一文搞懂 DeepSeek - DeepSeek-R1 训练过程
最近这一两周不少公司已开启春招。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
最近这一两周不少公司已开启春招。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结如下:
喜欢本文记得收藏、关注、点赞
技术交流

DeepSeek-R1的亮点在于其出色的数学和逻辑推理能力,这使其区别于一般的通用大语言模型(LLM)。DeepSeek-R1的训练目标是达到与OpenAI o1相似的推理能力,但技术路线有所不同。R1并没有采用o1 test-time compute(测试时计算),而是注重通过强化学习(RL)和监督微调(SFT)的结合来提升模型的性能。
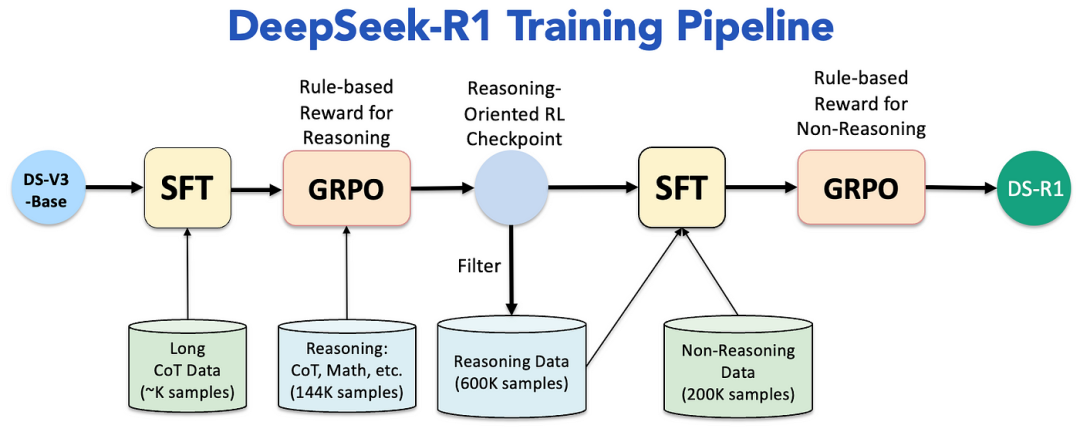
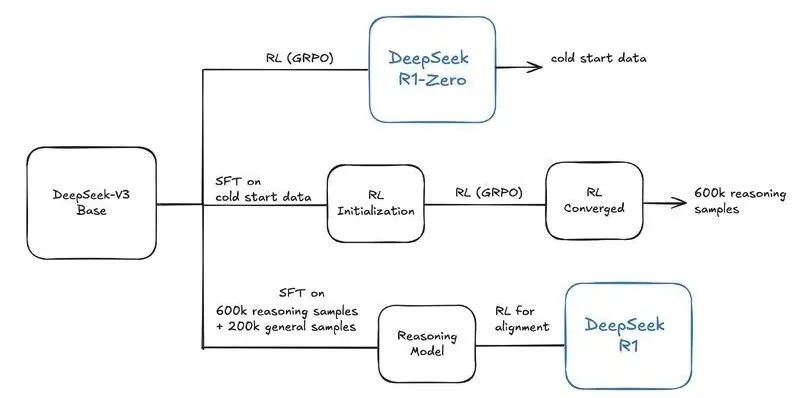
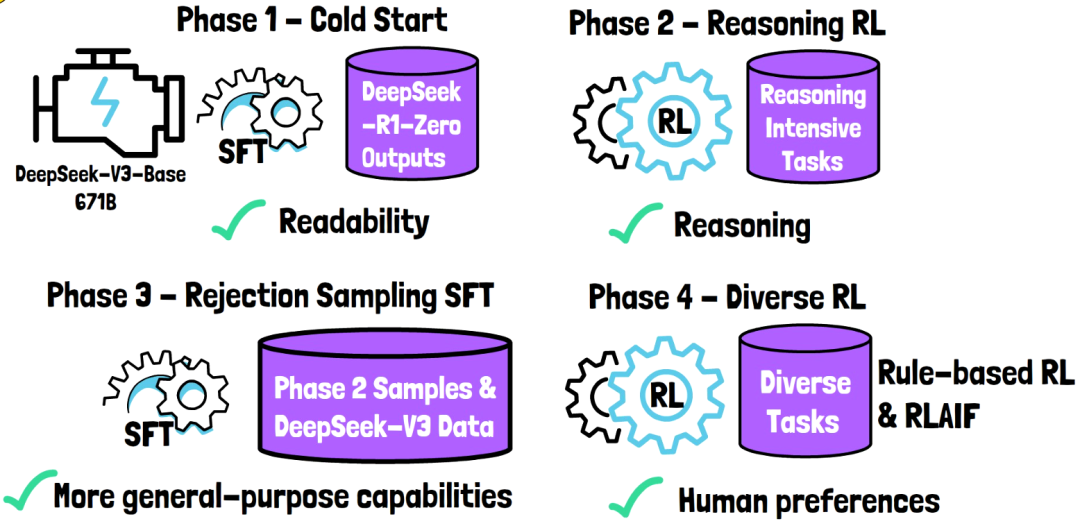
DeepSeek-R1训练过程是一个复杂但高效的过程,旨在通过多个阶段的训练,提升模型的推理能力和对齐人类偏好。整个训练过程包括冷启动监督微调、面向推理强化学习、拒绝采样和多领域监督微调以及全场景强化学习四个阶段,每个阶段都对模型的推理能力进行了针对性的提升。
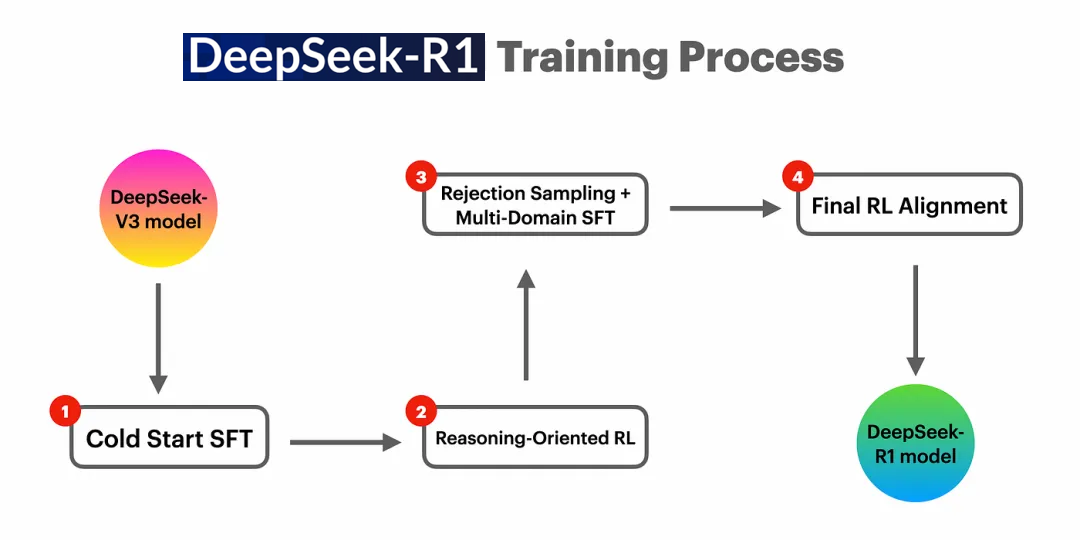
一、冷启动监督微调
第一阶段:冷启动监督微调(Cold Start SFT)是什么?冷启动监督微调通过准备高质量的长链思维数据(CoT Data)并对基模型(DeepSeek-V3 Base)进行监督微调(SFT),为模型提供了初始的规范化推理能力。
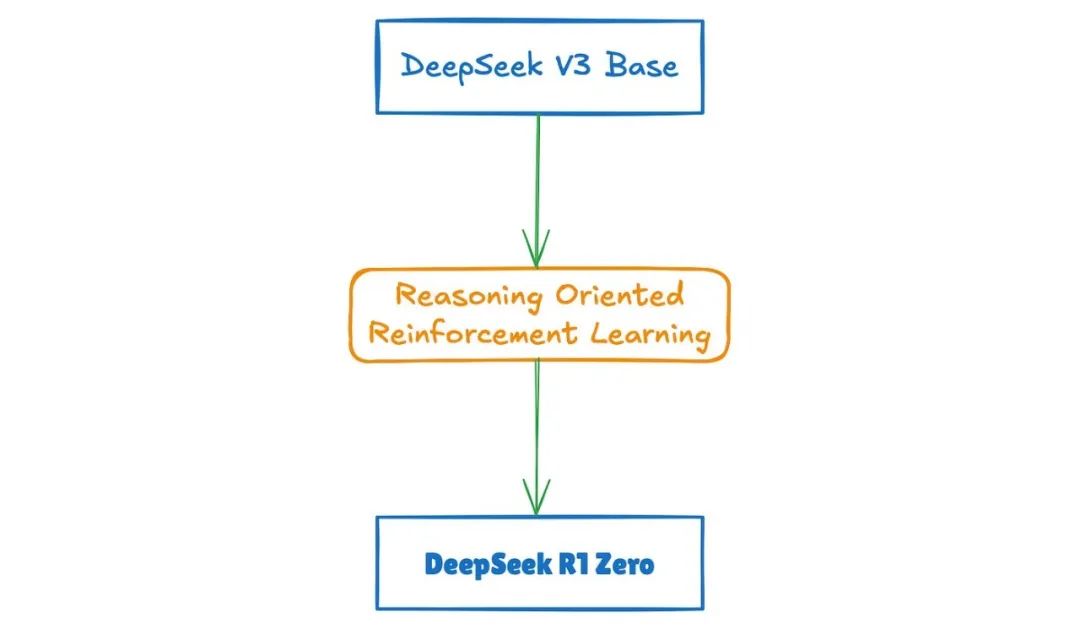
为什么需要启动监督微调(Cold Start SFT)?直接从基模型(如DeepSeek-V3-Base)启动强化学习(RL)得到的模型(如DeepSeek R1-Zero)可能导致输出混乱(如语言混合、格式不统一),以及缺乏人类友好的推理模式,因此需要为模型提供初始的规范化推理行为。
在准备好长链思维数据(CoT Data)后,使用这些数据对基模型(如DeepSeek-V3-Base)进行监督微调。
-
将CoT数据作为输入,通过模型生成相应的输出。
-
计算模型输出与真实标签(即CoT数据中的推理过程)之间的误差。
-
根据误差更新模型的参数,以减小误差并提高模型的准确性。
二、面向推理强化学习
第二阶段:面向推理强化学习(Reasoning-Oriented RL)是什么?DeepSeek-R1运用强化学习算法来精炼模型的推理策略,使模型在与环境的互动中持续学习进步。通过不断尝试与纠正错误,模型能够探寻出最佳的决策路径。
在冷启动的基础上,DeepSeek-R1应用了大规模的强化学习过程。这个过程侧重于提升模型在编码、数学、科学和逻辑推理等任务上的能力。此外,DeepSeek-R1还引入了语言一致性奖励等机制,有效解决了语言混合等问题,从而显著提升了模型的推理性能。
三、拒绝采样和多领域监督微调
第三阶段:拒绝采样和多领域监督微调(Multi-Domain SFT)是什么?拒绝采样确保了训练数据的准确性和高质量,而多领域监督微调则通过引入多领域数据,进一步扩展了模型的能力和适用范围。
一、拒绝采样(Rejection Sampling)
拒绝采样技术于强化学习收敛后应用,从模型生成的响应中筛选正确推理轨迹,确保后续训练数据质量,提升模型推理能力。
二、多领域监督微调(Multi-Domain SFT)
多领域监督微调利用混合数据集,结合正确推理轨迹与非推理数据,进一步提升模型在多个领域的性能。
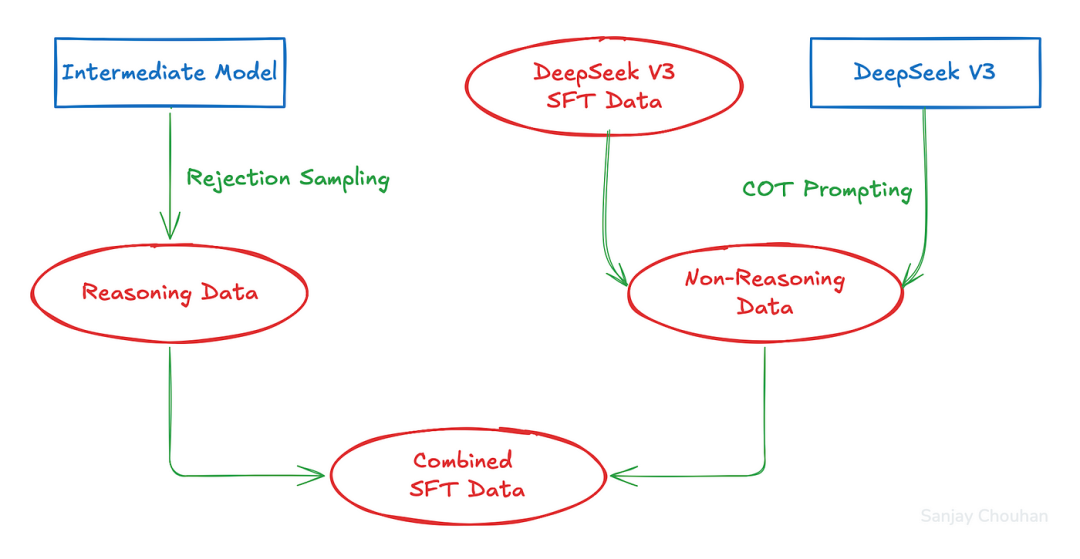
在面向推理的强化学习达到收敛状态后,DeepSeek团队巧妙地运用了所得的checkpoint,通过拒绝采样技术,精心生成了一批新的监督微调(SFT)数据。随后,他们利用这批数据进行了多领域的监督微调,这一举措极大地提升了DeepSeek-R1在第三阶段的推理能力和泛化性能。
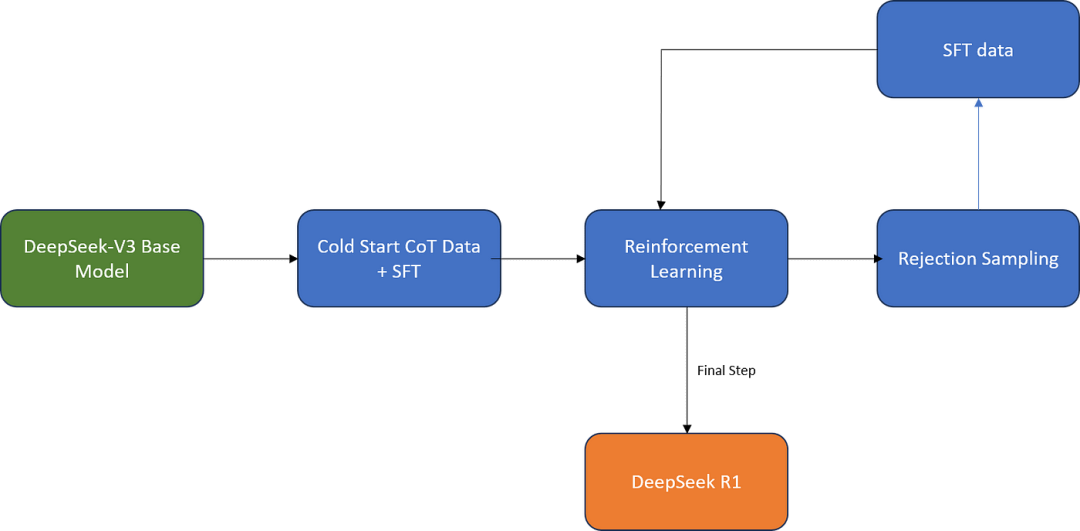
四、全场景强化学习
第四阶段:全场景强化学习(Final-RL Alignment)是什么?在全场景强化学习阶段,DeepSeek团队通过收集人类偏好数据、提升复杂场景泛化能力以及采用先进强化学习算法,确保模型与人类期望对齐并学习到最优策略。
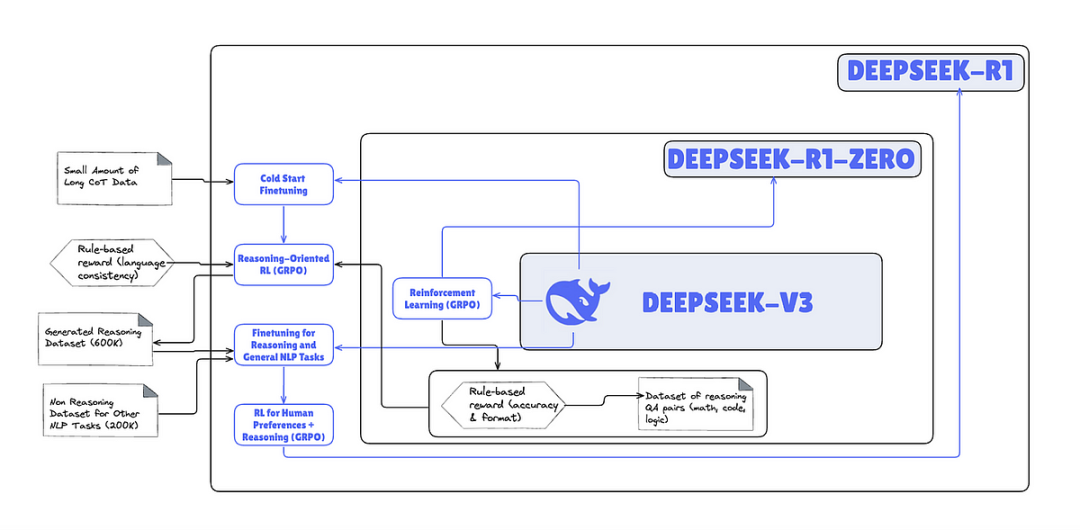
全场景强化学习(Final-RL Alignment)是DeepSeek-R1训练的最后阶段,通过强化学习技术,使模型在开放域问答、长文本理解等复杂场景中表现稳健,同时提升模型的安全性和实用性。这一阶段的主要目的是确保模型的行为和输出与人类期望的目标和价值观保持一致。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 26
26 2
2- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)