一文搞懂DeepSeek - 基础模型(V3)和深度思考(R1)
是时候准备春招和实习了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。DeepSeek提供了提供了基础模型(V3)和深度思考(R1)两种不同模式,以满足用户在不同场景下的需求。基础模型(V3)是通用模型,适用于绝大多数“规范性”任务,如用于快速获取百科信息;而
是时候准备春招和实习了。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞。

DeepSeek提供了提供了基础模型(V3)和深度思考(R1)两种不同模式,以满足用户在不同场景下的需求。
基础模型(V3)是通用模型,适用于绝大多数“规范性”任务,如用于快速获取百科信息;而深度思考(R1)是推理模型,擅长解决复杂推理和深度分析等“开放性”任务,如数理逻辑推理和辅助编程。
V3还是R1?过程驱动(规范约束)还是结果驱动(模糊目标)。

一、基础模型_(V3)_
基础模型DeepSeek-V3最大亮点是什么?DeepSeek-V3的训练成本远低于其它大模型。
据官方技术论文披露,DeepSeek-V3在预训练阶段仅使用2048块GPU训练了2个月,花费557.6万美元,而GPT-4o的训练成本估计高达数亿美元,马斯克的Grok3更是动用了20万块H100集群。

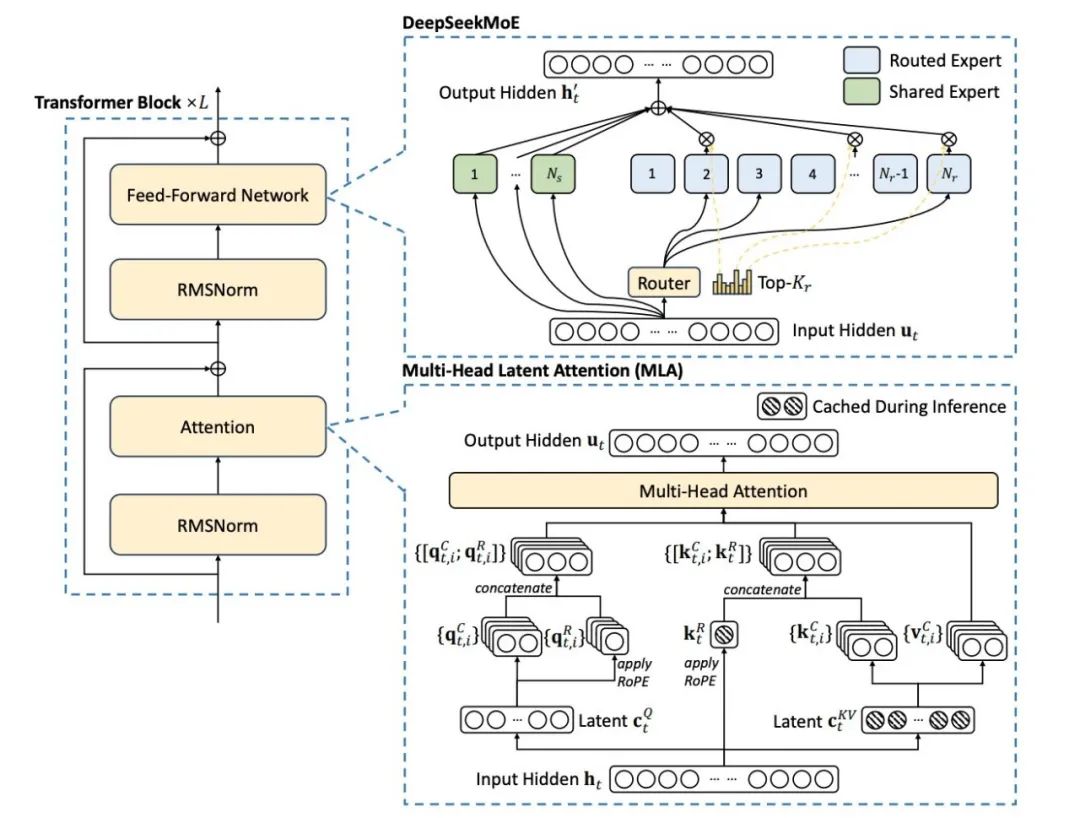
DeepSeek-V3如何实现低成本高性能?DeepSeek-V3之所以能实现低成本高性能,主要得益于其通过引入Mixture-of-Experts(MoE)架构和多头潜在注意力机制(MLA)进行模型架构创新,同时采用FP8混合精度训练进行训练方法创新。
-
Mixture-of-Experts(MoE)架构:由1个共享专家和256个路由专家组成,每个令牌会激活8个路由专家。这种细粒度的划分提高了模型的表达能力,同时减少了专家之间的通信开销。
-
多头潜在注意力机制(MLA):MLA通过对注意力键值(Key-Value)进行低秩压缩,将注意力键值压缩为一个低维的潜在向量,并在推理过程中仅缓存该向量,这种方式大大节省了存储空间,同时保证了信息的完整性。
-
FP8混合精度训练:DeepSeek-V3首次在如此大规模的模型上成功实现了FP8训练。DeepSeek-V3在大多数计算密集型操作(如矩阵乘法)中使用FP8格式,而在一些对精度敏感的操作(如嵌入模块、输出头、MoE门控模块等)中仍保留较高精度(如BF16或FP32)。这种混合精度框架在保证训练稳定性的同时,显著提高了计算速度和内存效率。
二、深度思考(R1)
深度思考DeepSeek-R1最大亮点是什么?DeepSeek-R1在推理能力方面表现出色,尤其在数学、代码和自然语言推理等复杂任务上。
由于DeepSeek-R1具有强大的推理能力和低成本优势,它在多个领域具有广泛的应用前景。例如,在教育领域,它可以作为智能辅导工具,帮助学生解决数学问题、编写代码等;在科研领域,它可以作为研究助手,帮助研究人员处理数据、生成假设等。

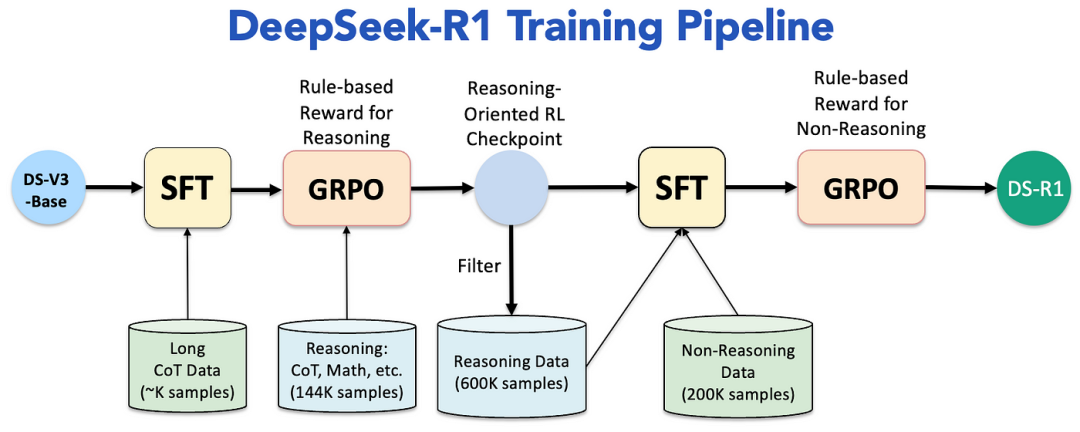
DeepSeek-R1如何实现强大的推理能力?DeepSeek-R1通过创新的强化学习技术、多阶段训练管道以及知识蒸馏技术实现了强大的推理能力。
一、强化学习为核心
DeepSeek-R1及其前身DeepSeek-R1-Zero代表了对传统监督微调(SFT)范式的背离,探索了强化学习(RL)的力量。
- DeepSeek-R1-Zero:DeepSeek-R1-Zero完全通过强化学习进行训练,没有任何监督微调的介入。在训练过程中,DeepSeek-R1-Zero展示了自我进化的能力,例如通过分配更多的思考时间来重新思考其最初的方法,实现了推理能力的显著提升。然而,这种方法也存在可读性差和语言混合的问题。
- DeepSeek-R1:DeepSeek-R1在强化学习之前结合了多阶段训练和冷启动数据方法。具体来说,它引入了数千条高质量的、包含长推理链(Chain of Thought,CoT)的冷启动数据对模型进行微调,从而显著提升了模型的可读性和多语言处理能力。
二、多阶段训练管道
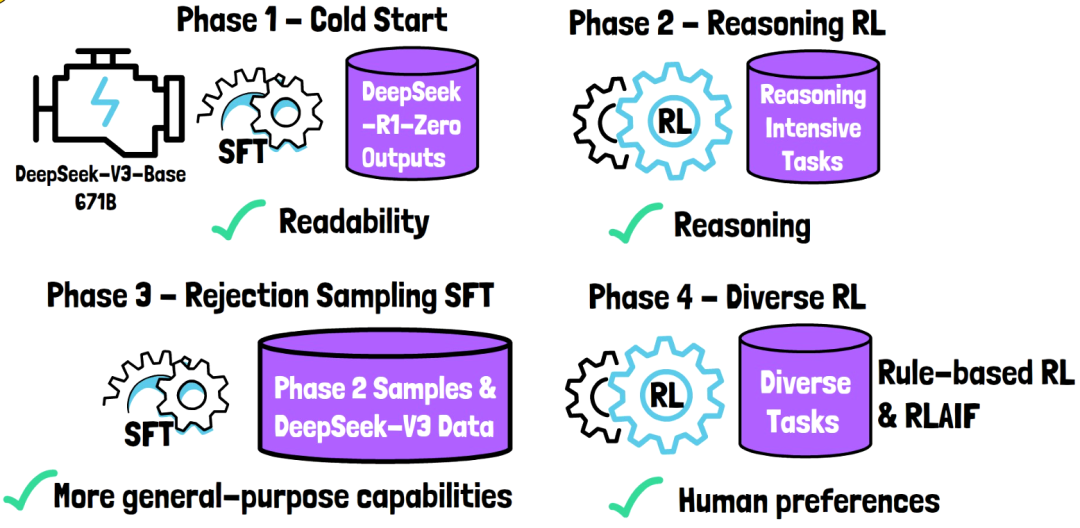
DeepSeek-R1的多阶段训练管道包括冷启动数据预训练、推理导向强化学习、拒绝采样和监督微调以及全场景强化学习等阶段,每个阶段都对模型的推理能力进行了针对性的提升。
三、知识蒸馏技术
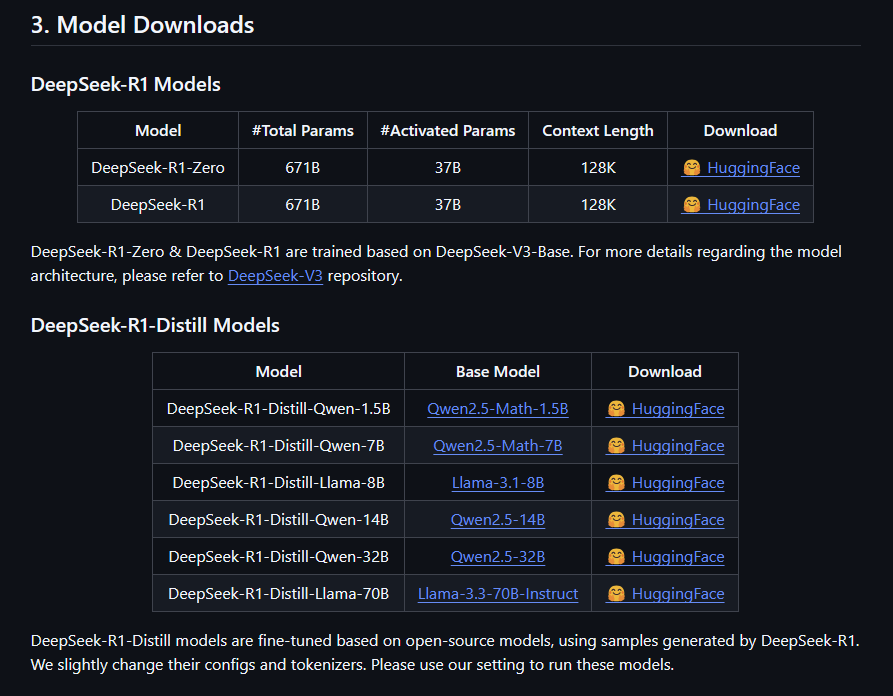
DeepSeek团队还深入探索了将R1的推理能力蒸馏到更小模型中的潜力。他们利用DeepSeek-R1生成的800K数据对Qwen和Llama系列的多个小模型进行了微调,并发布了DeepSeek-R1-Distill系列模型。这些小型模型在保持强大推理性能的同时,显著降低了计算资源需求,为企业级应用提供了更实用的解决方案。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)