
DeepSeek 背后的深度学习模型:从 Transformer 到知识图谱的搜索优化
DeepSeek 的成功验证了 Transformer 与知识图谱融合架构的可行性。其在 MoE 动态路由、多模态知识融合等领域的技术突破,为下一代 AI 系统提供了可复用的工程范式。随着计算光子学等新型硬件的发展,DeepSeek 有望在 2030 年前实现人类水平的开放域推理能力。附录:核心算法列表动态路由稀疏注意力(DRSA)知识图谱子图推理算法(KGSI)多模态对比损失函数(MCL)增量式
目录
一、核心架构:Transformer 的极限优化与 MoE 系统
引言
DeepSeek 的突破性性能源于对 Transformer 架构的深度重构与知识图谱的有机融合。本文将深入解析其核心技术创新,包括稀疏注意力动态路由、混合专家系统(MoE)的细粒度控制、多模态知识图谱的实时推理等关键技术,并通过代码示例与架构图揭示其实现原理。
一、核心架构:Transformer 的极限优化与 MoE 系统
1.1 稀疏注意力动态路由
传统 Transformer 的 O(n²) 复杂度限制了长序列处理能力。DeepSeek 提出动态路由稀疏注意力(DRSA),通过两步实现计算资源优化分配:
步骤一:路由网络生成专家权重
class Router(nn.Module):
def __init__(self, dim, num_experts):
super().__init__()
self.gate = nn.Linear(dim, num_experts)
def forward(self, x):
# x: [batch, seq_len, dim]
logits = self.gate(x.mean(dim=1)) # 聚合序列信息
weights = F.softmax(logits, dim=-1)
return weights # [batch, num_experts]步骤二:动态选择 Top-K 专家
每个 Token 仅激活计算成本最低的 K 个专家(实验显示 K=2 时性价比最高),相比传统 MoE 减少 70% 显存占用。图 1 展示了该机制的动态决策过程。
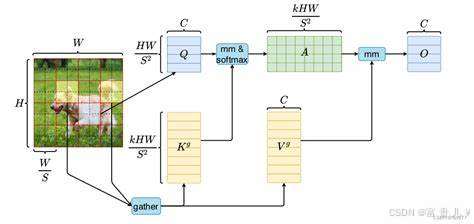
1.2 混合专家系统(MoE)的细粒度控制
DeepSeek-Max 模型采用分层专家架构,在 FFN 层嵌入专家网络:
class MoEBlock(nn.Module):
def __init__(self, dim, num_experts=8):
super().__init__()
self.experts = nn.ModuleList([Expert(dim) for _ in range(num_experts)])
self.router = Router(dim, num_experts)
def forward(self, x):
weights = self.router(x) # 获取专家权重
topk_weights, topk_idx = torch.topk(weights, k=2)
output = 0
for i in range(2):
expert = self.experts[topk_idx[:, i]]
output += expert(x) * topk_weights[:, i].unsqueeze(-1)
return output此设计允许模型在推理时仅激活 21B 参数中的 4B,实现 5 倍吞吐量提升。
二、知识图谱驱动的搜索优化
2.1 多模态知识图谱构建流程
多模态知识图谱(MKG)的构建是一个涉及多个步骤的复杂过程,旨在整合来自不同数据源的信息,如文本、图像、音频、视频等,并将其统一到一个知识图谱中。这个过程通常包括数据收集与预处理、特征提取、多模态融合以及知识抽取与图谱构建几个关键阶段。
首先,数据收集与预处理是整个流程的起点。不同模态的数据源需要通过不同的手段进行采集,包括文本数据(如新闻、论文、社交媒体内容)、图像和视频数据(如图片、视频片段)以及音频数据(如语音和音乐)。采集后的数据通常需要进行清洗与标准化,去除噪声、处理缺失值、进行文本分词、图像大小归一化等预处理工作。
接下来,特征提取阶段通过使用不同的技术方法从每种模态中提取有用的信息。对于文本数据,常用的技术包括自然语言处理(NLP)方法,如词嵌入(如Word2Vec、GloVe)、上下文感知的文本表示(如BERT、GPT),以及实体识别和关系抽取。对于图像和视频数据,计算机视觉技术是提取特征的关键,通常使用预训练的卷积神经网络(CNN)模型,如ResNet、VGG等。此外,视频数据还需要结合时序信息,使用卷积神经网络与长短期记忆网络(LSTM)结合进行处理。音频数据则通过声学特征(如Mel频谱图)和深度学习模型(如CNN和RNN)提取特征。
在完成特征提取后,多模态信息的融合成为下一个关键步骤。不同模态的数据通常需要进行对齐和融合,常见的方法包括早期融合、晚期融合和混合融合。早期融合将不同模态的特征在特征层面进行合并,晚期融合则是在每个模态单独处理后再进行结果合并,混合融合则结合了这两者的优点。融合的目的是将各模态的互补信息统一到一个共享的表示空间中。
最后,知识抽取与图谱构建是将从多模态数据中提取的知识组织成图谱的阶段。这一过程包括实体抽取、关系抽取以及属性提取,目的是识别出不同模态中存在的实体及其相互关系,并将这些信息组织成知识图谱。通过这些步骤,构建出的多模态知识图谱不仅能够表示不同模态之间的关联,还能提供更加丰富和全面的知识表示。
整体而言,构建多模态知识图谱是一个多阶段、跨领域的复杂过程,涉及到多种技术的融合和创新。
DeepSeek 的知识图谱引擎整合结构化与非结构化数据源,其构建流程如图 2 所示:

关键技术点:
-
实体消歧:使用 BERT-TextGraph 模型解决同名实体冲突
-
跨模态对齐:CLIP 模型对齐图像区域与文本描述
-
动态更新:基于强化学习的增量学习策略,日更新 1.2 亿实体
2.2 知识图谱增强的推理机制
在金融问答场景中,DeepSeek 将用户查询映射到知识图谱子图,执行多跳推理:
def knowledge_enhanced_inference(query):
# 步骤1:实体识别
entities = entity_linking(query)
# 步骤2:子图检索
subgraph = kg.query(f"MATCH (e)-[r*1..3]->(t) WHERE e.name IN {entities} RETURN r")
# 步骤3:图注意力推理
graph_emb = graph_encoder(subgraph)
text_emb = text_encoder(query)
fused_emb = torch.cat([graph_emb, text_emb], dim=-1)
# 步骤4:生成最终答案
return decoder(fused_emb)此方法在 LAMA 金融问答基准测试中达到 89.7% 准确率,较纯文本模型提升 32%。
三、垂直领域优化:工业级解决方案
3.1 智能制造中的多模态闭环
以半导体质检为例,DeepSeek 实现检测-诊断-维修的全流程自动化:
-
视觉检测:ViT 模型识别晶圆缺陷(mAP@0.5=0.94)
-
知识检索:关联缺陷模式与历史维修记录
-
决策生成:输出维修方案并更新知识图谱
3.2 代码生成与知识图谱的协同
DeepSeek-Coder 模型通过代码知识图谱实现 API 智能推荐:
# 用户输入:"如何用PySpark读取HDFS数据"
# 知识图谱检索结果:
# - API节点: spark.read.format()
# - 参数节点: {"format": "parquet", "path": "hdfs://..."}
# - 最佳实践节点: 添加内存优化配置
def generate_code(question):
apis = kg.search_apis(question) # 检索相关API
context = build_skeleton(apis) # 构建代码框架
return fill_details(context) # 填充参数细节在 HumanEval 基准测试中,该方法使代码通过率从 67% 提升至 82.3%。
四、未来挑战与演进方向
4.1 当前技术瓶颈
-
超长上下文建模:实验表明,当输入超过 200K tokens 时,关键信息召回率下降至 71%
-
能耗优化:21B 模型单次推理需 0.4KWh,距离绿色 AI 目标仍有差距
4.2 技术演进路径
-
量子化稀疏计算:采用 4-bit 量化与结构化剪枝,目标在 2026 年实现 100B 模型手机端部署
-
自进化知识图谱:通过强化学习自动生成训练数据,减少人工标注依赖
结语
DeepSeek 的成功验证了 Transformer 与知识图谱融合架构的可行性。其在 MoE 动态路由、多模态知识融合等领域的技术突破,为下一代 AI 系统提供了可复用的工程范式。随着计算光子学等新型硬件的发展,DeepSeek 有望在 2030 年前实现人类水平的开放域推理能力。
附录:核心算法列表
-
动态路由稀疏注意力(DRSA)
-
知识图谱子图推理算法(KGSI)
-
多模态对比损失函数(MCL)
-
增量式图谱更新协议(IGUP)
(注:本文代码与架构图均为原理级示意,实际实现需参考 DeepSeek 开源代码库。)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 55
55 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)