【AI观析堂】DeepSeek“小成本大能效”的秘密武器(第二期)
本期《AI观析堂》将继续深度解读DeepSeek技术优势,刨析其能够实现低成本推理背后的关键因素,使更多企业和用户能够更轻松地拥抱AI技术。
DeepSeek的推理成本为什么低?
关于“DeepSeek推理成本低”的真相和技术解释
上回我们谈到,OpenAI o1 的训练成本是DeepSeek-V3的27倍, Llama 3 训练成本是DeepSeek-V3的15倍。
今天我们继续讨论,DeepSeek应用起来(推理)是不是一样也有效率优势?其背后的技术逻辑又是什么?
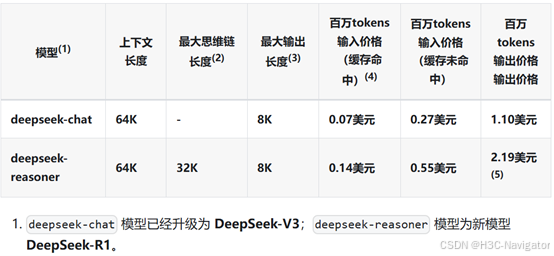
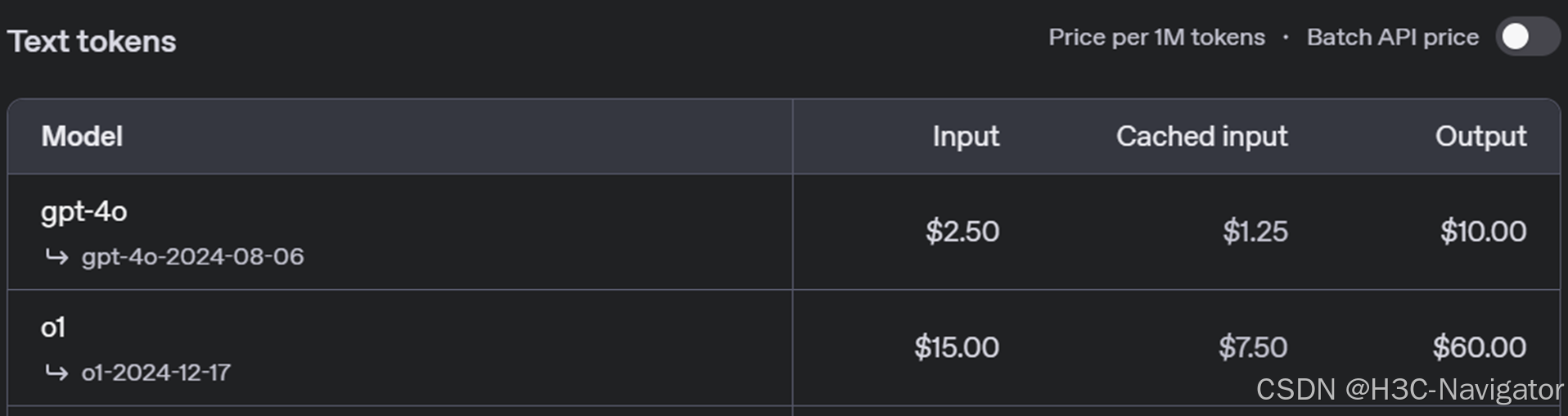
DeepSeek推理的成本与同级别模型比较
根据官网价格介绍,DeepSeek-V3的百万token的输出价格是GPT 4o的 1/10 ,DeepSeek-R1的百万token的输出价格是o1的 1/30 。
DeepSeek 的推理成本较低(效率高),主要得益于以下几个关键技术优化,因为模型推理和训练都是模型内部的计算过程,所以其中几个技术是上期的“老面孔”了,我们先来回忆一下:
高细粒度的混合专家(MoE)架构:还记得医院看病,通过更智慧的分诊系统优化看病速度的比喻吗?正是它!模型推理的过程,就像病人去医院看病,不用每个科室的大夫都凑在一起,模型不用全参数投入到每一次推理任务中,大大提升了效率。
FP8 混合精度:上期我们说fp8混合精度对训练的影响,像去饭馆点菜吃饭,在菜单图片上、点菜过程当中、服务员下单过程中,只使用简单菜名,便是“8位浮点数精度名称”,由厨师在炒菜的过程中,使用“原始数据格式”,增加了模型训练效率。
对推理也是一样!更短的“服务员,「上菜!」”比起“服务员,上『三号桌点的由青椒、土豆、少许生姜和大蒜炒制而成的青椒土豆丝」”大大降低了存储、传输和计算压力。
MTP多token预测加速推理:第一期我们在介绍“DeepSeek能力为什么强”时,已经讨论过。一般来说,语言模型每次只能预测一个词,但 MTP 能让模型一次性预测多个词。这就像是在下棋时提前想好好几步棋,提升了计划和决策的效率。
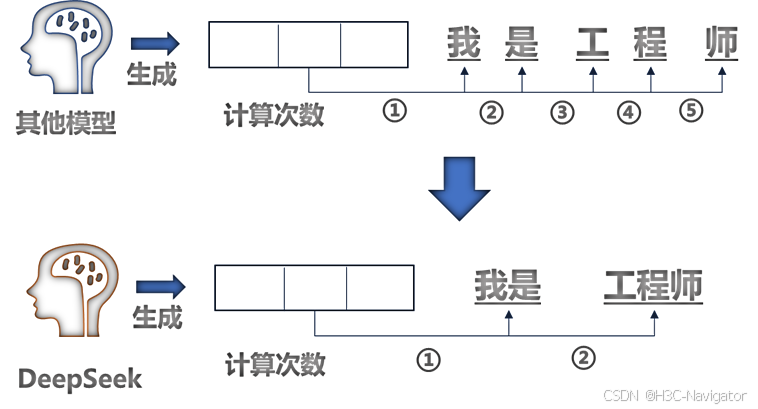
此外,还有两个“新面孔”技术,也在提升DeepSeek推理效率上起到了关键作用:
MLA-多头潜在注意力机制:减少了长文本推理时的 GPU 计算量,提升长文本处理的效率。降低了多 GPU 并行推理的通信成本。
PD分离比例调整:合理分配处理输入和输出的比例,提升 GPU 利用率,降低硬件需求,减少推理延迟。
别担心!我们还是用两个例子,让这两个技术更好理解!
MLA-多头潜在注意力机制
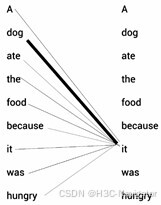
首先需要建立一个大语言模型的基础认识:模型本身在“与人对话”的时候,本质上都是在计算每个单词和其他单词前后的“关系”,最终选取“关系最深的”单词前后排列在一起,这就表示需要反复计算很多个单词和其他单词的关系,并将关系存储起来。

想象一个新班级,每当一个新同学进来时,他需要认识班里的每个同学。为了方便大家不用一个一个的相互自我介绍,班里有一个花名册(KV Cache),上面列出了所有同学的名字,帮助新同学快速找到要认识的人。
但是,随着班级人数增加,花名册可能越来越大,里面的名字过多,快写不下了!(占用的显存过多!)
DS在训练DeepSeek 时独创了MLA压缩算法,MLA 就是通过给每个同学一个简短的学号,使得花名册上的信息更加紧凑,减少了查找和存储的空间。
显然,这样可以显著缩小显存占用,降低推理成本
PD分离优化技术
DeepSeek 在技术架构中应用了 prefilling 和 decoding 分离(PD 分离)优化技术。真正体现了强大的研发实力!为了更好理解,我们首先要看,什么是p,什么是d。

假设你让大模型写一篇作文,它的推理过程分为两步:
- P!-Prefill阶段:模型先“吃下”你的输入提示(比如“写一篇关于AI的作文”),预先计算所有可能用到的中间结果(比如生成KV缓存,就是上一个技术例子里小明和爷爷关系那个!)。这个阶段计算量大,但可以并行处理(类似工厂里同时加工所有零件)。
- D!-Decode阶段:模型开始逐字生成作文(比如“人工智能是...”→“人工智能是一项...”→“人工智能是一项颠覆性...”)。这个阶段每次只生成一个token,计算量小,但持续时间长,对显存占用多,依赖前一步的结果,无法并行(类似流水线上必须一步步组装零件)。
我们自然而然的能想到,工人(硬件)一会儿要批量加工零件(Prefill),一会儿要停下来组装(Decode),效率极低,机器和人力都被浪费了啊,那是不是让预加工车间全力并行生产零件,组装流水线专注串行组装,效率会快很多?恭喜你,你已经是专家了。这就是所谓的PD分离。
但是!我们又必须考虑,两种阶段对硬件的要求完全不同:
- Prefill阶段的最小部署单元由4个节点和32个GPU组成。注意力部分采用4路张量并行(TP4)与序列并行(SP)结合,并辅以8路数据并行(DP8)。其较小的TP尺寸为4,限制了TP通信的开销。对于MoE部分,使用32路专家并行(EP32),确保每个专家处理足够大的批量大小,从而提升计算效率。
- Decode阶段阶段的最小部署单元由40个节点和320个GPU组成。注意力部分采用TP4与SP结合,并辅以DP80,而MoE部分则使用EP320。在MoE部分,每个GPU仅负责一个专家,其中64个GPU专门用于托管冗余专家和共享专家。
又复杂了?又技术了?没关系,关于PD分离你只需要记住这一句话:
PD分离的本质是“让适合干粗活的硬件干粗活,适合干细活的硬件干细活”。但它的效果高度依赖硬件配置是否“分工明确”,也是因为如此,PD分离体现了DeepSeek高超的技术整合能力。
是什么让我们更容易用上了DeepSeek?
除了上文提到的「能力效果好」、「训练成本低」、「推理成本低」等优势,DeepSeek还通过什么改变,降低了使用门槛,把大模型能力带到每个人身边?你可能还需要从以下两个方面解释!
开源策略!大模型应用成为“开卷考试”啦!
网络上对DeepSeek开源与性能的讨论:
截止目前,虽然DeepSeek的R1模型在表现上还没达OpenAI o3的高度,但已经到达了同一梯队,但不同于OpenAI的闭源策略,开源让每个人都有机会成为“模型的主人”,极速地吸引开发者构建生态,同时提供低成本API服务(价格仅为GPT-4o的1/10)。

对于大部分需要用大模型能力的场景服务商来说,DeepSeek开源模型提供了深厚的基础模型能力基础,如果我们把提供一套以大模型能力为基础的智慧化业务建设看作「答一套满分是750分的试卷」,获得开源DeepSeek模型支持的「答卷者」,开局便获得了「高达600分的开卷答案」,剩下「150分的获取」,便需要大家各凭本事,在模型应用、工程层面等领域发力。
蒸馏技术!算力受限下的模型能力平权!
什么是蒸馏技术?
模型蒸馏就是通过大模型生成的高质量训练数据(包含思维链,多步推理,答案分布等复杂数据800k样本),直接用小模型(如Qwen/Llama)在这些生成数据上进行微调,学习大模型的输出模式,从而学习复杂的推理模式。
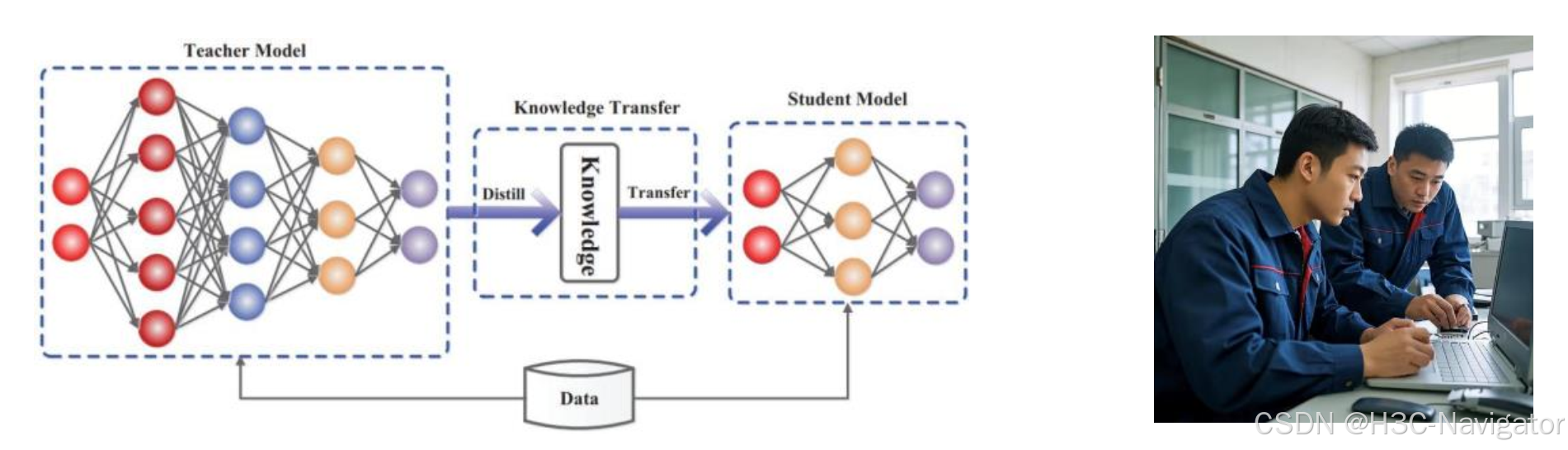
举例来说,一个新人和资深销售学习客户交流技巧,“学生” 一直跟着“老师”,学交流技巧,学汇报材料准备,“教师模型”不断生成“交流技巧500问”“材料准备1000问”等学习资料,让学生在监督下不断进步,将“老师”的能力部分“拷贝”在“学生”上。
蒸馏技术带来的直接效果就是“小体积模型”具备了“大体积模型的”部分能力,671B“满血版”模型是最小蒸馏7B模型体量的将近百倍!这背后是巨大的算力、存储和网络压力减小。

百万级轿车的部分性能和外观特色可以在20万级获得体验,此时消费者对技术细节和性能的边缘效益追求就会变小,同样,当公司个人可以利用开源的模型获得性能同梯队的智慧化能力时,市场需求会被极具放大。
精彩预告
当DeepSeek遇上新华三,会碰出怎样的火花?下期文章将揭晓新华三如何凭借其强大的技术实力,让百行百业抢先一步享受技术红利!精彩内容,敬请期待!
《AI观析堂》全期内容概览
第一期:DeepSeek热点技术解读(1)
- DeepSeek能力强体现在哪里?
- DeepSeek的训练成本为什么低?
第二期:DeepSeek热点技术解读(2)
- DeepSeek部署成本为什么低?
- 是什么让我们更容易用上了DeepSeek
第三期:结合DeepSeek,新华三提供大量能力
- 推理部署
- 产品提供
- 智慧化服务
第四期:DeepSeek热点对行业的影响
- 整个产业都被如何影响(模型、GPU、整机、推理、云、应用)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)