织,课程学习还有用吗?
-
从Zero开始和冷启动起手,到底有多大区别?为什么不选instruct模型开始RL呢?
-
只要随着RL稳定进行,我们总能观察到输出长度的近似线性增长,那什么时候增长是个头?长得快能代表reasoning能力也在快速提高吗?
-
Reflection token在RL训练里的词频变化?越高的词频是否暗示推理能力的变强?该监控哪些词比较好呢?
-
RL有多能泛化?Logic益智题上训练,锻炼出来的思考能力能否有助于数学竞赛水平的提升?
-
接上个问题,如果RL真的learn to learn,那它和传统SFT,RFT的对比?是真的学会了抽象的推理,还是依赖于大量问题模板的死记硬背?
-
自然涌现的语言混杂现象非常迷人,但它真的有助于推理吗?
我们详细解答了以上问题,开源了完整的超参调优经验,RL算法设计,代码数据等等。为了最佳体验,可以去看我们的论文:
论文地址:https://arxiv.org/abs/2502.14768,Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Github链接:Unakar/Logic-RL(https://link.zhihu.com/?target=https%3A//github.com/Unakar/Logic-RL)
我们的Logic-RL团队主要成员,从上次小打小闹的三人组升级到了五人阵容,不过大家还都是大三大四本科生。新来的两位大佬为此工作作出了巨大贡献,特此感谢。
基本现象展示
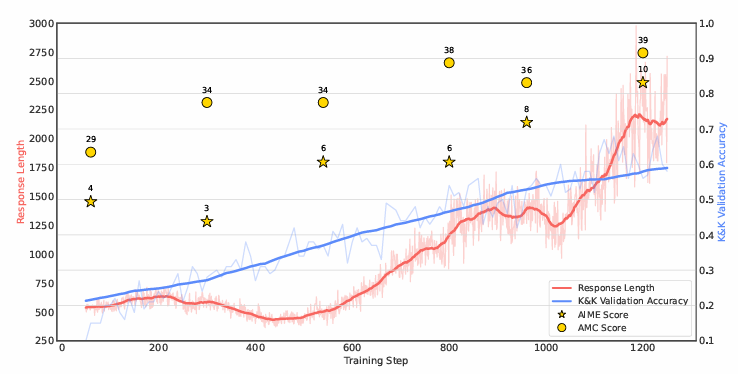
强化学习魅力时刻:仅在程序合成的逻辑益智题(5K)上进行Rule based RL训练。无需任何引导,7B模型自然学会了在某个节点开始,大幅增长思考时间。从初始的500长度,1.2k step后scaling到了2200 tokens,测试集acc也是几乎稳定线性增长,还没有饱和停止的趋势。非常漂亮的曲线!(红蓝双线)强化学习非常魅力时刻:好奇心促使我们测试了一下完全OOD的数学能力:伴随逻辑训练的进行,AIME和AMC的竞赛级数学benchmark正答率也在稳定增长!太意外了,训练数据里甚至不需要出现任何数学数据,AIME相比基线提升125%,AMC提升38%!(黄色散点)
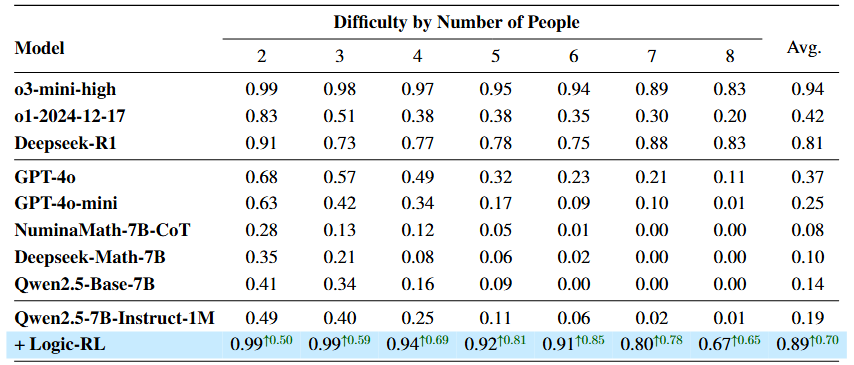
在逻辑题上,我们7B模型性能干碎o1, 与o3 mini不相伯仲,gpt4o就不用比了..(不过,不是fair的比较,毕竟人家也没在这个数据上RL过,看个开心)。
不过证明,纯RL上限极高,要靠传统SFT在逻辑题打o1几乎不可能(下文有RFT实验)
实验设置回顾
为啥不在math上做R1复现?
math问题难度难定义,所需的背景知识混杂,不利于受控实验探究。而且不同问题,所需最短思考时间很难估计到底是多少,对研究输出长度增长实验不友好。我们主要研究rule based RL的实验现象,希望通过受控实验得出一些偏本质性的观察,与经验性的结论。
于是我们转向了完全由程序合成的逻辑益智数据集——判定多人游戏里,到底谁说真话,谁说假话,角色分配是唯一可解的。随着游戏人数增多,问题难度几乎指数级地变难,是一个非常好的难度控制。也利好后续探究课程学习顺序与配比。
此外,也很好合成OOD数据:只要训练集稍微调换一下布尔逻辑式,对换/颠倒一下两个人的表述,就能完全改变答案和推理路径。
选Base模型还是Instruct模型?
当然两个都试了。我们发现,只要合理设置prompt, base模型也能很快学会think-answer的格式,与instruct模型在RL训练里的所有指标(长度增幅,reward,acc, KL) 几乎是一模一样的,非常amazing啊
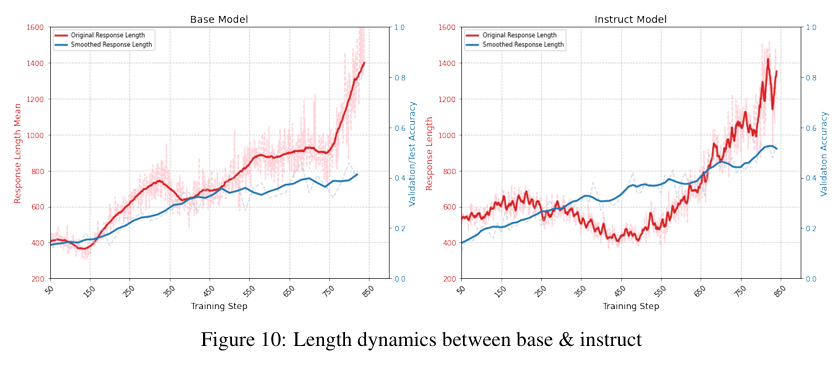
左图base,右图instruct。实际上前期base模型学会scaling thinking time好像还快一点...(此处应有更多实验佐证)
不过instruct模型的acc总是略微高base一丢丢...
看上去 Cold start 只是一个bonus, 不是necessity。(实际上Qwen SFT数据里大概率也没有逻辑题,base/instruct正答率本来就差不多。Qwen2.5 Base实际上是一个很好的起点,该有的基本能力(比如极少量的反思行为)也是有的
所以我们其他实验主要采用了Qwen2.5-1M-Instruct来展示 (指标稍微好看那么一点点~)
RL算法选择
在确保共享参数相同的情况下,多次消融,看上去reinforce++是性价比最高的。下图2是acc曲线(经过滑动窗口平均,所以GRPO蓝线的起点也会低一些,整条曲线看上去都是次于ppo/reinforce++的)
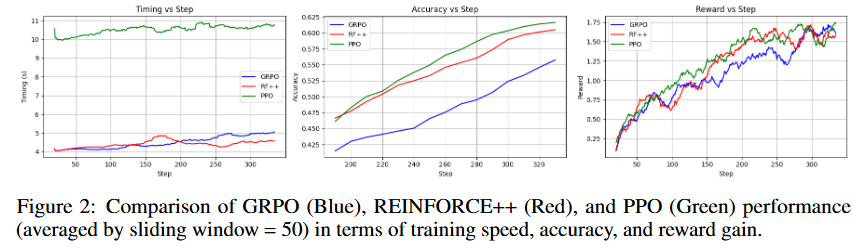
其实follow deepseek math论文,我们也对原ppo/reinforce++做了一点实现上的修改。
修改1:首先是KL loss。经典的RL做法是在reward里逐token算KL
![]()
嗯,我们把它换成了deepseek推荐的kl loss,把它提出来放到actor loss里面,省了点计算
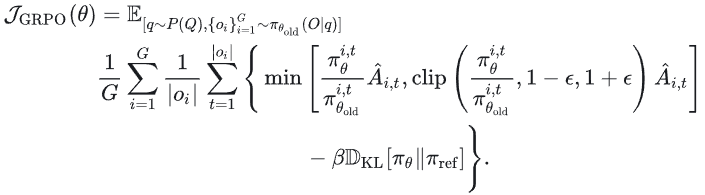
这个KL约束不是特别强,我们kl coef设0.001(试了0.01,很烂),让它稍微稳定一点。
实际上,我们认为,如果有大bacth,大rollout,好的base model startpoint, 应该是可以进一步衰减KL约束的,甚至不妨去掉
修改2:KL估计,经典做法是logp-logq, 不过这样KL估计的非负性无法保证。我们用另一个非负的无偏估计
![]()
好吧,实际上改不改这个,效果都差不多,只是看着舒服一点 --
此外,一点RL调参小经验:
-
ppo里的GAE,lambda和gamma都设成1。当时我看openrlhf里lambda都是1,还觉得非常奇怪,于是试验了衰减0.9,0.95.0.995..都不行,训练很快崩溃。转头结合PPO原理和LLM训练过程想一想,好吧,这样超参设置其实很合理
-
RL对超参非常敏感。actor学习率在3e-7,4e-7, 5e-7,曲线行为差异很大 (我们setting里4e-7始终一枝独秀,傲视群雄)。建议多跑网格搜索!
-
Max length也很重要,前期如果设的很大,很容易频繁触顶而崩溃
-
有卡就狠狠堆rollout吧,这样value估计会稳定很多
-
无论如何,RL稳定性都是最重要的!只要训练能正常进行,acc和length曲线基本就能保持上涨势头。训练stable是一切的前提
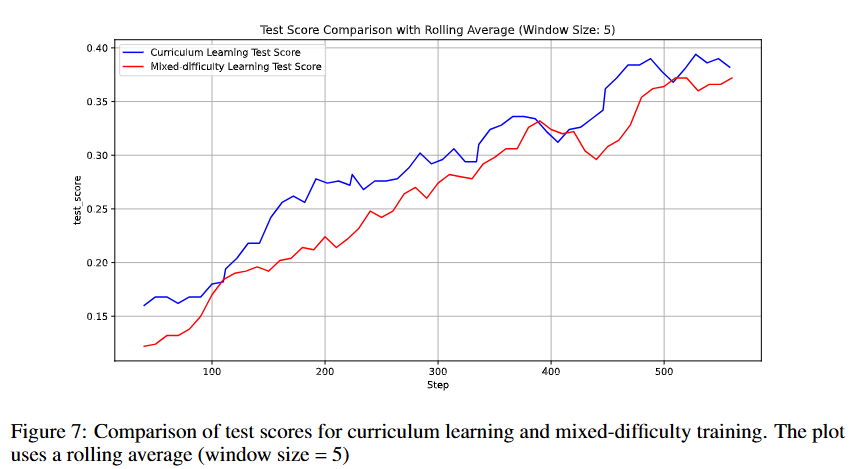
此外,课程学习的数据设计似乎还是有用的。我们固定数据混合ratio,调控不同难度的先后出现顺序,发现循序渐进,每个stage都比上次难一点,对RL学习收敛性能很有助益:
Rule based reward设计
我们是反复观察模型输出,与其斗智斗勇里不断完善我们的rule的,代码可以参考我们的github:https://github.com/Unakar/Logic-RL/blob/main/verl/utils/reward_score/kk.py
实际上,看到很多开源复现的rule都不是很严苛,应该会出现各种匪夷所思的hack才是。比如我们观察到,如果仅依赖把thinking过程放<think> tags里,answer结论放<answer> tags里的prompt,模型会用奇怪的方式骗分。如果说人类施加的约束是一座石山,而AI就是一株倔强的小草,总能从不起眼的石头缝里觅到自己的出路
-
跳过think, 直接回答answer: 建议在prompt里最后位置手动添加一个<think>再让模型输出
-
answer里多次回答,穷举答案骗分
-
在<think></think> tags里只说thinking process here,(或者简单复述一遍题目)然后就自作聪明以为think完了
-
</think>到<answer>不连贯,还有别的词
-
<answer>到一半,忽然又开始说<think>...
-
结论明明是对的,但是格式乱七八糟,提取失败
以上是部分观察。format reward建议严格控制special tag tokens的出现频次为1,依次出现,且</think><answer>索引连贯。(模型有段时间还会自创tag,冒出来<summary><verify>这种东西,非常好笑)
Answer reward设计:如果答对+2,提取成功但答错 -1.5, 提取失败直接 -2
建议狠狠检查模型输出,务必制止任何hack行为,编写严苛的rule。这样,模型大概会在前期反复探索format边界,摸透后才会放心地去scaling thinking time。
有趣的观察
Reflection tokens词频和reasoning的关系?
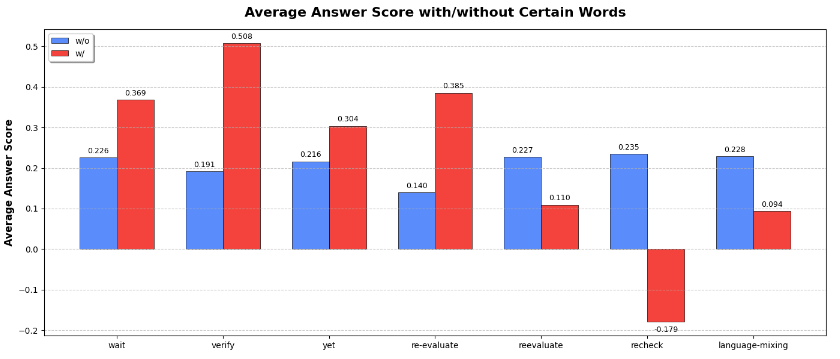
检查 wait, verify, re-evaluate等等词在<think>里,如果出现和不出现,各自对应的answer accuracy
-
当'wait,' 'verify,' 'yet,' and 're-evaluate' 这些词出现的时候,reasoning分数明显更高
-
但recheck出现的时候,都是负分,看来,不是所有我们以为的reflection token都能涨点。recheck可能表示模型总是举棋不定,更大概率犯错
-
re-evaluate 和 reevaluate完全不一样....前者涨,后者跌。我们检查了原始模型输出,发现说前者的频次本身就很高,而后者几乎不出现。似乎模型对自己爱说的词比较顺口呢..
有趣的language mxining现象。这里语言混杂,指英文里掺杂中文,可在论文appendix里找到不少例子。语言混杂总是削弱性能,犯错的几率大大增加。所以我们还是建议format里加一个语言一致性惩罚,这样可读性也更好一点
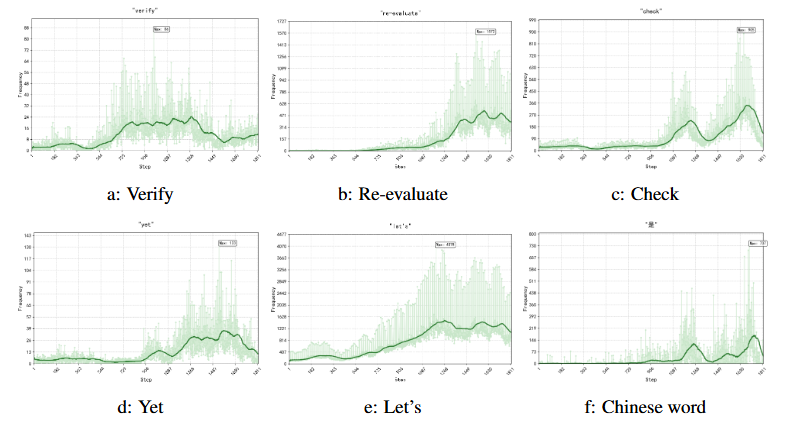
我们统计了前1800step里,各词频变化。RL总是会倾向于有增加reflection tokens词的频率(verify, check),还有语气舒缓词(let's, yet, now that..),观察模型输出,确实越来越不markdown了,更加的口语化
此图也能佐证,似乎确实不存在忽然的顿悟时刻——所谓的aha moment。这些词模型本来就会说,前10 setp的frequnecy就不是0 (对qwen 2.5 series是这样)
RL强大的OOD性能
如前所述,我们只在5000条益智逻辑题上进行RL答案训练,测一下绝对OOD的性能涨点:
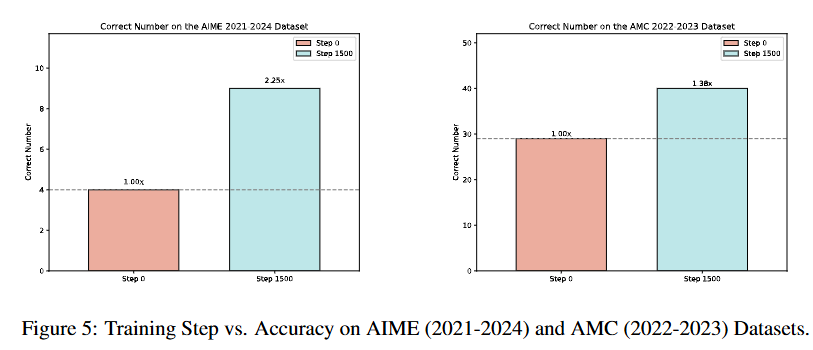
啊哈哈!非常amazing啊!
选取了五年的AIME数学竞赛合集消除可能的偏差。(实际上我们多次测试,也没有发现什么方差波动,这种题,模型会就是会,不会就是不会,初始acc始终是4题,不多不少)
各自涨幅125%和38%!完全不用任何数学数据!
检查输出,也没有发现到底泛化性从何而来:之前答对的,RL后还是对的;新答对的题,和logic puzzle看着半毛钱关系也没有——似乎就是锻炼了模型的心智,先思考再回答,解题更加成熟稳重了
相比之下,用SFT在ood的AIME上就完全涨不了点,(域内的logic accurcay也涨不了多少)
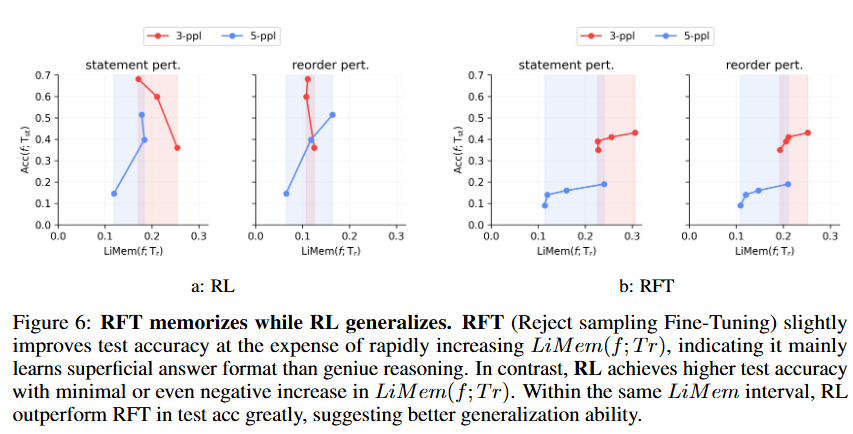
对比实验表明,SFT(或者更贴近模型ditribution的RFT,拒绝采样微调)总是倾向于背诵CoT数据,涨点效率很低,毋宁谈泛化了。而RL在横坐标的记忆分数上几乎没涨(有的还是负方向涨幅),而纵坐标一路直升测试集acc
看上去,SFT以拟合训练数据为代价,换取测试集上log曲线的缓慢性能增长;RL几乎不拟合数据,以指数曲线增长性能
SFT memorizes while RL generalizes!
越长的length,reasoning就越好吗?
只要RL在稳定训,输出长度就该自然而然地增长,但是训练过程里,希望把长度涨幅作为reaoning指标,不是很成熟
一个反例:
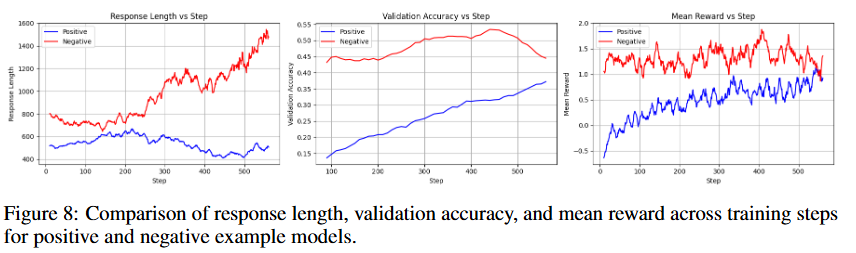
一段区间内,红线length快速增长,但acc不见得同比增长;蓝线吞吞吐吐,但acc和reward涨幅喜人
只能说,length增加是RL training dynamics基本副产物,两者相关,但不是training time衡量reasoning的有效指标
实际上,最优路径应该是正确且最短的路径。Token efficiency肯定越高越好。如果一直scaling length,后期可能会频繁长度触顶而崩溃。长度控制和缩减,可能是未来很有趣的一个方向。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 27
27 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)