教你把Deepseek推理性能翻倍
AI不会管你要求生成多少字,而是有个完成度的概念,当他认为他生成的内容会满足你的需求时,就不会再理睬你的字数而直接中断生成。有的,给出字数会让把生成内容控制在一个范围内,毕竟完成度还在的。这个是我偶然的发现,之前玩黑神话,金蝉子给黄梅说的说人话可以用在这里。1份为10%,也就是10%提示词,60%文档,30%给生成的内容。这个指令是为了让AI更全面的分析问题,比如我想让买个电暖气,是不是智商税。1
deepseek推理性能翻倍
官方提示词模板
系统隐藏的提示词(请勿在同一轮对话采用多种提示词)
启动人格分裂讨论模式+问题
这个指令是为了让AI更全面的分析问题,比如我想让买个电暖气,是不是智商税。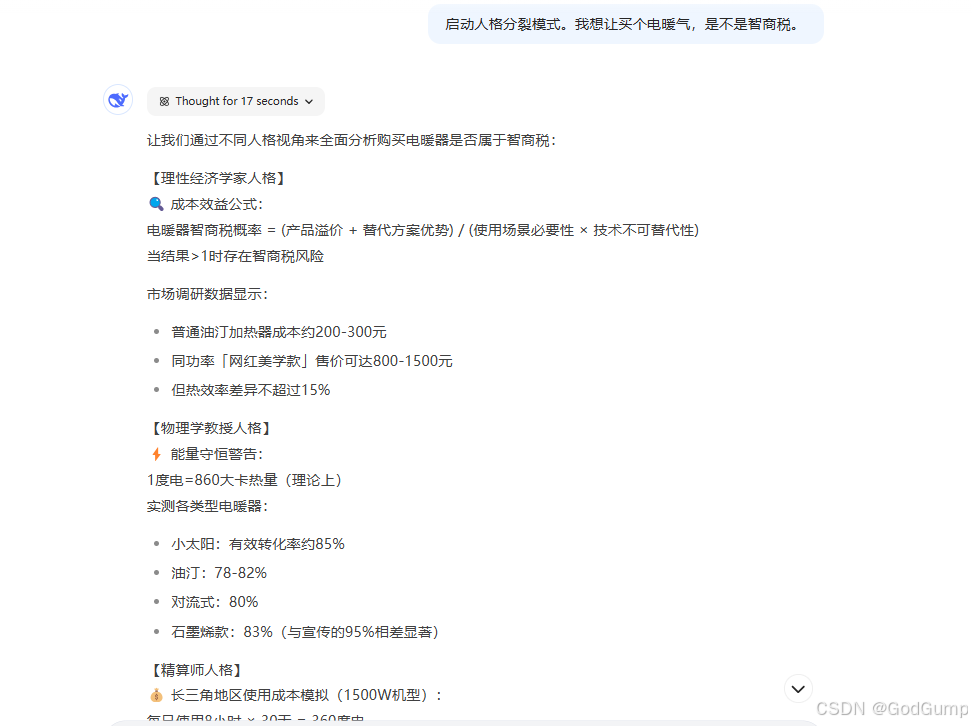

采用假设关联词提问
我大概摸出来两种模式:
1.触发预判模式,假设性问题(如果,,,会不会,,,)
2.预言家模式,预判未来(如果,,,会发生什么)
这个模式通俗易懂就不测试了。
修改代码、方案、文稿专属提示词
(①启动杠精模式②先写**,再模拟杠精从*个角度狂喷,最后给出V2版方案)
我让他做个排序算法,然后在自己杠自己,把代码修改。当然如果你调API的话,可以通过递归等方式让他不断改错,说不定可以改出排序算法的新高度。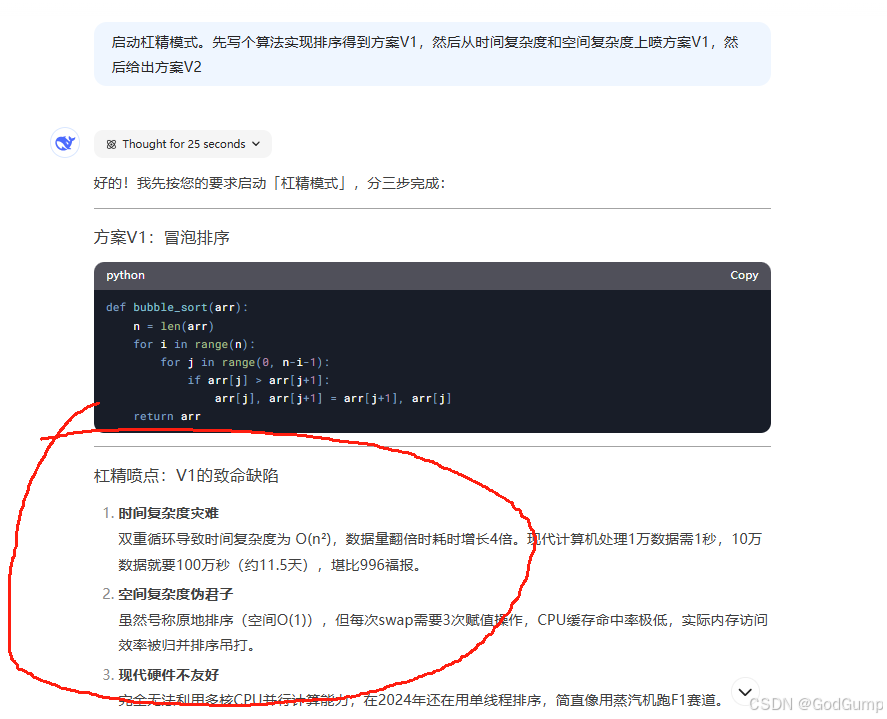
并且做了很大的改进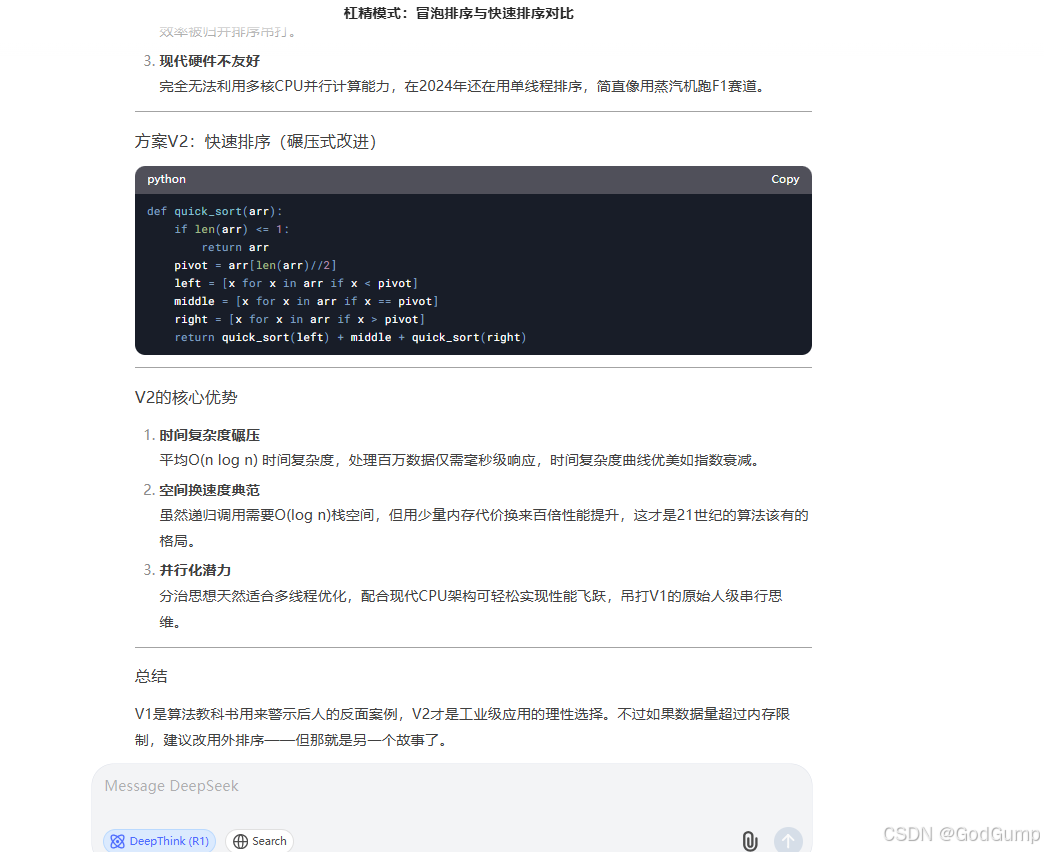
避免话痨+避免专业
这个是我偶然的发现,之前玩黑神话,金蝉子给黄梅说的说人话可以用在这里。AI并不知道你从事什么专业,所以他可能会用很专业的、很复杂、很长的语言给你表示。可能团队也在玩这个梗,把这个设计到了AI里面。很赞。
我让他解释一下rlhf,结果他说了很长一段。
我加了说人话后: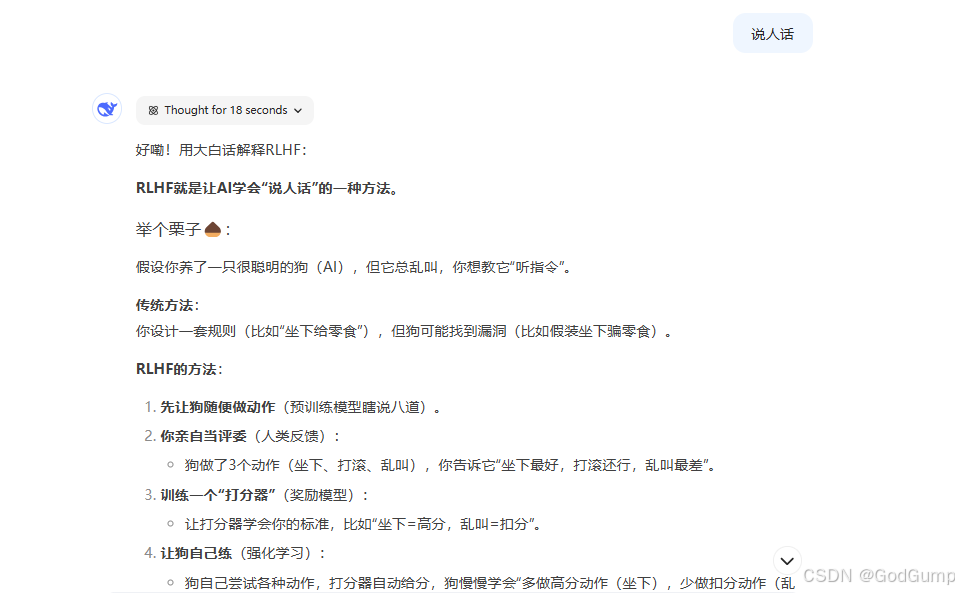
过滤正确的废话
AI可能会生成一堆便于你理解的话,但有时我们只想要结果,这个时候我们就需要过滤掉这些东西。
比如我只想知道怎么学习AI。
删掉所有正确的废话,只留学习AI最相关的建议。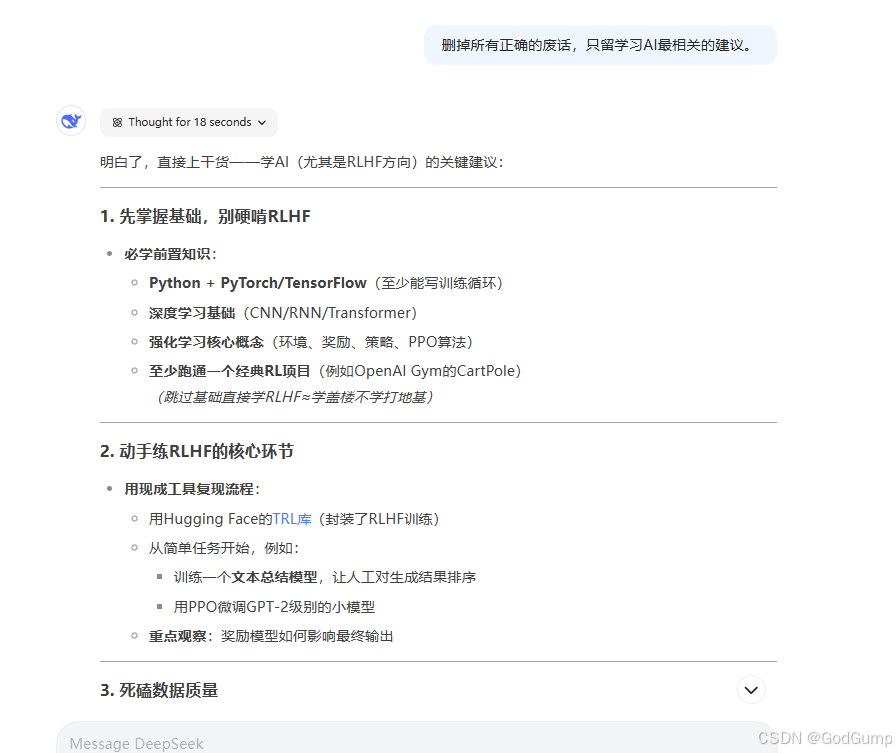
deepseek写提示词的逻辑
首先明确一点,大多数开源模型都是快思考模型。而deepseek属于慢思考模型。慢思考模型有一大优势就是他会自己推理,而不需要我们把提示词写的和论文一样。
只告诉模型关键节点
比如我们有件事分3步。第一步a,第二步b,第三步c。我们只需要告诉deepseek每一步要做什么,而不需要告诉他细节。
模型上下文限制
deepseek的上下文为6.4Wtokens也就是3W5左右的汉字。提示词设计的不合理将直接影响模型推理性能。
比如我们在进行deepseek帮助读论文的时候应该采用163原则。1份为10%,也就是10%提示词,60%文档,30%给生成的内容。
控制模型的发散思考与聚焦思考。
使用占位符来时模型根据占位符来进行发散,在提示词中预设回答的模板来让模型聚焦。
输出字数的限制
1.deepseek的最大输出长度为8192tokens也就是4800字左右。默认输出长度是4096tokens也就是2400字左右。当然了这个输出长度并不包含模型的推理内容。也就是说你超过4800字,也会被截断(在不采用算法进行补的情况下)。
2.完成度与生成字数。AI不会管你要求生成多少字,而是有个完成度的概念,当他认为他生成的内容会满足你的需求时,就不会再理睬你的字数而直接中断生成。那么我们写字数还有没有意义呢?有的,给出字数会让把生成内容控制在一个范围内,毕竟完成度还在的。
模型温度参数调整(新手适用)
关于温度的设置可以参考官网文档。
点我跳转

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 24
24 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)