docker + vllm 从零开始快速上手, 以部署DeepSeek-R1-Distill-Qwen-7B为例
本文手把手教你从零开始,以部署 DeepSeek-R1-Distill-Qwen-7B 模型为例,带你轻松搞定高性能推理服务!无论你是初学者还是进阶开发者,都能通过这篇教程快速上手,让复杂的模型部署变得简单高效。Docker 的便捷性与 vLLM 的强大性能结合,助你一步跨入大模型应用开发的前沿领域
在开始之前,请确认已准备好以下环境
-
Linux操作系统
-
Nvidia 显卡, 在shell中执行
nvidia-smi以确认驱动正确安装, 并且cuda的版本 >= 12.4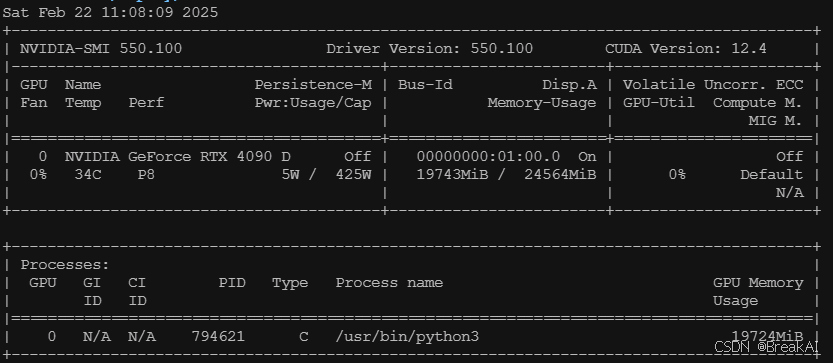
-
docker 以及 nvidia-docker (点击此处查看安装教程)
注意:本文不包含任何vllm原理解析,请放心阅读 😎
vllm
目前关于DeepSeek-R1部署的教程大多数都是使用ollama进行部署,其方便程度确实是不可否认的,但是对于专业用户如后端开发、运维来说,我们希望获得更高的并发,更高的吞吐,那vllm就是最合适的选择了,特别是v0.7之后vllm迎来了重大的更新, 获得了更高的吞吐速度。
当然sglang也是个不错的选择
首先,拉取vllm的镜像,在shell中执行如下命令
sudo docker pull vllm/vllm-openai:v0.7.1
该镜像在模型部署之后,可直接间使用openai的sdk进行对接,特别方便
镜像拉取完成之后,我们进入模型下载的操作
下载 DeepSeek-R1-Distill-Qwen-7B
从HF上下载模型DeepSeek-R1-Distill-Qwen-7B , 下载地址 点击下载
如果速度较慢可以配置加速地址,操作方法如下
export HF_ENDPOINT=https://hf-mirror.com
之后直接clone repo
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
也可直接从MdoelScope 上下载,点击前往
部署 DeepSeek-R1-Distill-Qwen-7B
由于财力限制,本文选择以 DeepSeek-R1-Distill-Qwen-7B 为例来说明如何使用vllm部署R1系统的蒸馏模型,如果参数量大于7B则调整对应的显卡数量以及-tp参数即可。
为了方便运维,本文使用docker compose 进行部署,部署的yaml文件如下:
vllm:
container_name: vllm
restart: no
image: vllm/vllm-openai:v0.7.1
ipc: host
volumes:
- ./models:/models
command: ["--model", "/models/DeepSeek-R1-Distill-Qwen-7B", "--served-model-name", "r1", "--max-model-len", "8912", "--max-num-seqs", "32", "--gpu-memory-utilization", "0.90"]
ports:
- 8000:8000
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
接下来本文将分块对该部署文件的内容进行说明
1. 服务名称与容器名
vllm:
container_name: vllm
vllm: 定义了一个名为vllm的服务。container_name: vllm: 指定了运行时容器的名字为vllm,方便通过该名字管理容器。
举例:查看日志时执行sudo docker logs -f vllm 即可
2. 自动重启策略
restart: no
restart: no: 表示容器不会在崩溃或主机重启后自动重启。
如果是生产环境建议为: always, 以确保在爆显存的时候自动重启容器以便恢复服务
3. 镜像信息
image: vllm/vllm-openai:v0.7.1
image: vllm/vllm-openai:v0.7.1: 使用了来自 Docker Hub 的镜像vllm/vllm-openai,版本为v0.7.1。vllm是一个高性能的大语言模型推理引擎,支持 OpenAI 兼容接口。- 版本号
v0.7.1确保使用的是特定版本的镜像,避免因镜像更新导致的行为变化。
4. IPC 命名空间共享
ipc: host
ipc: host: 容器将与主机共享 IPC(进程间通信)命名空间。- 这通常用于需要高性能通信的场景,例如 GPU 加速任务。
- 注意:此配置可能会影响隔离性,需谨慎使用。
5. 卷挂载
volumes:
- ./models:/models
volumes: 定义了卷挂载,将主机目录./models挂载到容器内的/models路径。- 用途: 容器可以访问主机上的模型文件夹,确保模型数据可以在主机和容器之间共享。
- 注意: 确保
./models目录存在,并包含所需的模型文件, 将下载好的DeepSeek-R1-Distill-Qwen-7B模型保存到此目录中
6. 启动命令
command: ["--model", "/models/DeepSeek-R1-Distill-Qwen-7B", "--served-model-name", "r1", "--max-model-len", "8912", "--max-num-seqs", "32", "--gpu-memory-utilization", "0.90"]
command: 定义了容器启动时执行的命令及其参数。--model /models/DeepSeek-R1-Distill-Qwen-7B: 指定加载的模型路径为/models/DeepSeek-R1-Distill-Qwen-7B。--served-model-name r1: 设置服务端暴露的模型名称为r1,客户端可以通过该名称调用模型。--max-model-len 8912: 设置模型最大输入长度为 8912 个 token。--max-num-seqs 32: 设置最大并发序列数为 32。--gpu-memory-utilization 0.90: 设置 GPU 内存利用率为目标值的 90%。
请根据实际情况对 max-model-len 以及 max-num-seqs 、gpu-memory-utilization 这三个参数进行调整,上下文越长占用的显存越多同时需要对max-num-seqs进行下调,否则会爆显存
7. 端口映射
ports:
- 8000:8000
ports: 定义了端口映射规则。8000:8000: 将容器的 8000 端口映射到主机的 8000 端口。- 用途: 允许外部通过主机的 8000 端口访问容器中的服务。
8. GPU 资源分配
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
-
deploy: 定义了部署资源限制。resources.reservations.devices: 指定需要的设备资源。driver: nvidia: 使用 NVIDIA GPU 驱动。count: all: 分配所有可用的 GPU。(也可以为[0]因为本机只有一张显卡, 如果需要指定GPU,则填入对应的序号即可如[3,4] 则指定使用3,4号显卡)capabilities: [gpu]: 请求 GPU 计算能力。
-
用途: 将主机上的GPU资源全部映射到容器中,以便vllm容器可以使用宿主机上的GPU资源
R1, 启动!
在docker-compose.yaml 文件所在目录中执行以下命令
sudo docker compose up -d
执行, 查看vllm日志, 发现vllm已启动完成并且在8000端口监听
sudo docker logs -f vllm
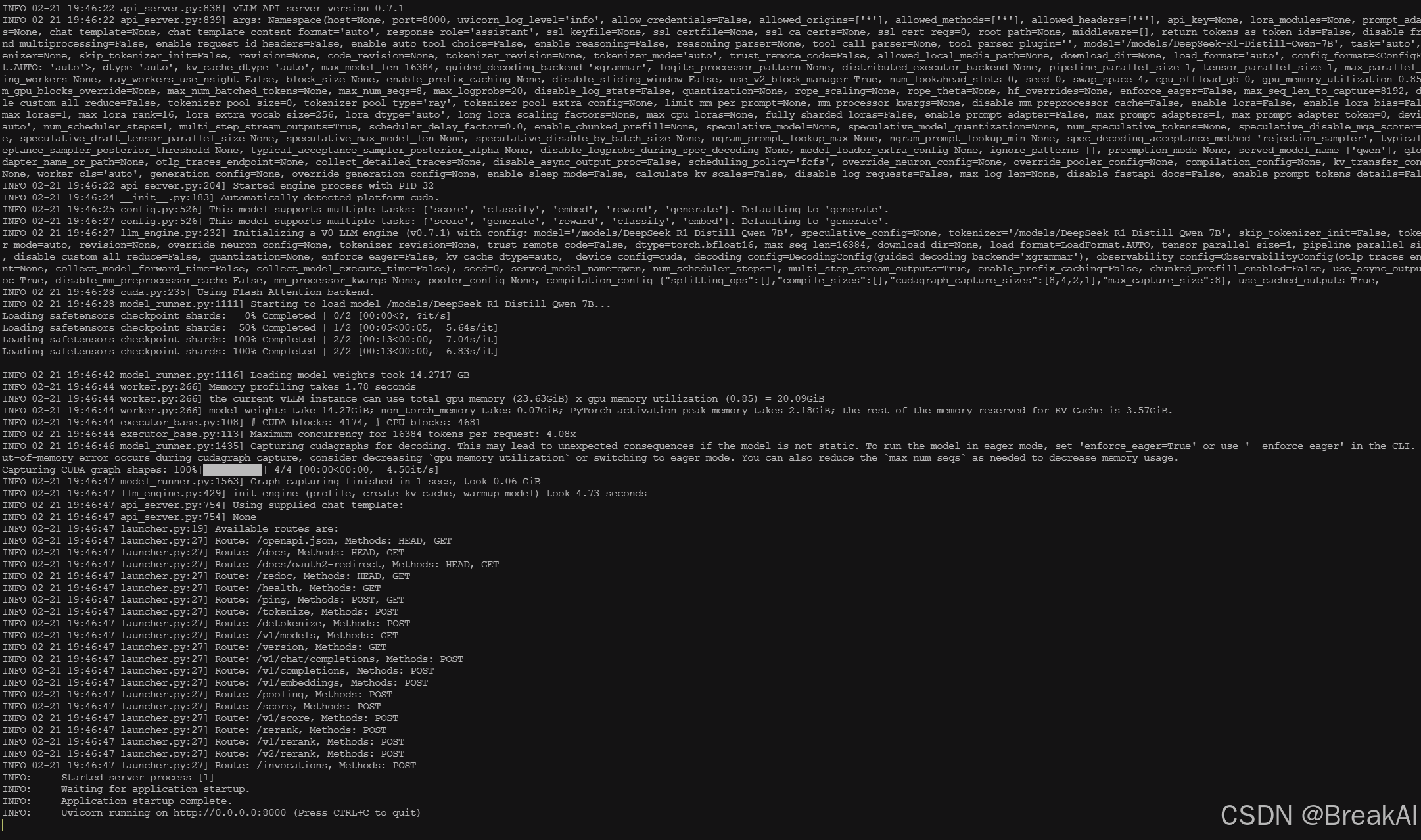
使用OpenAI SDK 调用
from openai import OpenAI
vllm_client = OpenAI(
# 由于我们启动vllm时未配置key, 因此此处可随意填写
api_key="NOT_NEED",
# 改成实际部署的IP
base_url="http://127.0.0.1:8000/v1",
)
response = vllm_client.chat.completions.create(
# 对应served_model_name
model='r1',
messages=[
{'role': 'user', 'content': '你好'}
]
)
print(response.choices[0].message.content)
关注我,将持续分享AGI生产级别的实践

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)