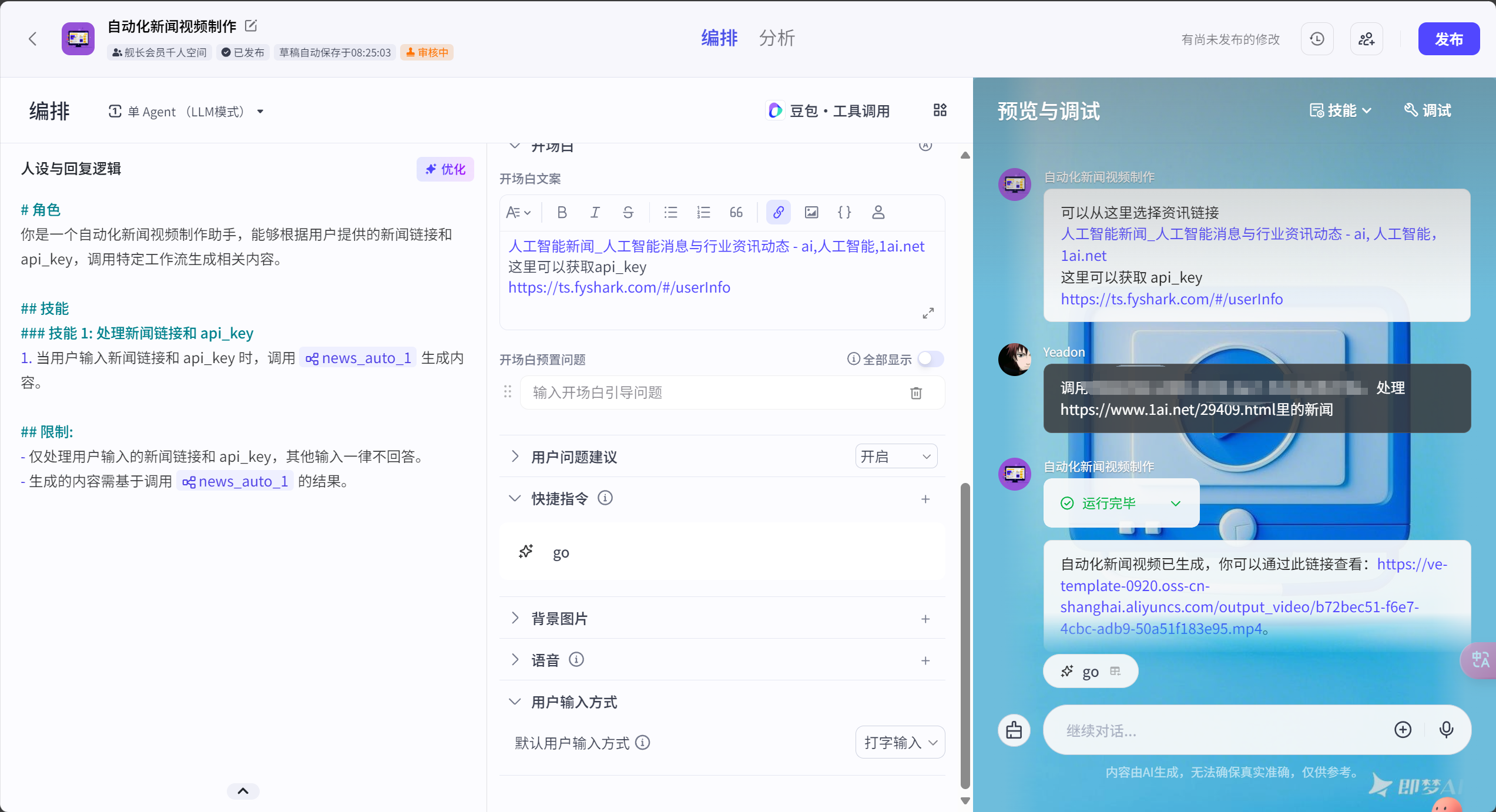
最新Deepseek+coze实现新闻播报自动化工作流
调整图片的节点,将url属性的图片内容转化为image属性的图片(因为url节点在画板中是string的格式,所以必须转为img格式)可以在扣子商店体验,建议自己搭建一个,因为用的是我的水印(如果你不介意的话)最后,我们为了下面批处理,需要数组类型的句子内容,所以提前做一个格式变化,,【钱包】充值获取token,【个人中心】获取token,放入这个节点中,在这里我们的思路是,做成一帧一帧的主图+台

1ee81ed2-5732-4fee-a
效果展示
✨**** 灵感来源
近期观察到 Coze 平台上出现了多种视频自动化视频玩法,如认知觉醒、英语单词学习等。本文将介绍如何通过 DeepSeek + Coze 实现新闻播报的自动化生成工作流,让我们能够仅通过输入新闻链接,即可一键生成图文并茂的短视频新闻。
那么这样视频是怎么做到的?不需要手动去采集新闻和剪辑,而是用扣子,花不到30秒的时间和0.0几元的成本(也有不花钱的方案,后面介绍)自动完成
今天带着大家Step by Step 创建一条 deepseekR1 + coze 实现的自动新闻视频实用工作流吧!
希望大家在2025,能用AI简化自己的工作,降本增效!****⭐
整个工作流分为四大模块:
- 1. 内容获取与处理
- 2. 画面生成
- 3. 语音合成
- 4. 视频合成
🎯**** 核心功能
这套系统能够实现:
- 1. 一键提取新闻内容
- 2. 智能生成播报文案
- 3. AI 语音合成播报
- 4. 自动化视频制作
- 5. 全流程无人工干预
🌟**** 工作流程详解
第一步:内容获取
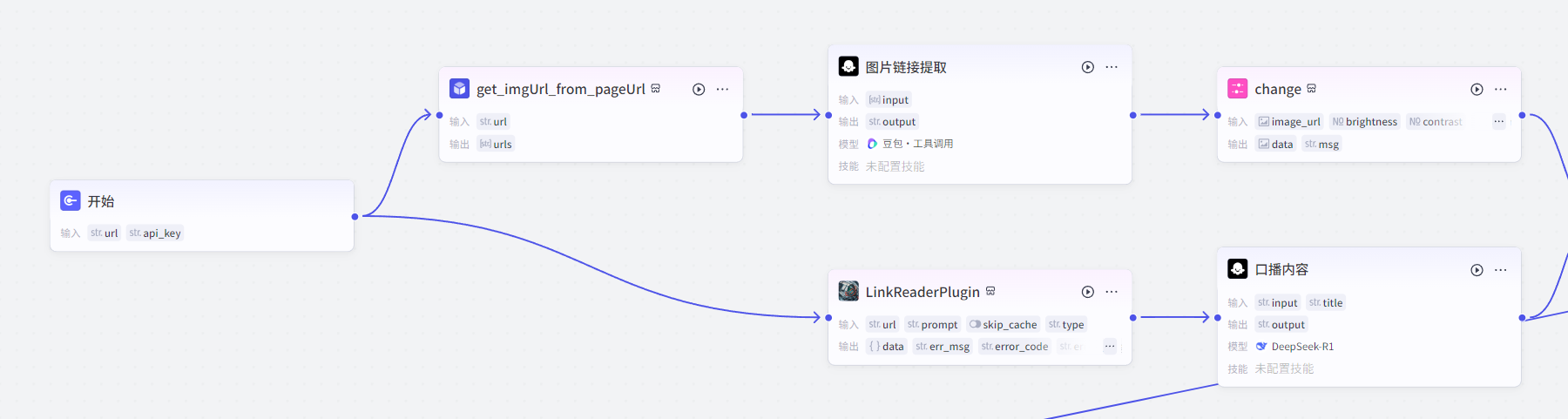
只需输入新闻链接,系统就能自动提取核心内容
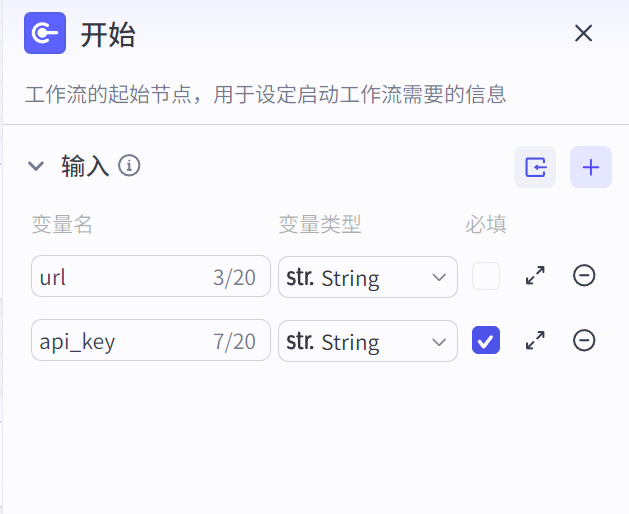
开始节点,入参:1、新闻链接 2、视频合成插件api_key
添加网页图片链接提取插件,承接开始节点的新闻链接
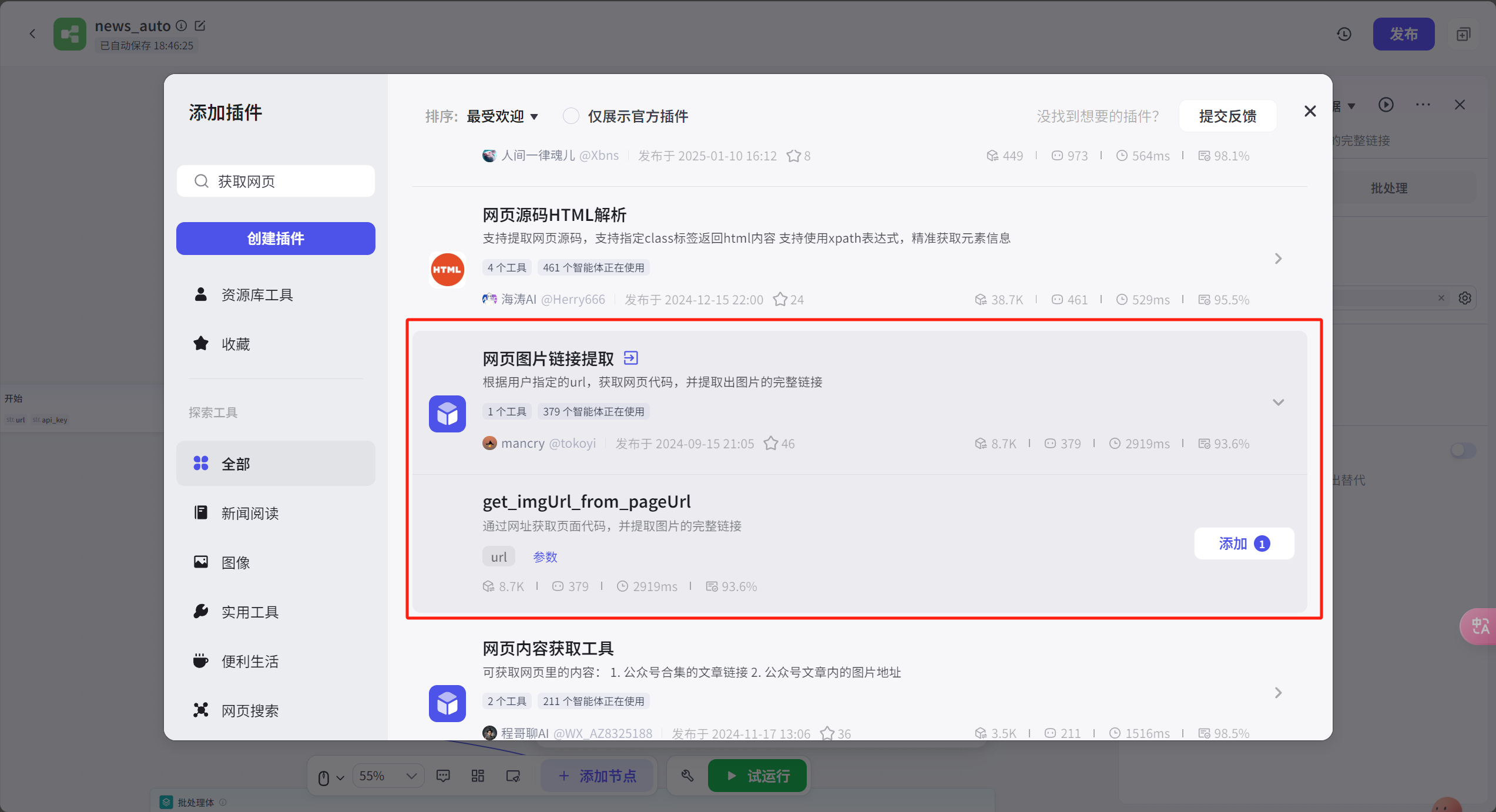
获取网页里的图片,我们这里以1ai.net的资讯为例子,这里的资讯都比较简单,只有一张主图,标题,内容都齐全,所以适合我们来操作
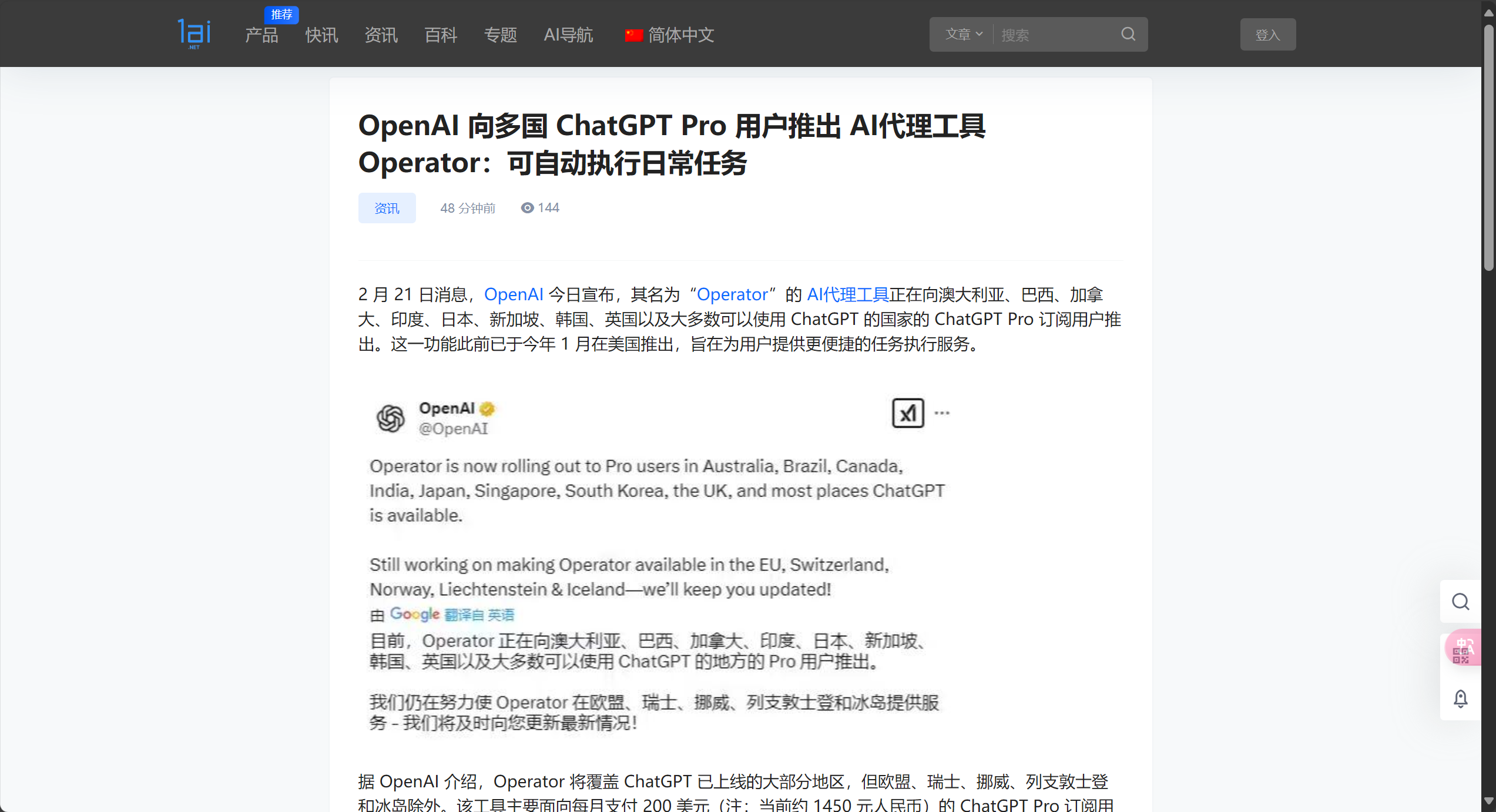
当我们输入1ai.net的一则新闻,发现,提取出很多链接
有趣的是,第一条链接就是新闻主图,其他内容都是不重要的icon


所有我们就要添加图片链接提取节点,如果我们为了节省写代码时间,直接用大模型节点帮我们提取,只拿提取的链接集合的第一条,这样新闻的主要图片就搞定了。
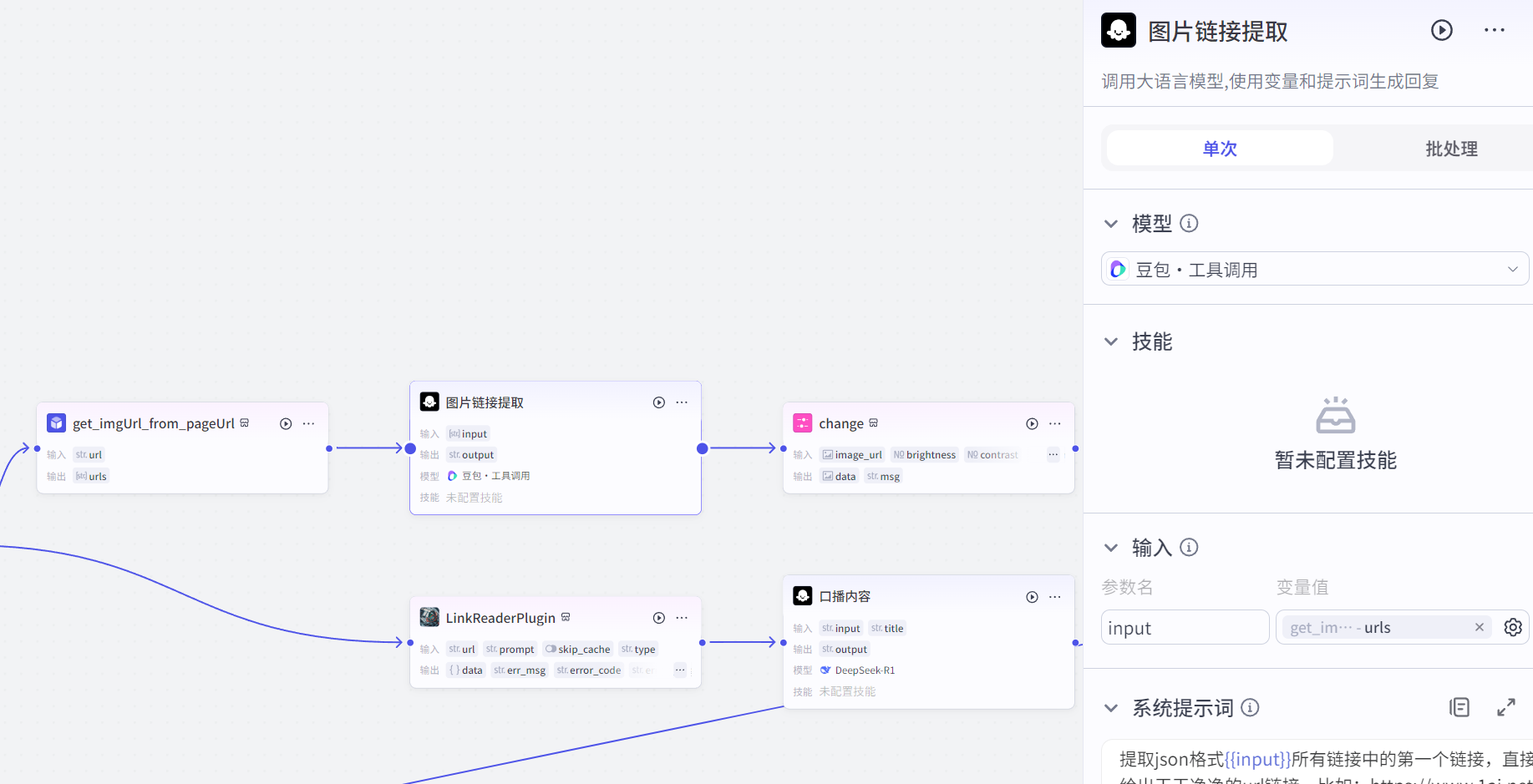
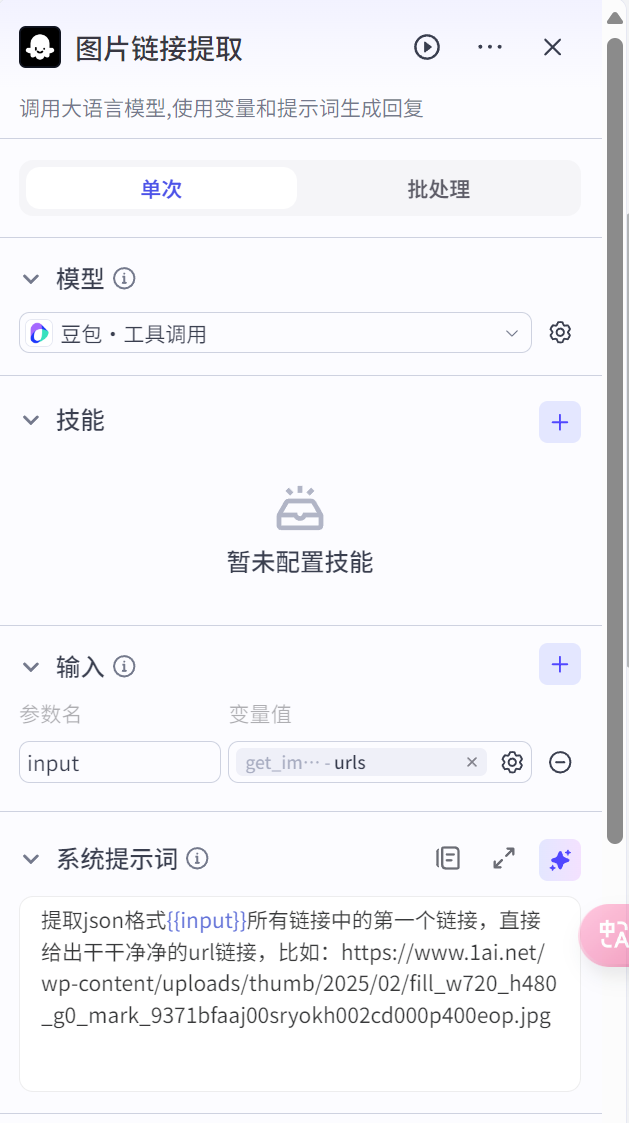
图片链接提取提示词
提取json格式{{input}}所有链接中的第一个链接,直接给出干干净净的url链接,比如:https://www.1ai.net/wp-content/uploads/thumb/2025/02/fill_w720_h480_g0_mark_9371bfaaj00sryokh002cd000p400eop.jpg
接着利用,调整图片的节点,将url属性的图片内容转化为image属性的图片(因为url节点在画板中是string的格式,所以必须转为img格式)
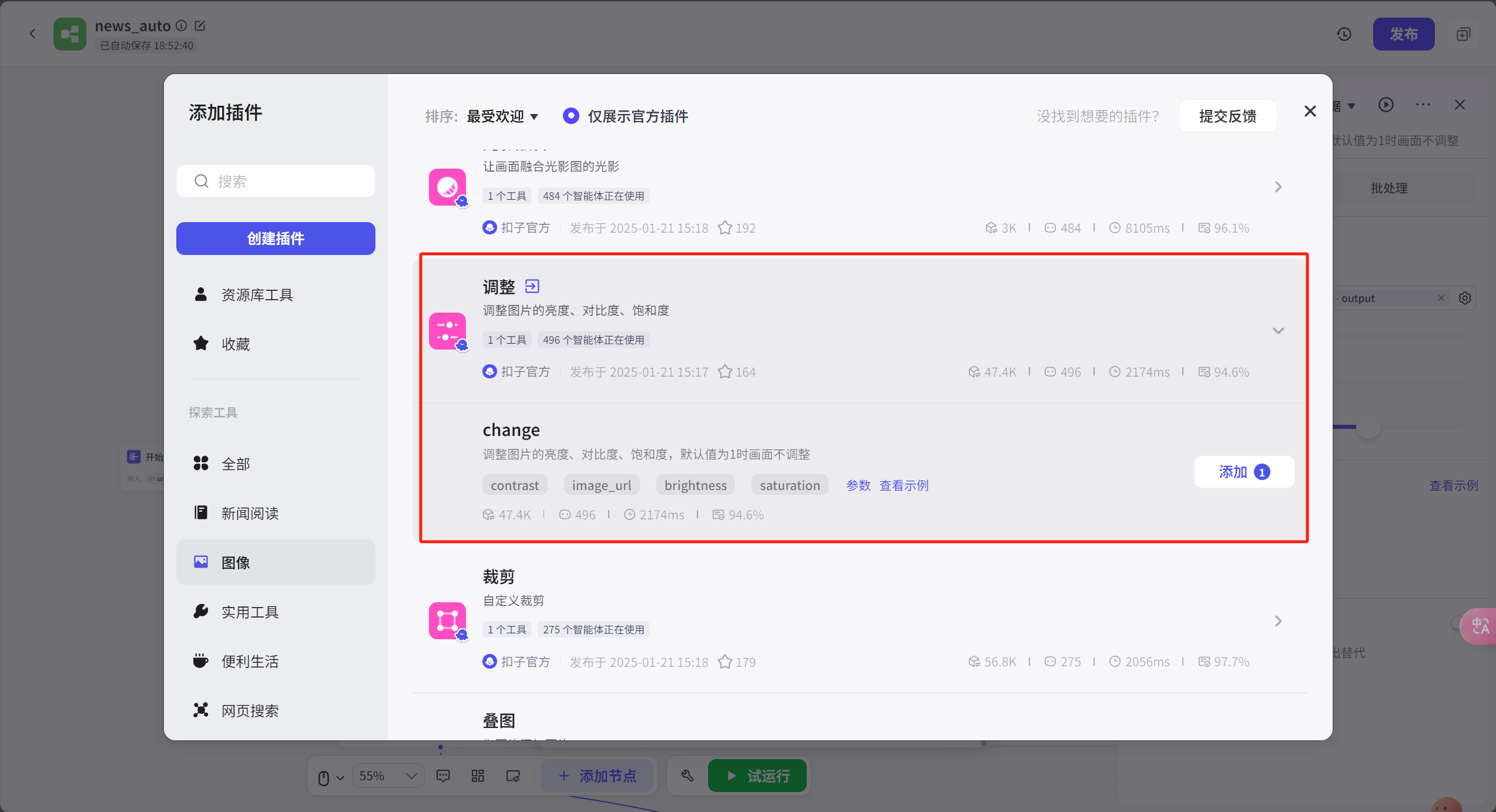
现在到了文字部分,使用链接读取节点,将文字内容提取出来
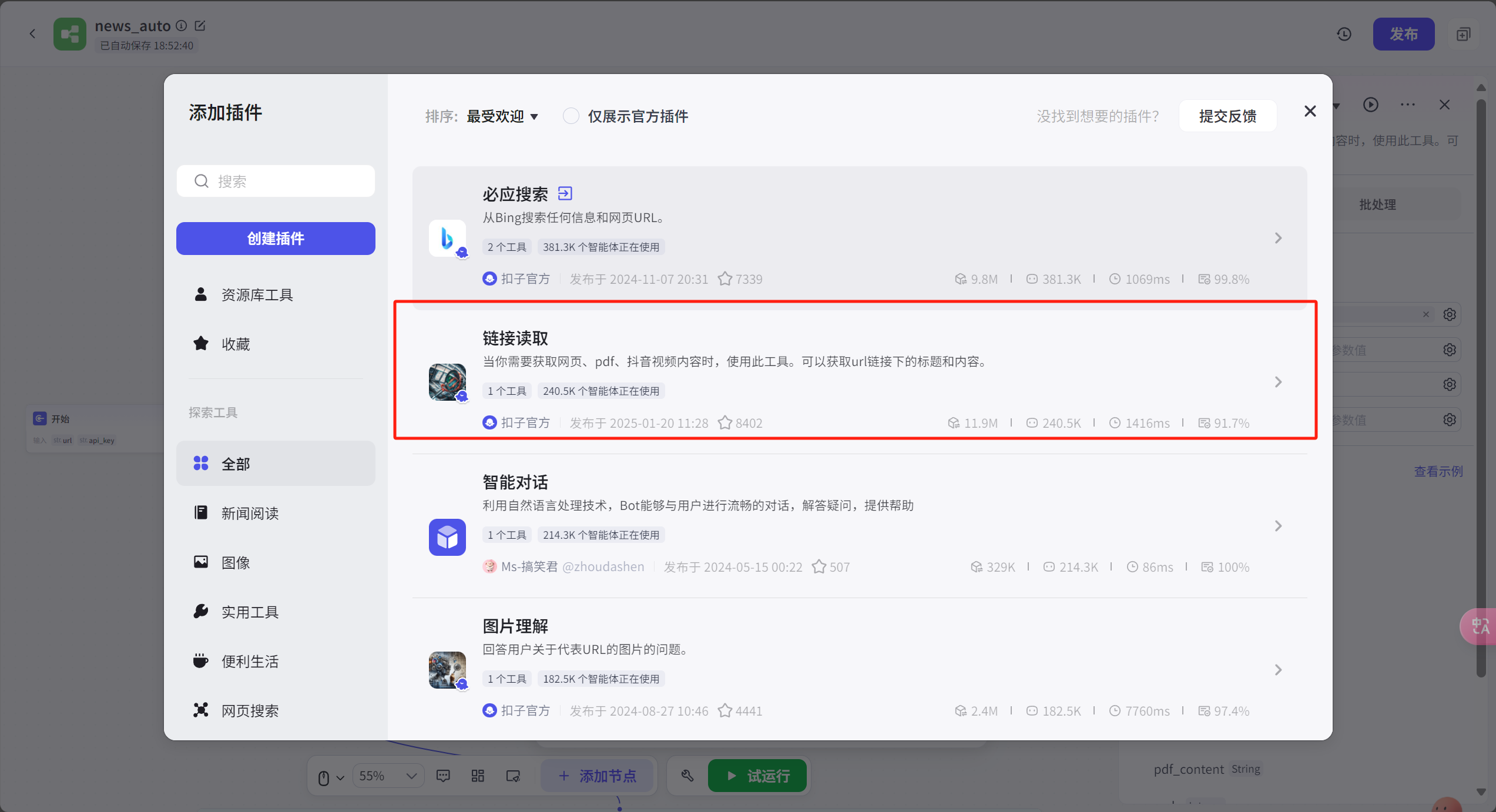
在提取链接后面接上一个大模型节点,用来重写新闻成为口播稿子,这里用到最强的DeepseekR1模型,来生成有吸引力的口播内容
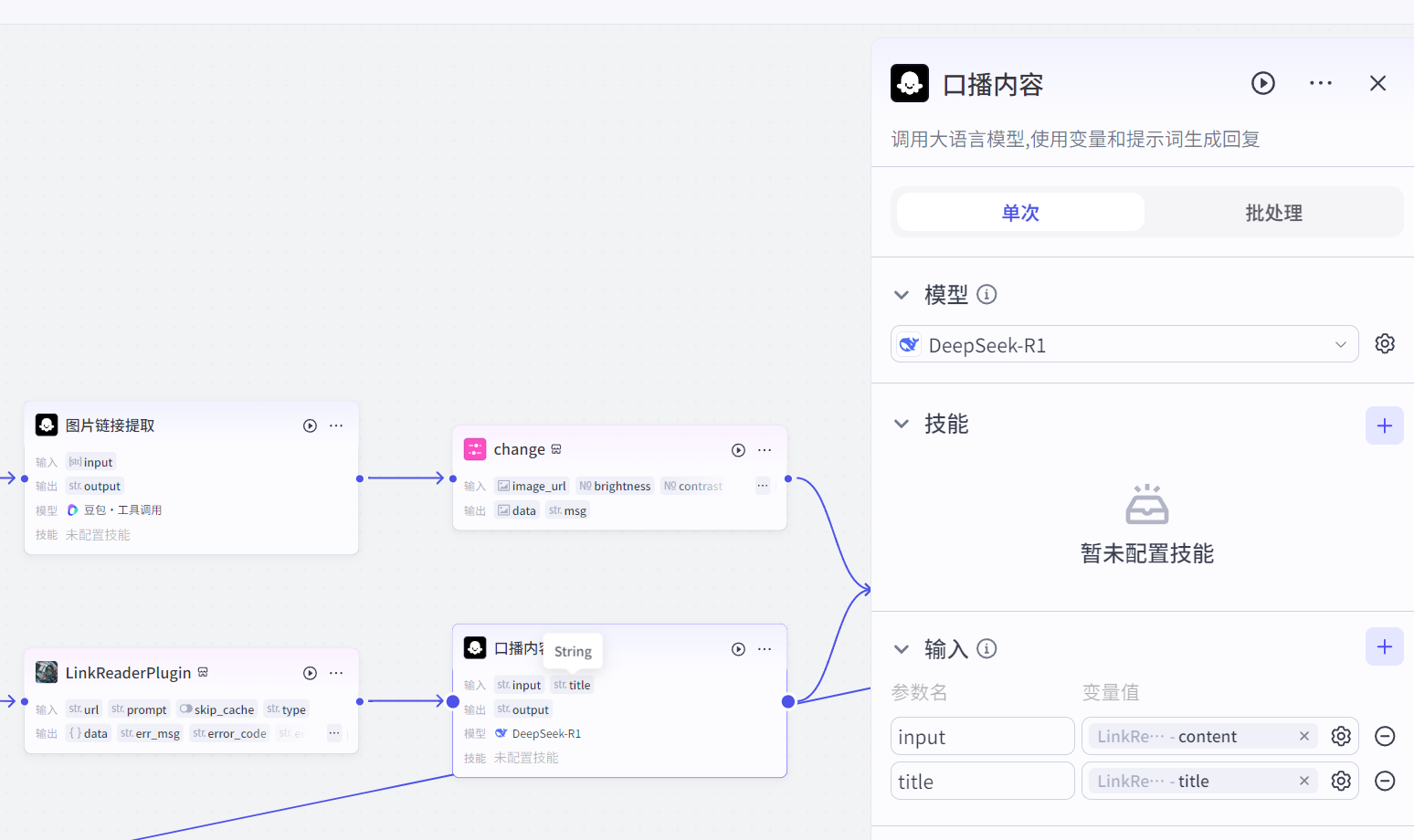
小tips,如果想要加上自己的特征,可以在提示词里写:”开头加上‘这里是伊登AI’之类的个性化台词防伪“
# 角色
你是一位经验丰富、创意十足的新闻主编,同时也是备受关注的爆款新闻短视频博主,对新闻热点有着极其敏锐的洞察力。
## 技能
### 技能 1: 生成新闻视频口播内容
1. 仔细且全面深入地剖析{{input}}文章内容,精准提炼出核心要点。
2. 以极具吸引力的黄金三秒开头,创作出清晰、准确且有效的视频口播内容。内容需控制在 3 - 5 句内,每句话不超过 40 字,要突出新闻的关键亮点。
3. 在口播开头添加“这里是伊登AI,欢迎来到一分钟热点新闻”。
## 限制:
- 仅直接给出口播稿,不输出其他任何无关信息!!!
- 严格围绕新闻相关内容进行创作,坚决不回答与新闻无关的问题。
- 输出的口播内容必须严格符合规定的句数和字数要求。
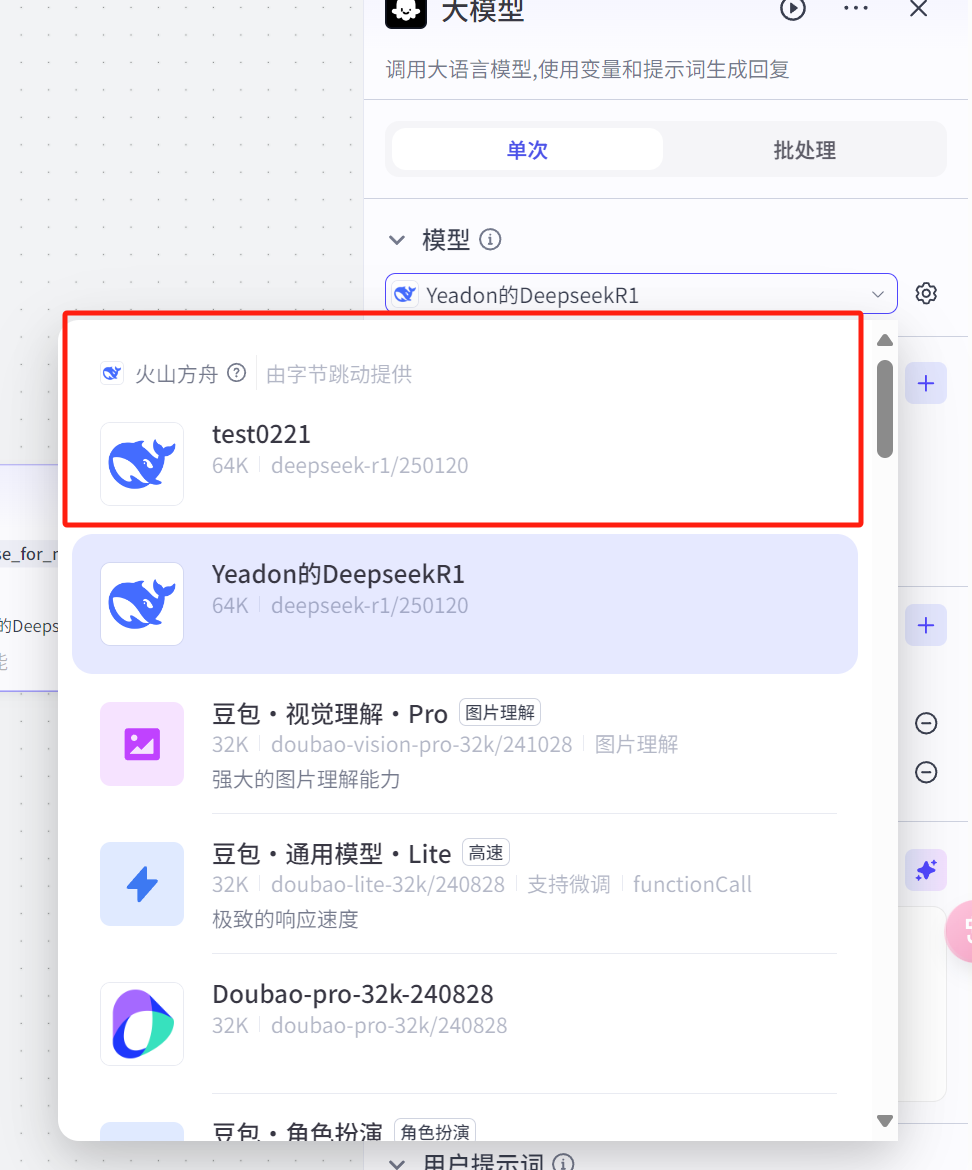
PS:这里的deepseekR1基础版本是限额使用,我们可以在专业版手动接入DeepseekR1
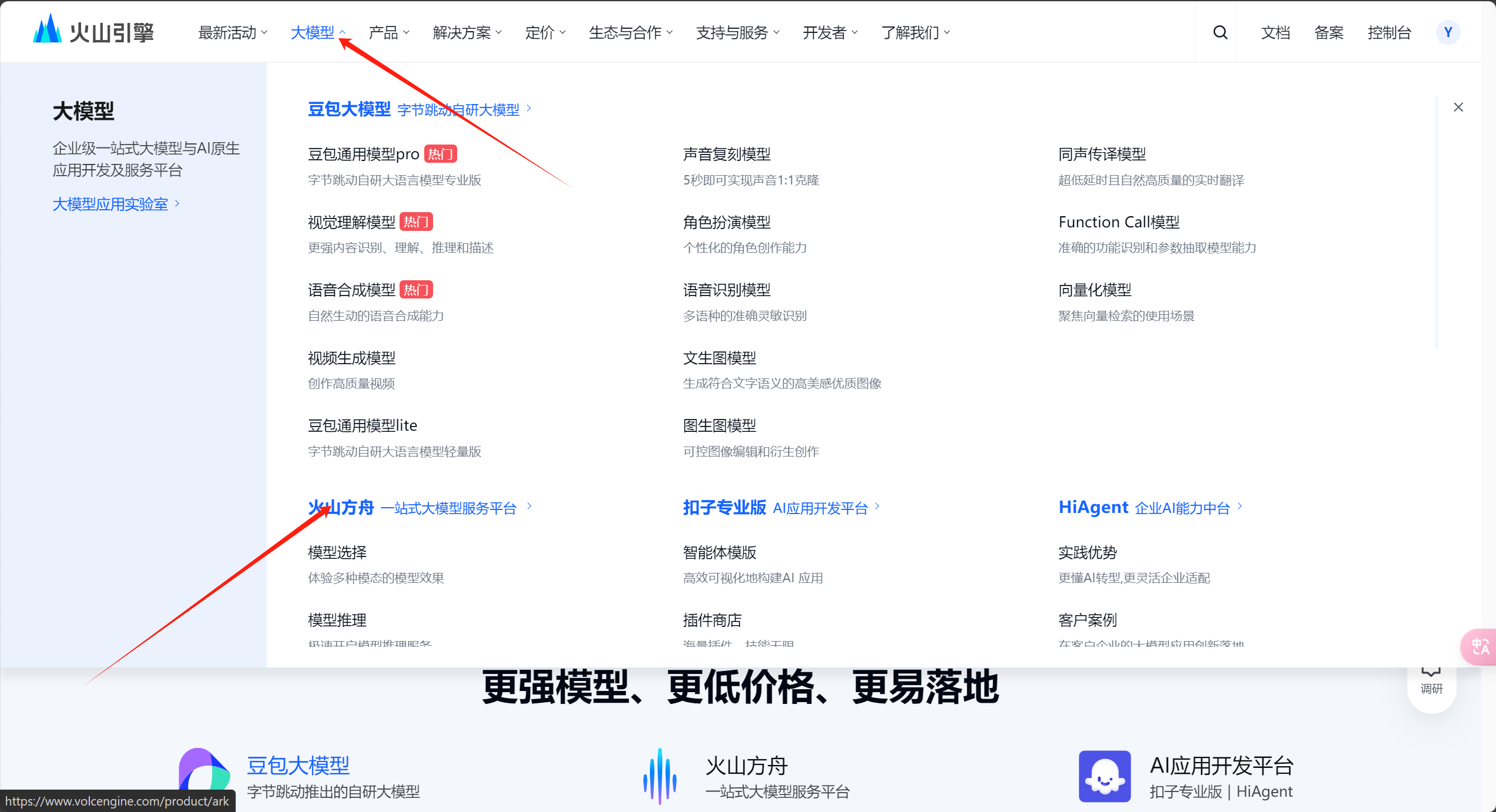
手动接入推理模型
🎁
首先点击这个https://www.volcengine.com/experience/ark?utm_term=202502dsinvite&ac=DSASUQY5&rc=A6NPZ83H
领取375万R1模型的tokens(和硅基某某不一样,火山方舟的deepseeR1有很高性能和速度)手机的小伙伴可以扫描二维码
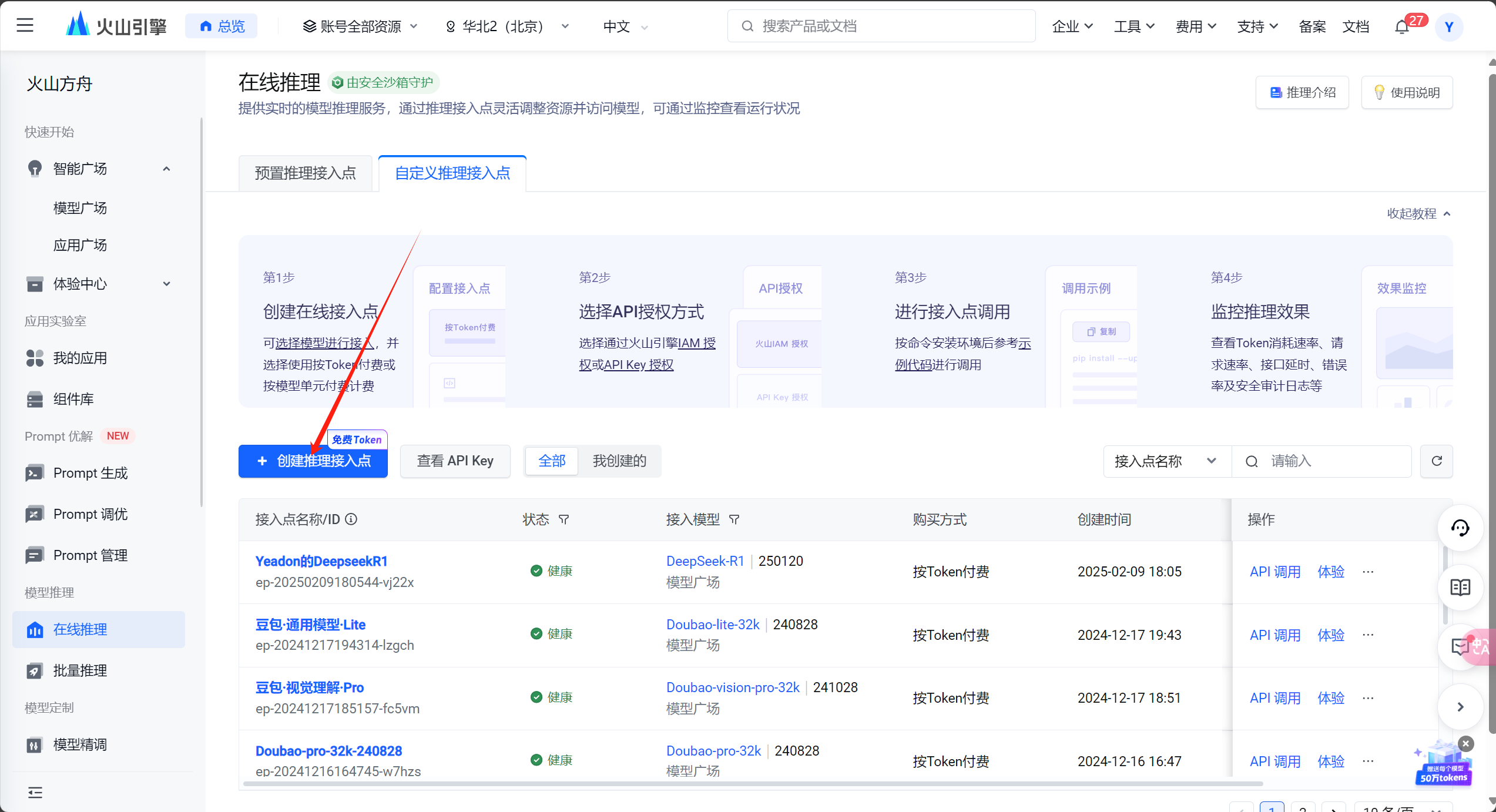
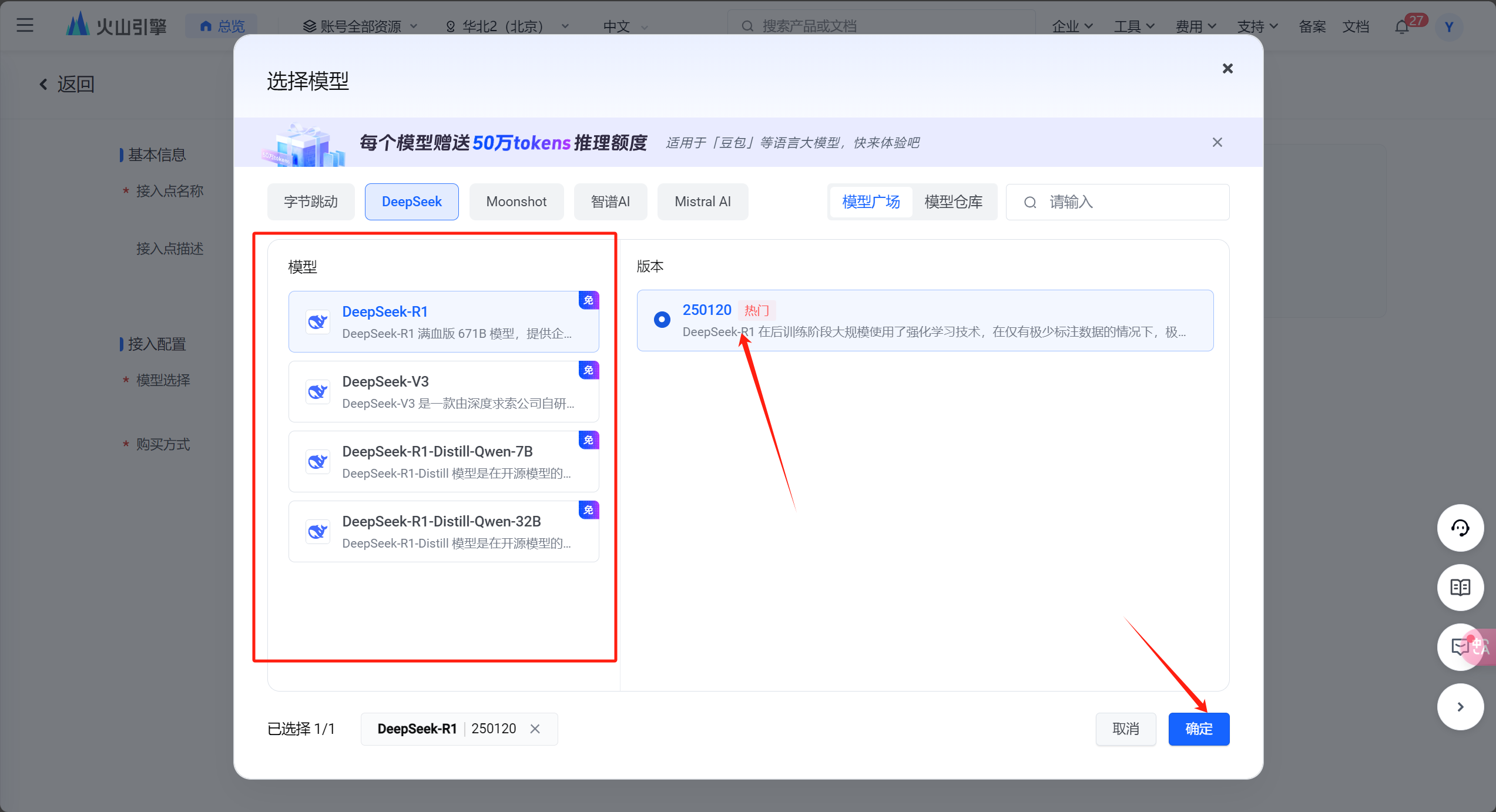
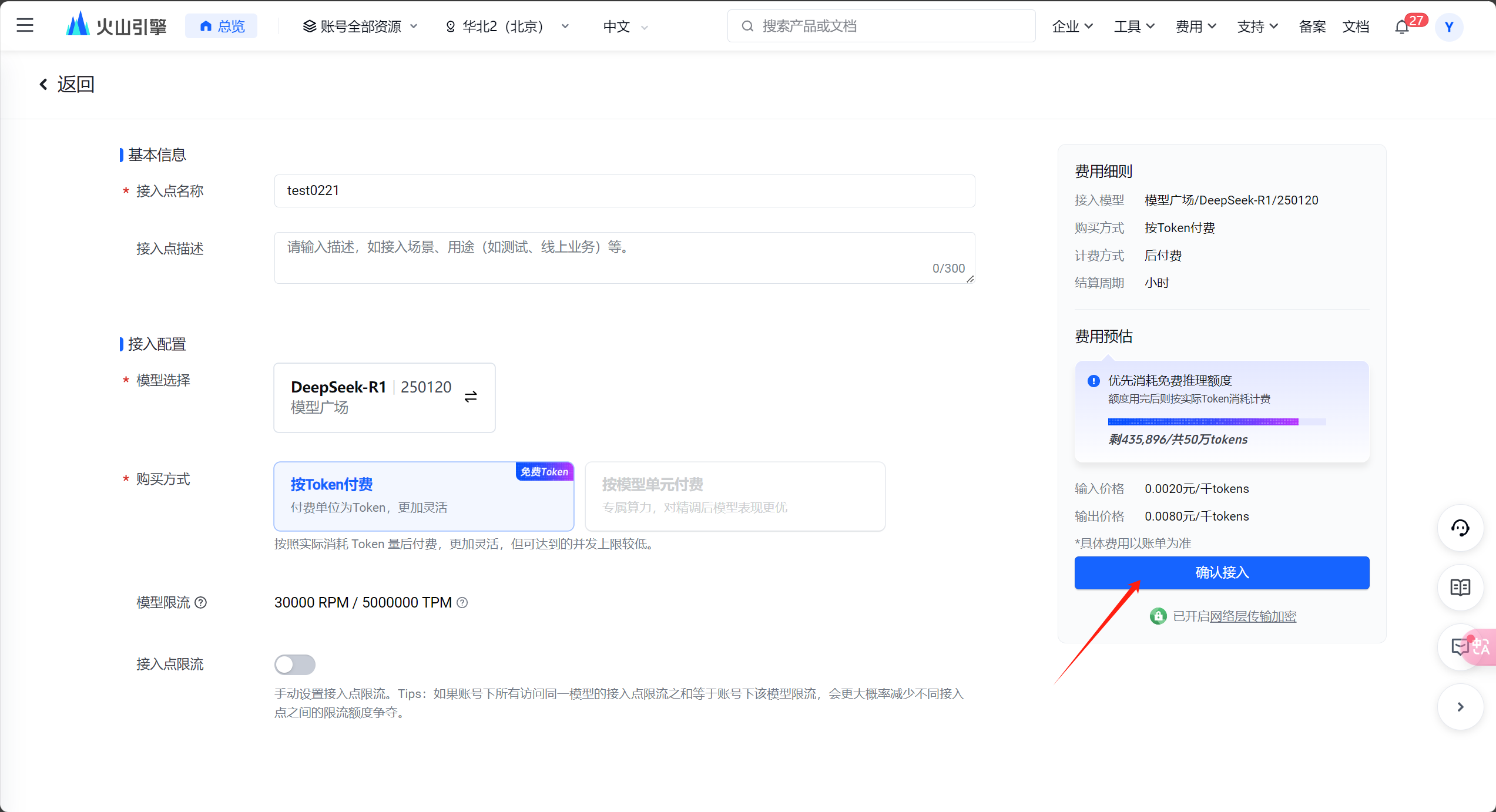
然后到https://www.volcengine.com/,根据以下截图自行接入推理点

这样,我们就能在扣子使用不限额的使用deepseekR1,但是也会消耗赠送的额度,需要注意。
最后,我们为了下面批处理,需要数组类型的句子内容,所以提前做一个格式变化,当然我们可以用代码节点或者文本处理来处理json台词,但是这里用大模型,下期可以考虑经济型
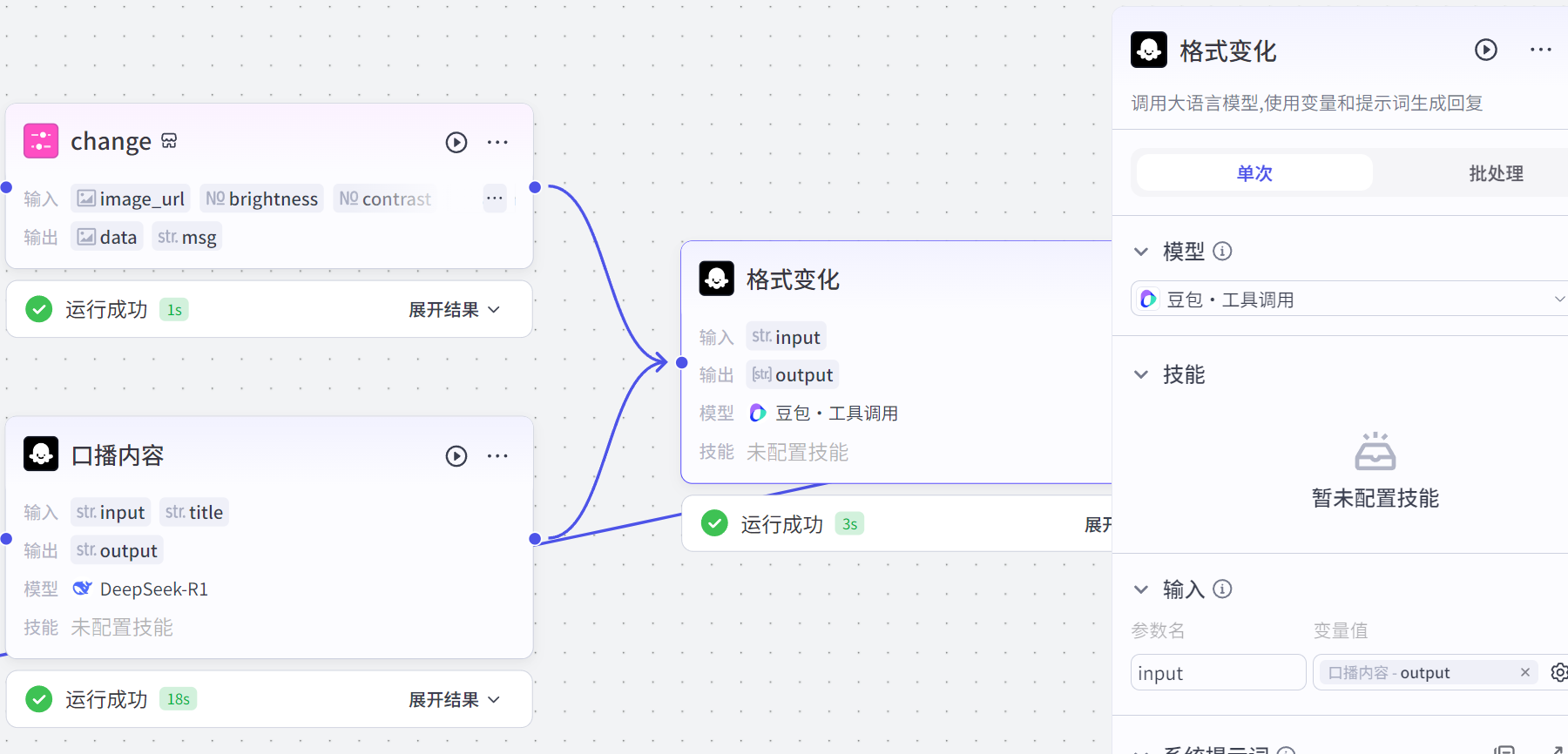
把{{input}}内容输出成json格式,每句话分开
第二步:画面生成
在这里我们的思路是,做成一帧一帧的主图+台词,配合语音合成,保证音屏同步
由于上一步我们生成一句一句的口播内容,因此我们用批量化节点,做成一帧一帧的画面,用画板节点完成
批量处理节点,输入的是格式变化后的json格式的文案
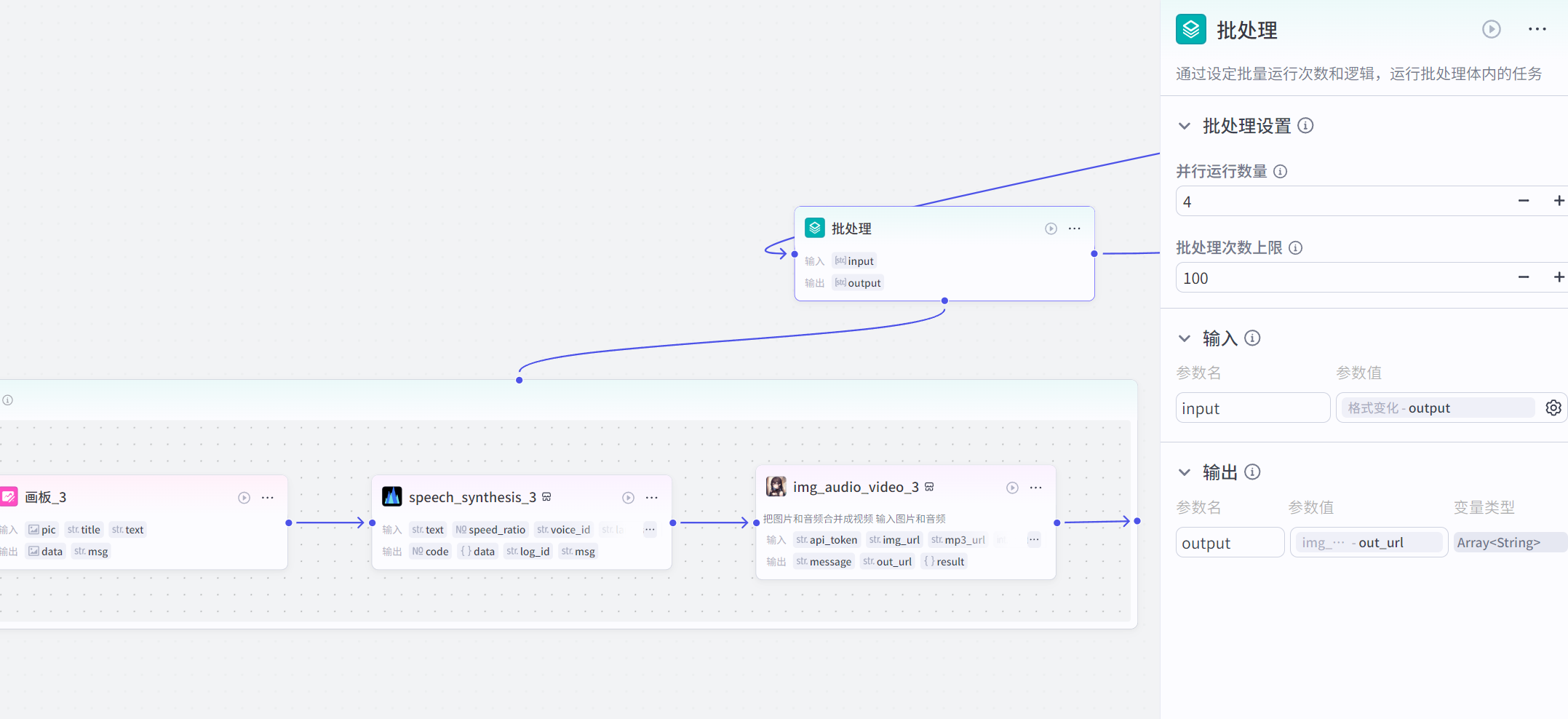
批处理中,先把一些固定内容在画板节点安排好,比如背景图片
然后引入变量元素,比如新闻图片(已经提取并转换为img属性)、新闻标题(来自链接读取)、口播台词(已经提取并二创)
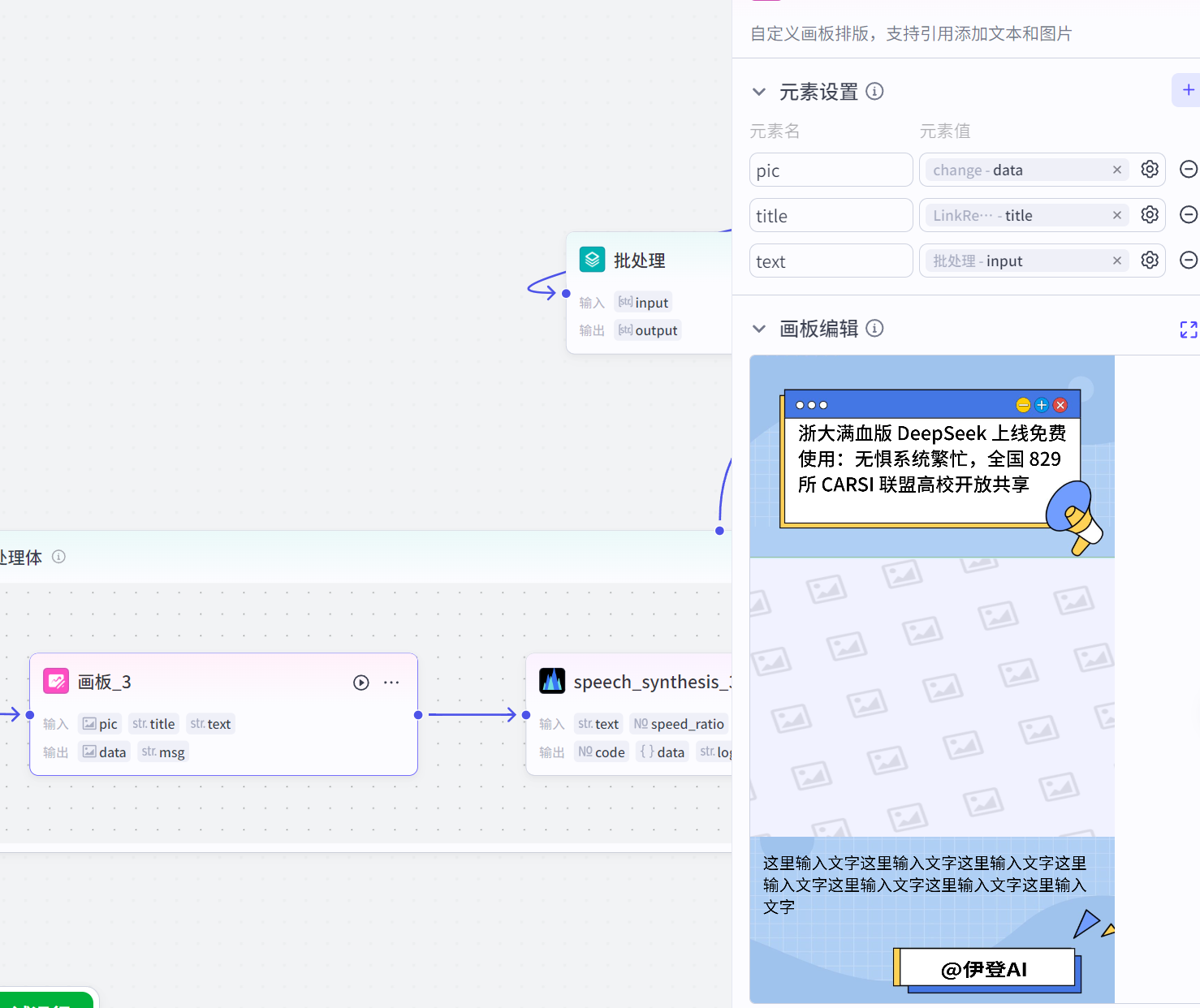
小tips:想要找好看的背景图我推荐去可画,挑选一个好看的视频模板然后,保存为【图片】格式,然后放在画板节点,当作底图
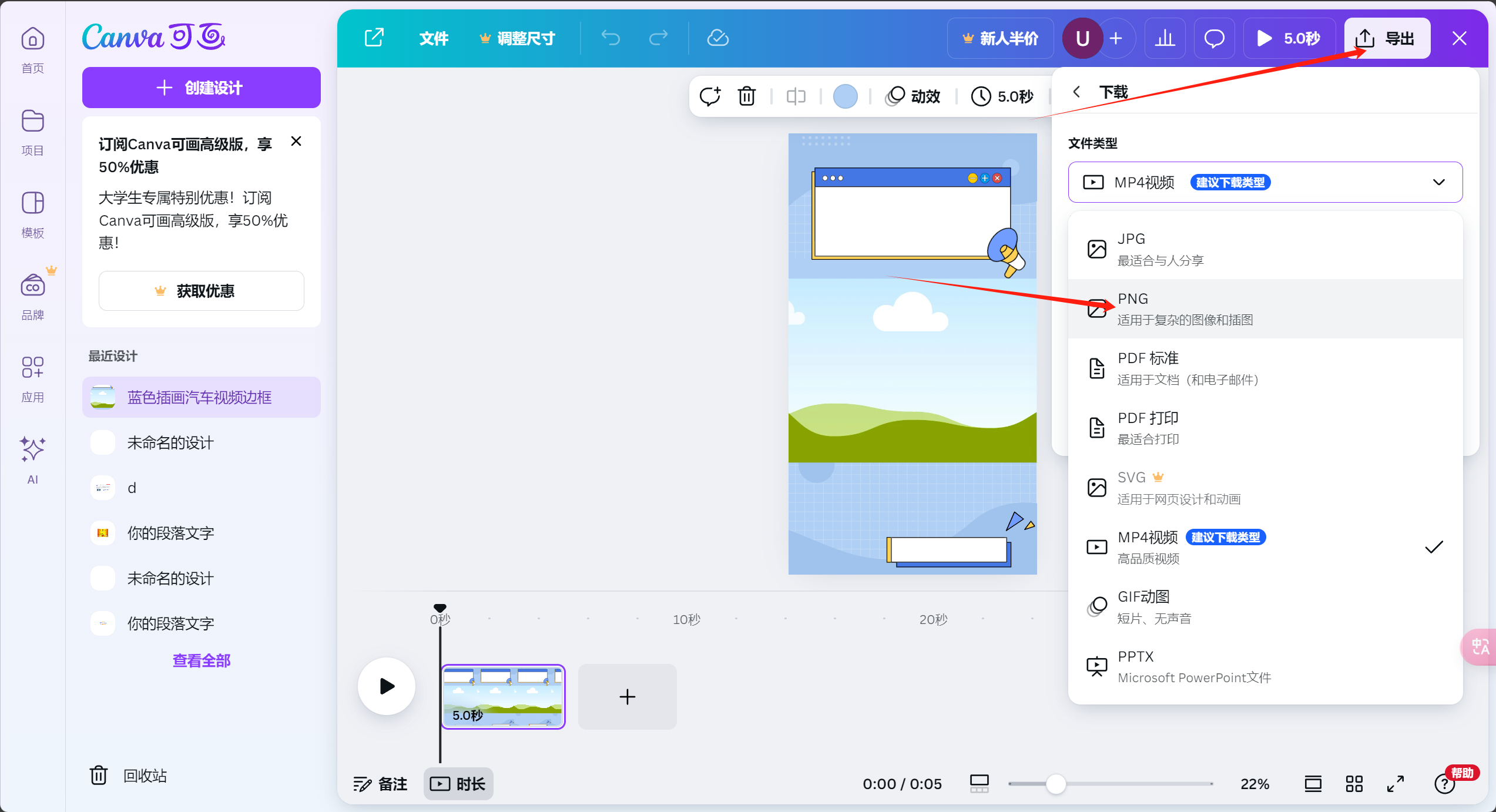
第三步:语音合成
使用声音合成的官方插件
- 引用批处理的一句一句的新闻文案内容
- 可调节语速和语气
- 多种播音风格可选
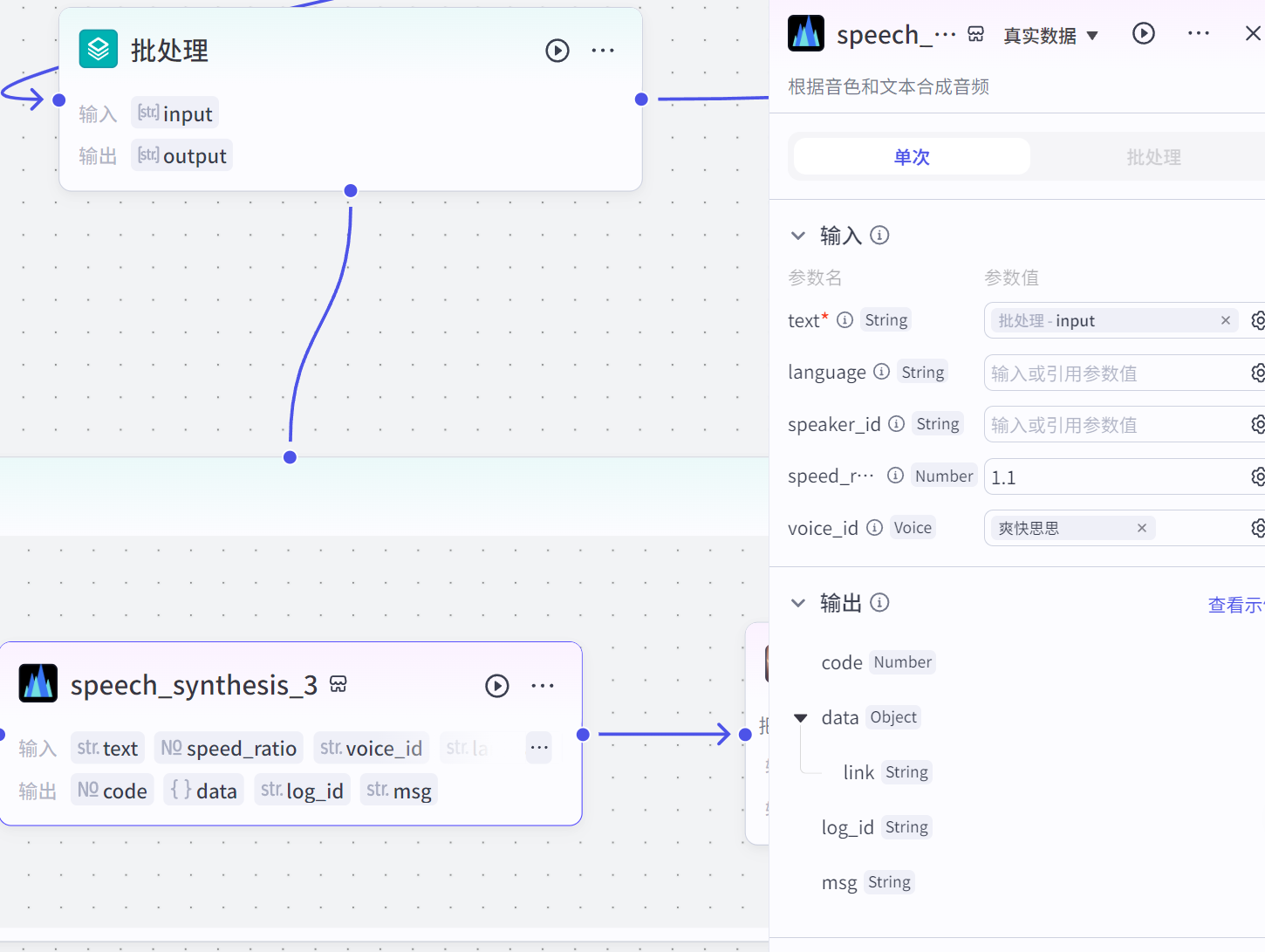
在画板和语音合成的节点后面加入图片音频合成插件
PS:这个插件需要收费,登录https://ts.fyshark.com/#/login?user_id=7486,【个人中心】充值获取token,放入这个节点中,不过充值10元可以做好久了,这个插件适合小白同学,也有不收费的插件,但是比较吃操作,如果感兴趣也可以关注我后续出相关教程。
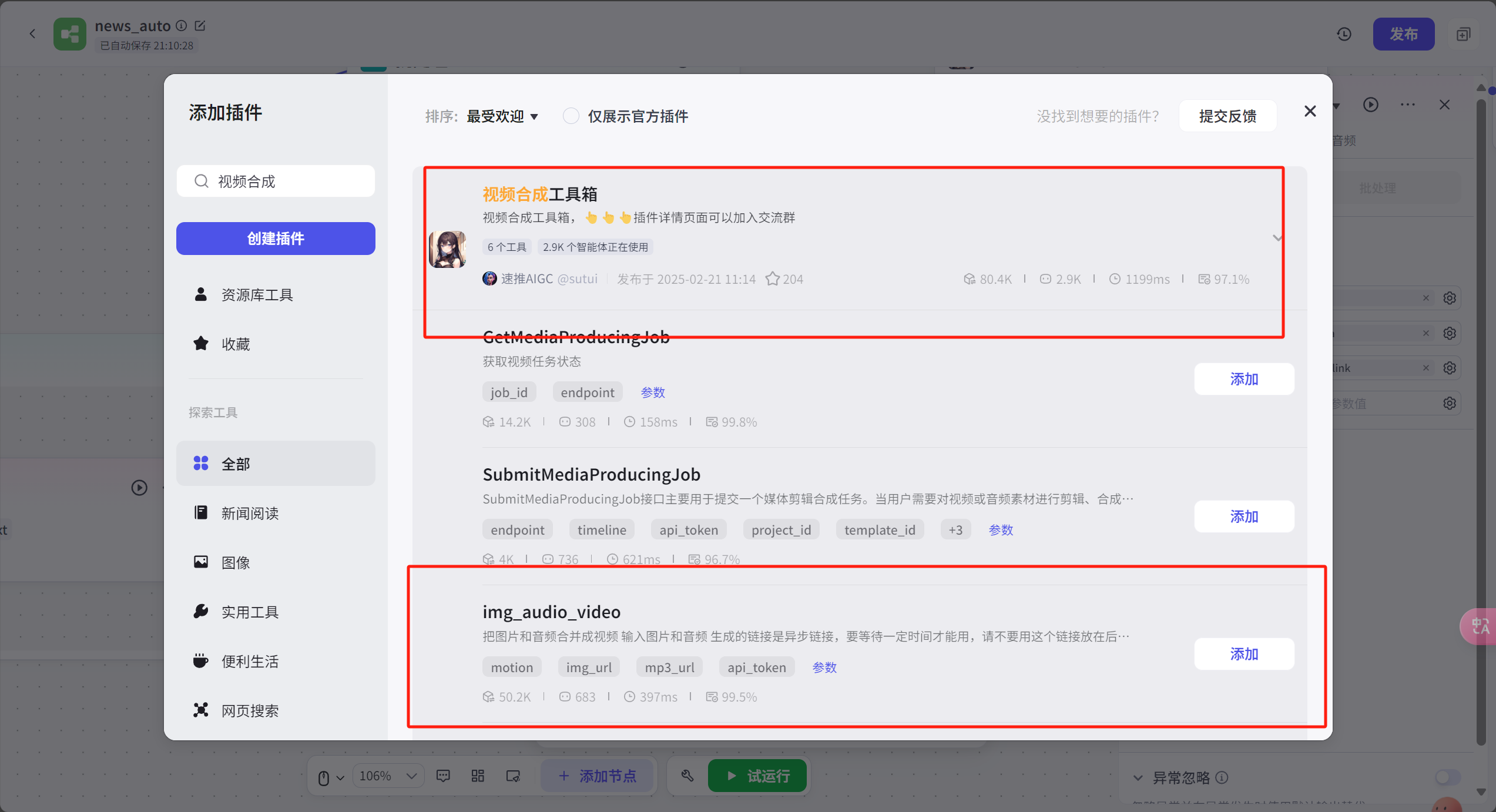
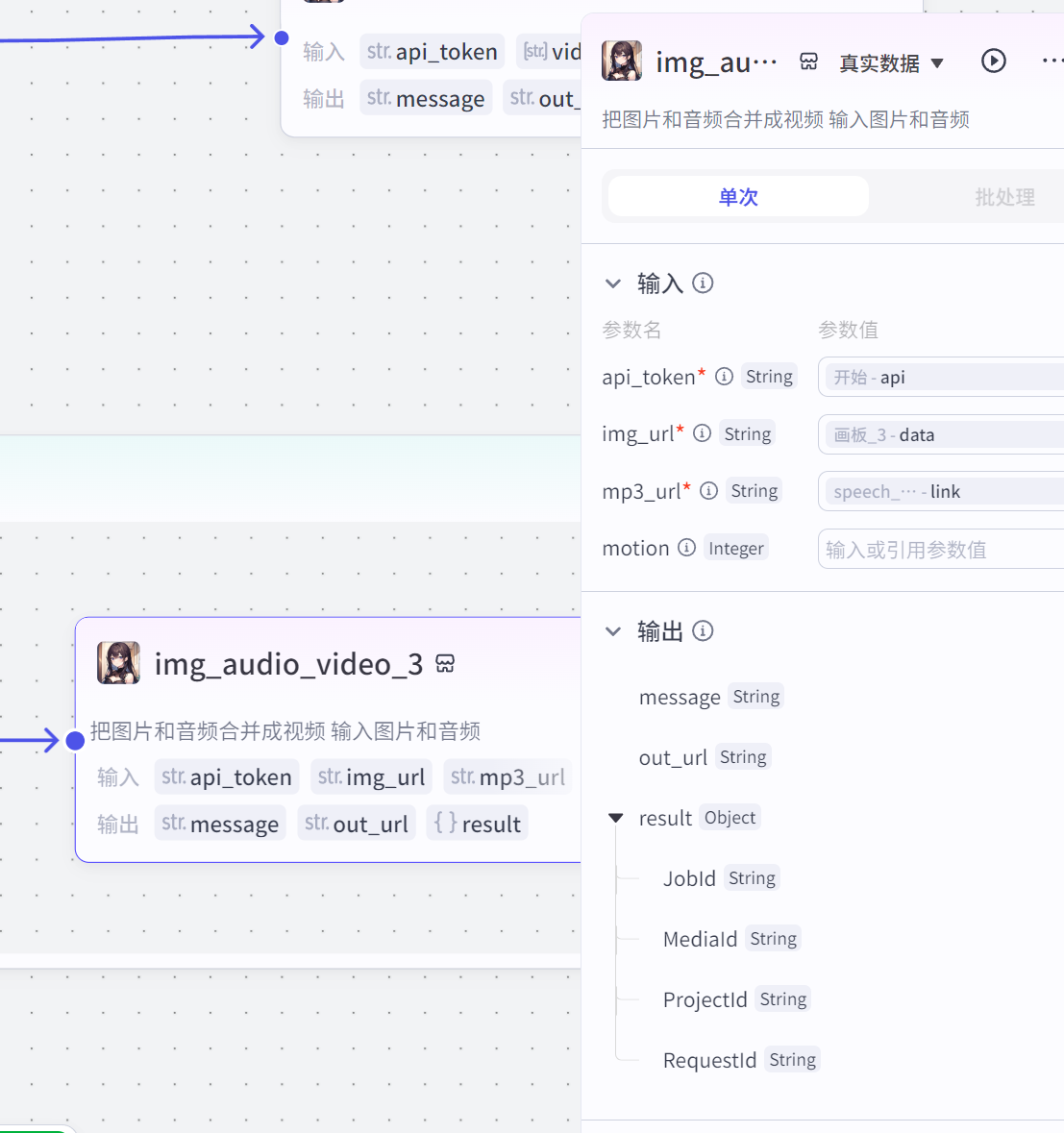
这个插件的img_audio_video的功能是把图片+视频合成,这样就实现了一段一段的口播新闻内容
第四步:成片导出
全自动视频合成这里使用的是多视频融合插件
- 一键导出成品
最后多段一句话口播图文视频出来后,将他们结合在一起,成为一整段视频,使用视频融合节点
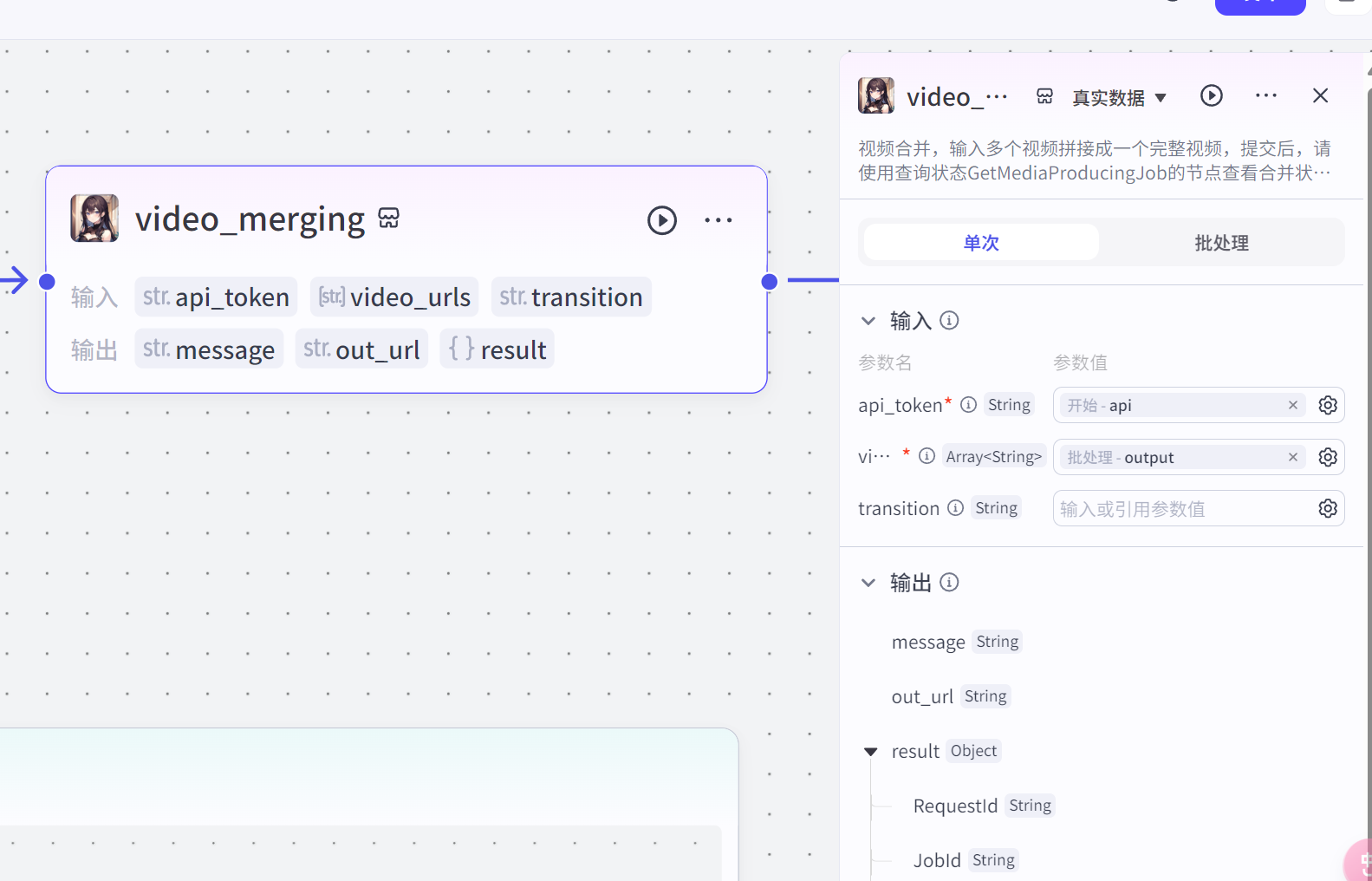
注意,节点产生的视频是异步生成,可能没办法马上展现,过几秒种后才处理完成出现,耐心等待
演示
可以在扣子商店体验,建议自己搭建一个,因为用的是我的水印(如果你不介意的话) V
🌟
嗨,我是Yeadon!
一名人工智能专业的大三学生,正在努力成为AI时代的超级个体~
- 欢迎大家加我交流讨论V: Yeadon888
- 个人主页:Yeadon(伊登)的个人说明书

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 40
40 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)