深度解读DeepSeek:发展历程
深度解读DeepSeek:开源周(Open Source Week)技术解读
深度解读DeepSeek:源码解读 DeepSeek-V3
深度解读DeepSeek:技术原理
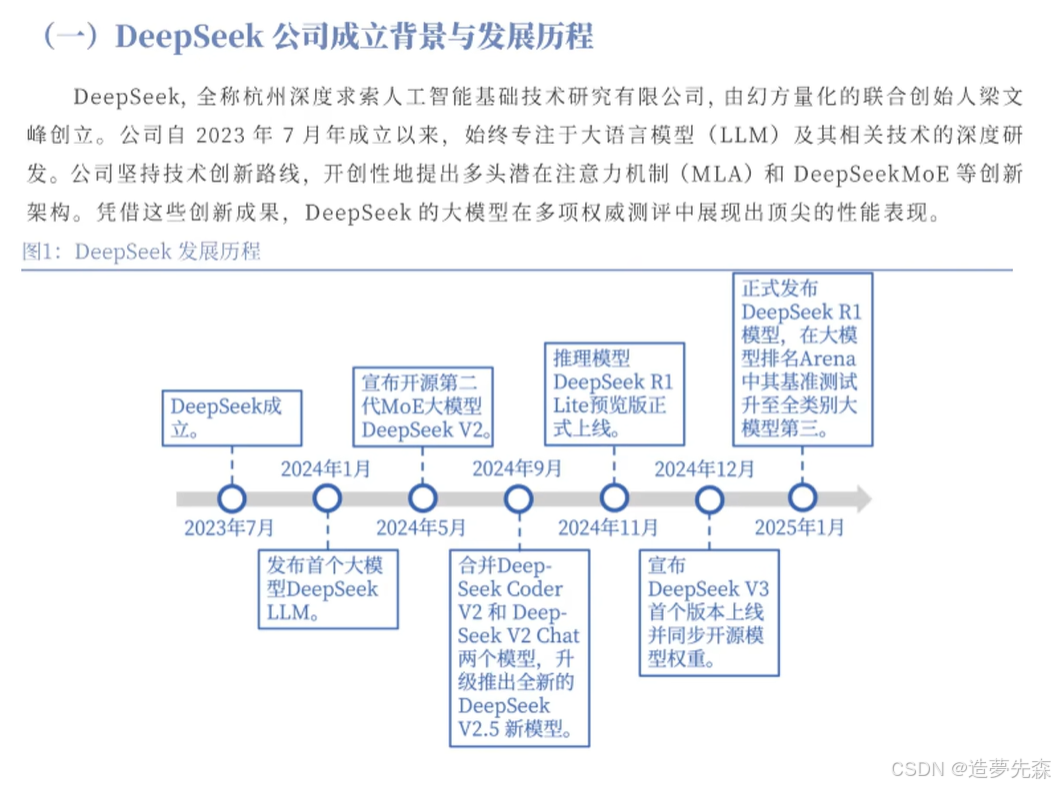
深度解读DeepSeek:发展历程
一、大模型模型发展路线

 大模型为什么叫大模型?就是因为它大,像传统的金融量化类的,可能用到几百个几千个参数够了,计算机视觉用20万个到100万个参数,而到文字模型最起码100万个起步,达到千亿级别。
大模型为什么叫大模型?就是因为它大,像传统的金融量化类的,可能用到几百个几千个参数够了,计算机视觉用20万个到100万个参数,而到文字模型最起码100万个起步,达到千亿级别。




二、DeepSeek V2-V3/R1技术原理


1,混合专家架构(DeepSeekMoE):DeepSeek采用动态稀疏激活的MoE架构:动态路由机制+专家模块激活。
DeepSeek的MOE跟普通MOE的最大区别在与:采用共享专家与细粒度专家划分机制。如上图所示,左侧的共享通用专家每个都激活,右侧选取topN的专业知识专家,最后汇总作为一个输出结果。因此总参数规模达236B但仅激活21B参数,降低计算冗余。而chatGPT基于密集激活的Transformer架构,所有参数在处理每个输入时均被激活。例如,GPT-4的1万亿参数全量参与计算,导致更高的算力需求
2,多头潜在注意力机制(MLA):通过低秩压缩优化Key-Value矩阵计算,结合旋转位置编码(RoPE),减少推理显存占用。
大模型说到底它是一个什么东西?它是个猜字游戏,猜一句话的下一个词是什么。DeepSeep的MLA=4,那就猜后面的4个词,速度就是4倍












DeepSeek V2、V3 和 R1 模型架构优化要点:
1、DeepSeek V2
- 混合专家架构(DeepSeekMoE):采用细粒度专家划分与共享专家机制,总参数规模达236B但仅激活21B参数,降低计算冗余34。
- 多头潜在注意力(MLA):通过低秩压缩优化Key-Value矩阵计算,结合旋转位置编码(RoPE),减少推理显存占用14。
- 训练数据扩展:预训练阶段使用8万亿token数据,通过平衡不同领域的数据采样提升模型泛化能力3。
2、DeepSeek V3
- 参数规模与效率平衡:总参数扩展至671B,结合动态稀疏激活机制,仅激活37B参数,实现更高性能与更低推理成本24。
- 动态专家选择优化:基于输入内容自适应分配计算资源,增强对复杂任务(如数学推理、代码生成)的适应性15。
- 多令牌预测(MTP):在训练阶段同时预测多个未来token,提升模型对上下文逻辑关系的捕捉效率45。
3、DeepSeek R1
- 检索增强生成(RAG)架构:采用双模块设计(检索模块+生成模块),结合外部知识库提升生成内容的准确性与实时性15。
- 强化学习策略:通过GRPO框架和人类反馈强化学习(RLHF),优化模型对齐能力与安全性25。
- 轻量化推理优化:结合DeepSeek-V3的稀疏激活特性,在AIME 2024等测试中实现接近GPT-4的性能但成本更低12。
演进关系:
- V2到V3的核心升级在于参数扩展(236B→671B)、动态专家选择优化以及MTP训练目标的引入24;
- R1基于V3的基础架构,强化检索增强生成与轻量化推理能力,聚焦垂直领域的高效应用
三、DeepSeek效应





四、未来展望





视频链接:
https://www.bilibili.com/video/BV1TzNVepEgY/?spm_id_from=333.337.search-card.all.click&vd_source=8066b0fe558a3d040eb762ed70ba335a

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)