一文深度解析DeepSeek:【技术原理+开发实践+行业应用】【为啥DeepSeek能火爆出圈】【9000+字】
MLA、MoE、MTP 三者结合,使 DeepSeek 既具备超⼤模型容量(因 MoE 稀疏扩张)和⾼训练效率(因 MLA、MTP ),⼜能在⻓序列或复杂推理中保持性能不衰减。不过趁着DeepSeek这个热度,不同的厂商有着不同的考量:有人卷模型上架,算力适配,主卖铲子;这套全栈式创新为 DeepSeek‐R1、V3 等系列模型的成功提供了坚实⽀撑,使其在与 GPT-4 等巨型闭源模型的竞争中,依

目录
零、DeepSeek是什么
1、概述
- DeepSeek是幻方量化于2023年7月创立的大模型子公司,创始人为梁文锋,公司出圈时大概有140多人;
- 2023年11月,其发布第一个同名AI大模型 DeepSeek LLM
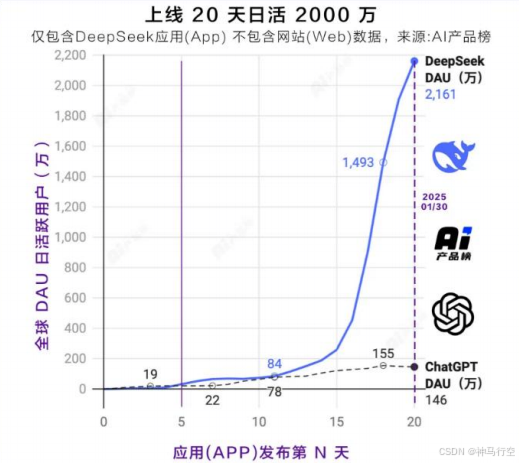
- 2025年1月20日,DeepSeek R1正式发布,为对标 OpenAI o1正式版的高性能推理模型;R1上线后火速出圈,其应用创造了全球 APP 历史上增长最快的记录
官网:DeepSeek

2、发展历程
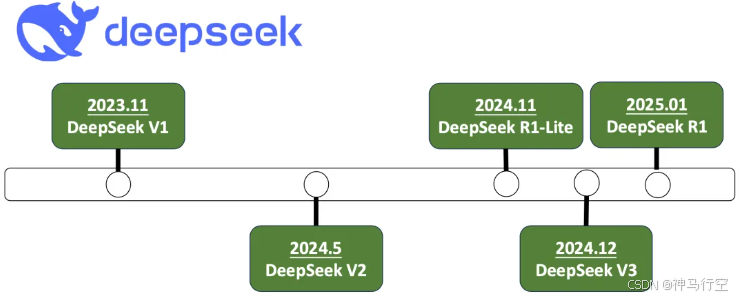
3、家族产品
一、技术解析
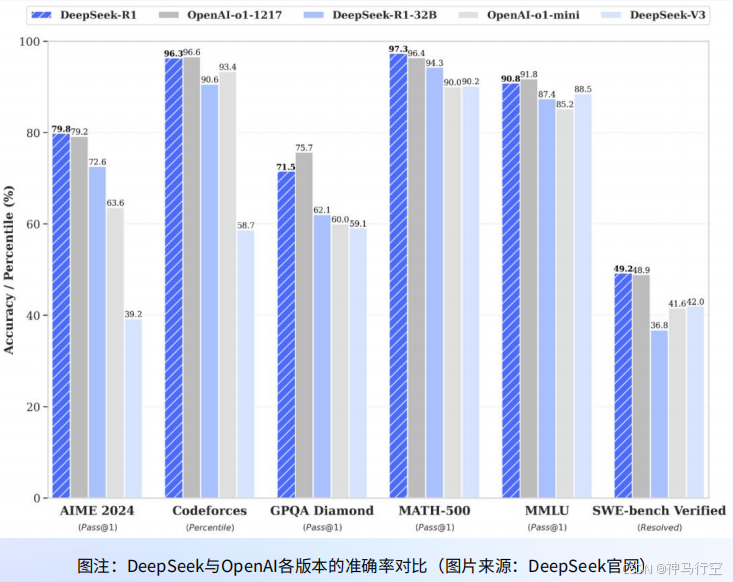
1.1、DeepSeek R1的三大特点
- 高性能:推理表现媲美OpenAI o1正式版
- 开源:R1开源,并公开训练技术,允许开发者访问和学习
- 低成本:R1开发成本仅为OpenAI o1的2%左右
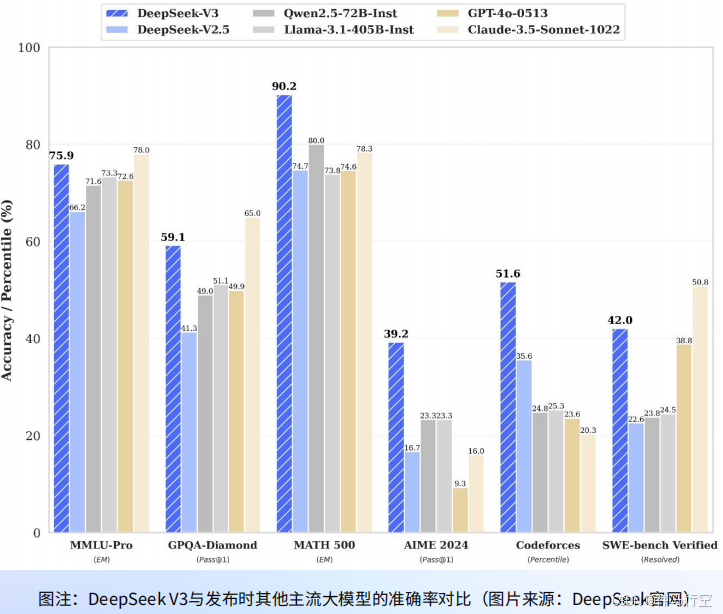
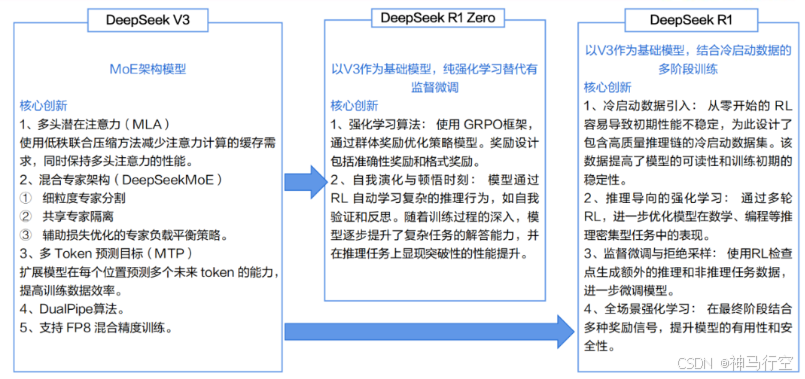
1.2、R1的基座模型V3
1、V3模型的特征
- V3是2024年12月发布的自研MoE模型;
- 参数与GPT-4大致在同一个数量级:V3有671B参数,每个Token的计算激活约37B;
- 在14.8T tokens上进行了预训练;
2、R1在DeepSeek V3基础上进行了开发
- V3:对标GPT-4o,通过指令微调和偏好微调提升性能;
- R1:专注于推理能力;
1.3、R1的变体和技术路线
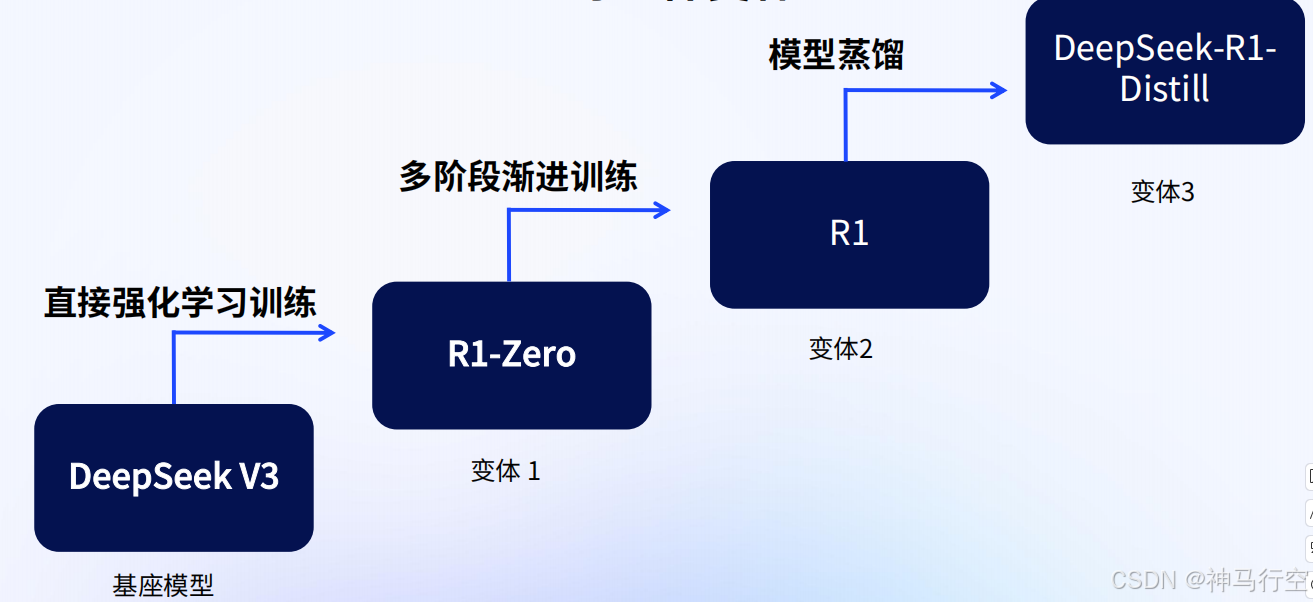

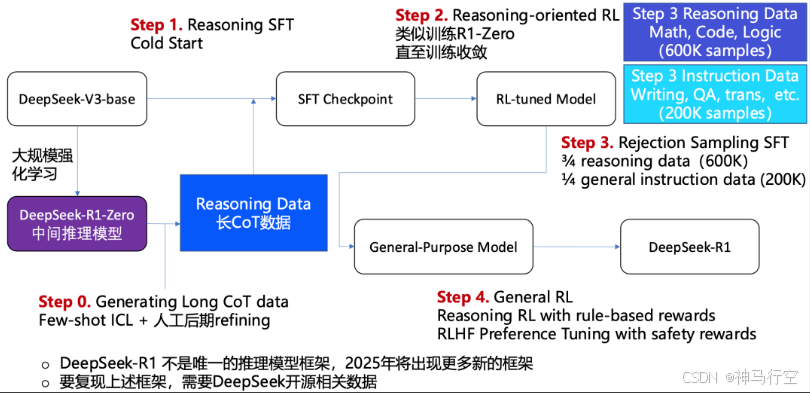
1.4、各系列主要创新点
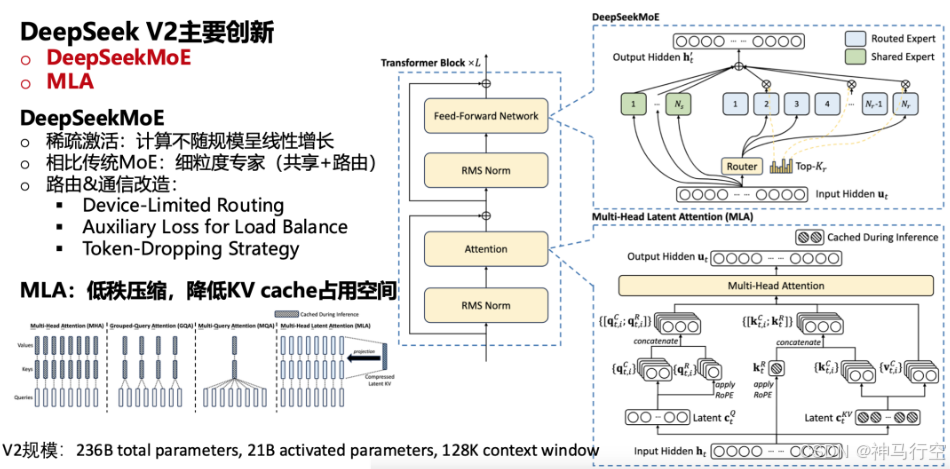
1.4.1、V2主要创新
1.4.2、V3主要创新

1.4.3、R1主要创新
- DeepSeek-R1-Zero:大规模RL训练,发现了RL训练的ScalingLaws,RL训练涌现“aha”时刻;
- 推理模型训练技术框架:4步法,有效解决了R1-Zero存在问题,将推理与对齐合为一体;
- 强化学习训练框架:GRPO,来自DeepSeekMath,降低了强化学习训练成本;
- 推理模型蒸馏:将大模型推理能力蒸馏到小模型,优于小模型直接进行推理训练(规模效应);
1.5、核心技术
在有限算力与资金投入的前提下,DeepSeek之所以能训练出与国际顶尖大模型相当、甚至在某些维度更具优势的模型,主要归功于在数据、模型、系统、硬件四大关键环节的系统性创新。
1.5.1、数据维度
数据集准备创建:极少人工标注+强机器自学习。
1、小样本人工标注与基础对齐
- 初步监督微调(SFT):DeepSeek通过较少量的人工标注数据(仅占总训练样本的极小比例)完成模型的基本对齐(比如,在对话场景上,标注人员会提供一小部分高质量问答实例;在数学、编程等特定领域,则人工编写部分精细的解决方案,以让模型在早期具备正确的思路和格式);
- 人工标注与模型生成相结合:人工标注数据用于“矫正”模型对话风格、格式一致性;模型自动生成+自动判分则承担起“大规模、细粒度”教学的主力;

2、自动判分与机器自学习
- 针对可验证任务的自动评分:
- 数据题:只要题目有明确的数值/方程解,就可在模型生成答案后,用脚本或数学工具进行验证;若回答正确则给模型正向奖励,否则给予惩罚或较低得分。
- 编程题:使⽤⾃动化测试框架/编译器验证结果;如通过全部测试⽤例,则评为“正确答案”。
- 作⽤:⼤量降低对⼈⼯批改的需求;模型能快速迭代并“学会”更严格的逻辑推理与调试思路。
- 针对开放性任务的奖励模型:
- 奖励模型(RM):当问题缺少客观判分标准时(如开放式问答、创意写作),DeepSeek 在内部还训练了⼀个或⼀组“奖励模型”⽤于打分。这些奖励模型通常以⼈⼯精选的数据微调⽽来,能帮助识别回答的合理性、连贯性与价值。
- 群体相对策略优化(GRPO):并⾮传统⼤规模 RLHF,需要⼤量⼈类反馈;⽽是将新旧策略(Policy)的回答两两对⽐,让模型⾃主选择更优答案,逐步淘汰较差策略,减少对⼈⼯⼲预的依赖。

3、“AI 教 AI”的循环自增强
- 模型⾃⽣成样本:在某些逻辑推理场景⾥,DeepSeek 也会调⽤⾃家先前或其他版本模型(如 R0、V3 的专家组件)⽣成初步解答,再由新模型进⾏对⽐学习或判分。
- 数据规模与多样性:通过机器⾃学习机制,可快速扩展到海量的问答/推理对,让模型⾯对多样化场景;强化学习过程中,“有错误的样本”也能成为宝贵素材,帮助模型持续纠错与收敛。
4、效果与意义
- ⼤幅减少⼈⼯成本:传统⼤模型往往需要数百甚⾄上千⼈进⾏标注,DeepSeek 则依赖机器⽣成、⾃动判分,⼤幅削减了⼈⼒投⼊。
- 加速模型⾃适应:通过⾃动化强化学习流程,模型能够持续“⾃纠⾃学”,更新迭代速度提⾼。
- 更深度的推理能⼒:数学、编程等可客观判定的任务特别适合机器评分,让模型得到更丰富、准确的训练反馈,推动了DeepSeek‐R1 在严谨推理领域的表现。
1.5.2、模型维度
模型训练架构创新:MLA + MoE + MTP
针对⼤规模语⾔模型(LLM),DeepSeek 在核⼼架构层⾯结合了多头潜在注意⼒(MLA)、混合专家(MoE)以及多 Token 并⾏预测(MTP)三⼤关键模块,形成了性能与效率兼顾的定制化Transformer 变体。
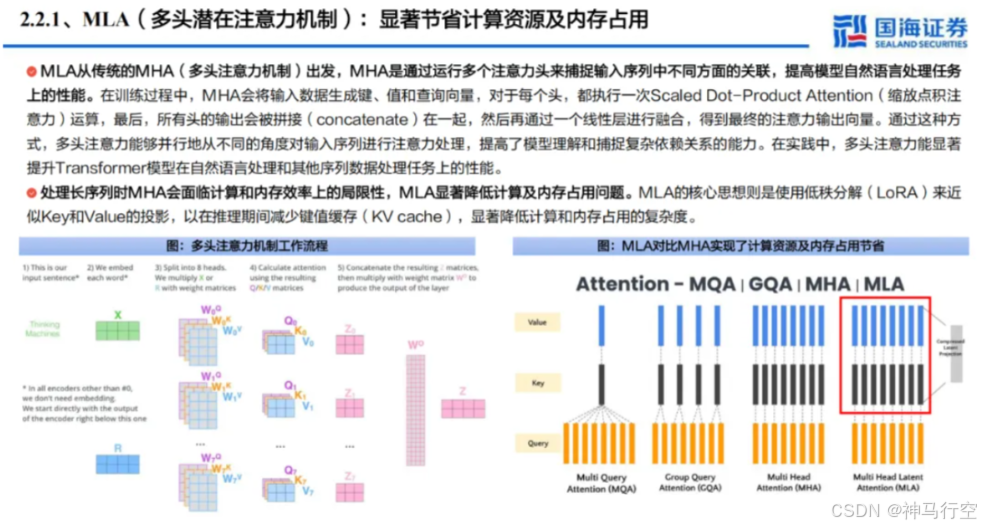
1、多头潜在注意力(MLA,Multi-Head Latent Attention)
- 基本原理
- 传统多头⾃注意⼒需要在⻓⽂本时保存庞⼤的 Key/Value 矩阵;
- MLA 先将 Key/Value 投影(Projection)到更低维的“潜在空间”(Latent Space),减少存储与计算量。
- 优势
- 节省计算资源和降低显存占⽤:在⻓序列场景下,KV 缓存占⽤显存量显著减少;
- 运算效率提升:因为 Key/Value 在投影前就已降维,后续注意⼒计算量随之降低;
- 与标准多头相当的性能:实测显示,通过适当的投影维度和归⼀化操作,MLA 在准确度与传统多头注意⼒相差⽆⼏,却能显著节省资源。
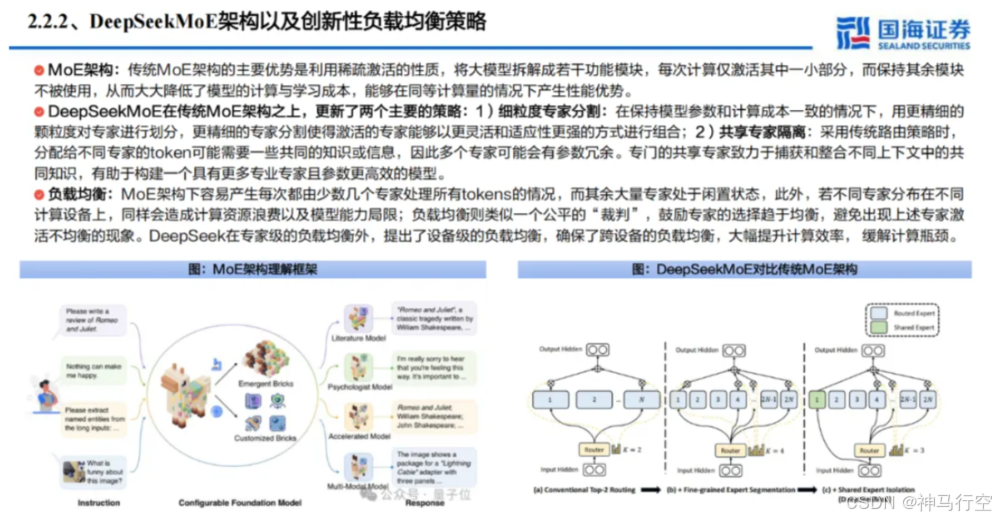
2、混合专家(MoE,Mixture of Experts)
- 稀疏激活原理
- 将模型划分为⼤量“专家⽹络”(Expert),每个专家负责不同类型或领域的特征提取;
- 在⼀次前向推理时,仅激活少数专家来处理输⼊ Token,⼤⼤降低实际计算量。
- DeepSeekMoE 的改进
- ⽆辅助损失的负载均衡策略:传统 MoE 模型常需额外引⼊均衡损失(如 Auxiliary Loss)来防⽌“热⻔专家”过载;
- DeepSeek 设计了⼀套可训练偏置(Trainable Bias)与动态路由机制,让各专家⾃动分配流量,减轻了额外超参的调优负担。
- 扩展到超⼤参数
- 在理论上可将参数规模拓展⾄数千亿甚⾄万亿级,但由于稀疏激活,模型实际推理时的计算量仍相对有限;
- DeepSeek‐V3(6710 亿参数)与 R1(6600 亿)均采⽤此架构实现⾼容量与可控推理成本并存。
3、多Token并行预测(MTP,Multi-Token Parallelism)
- ⾃回归模型的优化:常规 Transformer 在训练阶段⼀次仅⽣成下⼀个 Token,需重复多轮前向传播;MTP 则允许在⼀次前向中并⾏预测若⼲后续 Token,显著提升训练效率。
- 收益:
- 加速收敛:更多训练信号在同⼀时间段内产⽣;
- 增强连贯性:模型同时考量多个后续 Token 的交互,利于⽣成端的全局语义⼀致性;
- 减少重复计算:在训练阶段显著缩减迭代次数,降低总算⼒开销。
4、综合优势
MLA、MoE、MTP 三者结合,使 DeepSeek 既具备超⼤模型容量(因 MoE 稀疏扩张)和⾼训练效率(因 MLA、MTP ),⼜能在⻓序列或复杂推理中保持性能不衰减。这套定制的 Transformer 变体在DeepSeek‐V3、R1 中均得到验证,对提升模型质量与降低训练成本⽴下“核⼼功劳”。
1.5.3、系统维度
算力调配系统创新:HAL-LLM、负载均衡、FP8等
在⼤模型训练中,分布式系统与算⼒调度占据⾄关重要的地位。DeepSeek ⾃研的 HAI-LLM 框架(Highly Automated & Integrated LLM Training)⼤幅提升了集群利⽤率与通信效率。
1、分布式并行框架:DualPipe + 专家并行 + ZeRO
- DualPipe 流⽔线并⾏
- 将模型拆分为若⼲流⽔段(Pipeline Stage),前向和反向可在流⽔线上重叠执⾏;
- 减少传统流⽔线的空泡期,使 GPU 不再在正反向切换时处于空闲状态;
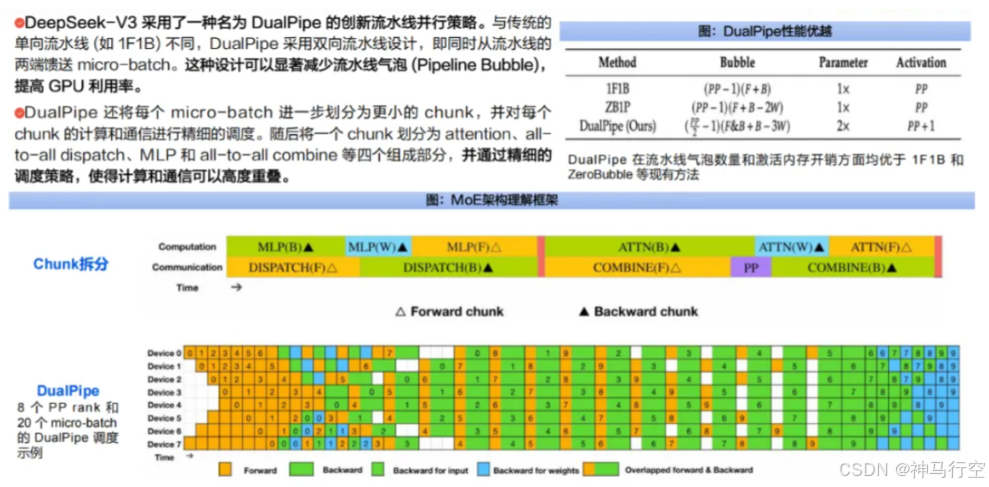
- 专家并⾏(Expert Parallelism)
- 针对 MoE 的⼦⽹络分配进⾏并⾏化操作,让不同节点处理不同专家;
- Warp 级别对 Token 路由进⾏调度,保证负载均衡与通信效率;
- ZeRO 数据并⾏
- 采⽤ ZeRO(Zero Redundancy Optimizer)原理,将模型的优化器状态、梯度等分块存储在各节点,最⼤化减轻单节点显存压⼒;
- 通过 CPU Offload 等技巧进⼀步节省显存,为稀疏激活的超⼤参数规模提供可能;
2、通讯优化与负载均衡
- Warp 级通信内核
- DeepSeek 为跨节点 All-to-All 与路由交换编写了⾃定义 CUDA/PTX 内核,精确控制 Warp级并⾏度;
- 与 InfiniBand + NVLink 硬件深度结合,减少“毫秒级延迟”对⼤规模训练的影响。
- 路由局部化
- MoE 中,各 Token 只需要路由到少数⼏个“候选专家”,避免在每⼀步都进⾏全节点⼴播,显著降低通信流量;
- 内部监控各专家 GPU 利⽤率,动态调度 Token 流,以防⽌出现局部过载或闲置;
3、FP8混合精度与内存管理
- FP8 混合精度
- 为进⼀步提升矩阵运算和通信带宽利⽤率,DeepSeek 采⽤FP16+FP8或 BF16+FP8 混合精度⽅案;
- 在保持模型收敛稳定性的前提下,⼤幅提升运算速度,减少显存占⽤;
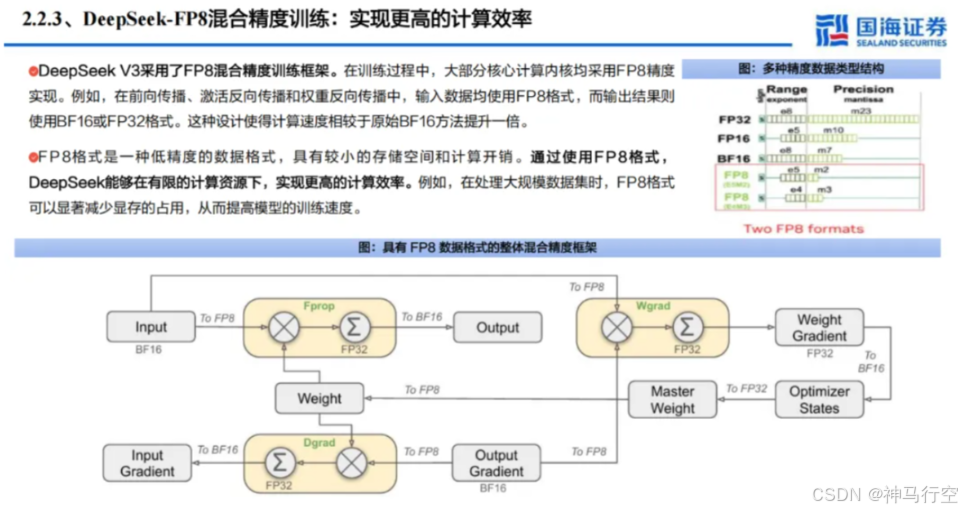
- 激活重计算(Activation Checkpointing)
- 为减⼩显存负担,正反向计算时只存储必要的激活,在反向需要时再进⾏前向重算;
- 与 ZeRO 数据并⾏、CPU Offload 结合,实现超⼤模型在受限 GPU 环境下的成功训练。
4、效果与评估
- 算⼒利⽤率显著提升:DeepSeek 团队宣称在 2048 张 H800 GPU 集群上可稳定维持⾼于 85% 的 GPU 使⽤率;
- 训练周期缩短:V3、R1 等级别的超⼤模型训练在约 55 天内完成,远低于传统⼤模型通常需要的 2~3 个⽉或更⻓时间;
- 通信瓶颈显著降低:Warp 级并⾏和路由局部化的结合,有效减少了⼤规模 All-to-All 操作,使每个节点的通信闲置时间降⾄最低。
1.5.4、硬件维度
底层硬件调用创新:绕过CUDA,直接使用PTX
1、PTX指令级编程动机
- CUDA 通⽤库的瓶颈:⼤模型训练中使⽤⾼阶库虽便捷,但往往难以满⾜个性化的稀疏激活、多维路由与低精度混合等需求。
- PTX(Parallel Thread Execution):
- Nvidia GPU 的低级中间语⾔,可实现对线程束(warp)、寄存器、Cache 等硬件资源的细粒度控制;
- 在特定场景下能榨⼲ GPU 新架构的潜⼒,⼤幅提升⾃定义算⼦的效率。
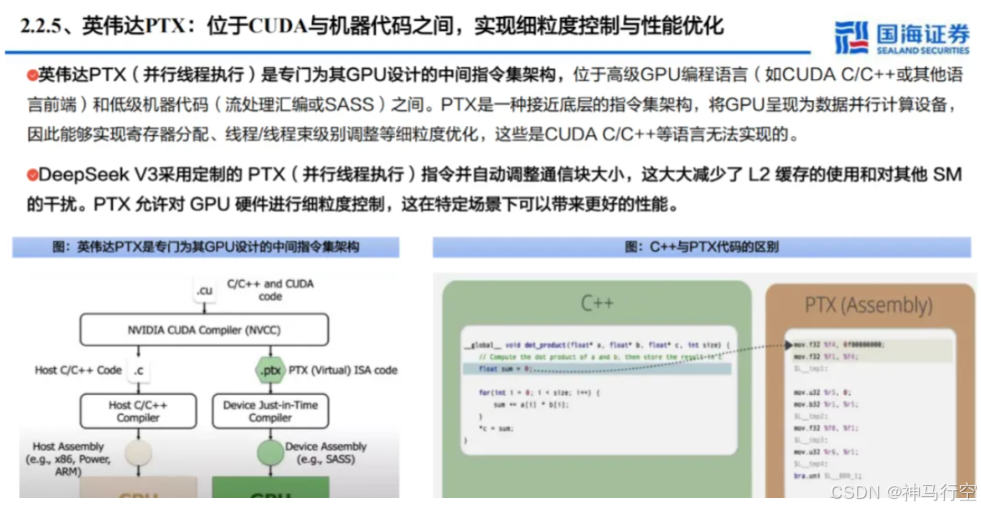
2、DeepSeek的PTX自定义内核
- MoE 路由内核:
- 直接在 PTX 层实现 Token-to-Expert 的动态分配和通信调度,跳过了⾼级库可能带来的额外开销;
- Warp 级路由与融合核(Fusion Kernel),减少了不必要的内存拷⻉和同步操作。
- FP8 矩阵运算内核
- 针对混合精度场景,DeepSeek 开发了⾃定义 GEMM(通⽤矩阵乘法)内核,⽀持 FP8/FP16转换及保留必要的数值精度校正;
- GPU 的寄存器和共享内存利⽤率提升,理论上可⽐标准 CUDA 库快 10%~20%。
3、在降配版H800上的极致适配
- 背景:受限于国际芯⽚制裁,中国市场获得的 H800 GPU 相对于⻄⽅的 H100 在算⼒与带宽上有所降配。
- 深度优化适配:
- DeepSeek 通过对 PTX 指令的细节调整,⽐如 Warp 调度策略、线程块⼤⼩、寄存器堆分配等,尽量弥补硬件降配带来的性能不⾜;
- 利⽤ NVLink、InfiniBand 通道设计专⽤通信调度算法,最⼤化⽹络带宽。
- 实际收益:据官⽅测试,DeepSeek 能在 H800 集群上实现与 A100/H100 相近的运算效率,使其在被封锁或受限的硬件环境下依旧可以“⼩投⼊训练⼤模型”。
GPU的差异参看:一文搞懂最新NVDIA GPU满血版和阉割版芯片:A100、H100、A800、H800、H20的差异_英伟达设备a800,h100-CSDN博客
综述:通过数据集、模型架构、算⼒调度以及底层硬件调⽤四⼤层⾯的创新,DeepSeek 形成了⼀条低成本、⾼效率、可持续演进的⼤模型研发路径:
- 1. 数据层:极少⼈⼯标注 + 机器判分 与 AI ⾃学习⼤幅降低训练数据开销;
- 2. 模型层:MLA、MoE、MTP 等新颖架构提升模型容量与效率并⾏,增强对⻓⽂本与复杂推理的适应⼒;
- 3. 系统层:HAI-LLM(DualPipe+专家并⾏+ZeRO)配合 Warp 级⾃定义通信内核,让 GPU 集群在受限算⼒下也能维持⾼利⽤率;
- 4. 硬件层:PTX 级编程跳过 CUDA 通⽤库限制,在 FP8 计算、MoE 路由等⽅⾯实现极致性能,充分挖掘降配版 H800 的潜⼒。
这套全栈式创新为 DeepSeek‐R1、V3 等系列模型的成功提供了坚实⽀撑,使其在与 GPT-4 等巨型闭源模型的竞争中,依靠“创新”⽽⾮“单纯的⾼算⼒投⼊”赢得了⼀席之地,也为后续更多开源⼤模型的研发指明了⼀条可⾏的⾼性价⽐道路。
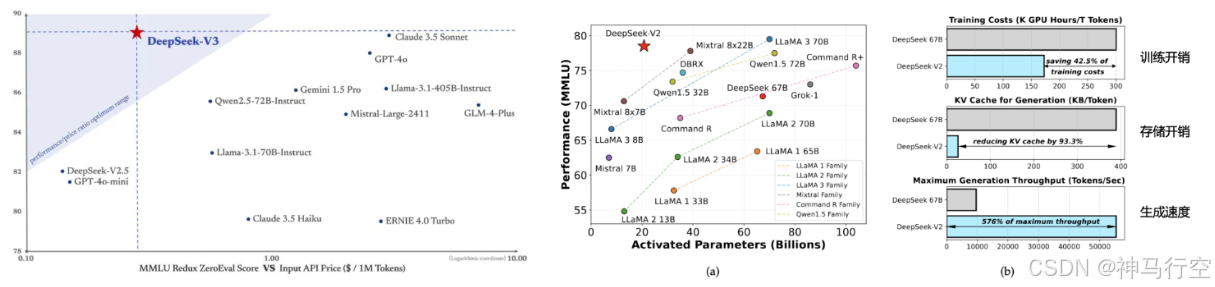
1.6、主流大模型成本对比
- DeepSeek‐R1
|
指标项 |
内容 |
|
官⽅宣称训练总成本 |
约 600 万美元 |
|
硬件规模 |
2048 张降配版 H800 GPU(分布于若⼲机柜集群) |
|
训练周期 |
约 55 天(合计约 1320 ⼩时) |
|
参数规模 |
~6600 亿(稀疏激活下的有效计算量⼩于全密度) |
|
主要创新贡献 |
MoE 架构 + FP8 混合精度 + PTX 底层优化,让⼤规模训练在有限预算内变得可⾏。 |
- DeepSeek‐V3
|
指标项 |
内容 |
|
成本 |
约 557.6 万美元 |
|
GPU 配置 |
同样基于降配版 H800,但专业针对通⽤对话与内容⽣成场景; |
|
规模 |
6710 亿(MoE 稀疏) |
|
周期 |
与 R1 接近,受数据与模型迭代步骤影响,整体在 50~60 天的范围内。 |
- GPT-4
|
指标项 |
内容 |
|
坊间传闻 |
训练投⼊可达数千万甚⾄上亿美元,具体数值尚未官⽅披露; |
|
硬件 |
据称主要由 Microsoft Azure 超⼤集群(含数万张 GPU)⽀持,计算量极为庞⼤。 |
- Claude 2 (Anthropic)
|
指标项 |
内容 |
|
资⾦规模 |
Anthropic 获得来⾃ Alphabet 等多⽅投资数亿美元; |
|
训练成本 |
具体不公开,但估计⾄少在数千万美元级别。 |
1.7、R1的四大进化方向
17.1、通用能力
R1在一些复杂任务上变现不如V3,未来可以通过长链推理来提升
1.7.2、语言混合
优化R1处理中英文以外语言的能力,避免现在的语言混合问题
1.7.3、提示工程
R1对提示很敏感,少量示例提示会降低性能
1.7.4、软件工程任务
从软件工程数据、强化学习的异步评估入手,缩短评估时长,保障强化学习过程的效率
二、开发实践
2.1、DeepSeek价值及常见使用方式
2.1.1、DeepSeek核心价值
2.1.2、DeepSeek用户及主要使用方式

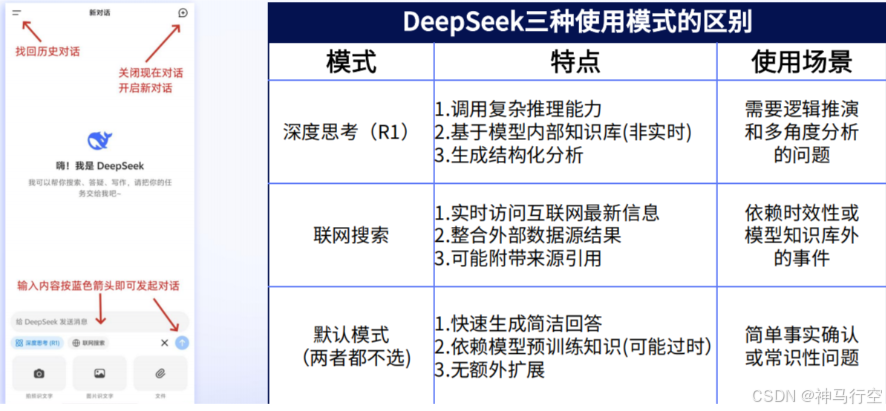
2.1.3、部署DeepSeek的五大决策关键

2.2、开发者部署DeepSeek的三种主流方式

2.2.1、官网API
使用 DeepSeek API 之前,请先 创建 API 密钥 Deepseek API | DeepSeek API Docs
License:MIT
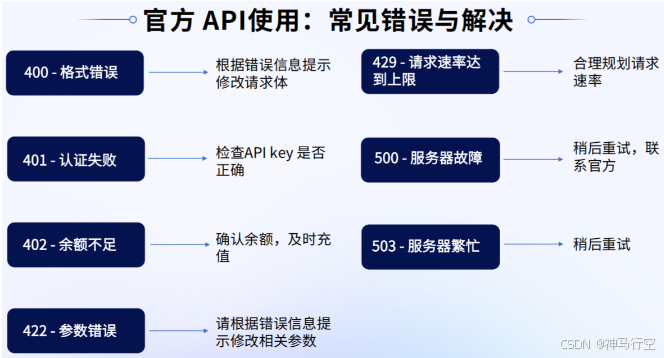
官方API使用的几个关键参数:
|
参数 |
说明 |
|
deepseek-chat |
调用DeepSeek-V3 |
|
deepseek-reasoner |
调用DeepSeek-R1 |
|
max-tokens |
默认最大输出长度为4K,可手动调整至8K |
|
temperature |
参数默认为1.0,建议根据使用场景进行配置 |
2.2.2、私有化本地部署
本地部署DeepSeek-R1蒸馏版,可以通过Ollama、vLLM等工具,简化部署过程;以Ollama为示例说明。
1、下载Ollama
Ollama官网下载:Download Ollama on macOS
2、下载DeepSeek R1
打开模型列表,选择合适参数量的模型,下载DeepSeek R1:deepseek-r1
3、安装模型
打开本地的命令提示符,进行安装
4、输入运行指令
与R1进行对话
具体不同操作系统安装可参考:
如何在个人电脑上私有安装DeepSeek?彻底告别服务器繁忙!
零基础也能行!July手把手教你用Ollama/vLLM/MNN本地部署DeepSeek-R1
2.2.3、云平台托管部署
目前国内主流云平台均已支持DeepSeek模型,比如硅基流动、华为云、腾讯云、百度云、阿里云等。以硅基流程为例说明。
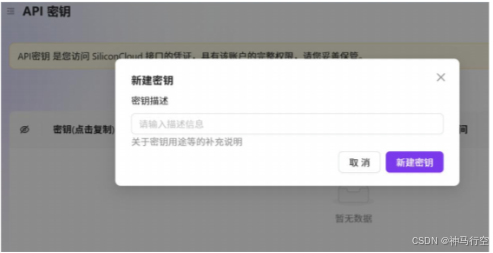
1、注册并登录云平台
2、新建API密钥
3、下载AI开发工具
下载Cherry Studio 或Chatbox AI开发工具。
Chatbox AI教程参考:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
4、安装开发工具,选择模型提供方
选择自己使用的API,下图红框中为硅基流动。
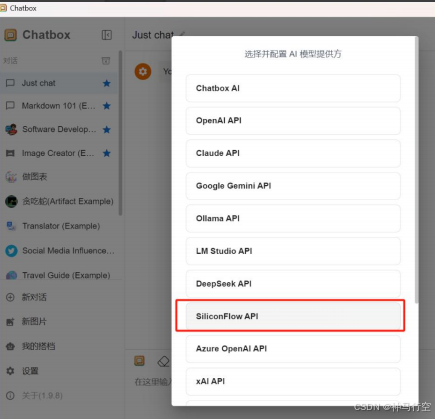
5、填写API密钥,选择模型
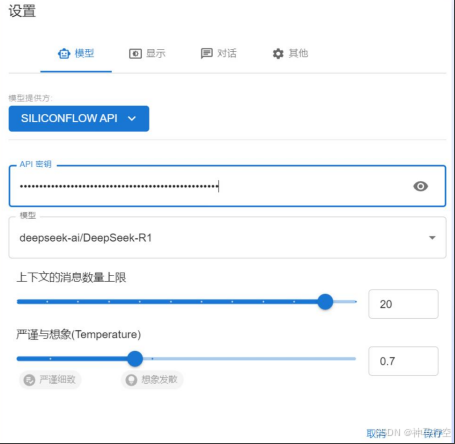
6、与R1对话使用
2.2.4、部署DeepSeek的其他方式

2.2.5 使用集成工具
下列框架已集成DeepSeek API,可帮助简化开发流程、提升效率。


三、行业应用
3.1、DeepSeek能力
DeepSeek依托精准推理、领域适配、多模态协同、轻量化部署四项核心能力,迅速引爆千行百业,助力各行业构筑专属的AI大脑。
3.1.1、精准推理

DeepSeek幻觉率解析参看:
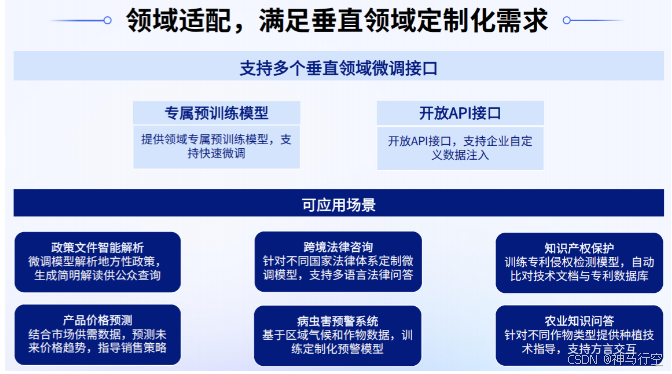
3.1.2、领域适配
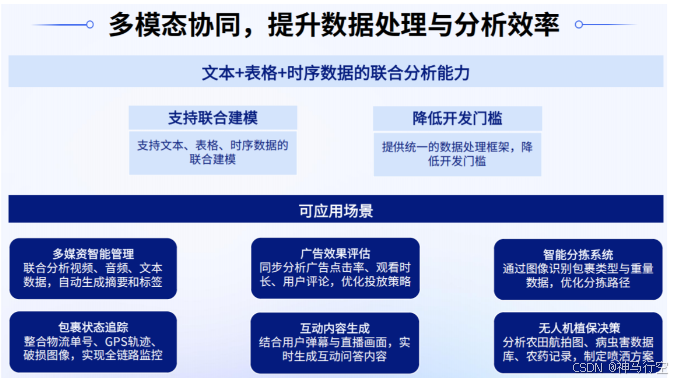
3.1.3、多模态协同
3.1.4、轻量化部署

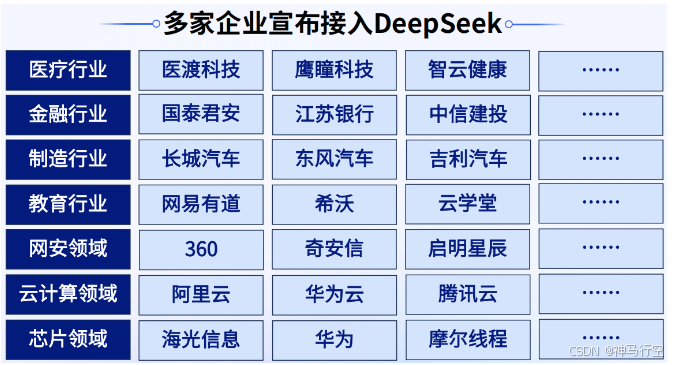
3.2、行业落地实例
1、医疗行业
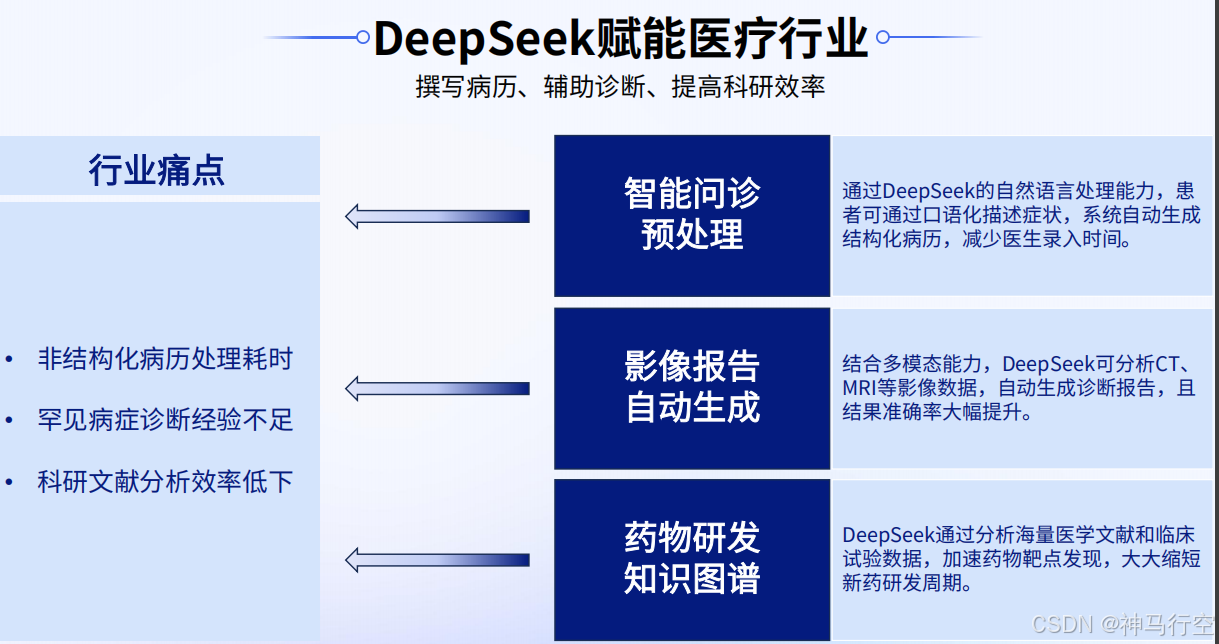

2、金融行业
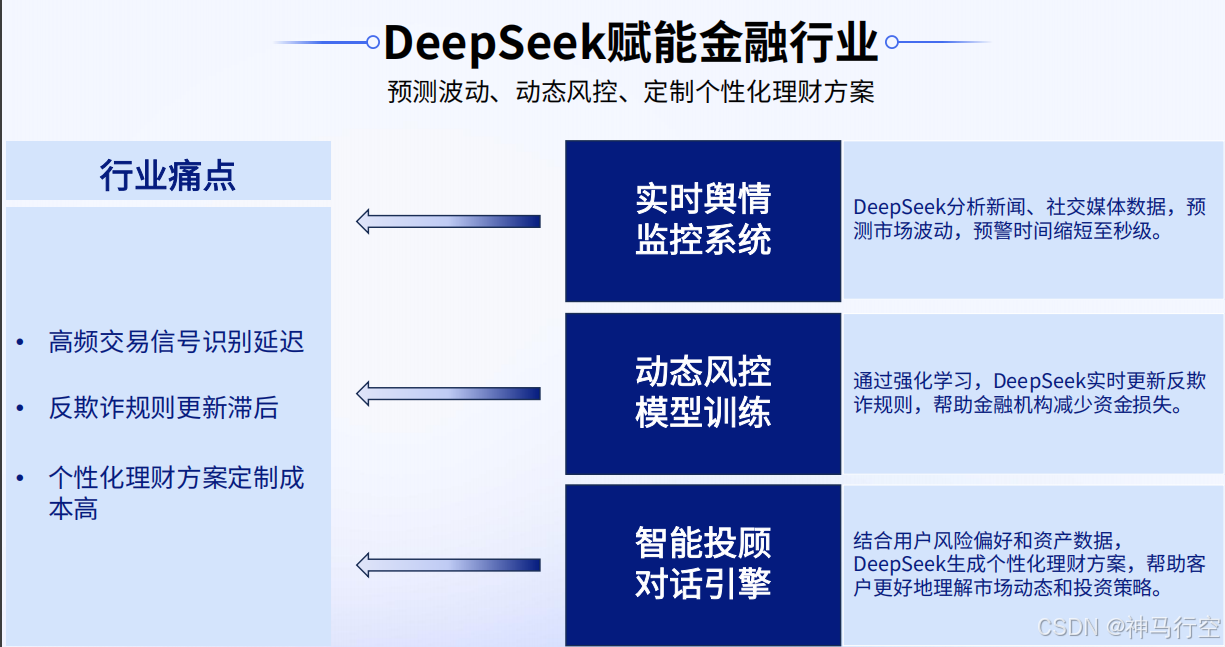

3、制造行业
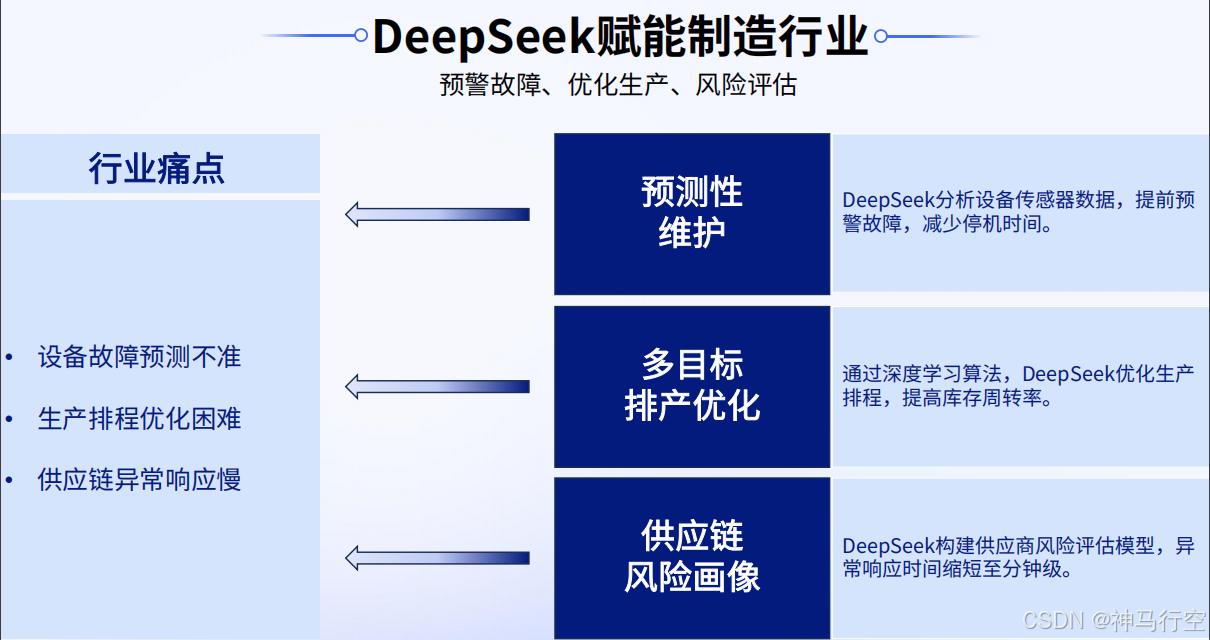

4、教育行业
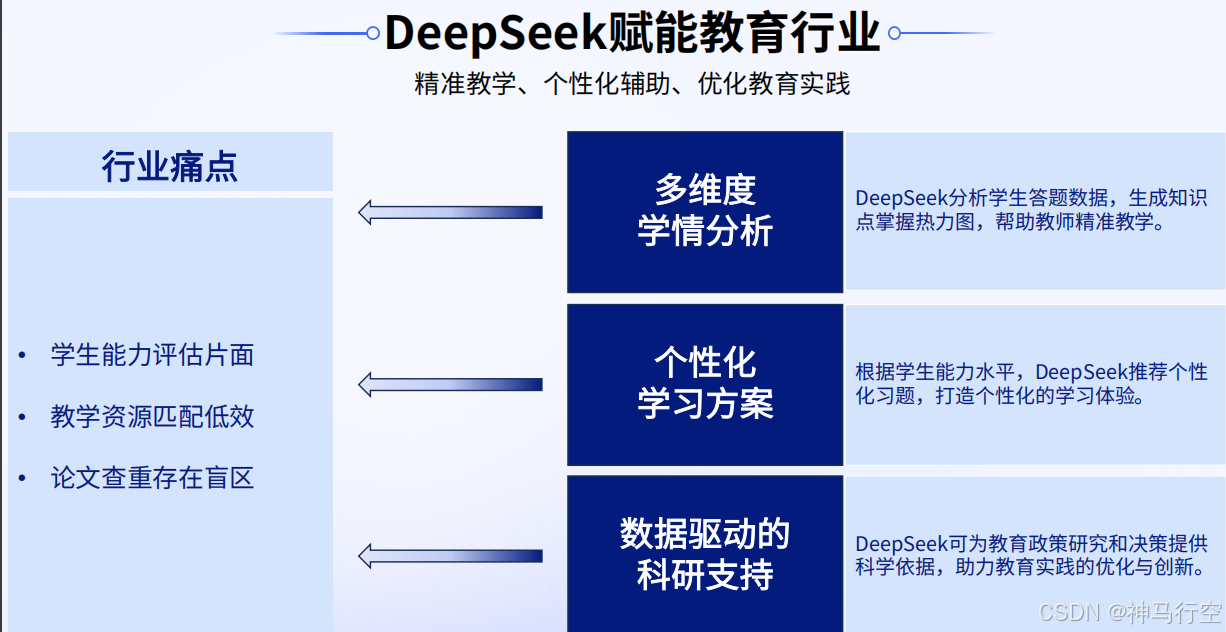

3.3、DeepSeek生态圈(接入情况,持续增多)
2.16号,腾讯也宣布微信8.0版本将接入DeepSeek-R1,这将是全球首个深度集成的大模型社交系统,并已开始灰度测试。被灰度到的用户,在对话框顶部搜索入口可以看到“AI搜索”字样。
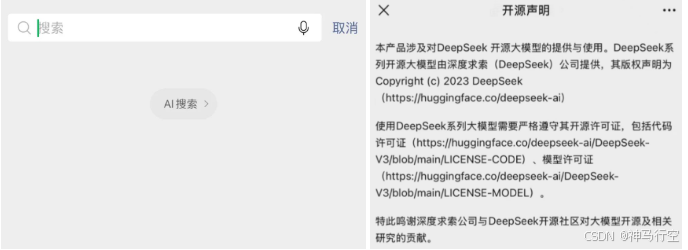
随着DeepSeek热度不断上升,接入的厂商也呈现井喷的态势。不过趁着DeepSeek这个热度,不同的厂商有着不同的考量:有人卷模型上架,算力适配,主卖铲子;有人卷功能接入,迭代产品,主卖应用;有人卷场景落地,业务升级,主卖价值;有人卷借势宣传,愿景画饼,主卖噱头;

四、附录
4.1、DeepSeek相关论文
[1]https://arxiv.org/pdf/2401.06066
[2]https://arxiv.org/pdf/2402.03300
[3]https://arxiv.org/pdf/2405.04434
[4]https://arxiv.org/pdf/2412.19437
[5] https://arxiv.org/pdf/2501.12948
[6] https://arxiv.org/pdf/2404.19737
[7] https://arxiv.org/pdf/2502.11089
4.2、Github仓库
DeepSeek:DeepSeek · GitHub
DeepSeek-V3:GitHub - deepseek-ai/DeepSeek-V3

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)