【AI论文】SuperGPQA: 跨285个研究生学科的大型语言模型评估扩展
实验结果表明,当前最先进的LLMs在不同知识领域(例如,以推理为重点的模型DeepSeek-R1在SuperGPQA上取得了最高的61.82%准确率)的表现仍有显著提升空间,凸显了当前模型能力与通用人工智能之间存在的巨大差距。其次,项目团队提出了一种新颖的人机协作过滤机制,通过迭代精炼的方式消除琐碎或模糊的问题,从而提高了评估的针对性和有效性。实验结果表明,在不同轮次的评估中,模型的表现具有较高的
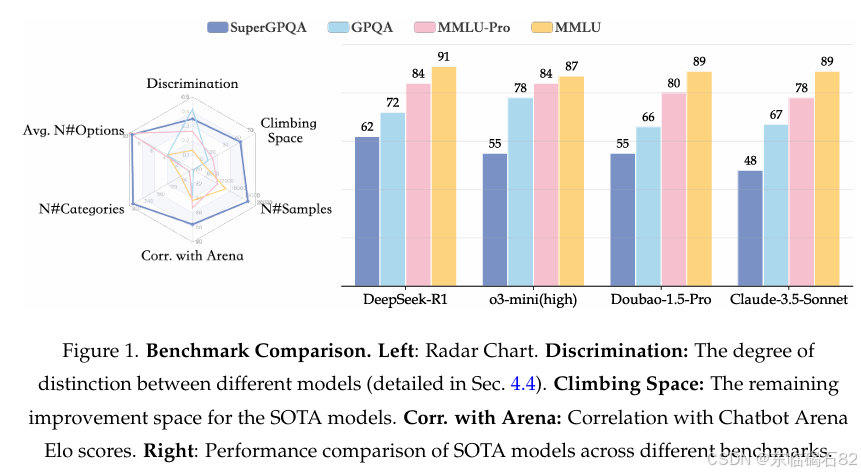
摘要:大型语言模型(LLMs)在数学、物理和计算机科学等主流学术领域已展现出卓越的能力。然而,人类知识体系涵盖超过200个专业学科,远远超出了现有基准的范围。在许多专业领域,尤其是轻工业、农业和服务导向型学科中,LLMs的能力仍未得到充分评估。为了填补这一空白,我们推出了SuperGPQA,这是一个跨285个学科全面评估研究生水平知识和推理能力的基准。我们的基准采用了一种新颖的人机(Human-LLM)协作过滤机制,通过基于LLM响应和专家反馈的迭代精炼,消除琐碎或模糊的问题。实验结果表明,当前最先进的LLMs在不同知识领域(例如,以推理为重点的模型DeepSeek-R1在SuperGPQA上取得了最高的61.82%准确率)的表现仍有显著提升空间,凸显了当前模型能力与通用人工智能之间存在的巨大差距。此外,我们还分享了管理大规模标注过程的全面见解,该过程涉及80多名专家标注员和一个交互式人机协作系统,为未来同等规模的研究项目提供了宝贵的方法论指导。Huggingface链接:Paper page,论文链接:2502.14739
1. 引言
大型语言模型(LLMs)在近年来取得了显著进展,尤其在主流学术领域如数学、物理和计算机科学中展现出卓越的能力。然而,人类知识体系极为庞杂,涵盖了超过200个专业学科,远远超出了现有基准测试的范围。特别是在轻工业、农业和服务导向型等专门领域中,LLMs的能力评估仍显不足。为了填补这一空白,SuperGPQA项目应运而生,旨在全面评估LLMs在285个不同学科中的研究生水平知识和推理能力。
SuperGPQA项目通过一种新颖的人机(Human-LLM)协作过滤机制,对大量候选问题进行筛选和精炼。这一过程不仅依赖于LLMs的响应,还结合了专家反馈,通过迭代的方式消除琐碎或模糊的问题,从而确保问题的质量和准确性。这一方法的采用,显著提高了评估的针对性和有效性,为全面评估LLMs的能力提供了坚实基础。
2. 数据收集与处理
在数据收集阶段,SuperGPQA项目采用了多种来源,包括教材、学术论文、在线课程资料等,以确保问题的广泛性和多样性。然而,初期由众包标注员收集的问题往往被专家标注员认为过于简单或不可靠,导致部分早期资金浪费在无效问题的标注上。为了解决这一问题,项目团队采用了更为严格的筛选和过滤机制,包括基于LLMs响应的初步筛选、专家标注员的详细审查以及基于准确性的进一步定制。
在数据处理方面,SuperGPQA项目实施了一系列严格的质量控制措施。首先,对候选问题进行了基于预定义规则的初步筛选,以快速识别和消除明显无效的数据点。随后,通过专家标注员的详细审查,对可疑问题进行进一步确认和修订。最后,还对问题的完整性、相关性和准确性进行了全面评估,以确保最终数据集的高质量。
3. 数据集统计与分析
SuperGPQA数据集涵盖了285个不同学科的问题,每个学科的问题数量和质量均经过严格控制和评估。数据集的统计结果显示,不同学科的问题长度、答案长度和选项数量存在显著差异。例如,一些理论性较强的学科(如物理学、数学)的问题往往较长且复杂,而一些应用性较强的学科(如工程学、管理学)的问题则相对简洁明了。
此外,SuperGPQA数据集还展示了不同学科在问题类型、难度和推理要求方面的多样性。一些学科的问题可能更侧重于理论知识的理解和应用,而另一些学科的问题则可能更侧重于实际问题的解决和推理能力的考察。这种多样性使得SuperGPQA数据集能够全面评估LLMs在不同知识领域中的表现。
4. 实验与结果
在实验阶段,SuperGPQA项目采用了多种基线模型进行评估,包括以推理为重点的模型(如DeepSeek-R1)和其他先进的大型语言模型。实验结果表明,当前最先进的LLMs在不同知识领域中的表现仍有显著提升空间。例如,在SuperGPQA数据集上,DeepSeek-R1模型取得了最高的61.82%准确率,但仍远低于人类专家的表现水平。
此外,实验还揭示了LLMs在不同学科中的表现差异。一些学科的问题可能更适合LLMs的处理方式(如语言学、文学等),而另一些学科的问题则可能更具挑战性(如物理学、数学等)。这种差异表明,未来需要针对不同学科的特点开发更加专门化的LLMs,以提高其在特定领域中的表现。
5. 学科鉴别力分析
为了评估SuperGPQA数据集的学科鉴别力,项目团队对不同学科的问题进行了详细分析。结果表明,SuperGPQA数据集能够准确区分不同学科的问题,并在一定程度上反映出各学科之间的知识差异和推理要求。这种鉴别力不仅有助于全面评估LLMs在不同学科中的表现,还为未来的模型开发和优化提供了重要参考。
6. 子领域信息的影响
为了探究子领域信息对模型性能的影响,SuperGPQA项目还进行了一系列零样本评估实验。实验结果表明,在提示中包含子领域信息的条件下,模型的表现通常会有所提升。这是因为子领域信息有助于模型更好地理解问题的背景和上下文,从而更准确地回答问题。然而,对于较小规模的模型来说,子领域信息的引入可能并不会带来显著的性能提升。
7. 评估的鲁棒性
为了确保评估的鲁棒性和可靠性,SuperGPQA项目对评估过程进行了多次重复和验证。实验结果表明,在不同轮次的评估中,模型的表现具有较高的一致性,表明SuperGPQA数据集的评估结果是稳定和可靠的。这种鲁棒性不仅有助于准确评估LLMs的能力水平,还为未来的模型比较和优化提供了有力支持。
8. 大规模标注过程的管理
SuperGPQA项目涉及大规模的数据标注过程,需要协调和管理众多专家标注员和众包标注员的工作。为了确保标注质量和效率,项目团队采用了一系列有效的管理策略和方法。例如,通过制定详细的标注指南和培训计划,提高标注员的专业水平和一致性;通过建立有效的沟通机制和反馈机制,及时解决标注过程中遇到的问题和困难;通过实施严格的质量控制措施和评估标准,确保最终标注结果的高质量和高准确性。
9. 方法论指导
SuperGPQA项目的成功经验为未来同等规模的研究项目提供了宝贵的方法论指导。首先,项目团队强调了数据质量和准确性的重要性,并采用了多种措施来确保数据的高质量和准确性。其次,项目团队提出了一种新颖的人机协作过滤机制,通过迭代精炼的方式消除琐碎或模糊的问题,从而提高了评估的针对性和有效性。最后,项目团队还分享了大规模标注过程的管理经验和策略,为未来类似项目提供了有益的参考和借鉴。
10. 结论与展望
综上所述,SuperGPQA项目通过全面评估LLMs在285个不同学科中的研究生水平知识和推理能力,揭示了当前最先进的LLMs在不同知识领域中的表现仍有显著提升空间。未来,需要针对各学科的特点开发更加专门化的LLMs,以提高其在特定领域中的表现。同时,还需要继续探索和优化人机协作机制和数据标注过程,以提高评估的准确性和效率。此外,SuperGPQA项目的成功经验也为未来同等规模的研究项目提供了宝贵的方法论指导和实践参考。
展望未来,随着LLMs技术的不断发展和完善,我们有理由相信,在不久的将来,LLMs将在更多领域展现出其卓越的能力和潜力。而SuperGPQA项目作为全面评估LLMs能力的重要基准之一,也将继续发挥其重要作用,推动LLMs技术的不断进步和应用拓展。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 34
34 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)