DeepSeek-MoE的发展路线v1-->v3
moe的第一代、第二代、第三代,参数量在逐步增加,优化的粒度被逐步细化。一直被坚持的,一个是共享的一个专家。第二是细粒度切分的一个专家。在第三代里边被保留的:第一个是device limited routing,一个token它最多能被多少个device做处理,这个做了一个限制。第二个是无损的负载均衡和序列的一个负载均衡。这两块是替代了之前的专家级别的均衡,设备级别的均衡以及通信。然后同时他也丢弃
一.MoE架构的三个核心的难点
1.分布式训练
通信成本比较高;尤其在r1和v3这个量级671b,它用的设备是非常多的,那它的通信成本就会非常高。再加上模型切分,数据切分,并行数据并行各种并行的策略。通信成本就会更高。
2.路由负载的不均衡
专家数从1+63 到1+256

DeepSeek使用更细粒度的专家数,专家数比较多。它第一个版本在1.89b的参数量时候,其实就用了大概1+63,就是64个专家。最早的时候像mixtral,包括后面Qwen,他发布的这个专家数量其实都是以大专家或者是这个专家参数,本身的参数都会比较高一些。本身专家没有这个没有做这么细粒度的切分。
3.大参数量推理速度慢
从v1的1.89B到v3的671B,训练的成本,训练的时间就会比较长。
MOE的训练成本也比较高,训练难度比较大。最早的MOE是谷歌提出来的。 其实这个图有一个版本是针对moe的一个版本,就是一个专家在干活一堆专家在鞭策。对,那这个图是类似于展示了,就是说相当于在moe上训练的时候有一个非常见的问题。这个问题就是专家之间的不均衡,且就是说很难实现moe之间的一个均衡。也就是说让我的所有的专家能够均衡,或者是相对来说负担比较平衡的情况下去处理所有的问题,这个是一个难点。左边写了moe。
二.如何保证MoE的效果好?且均衡?
DeepSeek Moe做了哪些事?
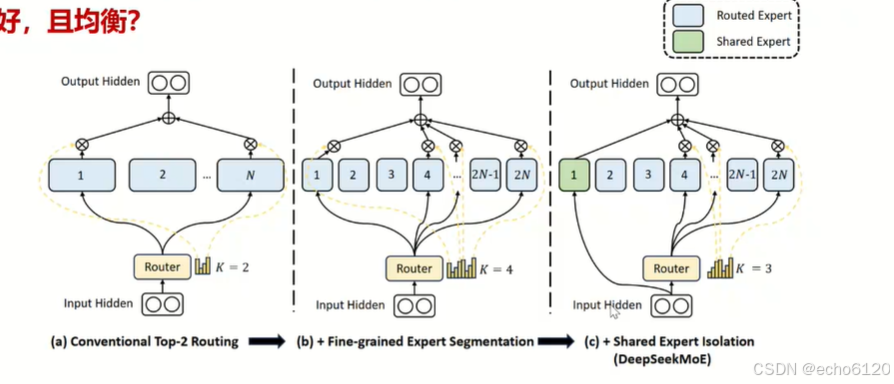
当一个神经网络里有一堆的专家,如何让这些专家能够均衡的去工作,以及让这些专家能够更好的处理自己更擅长的工作,这个是训练MoE时最核心的一个问题。
1.架构优化
细粒度专家分割(Fine-Grined Expert Segmentation)
共享专家隔离(Shared Expert Isolation)
如图:
从a到b到c,从一个非常粗粒度的专家切分,之前是一个盘子切成了n份,就是切成了n个专家,选切分后的两个
。到c图,它把一个盘子切成了2n份,其中的一个是固定要选的,就是一号专家,还有另外要选其中的三个。
激活的参数量是一样的。
但它的专家力度切分就会更细,而且同时会保证有一个专家始终会被选中。
那这种架构的好处就是当我的专家切分粒度比较细的时候,专家的互动性或者是共同参与决策的机会更多,
或者是知识能够做进一步的共享,更细粒度的共享。
第二个是有一个专家,他始终会参与任何token的处理或者任何任务的处理。那他会学到我们训练数据里面共性的一些东西,这个是一个结构上的一个优化。
2.负载均衡优化
专家级负载均衡loss(Expert-level balance loss )
设备级负载均衡loss(device-level balance loss) 新增提升训练时设备负载的均衡性
负载均衡的意思就是说如何在训练的时候保证这些专家能够相对均衡的去干活。
第一个优化点是专家级别的负载均衡。这个不是deepseek提出的原创的一个关注点。因为最早的时候,一个moe它其实只有一个专家,比如说他工作过于负载的时候,我会降低他的一些权重,或者是另外一个专家,一直不工作的时候,我会提高他的权重,提高他被选中的权重。但是这种场景下,其实训练的效果一直都不太好。这个也就是为什么目前为止除了deep seek之外。很少有极大的厂商去坚持走moe这个路线。
第二个是deep seek。在它的第一代moe的模型中提出的一个创新点:它是增加了设备级别的负载均衡,它主要是为了提升训练时设备负载的一个均衡性。当有些设备没有被使用的时候,我会如何去考量让它的设备的权重,设备处理token的一个几率会增加。第二是当我的设备一直被使用的时候,如何让设备降负载。
DeepSeek V2做了哪些事
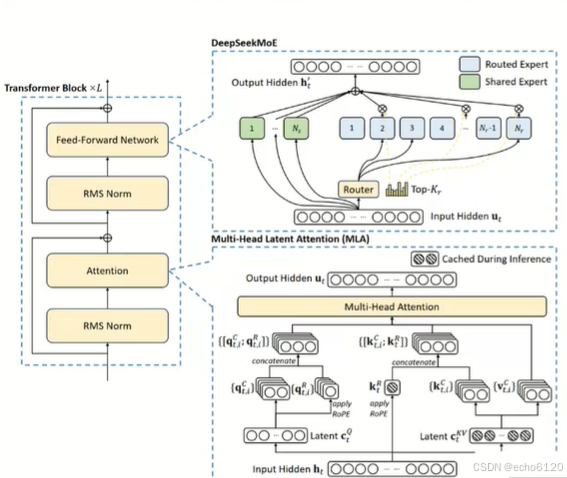
如图,上面它主要做的是负载均衡的优化,下面是指的它的多头注意力机制叫mla。
1.架构优化 Multi-head Latent Attention
细粒度专家分割(Fine-Grained Expert Segmentation)
共享专家隔离(Shared Expert Isolation)
下面那张表对deepseek做了一个mla,它与之前的mha就多头注意力机制相比,
它的优势:
它可以理解为做了一个降秩。这种场景下相当于一个矩阵,我对它做了降秩,它的参数量会大大的减小,计算的复杂度,可以理解为原来的n方变成n。可以带来什么样的好处呢?
好处是可以关注到更长的对话之间互相的一个注意力机制。在mla这种场景下,kv catch的显存或者kv catch的占用的显存量是做了极大的优化和降低的,能够捕捉更大窗口的上下文的一个关联。所以它相比mha gqa和mqa它有一个更强的一个能力。
2.:负载均衡优化
设备受限的专家路由机制(Device-Limited Routing)token角度:控制专家数增多带来的通信成本
通俗来讲就是从处理的一个token角度来看,一个token究竟能分给多少个设备来处理。最早的时候是有多少设备这个token不能说是等概率的,至少是有可能会被所有的设备来处理。这样的话来会极大的增加设备之间的通信成本,引入了设备受限的专家路由机制。从token的角度来看,处理我的设备会变少,那我的通信成本会大量的大量的降低。
通信负载均衡(Communication Balace Loss)设备角度:保证设备最多接收等量token
这个是从设备角度来考量的,保证设备接收最多等量的token。保证所有的设备能够处理几乎相等的量的一个token的数。在设备之间它的均衡性也会做的比较好。
Token丢弃策略(Token-Dropping Strategy) token 角度:超出容量的尾部token丢弃【v3删除了这个策略】
当超出一定长度的尾部的token会被丢弃,这个是类似于dropout的一一种方式。保证了负载均衡更细腻度的优化。
3.算法优化GRPO
对它是进一步的前进一步的提升了我的模型的一个强化学习的能力。
V3 671B又做了什么
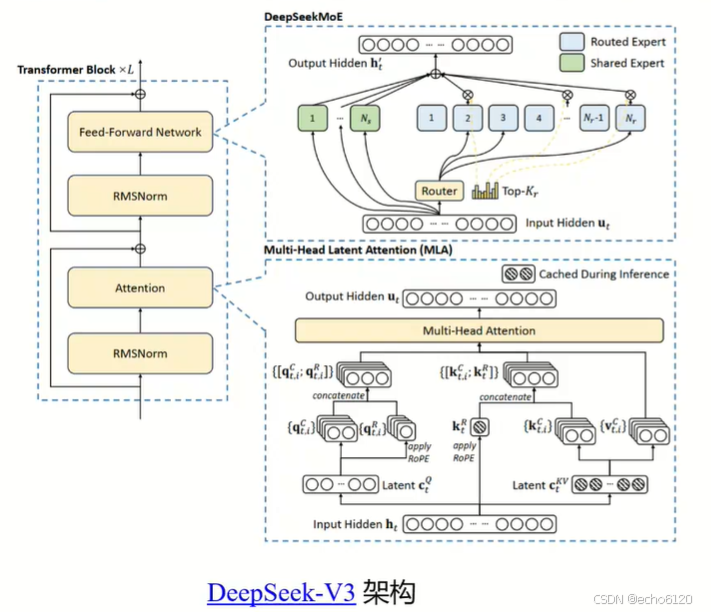
1.门控网络
MoE门控计算 SoftMax--》Sigmoid 专家数增多,归一化的长尾部分太小区分度减小。
第三代的整个架构和v2是一模一样的。他唯一改动的就是路由机制,如何去选top k这的一个计算。
当我的专家数量比较多,因为第三代的专家数量应该是1256个,soft max有一定的局限性。它的长尾部分,因为soft max它会让大的更大小的更小。那在尾部的时候,它们之间的区分度就会变得很小,这样的话计算就会非常多的超现象。
这个是就把我的路由改成了一个sigmoid,这个是对门控机制的一个改革。
在 MoE(混合专家模型)中,门控机制从 softmax 转成 sigmoid 主要有以下区别: 输出范围与性质 softmax:输出是一个概率分布,所有输出值之和为 1,用于表示每个选项被选中的概率,适用于在多个互斥的专家中进行选择,比如有多个不同功能的专家,softmax 能给出每个专家被选中的概率,以确定最终使用哪个专家。 sigmoid:输出值在 0 到 1 之间,不表示概率分布,而是衡量每个专家与输入的相关性或激活程度,可以理解为每个专家对于处理当前输入的 “贡献度”,每个专家都可以有自己独立的激活程度,不是互斥关系。 计算与决策方式 softmax:计算时会综合考虑所有专家的得分情况来进行归一化,以确定每个专家的选择概率,是一种全局的决策方式,需要比较所有专家的相对得分。 sigmoid:对每个专家独立计算,只根据当前专家与输入的关系得出一个激活值,不依赖于其他专家的得分,是一种更局部、独立的决策方式,速度可能更快,且更灵活。 对模型的影响 softmax:倾向于选择一个主要的专家来处理输入,可能会使模型在不同专家之间有更明确的分工,但也可能导致某些专家过度使用,而其他专家利用率低。 sigmoid:允许模型同时利用多个专家的信息,根据输入的特点动态地决定每个专家的参与程度,可能使模型的表现更平滑、更综合,有助于融合多个专家的知识,但也可能带来一些计算上的冗余。
2;负载均衡
无辅助损失负载均衡(Auxiliary-Loss-Free load balancing),添加bias 仅用于计算Top-k
squence粒度的负载均衡损失(Complementary Sequence-Wise Auxiliary Loss)
无损的负载均衡是对2n个专家都添加相应的偏置。当专家负载大,偏执就会减小。那专家负载比较小,我的偏置就会增大。
达到偏置的相对平衡,也是实现专家的平衡,这个只用于计算top k,他不会参与所有的推理计算。
删除token-dropping策略
总结:
moe的第一代、第二代、第三代,参数量在逐步增加,优化的粒度被逐步细化。
一直被坚持的,一个是共享的一个专家。第二是细粒度切分的一个专家。
在第三代里边被保留的:第一个是device limited routing,一个token它最多能被多少个device做处理,这个做了一个限制。
第二个是无损的负载均衡和序列的一个负载均衡。这两块是替代了之前的专家级别的均衡,设备级别的均衡以及通信。
然后同时他也丢弃了之前的一个token dropping的一个策略。
moe的门控机制从soft max转成了sigmoid。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)