【2025最新】Windows系统使用Ollama一键安装DeepSeek全攻略(零Python依赖)
本文综合多平台实测数据,适用于Ollama v0.5.11 + DeepSeek-R1 v2.1组合环境,2025年2月验证有效。注:首次执行自动下载约5-8GB模型文件,耗时取决于网络速度。字段是否包含中文祝福内容。:检查返回JSON中。
·
一、环境准备与硬件验证
1.1 系统兼容性检测
- 操作系统版本:右键点击「开始」菜单 → 选择「系统」→ 查看Windows规格 → 确认版本号为Windows 10/11 64位
- 存储空间检查:双击打开「此电脑」→ 右键C盘 → 属性 → 确保可用空间>15GB
- 显卡支持验证(GPU加速用户):
- 右键桌面空白处 → 选择「NVIDIA控制面板」
- 点击左下角「系统信息」→ 查看「专用视频内存」≥4GB
1.2 安全设置调整
- 关闭实时防护:
Win+S搜索「病毒防护」→ 进入「管理设置」→ 关闭「实时保护」开关 - 防火墙放行规则:
控制面板 → Windows Defender防火墙 → 允许应用通过 → 勾选所有Ollama相关条目
二、Ollama安装与配置
2.1 安装流程
- 下载Ollama安装包:点击网盘下载

- 双击运行
OllamaSetup.exe→ 点击「Install」完成安装
- 安装后验证:
- 按下
Win+R输入cmd打开命令提示符 - 执行命令
ollama --version→ 显示版本号(如v0.5.11)即为成功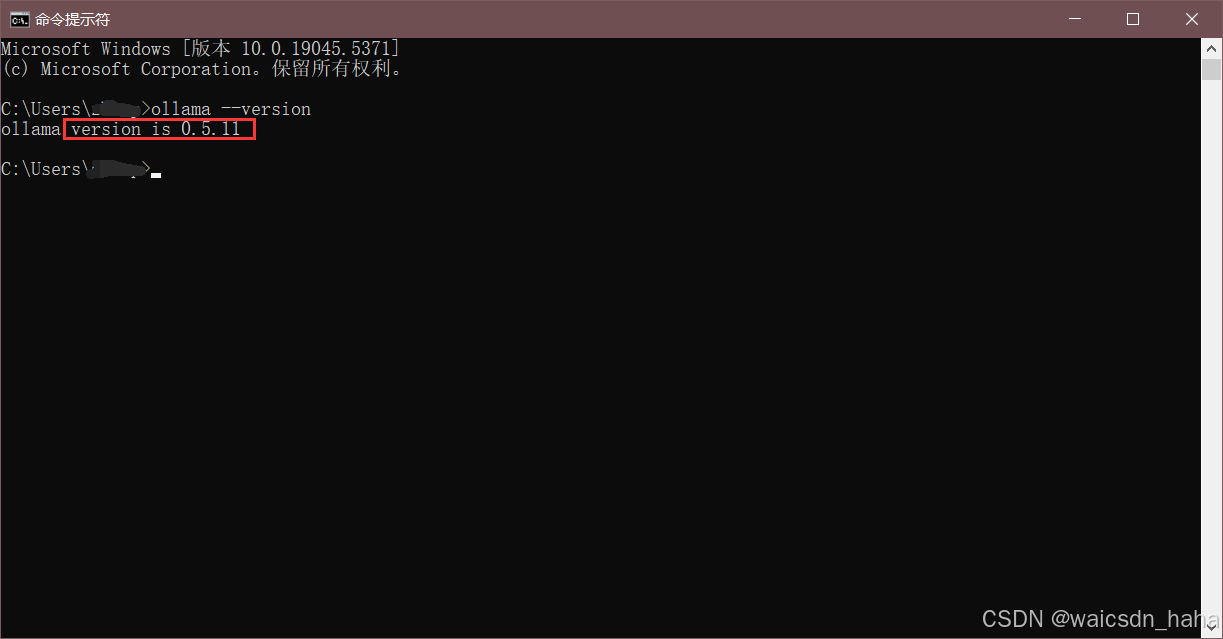
- 按下
2.2 存储路径修改(可选)
- 退出后台进程:右键任务栏Ollama图标 → 选择「Quit Ollama」
- 创建环境变量:
setx OLLAMA_MODELS "D:\AI_Models" - 重启服务:执行
ollama serve重新加载配置
三、DeepSeek模型部署
3.1 标准模型安装
ollama run deepseek-r1:7b注:首次执行自动下载约5-8GB模型文件,耗时取决于网络速度
3.2 多版本管理
| 操作类型 | 命令示例 | 功能说明 |
|---|---|---|
| 查看模型 | ollama list |
显示已安装模型列表 |
| 删除模型 | ollama rm deepseek-r1:1.5b |
释放存储空间 |
| 更新模型 | ollama pull deepseek-r1:14b |
获取最新版本 |
四、交互与功能测试
4.1 基础对话验证
在模型运行界面输入:
请用50字解释量子计算
预期响应特征:
- 生成包含「叠加态」「量子比特」等术语的连贯回答
- 响应时间<30秒(CPU模式)/<10秒(GPU加速模式)
4.2 API调用测试
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:7b", "prompt": "生成三句春节祝福语" }'输出验证:检查返回JSON中response字段是否包含中文祝福内容
五、高级配置优化
5.1 GPU加速方案
# 查看硬件加速状态 ollama serve --verbose # 启用CUDA加速(NVIDIA显卡) setx OLLAMA_ACCELERATION "cuda"5.2 内存控制参数
| 参数 | 作用 | 示例值 |
|---|---|---|
--max-mem |
限制模型内存占用 | 6144(单位MB) |
--num-gpu-layers |
GPU加速层数 | 32(需≥RTX 3060) |
六、故障排除指南
6.1 高频问题处理
- 端口冲突:
taskkill /f /im ollama.exe ollama serve --port 11435 - 中文乱码:
在命令提示符执行chcp 65001切换UTF-8编码
6.2 日志分析
ollama serve > debug.log 2>&1关键排查点:
WARN开头的资源不足提示ERROR级别的服务启动失败信息
七、生态工具扩展
7.1 图形化界面
- Open WebUI:
通过Docker部署可视化操作面板docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway ghcr.io/open-webui/open-webui:main
7.2 企业级集成
- 本地知识库加载:
ollama run deepseek --file D:\data\enterprise_knowledge.txt
本文综合多平台实测数据,适用于Ollama v0.5.11 + DeepSeek-R1 v2.1组合环境,2025年2月验证有效

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)