【Qwen2.5-VL-3B-Instruct微调,单卡A800-PCIE-80GB复现VLM-R1】VLM-R1:DeepSeek R1方法成功迁移到视觉领域,多模态AI迎来新突破
源码:https://github.com/om-ai-lab/VLM-R1
链接:重磅!DeepSeek R1方法成功迁移到视觉领域,多模态AI迎来新突破
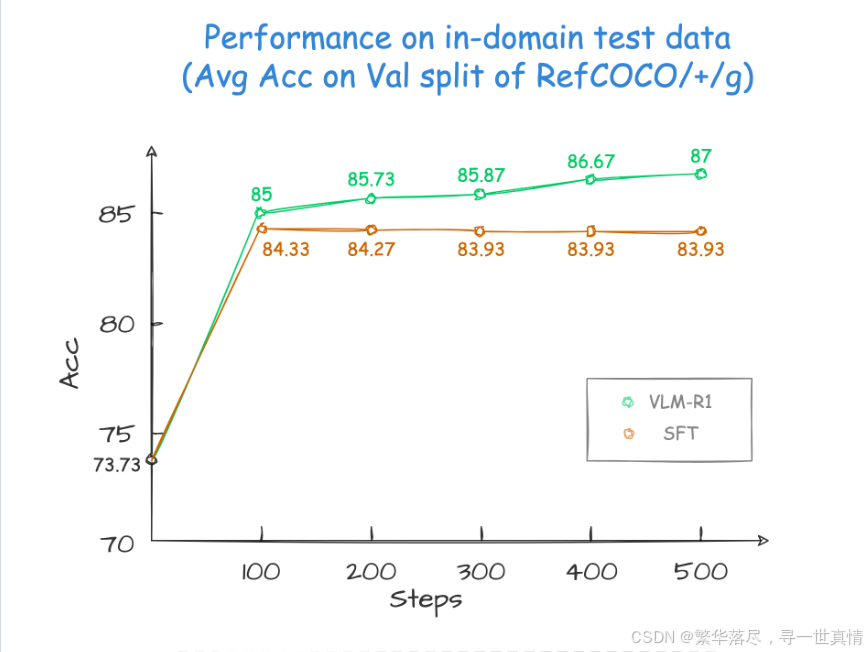
训练和测试领域的差异对比:域内
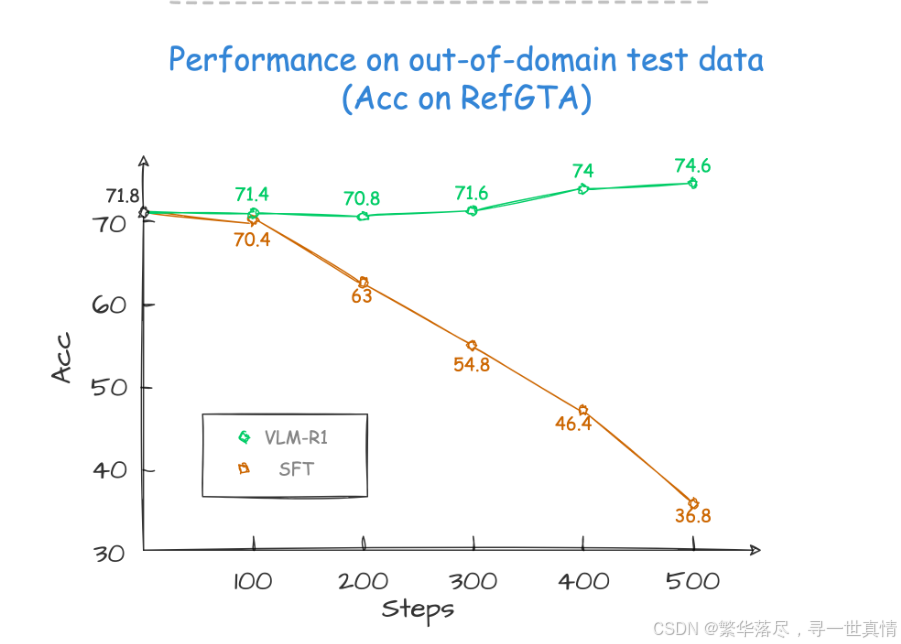
训练和测试领域的差异对比:域外
怀着满怀期待的心情,看着重磅!DeepSeek R1方法成功迁移到视觉领域,多模态AI迎来新突破的标题。本人也准备加入到视觉的R1强化学习中。开始以为是3B的模型,很容易进行训练,于是大张旗鼓的在kaggle将训练环境配置好,奈何需要的显示太大,崩了。于是有转移到windows4080s上,奈何Qwen2.5-VL的训练环境需要linux。于是又租了台V100-SXM2-32GB,想着32G的应该可以训练起来吧,结果还是GG了,奔溃了,这就不是平民玩的。于是又从Qwen2.5-VL-3B-Instruct转战到Qwen2-VL-2B-Instruct。结果还是GG了,报RuntimeError: FlashAttention only supports Ampere GPUs or newer.说是需要使用A100, RTX 3090, RTX 4090。奔溃了,下级明天租A100。
于是乎,第二天又爬起来租40G的A100,Qwen2.5-VL-3B-Instruct果然还是GG了。于是只能微调Qwen2-VL-2B-Instruct试试。结果还GG了,OMG!!!!
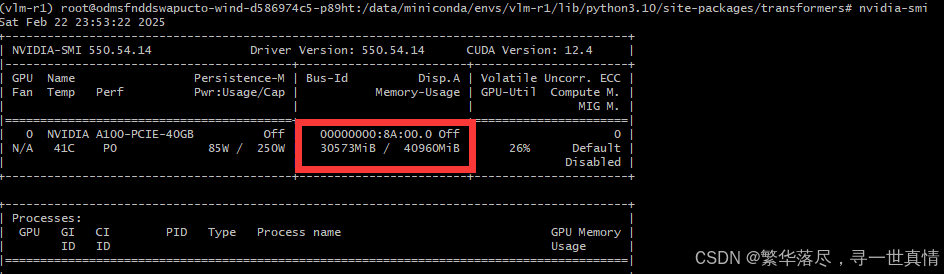
折腾了半天,想到一个办法,将预训练模型的权重冻结起来,只训练特定层。于是巴拉巴拉transformers库中的代码。最终在modeling_qwen2_5_vl.py找到模型结构,想着将视觉特征提取器给冻结起来,只训练self.model和self.lm_head,结果不出所料,OOM了。于是又将self.model给冻结,只训练self.visual和self.lm_head。结果终于可以在40G的A100上训练了。显存占用30575MiB / 40960MiB。
p89ht:/data/miniconda/envs/vlm-r1/lib/python3.10/site-packages/transformers/models/qwen2_5_vl/modeling_qwen2_5_vl.py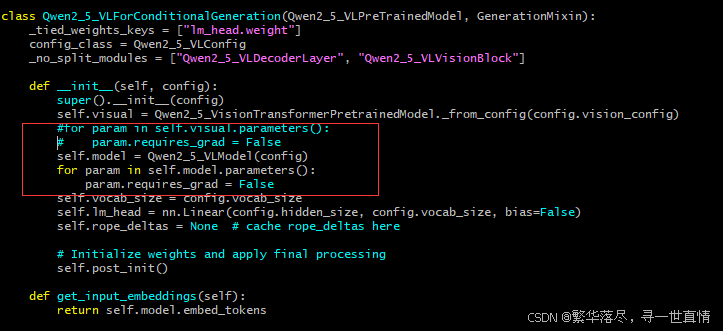
在看训练日志,2366小时?我去,果断放弃了。本身冻结self.model都不确定是否有效果,结果一下子这么多小时。果然还是需要在大显卡分布式训练。

再次不甘心的我,觉得租单卡A800-PCIE-80GB,一小时6元,都可以吃几根淀粉肠了。于是有大张旗鼓的配置环境了,结果还是GG了,于是我就将配置改小。在src/open-r1-multimodal/run_grpo_rec.sh添加–gradient_checkpointing true 的参数,qwen2-vl模型推理代码,以及min_pixels和max_pixels设置。修改 min_pixels 和 max_pixels 参数。终于可以训练了…
cd src/open-r1-multimodal
export DEBUG_MODE="true"
export CUDA_VISIBLE_DEVICES=0
RUN_NAME="Qwen2.5-VL-3B-GRPO-REC"
export LOG_PATH="./debug_log_$RUN_NAME.txt"
torchrun --nproc_per_node="1" \
--nnodes="1" \
--node_rank="0" \
--master_addr="127.0.0.1" \
--master_port="12346" \
src/open_r1/grpo_rec.py \
--deepspeed local_scripts/zero3.json \
--output_dir output/$RUN_NAME \
--model_name_or_path /data/coding/VLM-R1/Qwen2.5-VL-3B-Instruct \
--dataset_name data_config/rec.yaml \
--image_root /data/coding/VLM-R1/ \
--max_prompt_length 512 \
--num_generations 4 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 2 \
--logging_steps 1 \
--bf16 \
--torch_dtype bfloat16 \
--data_seed 42 \
--report_to wandb \
--gradient_checkpointing true \
--attn_implementation flash_attention_2 \
--num_train_epochs 2 \
--run_name $RUN_NAME \
--save_steps 100 \
--save_only_model true
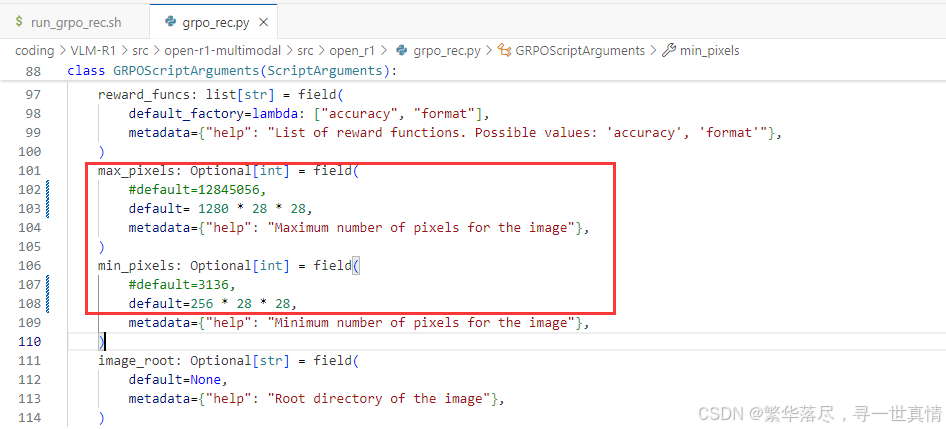
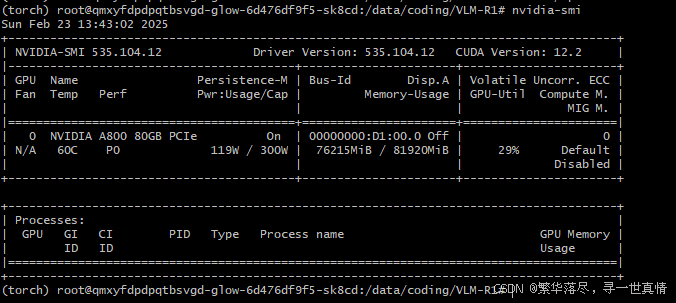
期待中,训练到step=100时,可以看到是正常了,看线显存占用76215MiB / 81920MiB,乖乖,挺大的:
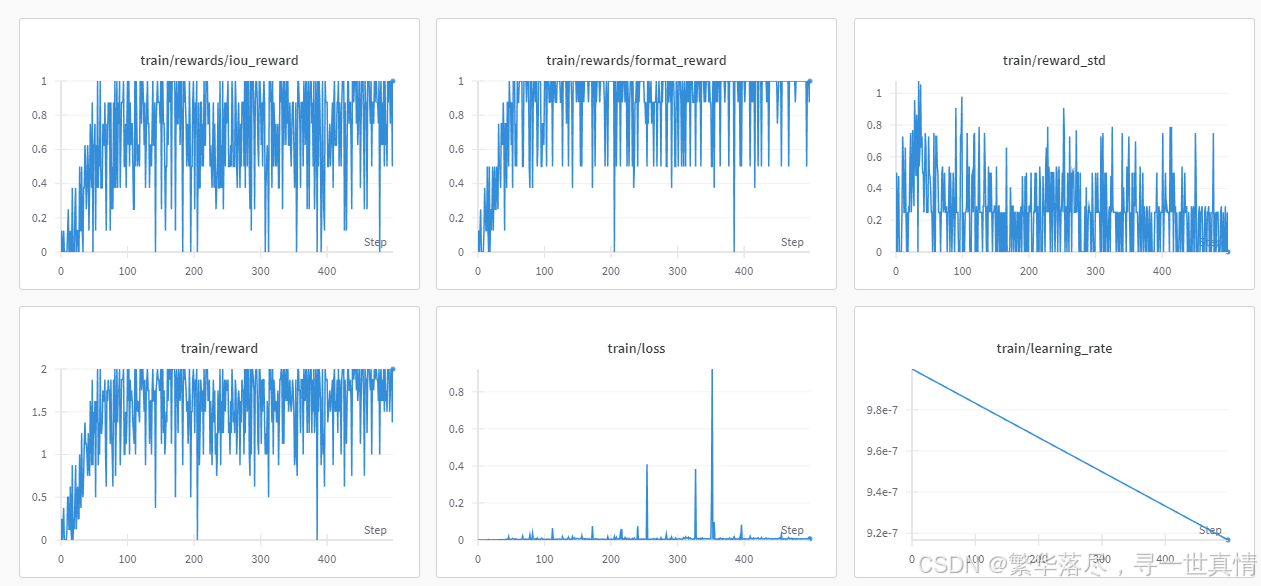
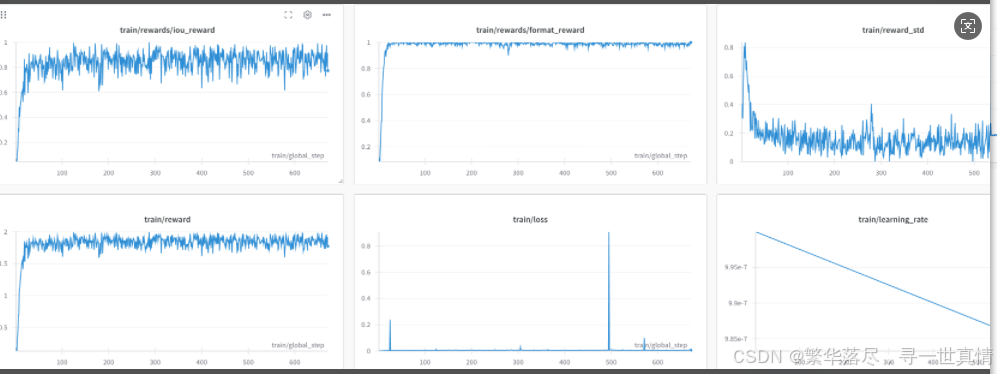
从训练指标图可以看到,已经很接近VLM-R1项目提供的训练图
自己训练(与VLM-R1的差异可能是自己修改的低配置导致的)
原图

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)