DeepSeek深度:市场表现、发展展望、产业机遇及相关公司深度梳理
DeepSeek 近期分别发布大模型 DeepSeek-v3 和推理模型 R1,前者在大模型主流榜单的开源模型中位列榜首,并与世界上最先进的闭源模型不分伯仲;后者性能对标OpenAI的o1正式版,在数学、代码和自然语言推理等任务上表现卓越。以上两个模型均通过算法和架构的创新,大幅降低了训练成本和推理成本,为AI技术的普及与创新作出了卓越的贡献。
DeepSeek 近期分别发布大模型 DeepSeek-v3 和推理模型 R1,前者在大模型主流榜单的开源模型中位列榜首,并与世界上最先进的闭源模型不分伯仲;后者性能对标OpenAI的o1正式版,在数学、代码和自然语言推理等任务上表现卓越。以上两个模型均通过算法和架构的创新,大幅降低了训练成本和推理成本,为AI技术的普及与创新作出了卓越的贡献。DeepSeek相关模型自从推出后,立刻占据全球科技头条并引发巨大关注,相关人士认为,DeepSeek呈现出的算法创新、性能表现、开源属性等多重因素,将对AI应用与算力行业产生深远的影响。
DeepSeek开源模型将直接推动AI产业模型能力普遍提升,同时低廉的使用成本搭配卓越的性能倒逼 OpenAI降低GPT使用成本、加速模型迭代,促进产业生态繁荣。大模型能力普遍提升一方面将利好AI 应用开发,尤其小模型易于在端侧落地;另一方面,从更长远的角度看,DeepSeek带来的也将是算力层面的杰文斯悖论,整体AI应用生态繁荣将带来推理算力的更大需求。
以下内容我们就将聚焦DeepSeek,对产业相关问题展开分析。DeepSeek当前呈现怎样的基础现状?其发布以来市场表现如何?在技术创新方面,DeepSeek有哪些创新之处?在应用场景上,DeepSeek将对相关场景带来怎样的赋能?以及DeepSeek的加速适配,将会对哪些层面带来市场机遇?相关企业发展情况如何?后续产业将会呈现怎样的发展趋势?立足以上问题,我们为大家一一解析。
一、行业概况
1、版本有序落地,DeepSeek的产品体系不断丰富
模型厚积薄发,技术能力不断突破。DeepSeek(中文名为深度求索)成立于2023年,是一家位于杭州的人工智能公司,为量化巨头幻方量化的子公司。公司自成立以来就不断研发迭代大模型,幻方目前拥有1万枚英伟达A100芯片,2023年4月幻方宣布成立新组织,集中资源和力量,探索AGI(通用人工智能)的本质,在一年多时间里进展迅速。

DeepSeek的产品体系不断丰富,每个模型都在不同的领域和任务中展现出了独特的优势和性能特点。随着时间的推移,DeepSeek在不断优化模型性能的同时,也在推动着人工智能技术的发展和应用。
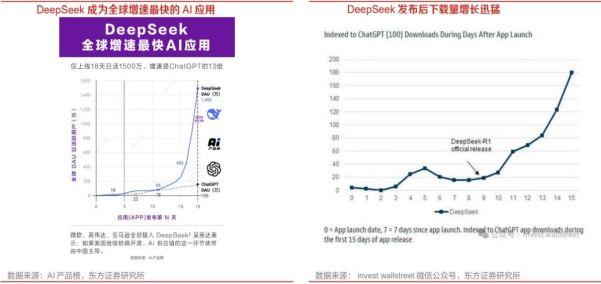
从版本迭代来看,公司历经一年已然迭代多个版本,目前模型能力可比肩OpenAI o1-mini,从下载量来看,根据AI产品榜数据显示,DeepSeek成为全球增速最快AI应用,上线20天日活突破2000万。
2、Deepseek:AI生产函数的根本性改变
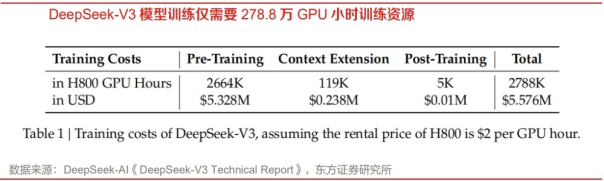
简单来说,DeepSeek是一款大语言模型(LLM),主打“极致性价比”。它能写代码、解数学题、做自然语言推理,性能优越,但成本却低到离谱——训练费用仅557.6万美元,是GPT-4o的十分之一,API调用成本更是只有OpenAI的三十分之一。

3、科技巨头纷纷接入DeepSeek,推动全球AI生态发展
英伟达于2025年1月30日正式宣布,DeepSeek-R1模型已作为NVIDIANIM微服务预览版上线;2025年1月29日,微软正式宣布将DeepSeek-R1模型纳入Azure AI Foundry平台。企业可以在Azure AI Foundry上通过模型目录以无服务器端点的形式访问DeepSeek-R1。此外DeepSeek-R1还上线了GitHub Models,开发者可以在GitHub上免费试用该模型;2025年2月1日,硅基流动和华为云团队双方联合首发并上线基于华为云昇腾云服务的DeepSeek R1/V3推理服务。得益于自研推理加速引擎加持,硅基流动和华为云昇腾云服务支持部署的DeepSeek模型可获得持平全球高端GPU部署模型的效果。提供稳定的、生产级服务能力,让模型能够在大规模生产环境中稳定运行,并满足业务商用部署需求。华为云昇腾云服务可以提供澎湃、弹性、充足的算力。
二、市场表现
1、DeepSeek-V3性能表现不输全球顶尖模型
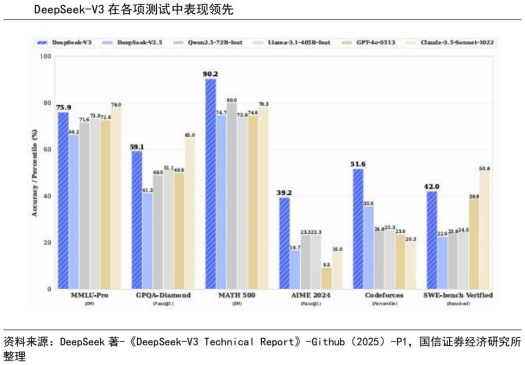
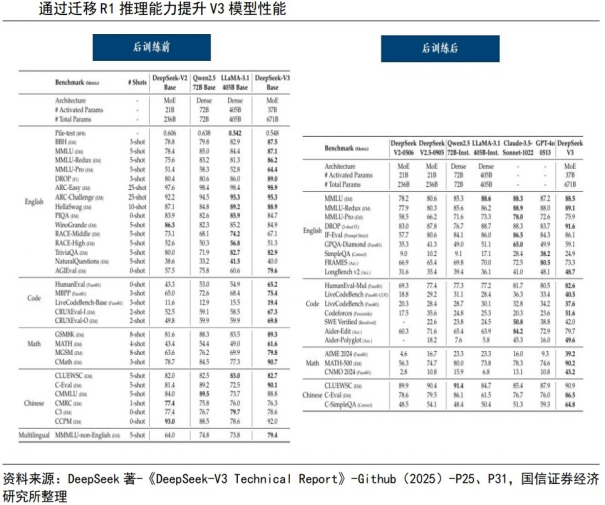
2024年12月26日,杭州深度求索(DeepSeekAI)发布DeepSeek-V3并同步开源,据介绍,DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
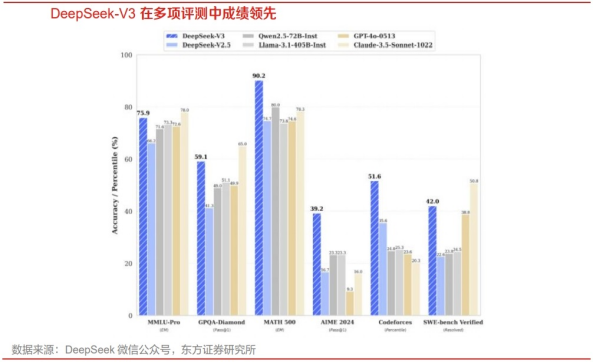
具体而言,DeepSeek-V3在知识类任务(MMLU,MMLU-Pro,GPQA,SimpleQA)上的水平相比前代DeepSeek-V2.5显著提升,接近当前表现最好的模型Anthropic公司于2024年10月发布的Claude-3.5-Sonnet-1022;在长文本评测(DROP、FRAMES和LongBenchv2)方面,V3平均表现也超越其他模型。在算法类代码场景(Codeforces),V3远远领先于市面上已有的全部非o1类模型,并在工程类代码场景(SWE-Bench Verified)逼近Claude-3.5-Sonnet-1022。而在美国数学竞赛(AIME2024,MATH)和全国高中数学联赛(CNMO2024)上,DeepSeek-V3大幅超过了其他所有开源闭源模型。
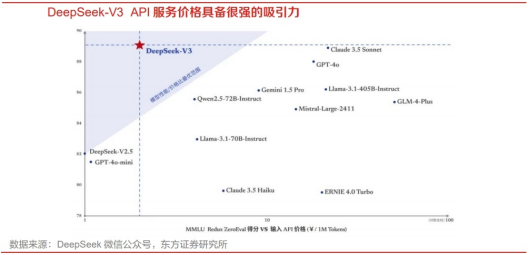
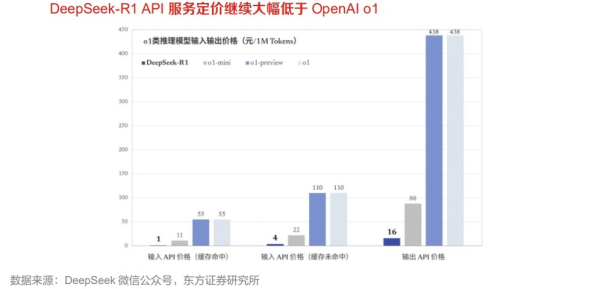
另外,DeepSeek-V3通过算法和工程上的创新,将生成吐字速度从20TPS(Transactions Per Second每秒完成的事务数量)大幅提高至60TPS,相比V2.5模型实现了3倍的提升,可以带来更加流畅的使用体验。同时,模型API服务定价也将调整为每百万输入tokens0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens8元,因此,V3模型在性能实现领先的同时,定价大幅低于市面上所有模型,性价比优势明显。
2、R1模型实现了比肩OpenAI o1的推理能力
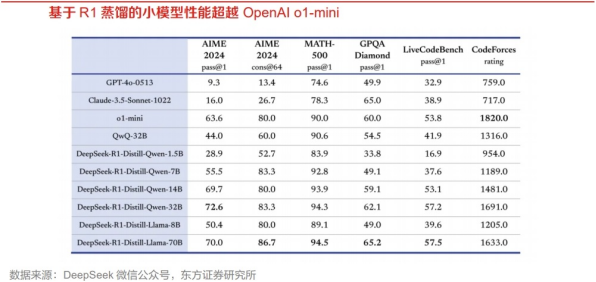
2025年1月20日,DeepSeek再次扔出重磅炸弹,发布了推理模型R1,该模型在后训练阶段大规模使用了强化学习技术,在仅仅使用极少标注数据的情况下,极大提升了模型推理能力,在数据、代码、自然语言推理等领域均实现了比肩OpenAI o1模型的能力。
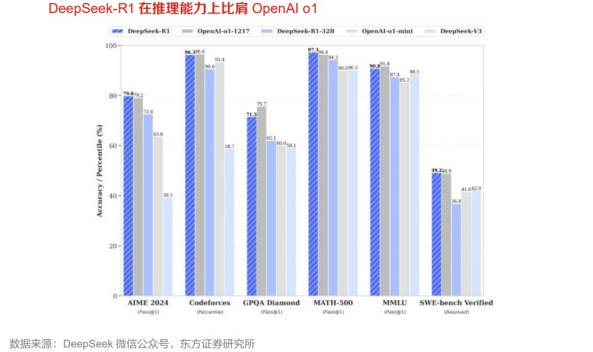
DeepSeek不仅开源了R1-Zero和R1两个660B模型,还通过DeepSeek-R1的输出,蒸馏了6个小模型开源给社区,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。同时,DeepSeek还修改了产品协议,支持用户进行“模型蒸馏”,即允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
除了开源相关模型外,DeepSeek-R1上线API,对用户开放思维链输出,服务定价为每百万输入tokens1元(缓存命中)/4元(缓存未命中),每百万输出tokens16元,与OpenAI o1API调用相比,继续保持超高的性价比。与此同时,DeepSeek还上线了APP并更新官网,打开“深度思考”模式,即可调用最新版DeepSeek-R1完成各类推理任务。
3、DeepSeek-V3、R1模型在产业中引发巨大反响
DeepSeek-V3、R1两款模型最让人印象深刻的不仅在于其比肩业内最佳表现的性能,更在于超低的训练成本:DeepSeek在V3相关的论文中披露,V3仅仅使用2048块H800 GPU训练2个月的时间,共消耗278.8万GPU小时,而按照OpenAI创始成员之一Andrej Karpathy介绍,Llama3-405B则消耗了3080万GPU小时,是V3的11倍;如果按照H800 GPU每小时2美金的租赁费用计算,意味着V3模型正式训练仅仅需要557.6万美金,而此前同等性能的模型则需要0.6-1亿美金。而R1模型是在DeepSeekV3的基础上,通过引入大规模强化学习(Reinforcement Learning)和多阶段训练,进一步提升推理能力的模型,据专家判断,在V3的基础上生产R1模型的成本可能非常低廉。
DeepSeek-V3、R1两款模型的推出,犹如在AI行业投入了两颗重磅炸弹,DeepSeek迅速成为科技产业最耀眼的明星企业,并引发了巨大的讨论与关注。相较于各科技巨头不断构建更大规模算力集群来训练更强大的模型,DeepSeek向大家展示了通过精巧的算法优化,可以在低一个数量级算力消耗的情况下生产出顶尖性能的模型。
DeepSeek已经成为众多科技领域领袖重点关注的对象:微软CEO纳德拉在财报电话会议上称Deep Seek“有一些真的创新”,并透露R1模型已经可以通过微软的AI平台获取;Meta CEO扎克伯格表示Meta将DeepSeek视为竞争对手并正在学习;ASML CEO则在接受采访时表示DeepSeek这样的低成本模型将带来更多而非更少的AI芯片需求;Anthropic创始人认为V3是真正的创新所在;人工智能专家吴恩达也发文认为中美AI差距正在迅速缩小。OpenAI CEO山姆奥特曼更是在发布o3-mini后罕见地承认“在开源上OpenAI站在了历史的错误一方”。
在超高的热度下,DeepSeek成为了全球增速最快的AI应用,仅上线18天日活就达到了1500万,而ChatGPT过1500万花了244天,增速是ChatGPT的13倍;1月26日同时登顶苹果AppStore和谷歌PlayStore全球下载榜首,目前仍然在100多个多家/地区维持领先。
三、技术创新解析
1、模型蒸馏增强小模型推理能力,视觉解耦统一多模态理解和生成
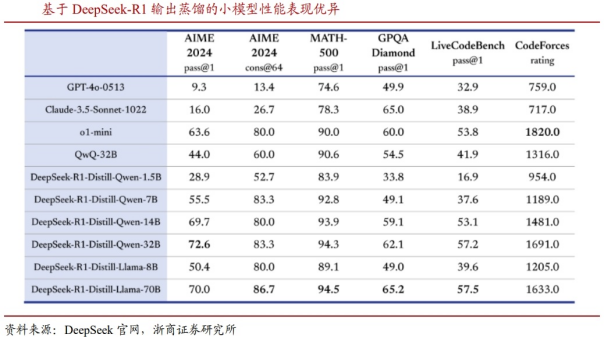
DeepSeek采用模型蒸馏技术,极大提升模型推理能力。DeepSeek官方技术文档显示,研究人员使用DeepSeek模型遴选了80万个样本,并且基于DeepSeek-R1模型的输出对阿里Qwen和Meta的Llama开源大模型进行微调。评测结果显示,基于DeepSeek-R1模型蒸馏的32B和70B模型在多项能力上可对标OpenAI o1-mini的效果。DeepSeek研究结果表明,蒸馏方法可以显著增强小模型的推理能力。
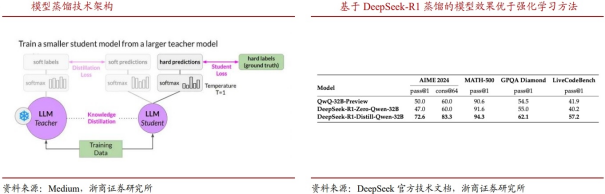
DeepSeek采用蒸馏技术得到的模型效果优于同等条件下使用强化学习(RL)的效果。技术文档显示,DeepSeek-R1-Zero-Qwen-32B模型是研究人员在Qwen-32B-Base模型基础上使用数学、代码、STEM数据进行超过10,000步的RL训练得到,其各项测评结果均差于DeepSeek-R1模型通过蒸馏得到的DeepSeek -R1-Distill-Qwen-32B模型。考虑RL方法需要大量的计算资源,蒸馏方法在性能和性价比方面均呈现出显著的优势。
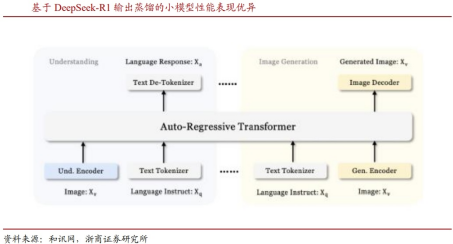
anus-Pro是DeepSeek发布的一款统一多模态理解与生成的创新框架,通过解耦视觉编码的方式,极大提升了模型在不同任务中的适配性与性能。其中,Janus-Pro的SigLIP编码器专门负责理解图像,能提取图像的高层语义特征,并关注图像的整体含义和场景关系;而VQ tokenizer编码器,专门用于创作,将图像转换为离散的token序列,这样架构创新使得Janus-Pro在7B参数规模下,仅用32个节点、256张A100和14天的时间就完成训练并取得出色性能表现。
2、DeepSeek创新技术架构:打破传统内存和算力瓶颈
DeepSeek通过多方面创新实现在低算力的同时性能优异。DeepSeek模型对算力要求相比以往大模型大幅降低,主要得益于其在架构设计、训练策略、算法优化以及硬件适配等多方面的创新。
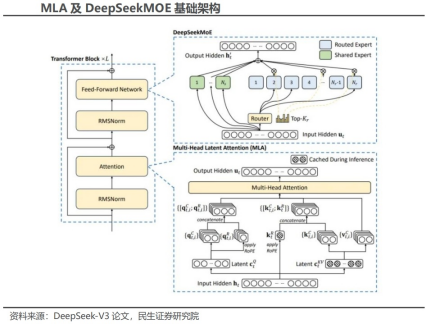
多头潜注意力(MLA)、深度求索混合专家系统(DeepSeekMoE)的创新架构显著降低训练和推理时的内存占用和计算量。传统计算方式存在对KV矩阵重复计算的问题,这不仅浪费了大量的计算资源,还会导致显存消耗过大,影响模型的运行效率。而MLA技术巧妙地解决了这个难题,它通过独特的算法设计,减少了对KV矩阵的重复计算,大大降低了显存的消耗。而MOE技术将模型分解为多个专家模型和一个门控网络,门控网络根据输入数据的特点,智能地选择合适的专家模型来处理,这样不仅减少了知识冗余,还提高了参数利用效率。在自然语言处理的语言模型任务中,使用MOE结构的DeepSeek模型可以用相对较少的参数,保持甚至提升语言生成的质量,同时显著降低训练和推理时的内存占用和计算量,根据CSDN,DeepSeekMoE在保持性能水平的同时,实现了相较传统MoE模型40%的计算开销降低。
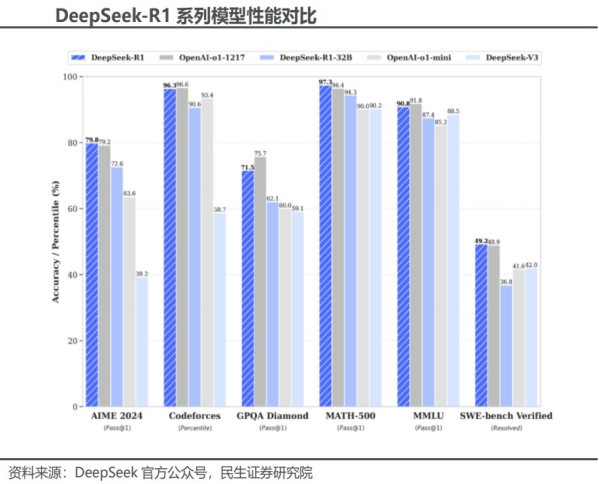
DeepSeek-R1在继承了V3的创新架构的基础上,在后训练阶段大规模使用了强化学习技术,自动选择有价值的数据进行标注和训练,减少数据标注量和计算资源浪费,并在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,DeepSeek在AIME2024测评中上获得79.8%的pass@1得分,略微超过OpenAI-o1;在MATH-500上,获得了97.3%的得分,与OpenAI-o1性能相当,并且显著优于其他模型。
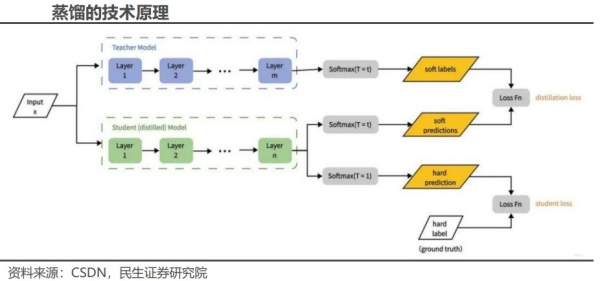
DeepSeek的蒸馏技术为模型的广泛运用打开想象空间。模型蒸馏(Knowledge Distillation)是一种将大型复杂模型(教师模型)的知识迁移到小型高效模型(学生模型)的技术。在深度学习领域,模型参数数量通常被视为衡量模型复杂度和能力的一个重要指标,一般认为参数越多,模型能够学习到的知识和模式就越丰富,性能也就越强。然而,大参数模型也带来了诸多问题,如训练成本高昂,需要大量的计算资源和时间;部署和运行时对算力要求极高,限制了其在一些资源有限场景下的应用。
DeepSeek的蒸馏模型在计算资源、内存使用和推理速度方面都实现了显著的优化。蒸馏模型的参数量大幅减少,例如DeepSeek-R1-Distill-Qwen-7B的参数量仅为7B,相比原始的DeepSeek-R1(671B参数),计算复杂度显著降低。由于参数量的减少,蒸馏模型在内存占用方面也表现出色。且DeepSeek的蒸馏模型在推理速度上实现了显著提升。例如,DeepSeek-R1-Distill-Qwen-32B在处理复杂的推理任务时,推理速度比原始模型提高了约50倍。
且在多个基准测试中,DeepSeek的蒸馏模型表现优异。例如,DeepSeek R1-Distill-Qwen-7B在AIME 2024基准测试中实现了55.5%的Pass@1,超越了QwQ-32B-Preview(最先进的开源模型)。DeepSeek-R1-Distill-Qwen-32B在AIME2024上实现了72.6%的Pass@1,在MATH-500上实现了94.3%的Pass@1。这些结果表明,蒸馏模型在推理任务上不仅能够保持高性能,还能在某些情况下超越原始模型。
3、多层面技术提升训练效率,测试性能领跑开源模型
(1)模型层:在多项测评中能力领先其他开源模型
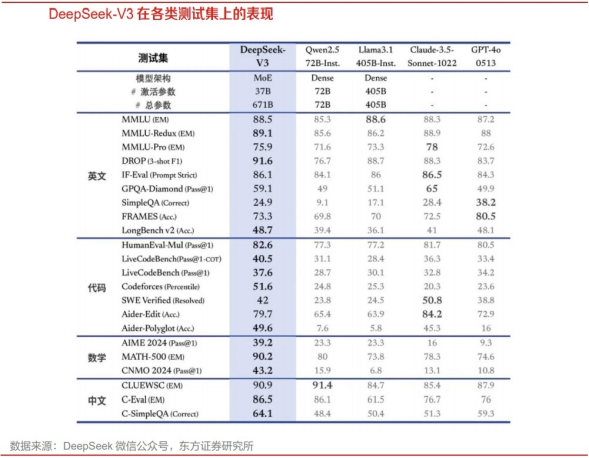
模型采用MoE架构,运用R1提炼推理能力。据DeepSeek-V3 Technical Report,DeepSeek-V3(以下简称模型)采用MoE(专家混合模型)架构,总参数量达6710亿,每个Token激活37亿参数。在预训练阶段,模型使用14.8T的高质量数据集进行训练,并在后续对模型进行了两个阶段的上下文长度扩展,第一阶段将上下文长度扩展至32K,第二阶段进一步扩展至128K。在后训练部分,DeepSeek使用了监督微调(SFT)和强化学习(RL)来提升模型能力,并从DeepSeek R1系列模型中提炼推理能力,以提高模型在实际运用中的表现。
在实际测评中,DeepSeek表现领先开源模型,并进一步缩小与闭源模型的差距。知识层面:在教育类基准测试如MMLU、MMLU-Pro上,模型超越了目前所有开源模型,其表现与领先的闭源模型如GPT-4o和Claude-Sonnet-3.5相当。在常识性测试中,模型在SimpleQA和Chinese SimpleQA中的评分领先,在英语事实性知识(SimpleQA)方面稍逊于GPT-4o和Claude-Sonnet-3.5;代码、数学与推理层面:在数学相关测试中,模型在所有非思维链推理模型中表现出色,在MATH-500等特定测试中超越了o1-preview。模型在编程竞赛基准测试中表现领先,在工程类任务中模型表现略逊于Claude-Sonnet-3.5。
(2)架构层:基本沿用V2架构,引入MTP等全新技术
沿用V2基本架构,引入无辅助损失的负载均衡策略。模型在架构层面沿用V2模型中的多头潜在注意力(MLA)以及DeepSeekMoE架构,以实现经济训练。在此基础上,模型引入了无辅助损失的负载均衡策略,以减少因负载均衡所带来的性能下降。MLA架构用于减少注意力键值(KV)缓存时的空间占用,通过对注意力键和值进行低秩压缩来实现,帮助模型在维持性能的同时减少计算资源的消耗。
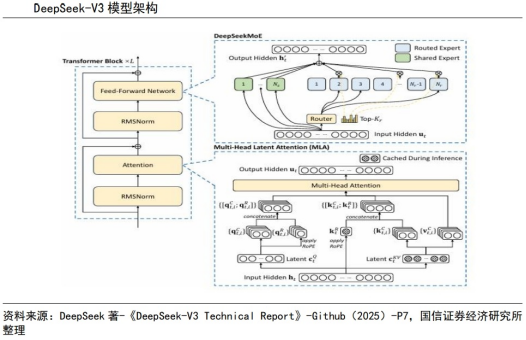
DeepSeekMoE较传统MoE有多方面改进。与传统MoE架构相比,DeepSeekMoE使用了更细粒度的专家,并将部分专家设置为共享专家,能够更精确地针对特定的问题提供解决方案。同时,传统MoE架构采用辅助损失来鼓励负载平衡,以免不平衡的专家载荷导致计算效率降低,但这可能在某些情况下影响模型性能。DeepSeekMoE引入了无辅助损失的负载平衡策略,在每个专家模型的任务匹配程度评分中添加一个偏置项,用于调整每个专家在决定哪些专家应该处理哪些任务时的负载,同时使用补充序列级辅助损失,以此来优化整个系统的性能和效率。
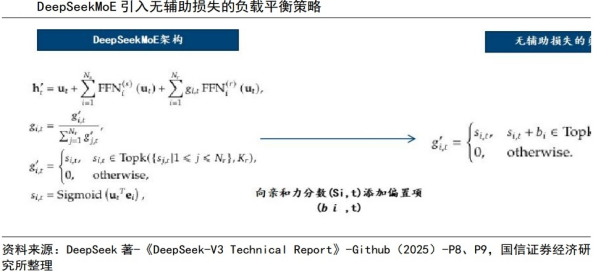
模型通过MTP提升数据利用效率。DeepSeek在模型训练时设定了多Token预测(MTP)目标,将预测范围扩展到每个位置的多个未来Token。MTP增加了模型训练过程中的信号密度,提高模型对数据的整体利用效率,同时增强模型生成文本的连贯性。MTP策略主要旨在提高主模型的性能,在推理过程中可直接丢弃MTP模块,主模型独立正常运行。
(3)训练层:通过工程优化,进一步实现成本控制
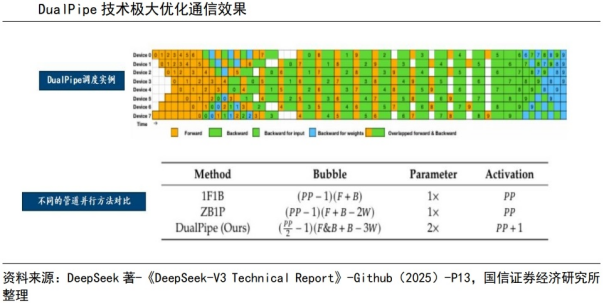
为了促进模型的高效训练,DeepSeek实施了工程优化。首先,模型使用了DualPipe算法,以实现高效的管道并行。与现有方法相比,DualPipe具有更少的管道气泡(等待数据处理或通信延迟形成的停滞区域),在模型训练的前向和后向传播过程实现了重叠计算和通信,从而提高了整体的训练效率。其次,DeepSeek引入了FP8混合精度训练,优化了训练期间的内存占用。
DualPipe技术优化通信成本。在大规模分布式训练系统中,每个计算节点需要频繁地与其他节点交换信息,导致部分时间在等待数据的传输,计算资源不能持续进行数据处理,资源利用率低下。以DeepSeek -V3为例,在模型训练时跨节点的专家并行性带来的通信开销导致计算与通信的比率约为1:1。为了解决这一问题,DeepSeek在单独的前向和后向块内部重叠计算和通信,通过采用双向管道调度,同时从管道的两端供给数据,使大部分通信可以完全重叠,从而实现通信成本的降低。
使用FP8数据格式提升训练效率。DeepSeek在训练模型时提出了使用FP8数据格式的细粒度混合精度框架,大部分计算密集型操作在FP8精度下进行,少数关键操作保持在原始的数据格式中。这种设计理论上使计算速度比传统的BF16方法提高了一倍。同时,使用FP8精度存储可以减少内存需求,使得训练过程更加高效。然而,低精度计算可能会引入更多的数值不稳定性和精度损失,为了解决这一问题,DeepSeek在GEMM(通用矩阵乘法)操作的内部维度引入了每组缩放因子,根据较小的元素组调整缩放比例,使量化过程能更好地适应离群值,从而保障了低精度训练结果的准确性。
(4)推理层:将R1推理能力迁移至模型中
推出类o1推理模型,为V3模型提供基础。2024年11月20日,DeepSeek发布DeepSeek-R1-Lite,R1系列模型使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字,在数学、代码以及各种复杂逻辑推理任务上,取得了与o1-preview相似水准的推理效果。目前该系列模型仍处于迭代开发阶段,正式版DeepSeek-R1模型技术仍未开源。
以R1推理能力为底座,将能力迁移至V3中。在后训练部分中,对于推理相关的数据集,DeepSeek利用内部的DeepSeek-R1模型生成数据。DeepSeek首先开发一个专门针对特定领域(如编程、数学或一般推理)的专家模型,使用结合了监督式精调(SFT)和强化学习(RL)的训练管道,使用这个专家模型作为最终模型的数据生成器。这种方法确保了最终训练数据保留了DeepSeek-R1的优势,使用此训练数据训练的V3模型能够极大的提升自身的推理能力。对于非推理数据,DeepSeek使用DeepSeek-V2.5生成响应,并招募人类注释员来验证数据的准确性和正确性。通过从DeepSeek-R1系列模型中提取推理能力,V3模型实现了在数学、编程等领域性能上的提升。
推理算力包含GB300、博通、marvell等各类asic芯片。
四、应用场景
DeepSeek的技术创新不仅降低了成本,还推动了AI技术在各行各业的应用。以下是具体的应用场景分析:
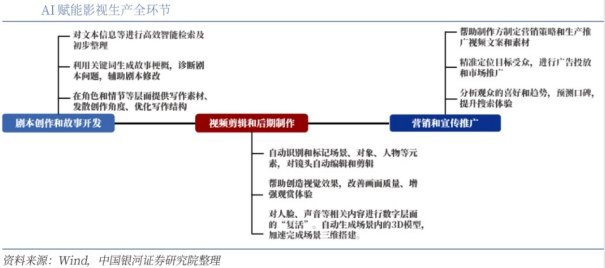
1、AI+影视:重塑影视创作与生产
AIGC(生成式AI)在影视生产全环节得到广泛应用,从剧本生成到场景渲染,AI技术大幅降低了影视制作的成本和时间。例如,AI可以根据导演的创意快速生成剧本大纲,甚至生成详细的场景描述和对话。在后期制作中,AI可以自动完成特效渲染、画面修复等工作,提高制作效率。此外,AI还可以通过分析观众反馈,实时调整剧情走向,提升影视作品的吸引力和观众满意度。
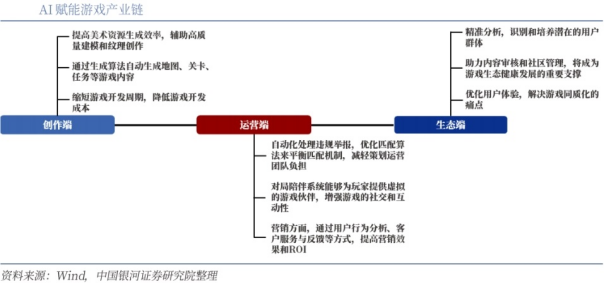
2、AI+游戏:提升游戏开发效率与体验
AI技术在游戏资产生成、仿真场景渲染等多个环节的应用,提升了游戏开发的效率和多样性。AI可以自动生成游戏中的角色、道具、场景等资产,减少人工设计的工作量。同时,AI驱动的NPC(非玩家角色)能够根据玩家的行为做出更智能的反应,增强游戏的互动性和趣味性。此外,AI还可以优化游戏的渲染效果,提高画面质量和帧率,为玩家带来更流畅的游戏体验。
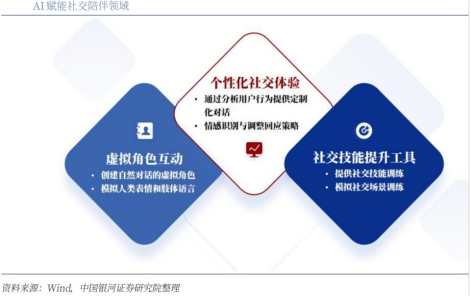
3、AI+社交陪伴:满足个性化社交需求
AI驱动的虚拟助手和虚拟角色能够提供情感支持和个性化服务,满足用户的社交需求。例如,虚拟助手可以根据用户的兴趣爱好、情绪状态等,主动发起对话,提供陪伴和安慰。在社交平台上,AI可以生成虚拟角色,与用户进行互动,甚至参与社交活动。这些虚拟角色可以根据用户的反馈不断学习和优化,提供更贴心的服务,缓解用户的孤独感。
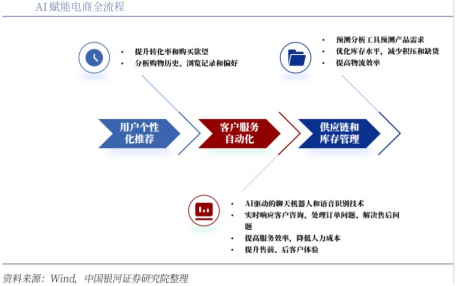
4、AI+电商:提升运营效率与用户体验
AI技术通过分析用户行为数据,实现精准推荐和自动化客户服务,提升了电商平台的运营效率和用户体验。AI可以根据用户的浏览历史、购买行为等,精准推荐符合用户需求的商品,提高用户的购买转化率。同时,AI驱动的聊天机器人可以实时解答用户的问题,提供24小时不间断的客户服务。此外,AI还可以优化电商平台的物流配送、库存管理等环节,降低运营成本,提高运营效率。
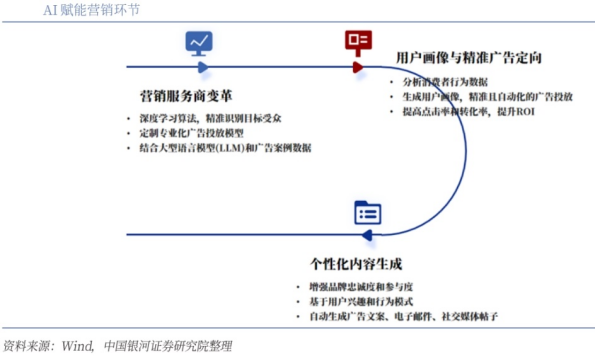
5、AI+营销领域:实现个性化的营销策略
在AI+营销领域,DeepSeek凭借其强大的AI能力,为营销行业带来了新的变革。DeepSeek能够通过深度学习和数据分析,精准地识别和预测消费者的偏好和需求,实现个性化的营销策略。它可以根据用户的浏览历史、购买行为等多维度数据,构建详细的用户画像,为每个用户推荐符合其兴趣的商品,从而提高用户的购买转化率。同时,DeepSeek的AI技术还可以优化广告投放策略,实时调整广告的投放时间和渠道,确保广告能够在最合适的时机触达目标受众。此外,DeepSeek的生成式AI能力能够自动生成高质量的营销文案、图片、视频等内容,为品牌商提供多样化的创意素材。这些内容不仅具有高度的创意和吸引力,还能精准传达品牌的核心价值。通过这些创新应用,DeepSeek帮助企业在海量用户中精准触达目标客户,提升营销效果和投资回报率,为营销行业注入新的活力。
五、产业机遇
1、产业加速适配DeepSeek,“Jevons悖论”下算力需求或将提升
(1)国产Deepseek模型爆火,高端算力/高集群能力并非唯一解
R1模型在技术上实现了重要突破——用纯深度学习的方法让AI自发涌现出推理能力,在数学、代码、自然语言推理等任务上,性能比肩美国开放人工智能研究中心(OpenAI)的o1模型正式版,该模型同时延续了该公司高性价比的优势。深度求索公司R1模型训练成本仅为560万美元,远远低于美国开放人工智能研究中心、谷歌、“元”公司等美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元。根据新智元援引外媒报道,他们在短短两个月时间,在2048个H800GPU集群上,训出6710亿参数的MoE语言模型,比顶尖AI效率高出10倍。
Deepseek突破不是用CUDA实现的,而是通过大量细粒度优化以及使用英伟达的类汇编级别的PTX(并行线程执行)编程。在训练V3模型时,DeepSeek对英伟达H800GPU进行了重新配置:为了最大化性能,DeepSeek还通过额外的细粒度线程/线程束级别调整,实现了先进的流水线算法。这些优化远超常规CUDA开发水平,但维护难度极高。然而,这种级别的优化恰恰充分展现DeepSeek团队的卓越技术实力。
(2)“Jevons悖论”或说明算力需求有望持续提升
DeepSeek激活AI产业链,云厂商加速适配。基于DeepSeek的开源属性,AI产业链企业正加速适配DeepSeek。据不完全统计,2月以来,已有超20家云服务和智算企业宣布支持DeepSeek,包括华为云、腾讯云、阿里云、百度智能云、火山引擎、京东云、三大运营商云、国家超算互联网平台等。同时,海外科技巨头微软、英伟达、英特尔、AMD、亚马逊等也已上线DeepSeek。DeepSeek作为开源的大模型技术,正持续激发产业拥抱新技术,加速AI技术升级迭代。
DeepSeek持续火爆,官网多次宕机。据AI产品榜数据显示,1月20日DeepSeekR1模型发布后,1月DeepSeek用户增长达1.25亿(含网站(Web)、应用(App)累加不去重);1月27日,DeepSeek应用登顶苹果中国地区和美国地区应用商店免费APP下载排行榜;同时,根据QuestMobile数据显示,Deep Seek日活跃用户数在2月1日突破3000万大关,成为史上最快达成这一里程碑的应用。与此同时,访问量激增导致DeepSeek服务状态在1月27日多次出现异常,影响API服务和网页对话服务;2月6日,DeepSeek开放平台由于服务器资源紧张,暂停了API服务充值。在服务需求高增的同时,算力不足仍是目前制约产业发展的瓶颈之一。
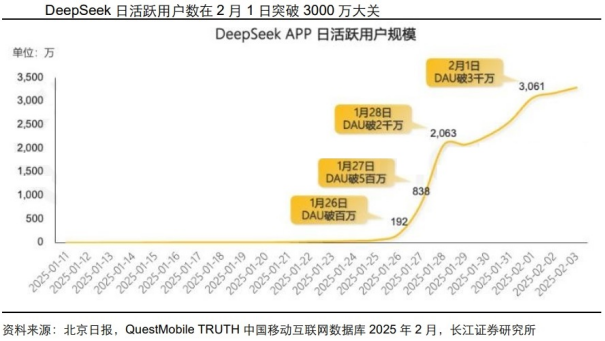
“Jevons悖论”或说明算力需求有望持续提升。“Jevons悖论”指出:当资源利用效率提高时,实际上可能会导致资源消耗的增加,而不是减少。由于DeepSeek的技术突破使得大模型训练成本大幅优化,或将驱动企业开发此前因预算受限而搁置的创新项目,最终加大了整体技术支出。同时,随着人工智能变得更加高效,其使用量也将激增。因此,长期视角下,高质量开源低价模型将带动AI大繁荣,算力需求不降反增。
DeepSeek加速AI平权,算力需求或将持续提升。随着DeepSeek在大幅降低AI大模型使用成本的同时,进一步提升了应用质量,或将在其基础上催生大量垂类应用,并加速AI应用落地,进而进一步带动算力需求的爆发。
(3)多家云厂适配DeepSeek,第三方云厂有望受益
云资源成为“硬通货”,云厂商手握算力资源,打开阈值上限。DeepSeek通过开源实现了与OpenAI的o1模型性能相媲美的R1系列模型,不仅降低了技术门槛,还为中小企业和初创公司提供了平等的技术获取机会,从而推动了AI生态的完善。广大研究人员、开发者以及企业,无需依赖商业公司的闭源模型,能够基于DeepSeek的开源成果进行更深入的研究和开发。企业争相部署DeepSeek模型的背景下,算力模型的平铺最后,云厂商会因后天积累的算力资源而受益。DeepSeek模型的部署不仅降低了算力门槛,还为云厂商带来了新的收益机会。在大模型之间的差距被拉平的的趋势下,能赢得“胜局”的决定权落回到算力层面,云厂商在具备充足的算力“弹药”与广泛的用户覆盖的天然优势前提下,有望迅速反哺。
算力短缺让模型的使用捉襟见肘。在DeepSeek-R1发布后,用户访问量短时间内激增,导致服务器压力过大。DeepSeek在1月26日发布R1模型后连续多日出现了服务中断的情况,DeepSeek表示出自服务的不稳定性源自多重复杂因素:突发流量激增、系统升级适配中的问题以及底层基础设施的临时性波动。
云厂商有望通过提供MaaS服务(模型即服务)受益于AI应用爆发中推理需求的崛起。对于很多不具备专业数据科学团队、缺乏模型开发能力以及算力部署和管理能力的AI应用企业,云厂可通过MaaS服务——将人工智能模型、机器学习模型等以服务的形式通过互联网提供给用户,用户无需自行搭建复杂的模型开发和训练环境,只需通过API接口或其他指定方式调用模型,就能获得模型的预测、分析等能力,实现特定的业务功能。用户可以确保基础模型的稳定运行、又能在需求变化时弹性扩展算力。
云厂纷纷上线DeepSeek模型。目前,华为云、天翼云、腾讯云、阿里云、百度智能云、火山引擎、京东云、联通云、移动云、浪潮云、中国电子云(深桑达控股公司)等中国头部云厂均已上架DeepSeek。而无问芯穹、硅基流动、优刻得、首都在线、PPIO派欧云、云轴科技、青云科技、并行科技等独立云厂商均已宣布适配及上架DeepSeek模型服务。

DeepSeek带来的模型平权有益于第三方中立云厂的持续发展。DeepSeek带来的模型平权有望打破原有产业价值链分配,打破模型优势给大模型厂商和互联网厂商带来的壁垒。另外,相比于头部云厂,第三方云厂在赋能下游客户模型微调等方面更有优势,且具有中立性的优势。
过年期间,优刻得云平台上线DeepSeek-R1系列模型,并发布了部署及使用攻略。优刻得科技股份有限公司在云计算领域实力强劲,技术研发成果显著。公司持续投入资源,自主研发出IaaS、PaaS、大数据流通平台、AI服务平台等一系列云计算产品,能高度适配不同行业的多样化需求。公司构建了涵盖公有云、混合云、私有云、专有云在内的综合性行业解决方案,业务广泛渗透到互联网、政府、运营商、工业互联网、教育、医疗、零售、金融等多个行业,精准满足不同客户的个性化需求,积累了大量优质客户资源和良好口碑。
2月6日,首都在线云平台上线DeepSeek-R1系列模型,还提供为期1个月的免费使用权限。早在23年初,公司就部署了大量的推理算力。公司基于英伟达GPU、国产卡等适配DeepSeek模型,并打造异构算力池。另外,公司有望在AI出海中受益。DeepSeek在全球火爆,有望在全世界广泛使用。而首都在线全球布局云服务,业务遍布五十多个国家和地区,且具有服务海外客户的核心经验。
2、Deepseek降本利好应用端侧爆发
端侧AI:Deepseek推动端侧推理成本压缩,眼镜+耳机+学习机+玩具四面开花
Deepseek对推理算力的压缩能够降低端侧AI成本。近日,英特尔公布,Deepseek目前能够在英特尔产品上运行,也可以在AIPC上实现离线使用。在其最新发布的酷睿Ultra200H(ArrowLakeH)平台上,Deepseek-R1-1.5B模型能够顺利运行,在因式分解演示中,能够迅速演绎逻辑思维,并最终解决数学难题,突破难关。小米、比亚迪等企业迅速接入API,特斯拉中国区客服宣布测试Deepseek语音助手,称其“中文理解能力优于现有系统”。OPPO、荣耀宣布年内推出搭载Deepseek轻量版模型的智能眼镜,可实现实时同声传译和AR导航。
AI眼镜:有望成为最能承载AI应用的新硬件产品,参与玩家众多,深耕手机算法的计算机厂商有望受益。目前该赛道的玩家包括AR眼镜厂商、互联网大厂、手机厂商、AI创业公司等,在2025CES中参展的AI及AR眼镜数量达到47个,提供的主要功能包括拍摄、AR显示、语音交互、翻译等,竞争较为激烈。根据Wellsenn预测,2025年全球AI智能眼镜将进入新品密集发布期,出货量有望达400万副,到2030年出货量有望增长至8000万副。AI眼镜在软件技术方面与智能手机有较多相似之处,在手机领域布局较深的产业链公司有望收益:比如雷鸟V3使用虹软科技的AI视觉算法猎鹰影像系统;闪极AI拍拍镜由云天励飞提供万物识别功能、由科大讯飞提供复杂环境语音识别、多语言翻译等核心技术。
AI耳机:主要提供办公效率辅助功能,多款产品接入第三方大模型。目前AI耳机赛道中的玩家包括:传统手机厂商如华为、小米、三星等,AI耳机通常与手机绑定,可以用于唤醒手机端智能体;传统耳机制造商,如飞利浦、纽曼等,使用腾讯、百度等第三方大模型,可唤醒对应的手机APP;互联网及AI厂商,科大讯飞相关团队自2011年起专注AI+耳机领域,最新推出的Pro2提供三种录音转写、viaimai助理、多语种翻译等功能,产品定位商务人群价格较高。各家AI耳机均定位为生产力工具,提供同传翻译、语音转文字等功能,功能较为局限,若后续能够拓展至生活娱乐场景、AI语音交互等功能延伸至耳机端侧、或与其他硬件融合,则相关产品销量有望大幅提升。
AI学习机:学习平板销量稳步增长,融合AI功能的高端学习机占比提升明显。根据洛图科技数据,2024年,中国学习平板市场全渠道销量为592.3万台,同比2023年增长25.5%,受到学生寒暑假影响,6月、12月销量较高;全年销售额为190.6亿元,同比2023年增长37.6%。学习平板线上市场的零售量达393.7万台,在全渠道中的占比为66.5%;学而思、作业帮、科大讯飞为线上销售额top3,市场份额分别为28%、25%、13%。从价格区间来看,价格在6,000元以上的高端学习机多搭载更优质的教学资源和AI功能,24年其线上市场份额达12%,较23年增加5.4pct,在这一细分市场中,学而思和科大讯飞的贡献较大,分别位列线上市场的销量和销售额首位。
AI玩具:目前发布的产品核心功能基本一致,包括语音识别、自然语言处理和机器学习,希望通过拟人、拟动物,以及拟IP的方式,与用户进行视/听/触多维度交互。受到功能和IP溢价影响,AI玩具的价格差异较大。相较于AI眼镜、AI学习机、智能音箱等产品,AI玩具依托玩偶、宠物和知名IP为载体,能够提供更多陪伴和情感支持,该领域更容易出现爆款产品,比如官方售价449元的AIGC玩具挂件BubblePal,开售首月GMV突破400万。
六、相关公司
1、国产算力及算力服务企业
长期看,DeepSeek方法带来的应是算力层面的杰文斯悖论(当技术进步提高了使用资源的效率,但成本降低导致需求增加,令资源消耗的速度是上升而非减少),整体AI应用生态繁荣应带来推理算力的更大需求。
(1)润建股份:DeepSeek催生行业红利,阿里云有望开启公司全新机遇
部署DeepSeek赋能智能体应用开发。润建股份曲尺平台升级部署DeepSeek-R1(满血版,671B)及基于其蒸馏的DeepSeek-R1-Distill-Qwen-32模型,赋能公司内部数智化转型,助力AI应用业务发展。公司自2024年8月起,在自有五象云谷智算中心私有化部署了DeepSeek-V2-Lite,用于公司内外部业务的AI智能体应用开发。目前在曲尺部署的DeepSeek开源模型有DeepSeek-R1-Distill-Qwen-32、DeepSeek-R1、DeepSeek-V2-Lite以及DeepSeek-V3。同时,基于DeepSeek模型,润建股份开发了多个智能体应用,包括内部知识库“润小知”、政务和电网营业厅的“数字导办”、马来西亚教育司阅卷机器人等。
除近期完成升级部署DeepSeek外,公司此前在AI(算力和应用)持续布局,取得较多成效。
算力业务前瞻布局,五象云谷AIDC迎高速发展机遇。公司前瞻布局算力业务,利用自身五象云谷数据中心,进行算力业务拓展。五象云谷是面向国内及东盟国家客户提供数据服务、算力服务的高等级数据中心。三期规划建设20000个机柜,一期已投资建成6000个机柜规模。在算力业务拓展方面,公司目前已有较好客户资源,阿里云、百度等需求有望成为公司算力重要支柱与增量。
2023年,五象云谷与阿里云签署了《合作协议》,拟就“中国-东盟智算云”项目及“数字经济创新中心”项目开展合作,为客户提供算力服务与数字化云。
与百度智能云紧密合作,正式部署百度大模型到五象云谷智算中心。
与华为签署合作,加强与华为在新能源、算力、人工智能、数字化等领域的合作,双方还计划在智算中心、AI大模型、大模型应用与云资源平台等领域拓展合作,并在润建股份五象云谷启动搭建基础云服务平台与昇腾算力中心测试环境。
算力运维领域也实现中标,24年成功中标全球运营商最大单体智算中心——内蒙古某单位智算中心运维项目,为智算中心提供全方位智能运维服务。
B端应用持续布局,迎接应用开花时代。公司自2023年发布自研“曲尺”人工智能开放平台以来,已在多个行业场景成功实现应用落地。润建人工智能展厅将Bytepiping开发者作业平台、数据标注、AI模型生产线等复杂技术的演绎化繁为简,让体验更加直观。同时,大家还可感受结合AIAgent能力的全新数字人交互体验。在应用布局体现在:
进入2024年,CV大模型已成功部署在五象云谷智算中心,在CV大模型及AI智能助手等人工智能技术的赋能下,润建股份全面升级了数智城管系列产品,借助“人工智能+城市治理”创新模式,推动城市管理与服务更加精细化。
润建股份在南宁中关村成立了数据标注基地,同时与国内多所高校合作,组建数据标注团队,专注于为行业内AI应用提供精准、丰富的标注数据,可支撑内外部在做大数据交易规模、增强数据流通效率、发挥数据要素乘数作用等探索服务,不断挖掘激活数据要素价值,加快培育发展更多新质生产力。
低空经济领域布局。润建股份作为全品类无人飞行平台与低空经济AI+行业应用专家,为天津宝坻区打造农村人居环境长效管理平台,该平台通过AI视觉识别大模型、无人机等现代技术,基于AI非现场执法系统,创新实现将乡村低空基础设施纳入公共基础设施体系。
部署DeepSeek-R1,DeepSeek-R1的逻辑推理能力显著减少了提示词设计和部分工作流设计的复杂性,使得开发智能体的效率提升了15%左右。随着DeepSeek-R1的部署上线,润建股份曲尺私有化部署以及微调过的模型已经超过15+,大大丰富了在大模型应用开发的选择。
(2)中科曙光:业绩稳健增长,计算产业生态持续完善
公司发布2024年第三季度报告,2024年前三季度公司实现营业收入80.41亿元,同比增长3.65%,实现归母净利润7.70亿元,同比增长2.57%,实现扣非归母净利润4.45亿元,同比增长8.66%。第三季度公司实现营收23.29亿元,同比下滑1.19%,实现归母净利润2.06亿元,同比增长0.41%,实现扣非归母净利润0.79亿元,同比下滑24.55%。
主营业务表现相对稳定,公司逐步向服务器上游领域转型。公司第三季度收入小幅下滑,扣非归母净利润相对承压,主要因公司向服务器上游领域转型,重点发力服务器解决方案,聚焦高价值业务。未来随着公司业务结构优化,生态及产业竞争力提升,盈利能力有望逐步回升。
保持高强度研发投入,打造全栈自主可控计算生态。2024年前三季度公司销售/管理/研发费用率分别为6.45%/3.03%/12.22%,同比变动+0.56/+0.49/+1.15pcts,保持高研发投入力度,发力高性能计算机、高性能存储、浸没液冷等方向,核心部件自研能力及比例持续提升,联合上下游企业共同打造全栈自主可控计算生态,助力国产算力产业发展。
参控股公司业绩表现优异,为公司增长提供助力。公司重点参控股公司海光信息、中科星图、曙光数创业绩持续高增,根据上述公司2024年三季度报告,海光信息、中科星图、曙光数创24Q3净利润分别为8.81亿元(同比+171%)、1.23亿元(同比+21%)、0.01亿元(同比+105%),为公司业绩增长提供保障。展望未来,公司与上述参控股公司在通用&AI芯片、地理信息产业、低空经济、商业航天等领域将进一步加大合作,具备广阔发展前景,有望持续为公司增长赋能。
(3)海光信息:DCU持续投入巩固国产算力份额,大模型生态适配优化加快应用落地
通用计算国内领先,DCU产品快速迭代发展。2024年,公司的CPU产品进一步拓展市场应用领域、扩大市场份额,支持了广泛的数据中心、云计算、高端计算等复杂应用场景;在AIGC的时代背景下,公司DCU产品快速迭代发展,得到市场更广泛认可,以高算力、高并行处理能力、良好的软件生态支持了算力基础设施、商业计算等AI行业应用,进一步促进了公司业绩的较快增长,预计实现营业收入872,000.00万元到953,000.00万元,同比增长45.04%-58.52%。公司始终围绕通用计算市场,通过高强度研发投入,不断实现技术创新、产品性能提升,保持了国内领先的市场地位。
深算系列进展顺利,持续加大DCU投入。公司的深算系列产品进展顺利,且公司持续加大在DCU软件方面投入。公司DCU产品打造了自主开放的完整软件栈,包括“DTK(DCU Toolkit)”、开发工具链、模型仓库等,其完全兼容“CUDA”、“ROCm”生态,支持TensorFlow、Pytorch和PaddlePaddle等主流深度学习框架与主流应用软件。依托开放式生态,公司构建了拥有完善的层次化软件栈的统一底层硬件驱动平台,其能够适配不同API接口和编译器,并支持常见的函数库、AI算法与框架等。
DeepSeekV3和R1模型完成海光DCU适配并正式上线。DeepSeekV3和R1模型基于Transformer架构,采用了Multi-Head Latent Attention(MLA)和DeepSeekMoE两大核心技术。MLA通过减少KV缓存显著降低了内存占用,提升了推理效率;DeepSeekMoE则通过辅助损失(auxiliary loss)实现了专家负载的智能平衡,进一步优化了模型性能。此外,DeepSeek还引入了多令牌预测、FP8混合精度训练等创新技术,显著提升了模型的训练效率和推理性能。
DeepSeek R1还引入了强化学习技术,进一步增强了模型的思考能力和决策效率,使其在复杂任务处理中表现出色,尤其适用于需要高智能决策的场景。近日,海光信息技术团队成功完成DeepSeekV3和R1模型与海光DCU的国产化适配,并正式上线。海光DCU技术团队还将持续推动大模型迭代适配与优化更新,凭借卓越的算力性能和完备的软件生态,海光DCU已在科教、金融、医疗、政务、智算中心等多个领域实现规模化应用。
2、AI应用类企业
DeepSeek开源模式有望快速提升其他大模型综合实力,大模型能力普遍提升利好AI应用开发。
(1)金山办公:智能化、国产化、云化三浪叠加
信创深化落地,国产操作系统带动WPS份额提升。2023年以来,信创进入深化落地阶段,党政、8大重点行业信创进一步深化,制造业等其他行业也陆续开始信创,万亿国债以及地方化债有望为信创带来支持。微软Office凭借在Windows系统预装优势占据市场份额,当前WPS产品足以替换Office,随着国产操作系统市场份额的增加,WPS份额有望持续扩大。
机构业务蓬勃发展。2023年公司推出WPS365,通过SaaS服务为企业同时提供文档、AI、协作服务,满足一个组织的办公需求。WPS365可满足对企业数据安全的保护以及协同办公这两大区别于个人端的场景。针对党政客户,公司发力公文领域,提供黑马智能校对、公文排版功能。近年来,公司机构客户SaaS化趋势明显,机构订阅占收入比从2021年的13.6%增长至2023年的21.0%。未来,大模型深入企业已成趋势,由于大模型具有较高的私有化部署成本,因此预计将有更多机构客户上云。
AI持续升级,带来全新体验。目前,WPSAI已升级至2.0,面向个人、企业、党政客户均有相应版本。针对企业客户,WPSAI可利用其内部文档构建私域知识库,从而更好地利用企业数据资产,这种B端AI思路得到了企业客户的认可。此外,WPS灵犀Beta版本上线,除了常规大模型功能外,可直接阅读WPS云文档中的内容而无需用户再次上传,带来便捷体验。

(2)彩讯股份:从信创到AI应用,Rich AI超级工厂打开成长空间
三大产品线呈向好态势,发布股权激励彰显未来发展信心。公司三大产品线情况:协同办公产品线:公司的邮箱产品是中国500强的首选邮箱,围绕着邮箱、统一办公平台,今年将结合AI及元宇宙朝着“数字员工”方向继续推进。智慧渠道产品线:主要是服务企业数据化运营和管理,通过彩讯AIBox一站式AI应用平台,助力企业客户实现个性化、智能化的应用场景;此外,公司过去为客户完成了多个亿级用户规模的软件开发,后续也将根据客户需求推进软件鸿蒙版本的开发。同时,公司未来也将结合AIBox相关技术让产品更加智能化。云和大数据产品线:公司是移动云的核心供应商,未来将结合传统云的优势,朝智算中心的方向进行深度延伸。公司发布了《2024年限制性股票激励计划(草案)》,已完成授予,其中公司层面业绩考核指标之一为2024-2026年每年剔除有效期内正在实施的所有股权激励计划和员工持股计划所涉股份支付费用后扣非净利润同比增长达到16%及以上,彰显未来发展信心。
深度布局人工智能开发Rich AI超级工厂,围绕AI+元宇宙构造全景生态。在AI的浪潮下,彩讯股份开发了Rich AI超级工厂,Rich Al超级工厂是公司围绕AI+元宇宙构造的全景生态,由下至上大致分为三层,从下往上的第一层是智算基础设施底座Rich AICloud,AICloud的底层是下一代AI原生云计算架构RichNet,中间层是可实现万卡集群管理的RichMoss超大规模算力集群管理平台,顶层是针对大语言模型/文生图/视频的RichBoost高性能大模型训推平台;第二层为Rich AIBox,它的定位非常清晰,旨在帮助大中型国有企业以及所有B端客户快速定制化开发AI应用,公司的AI邮箱和AI云盘均通过AIBox进行产品开发升级,彩讯AIBox一站式AI应用开发平台在行业内被广泛认可,同类平台还有文心智能体平台、字节扣子、Dify等平台;第三层是AI应用层,包含toB和toC的AI应用以及相关行业解决方案能力。目前彩讯AI应用有:AI智能邮箱、数字人、AIGC新通话、彩灵图歌乐。
发布图生音乐AI应用彩灵图歌乐,未来应用场景可观。彩灵图歌乐是彩讯股份基于新一代多模态大模型技术,构建的AI音乐生成产品,它将AI算法、音乐制作与数据分析完美融合,为用户带来前所未有的音乐创作体验。公司综合技术可实现性、算力成本、可玩性等方面发现图生音乐当前仍然是一个较为空白的点,经过半年的不断迭代尝试和用户测试,公司重点研发了图生音乐的场景,极大降低音乐制作的门槛,这是一个充满潜力的场景。在公司尚未全面推广的情况下,彩灵图歌乐产品用户量级已达到了几十万级别,用户体验较好。
(3)同花顺:乘资本市场东风,启AI赋能新篇
深耕金融信息服务行业近三十年,收入增长与资本市场活跃度紧密相关。公司是国内领先的互联网金融信息服务提供商以及头部网上证券交易系统供应商之一,始终保持技术与应用的创新,推出爱基金网、iFind金融数据终端、i问财、AI投资机器人、AI开放平台、智能投顾、智能客服等产品及功能,2024年初发布业内首个金融对话大模型问财HithinkGPT。公司收入增长与国内资本市场活跃程度密切相关,比如在2015年、2020年牛市环境下公司收入增长表现强劲,同比增速分别达到443%、63%。在2024年四季度资本市场交易活跃度明显提升(单季沪深两市股基成交额同比增长123%)的背景下,投资者对金融信息服务需求的高涨预计带动公司收入增长取得良好表现。
以庞大C端用户与渠道网络为基,四大主营业务发展前景广阔。增值电信:为公司收入端支柱,2019至2023年收入占营收比重平均达到46%。在同类产品中,公司产品拥有行业领先的用户活跃度与流量优势,同花顺App长期位列证券应用类App活跃度排名第一的位置。公司已经拥有庞大的C端用户基础,截至2024上半年,同花顺金融服务网累计注册用户约6.25亿人。广告推广:基于领先的C端用户规模与合作券商数量,公司广告推广类收入规模遥遥领先于可比同业。公司在广告导流领域具备较强的竞争优势,也将充分受益于市场行情的提振。基金销售:同花顺基金保有规模位于独立销售机构前列,公司将受益于ETF加速扩张带来的市场扩容,基金销售业务空间有望进一步打开。软件销售:面向B端,收入规模主要取决于证券公司对网上交易系统的扩容需求,在交易活跃的年份,可以看到公司该项收入增速相对更高,该业务或将受益于市场交易活跃度提升与证券行业IT投入力度的加大。
坚持技术驱动提质增效,前瞻布局AI大模型及应用。大模型方面,公司推出金融垂类基座大模型HithinkGPT,实现对话交互与多模态融合。2019年公司提出“ALL in AI”战略,2024年1月,同花顺发布金融对话大模型——问财HithinkGPT,能够高分通过多个金融领域的专业考试。公司旗下投顾对话机器人同花顺问财基于HithinkGPT升级,成为国内金融领域首个应用大模型技术的智能投顾产品。视频算法方面,同花顺的图像团队研发了一整套语音驱动人脸算法,推出2.5D虚拟人模型,支持原声、合成声、中英文语音驱动,口唇同步率达到99%以上,目前已落地多家券商保险行业公司,用于金融营销领域。基于公司丰富的行业经验与领先的大模型能力,当前,公司已在大模型+金融投顾、大模型+智能客服、大模型+智能投研、大模型+代码生成、大模型+法律咨询、大模型+办公助手、大模型+翻译、大模型+医疗等多个领域推出了产品。针对金融垂类领域,公司的AI应用百花齐放,相关人士认为问财对话机器人、同花顺AIPC版、智能编码助手Hi Pilot、金融垂类Agent平台同创智能体平台等AI产品未来值得重点关注。
七、发展展望
1、DeepSeek推动AI平权时代降临,加速应用端Android时刻到来
DeepSeek开源R1推理模型对标OpenAI o1,同时展示官方集成案例鼓励AI应用开发,实现AI平权、鼓励AI应用开发。2025年1月,DeepSeek发布R1推理模型,在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版;DeepSeek通过DeepSeek-R1的输出,蒸馏了6个小模型开源给社区,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。此外,官方还开放了大量实用集成案例,推动AI应用发展。
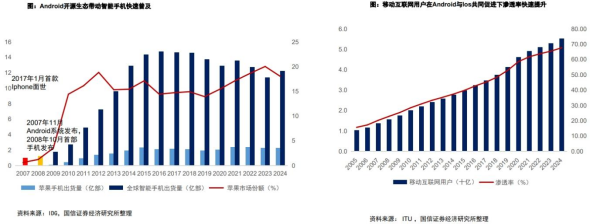
参考智能手机产业发展历程,苹果推出划时代的ios以及苹果手机之后,Google推出开源智能手机操作系统Android,成为当前市场市占率最高的操作系统、也推动了智能手机产业的快速发展;智能手机普及之下,移动互联网用户数及渗透率快速提升,移动互联网应用产业迎来爆发。
高效低成本且开源的DeepSeek为代表的开源大模型生态有望成为AI时代的Android,加速端侧硬件及应用生态成熟。
2、DeepSeek推动AI生态繁荣
(1)DeepSeek进一步驱动高质量模型平价化
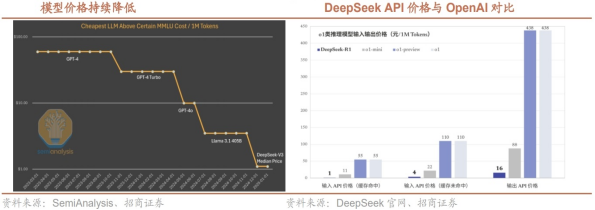
算法的改进和优化带来模型能力提高的同时成本降低,持续提升模型性价比。根据Semi Analysis估计,算法的进步速度为每年4倍,这意味着每过一年,实现相同功能所需的计算量就会减少4倍。Anthrop ic首席执行官Dario认为,算法的进步速度更快,可以带来10倍的改进。在近一年已看到算法的改进和优化使成本降低了10倍,而模型能力则有进一步提升。
DeepSeek进一步驱动高质量模型平价化。DeepSeek-R1API服务定价为每百万输入tokens1元(缓存命中)/4元(缓存未命中),每百万输出tokens16元。对比最新发布的OpenAIo3-mini,o3-miniAPI服务定价为每百万输入tokens1.1美元(约8元人民币),每百万输出tokens4.4美元(约31元人民币),仍约为R1的8倍。
(2)DeepSeek直接拉高模型能力下限,将驱动AI应用进展
DeepSeek迅速集成进各云厂商的平台中,直接拉高模型能力下限,AI应用开发提速升级。
2月1日,华为云宣布上线基于华为云昇腾云服务的DeepSeekR1/V3推理服务,华为昇腾云服务支持部署的DeepSeek模型可获得持平全球高端GPU部署模型的效果,且让模型能够在大规模生产环境中稳定运行,并满足业务商用部署需求。
2月2日,腾讯云宣布在高性能应用服务HAI上支持一键部署Deepseek-R1模型,开发者可以在三分钟内完成模型的启动和配置,无需手动处理复杂的安装和调优过程,同时,开发者还能将DeepSeek-R1与其他腾讯云CloudStudio、对象存储等服务无缝集成,高效率构建基于DeepSeekR1的完整AI应用。
2月3日,百度智能云宣布DeepSeek-R1和DeepSeek-V3模型已在百度智能云千帆平台上架,同步推出超低价格方案,并提供限时2周的免费服务。阿里云PAIModelGallery支持云上一键部署DeepSeek-V3、DeepSeek-R1。
此外,国外平台也在加速接入DeepSeek-R1。目前,包括英伟达、微软、亚马逊、Cursor在内的多家美国公司陆续采用DeepSeek-R1模型。
(3)AI行业迭代速度加快
2025年1月31日OpenAI发布最新推理模型o3-mini,实现低成本、低延迟、高性价比,且针对STEM推理进行优化;2月3日进一步发布面向深度研究领域的智能体产品DeepResearch,旨在帮助用户进行深入、复杂的信息查询与分析。
OpenAIo3-mini已在ChatGPT和API中提供,这一模型保持了OpenAIo1-mini的低成本和低延迟,同时针对STEM推理进行优化,尤其擅长科学、数学和编码。根据OpenAI评估,o3-mini的中等推理努力与o1在数学、编码和科学方面的表现相当,同时响应速度更快。o3-mini还在中等推理工作量的额外数学和事实性评估中表现出色。在A/B测试中,o3-mini的响应速度比o1-mini快24%,平均响应时间为7.7秒,而o1-mini为10.16秒。目前o3-mini可供免费用户使用。
Deep Research是一个使用推理来综合大量在线信息并为用户完成多步骤研究任务的智能体,旨在帮助用户进行深入、复杂的信息查询与分析。Dee pResearch能够针对复杂任务在互联网上开展多步骤调研,并在几十分钟内完成人类需耗费数小时才能完成的工作,该功能专为金融、科学、政策、工程等领域的高强度知识工作者设计。
2025年1月22日,字节跳动正式发布了豆包大模型1.5Pro版本。豆包大模型1.5Pro不仅增强了对知识、代码和推理的处理能力,同时也优化了中文交互,在处理复杂任务时的表现较以往版本更加出色,尤其是在自然语言理解和生成能力上,用户将享受到更流畅和自然的对话体验。此外,豆包实时语音模型Doubao-1.5-realtime-voice-pro辅以创新的Speech 2 Speech端到端框架,具备了丰富的语音表现力,能够根据语境流畅地表达快乐、悲伤等情绪,更能使用方言,甚至具备唱歌的能力,这在业界尚属首次。

3、美国持续加码AI出口管制,中国AI模型芯片瓶颈亟待突破
(1)美国持续加码AI出口管制,多国限制DeepSeek使用
美国封锁16nm以下先进制程,并将中国、新加坡的多个实体列入实体清单。2025年1月16日,BIS发布两条规则,一项是更新先进计算半导体的出口管制,增加对芯片工厂和封装公司的出口管控,涵盖14纳米或16纳米及以下节点的芯片,美国还将加强代工调查并防止先进芯片流向中国。另一项是将25家中国公司和2家新加坡公司列入实体名单。
DeepSeek反映出中美在AI领域的差距在缩小,再次引发地缘政治角度的热议。美国AnthropicCEO达里奧·阿莫迪呼吁美国政府继续维持芯片管制,将H20芯片也纳入限制范围。据彭博社报道,OpenA!和微软针对DeepSeek2024年使用OpenAIAPI接口的账>进行审查,并以涉嫌违反服务条款的模型蒸馏为由取消访问权限。爱尔兰、意大利等国针对DeepSeek的数据安全问题提起质询DeepSeekApp已在意大利国内的应用市场全面下架。

(2)中国AI模型积极进行工程创新,芯片瓶颈亟待突破
中国AI企业依靠工程创新持续进步,先进算力仍需突破。伴随美国BIS会进一步加码对芯片、模型的管制,争取美国AI产业的发展时间,中美科技领域差距仍可能拉大。因此,突破先进制程梏,实现半导体自主可控将是中国AI产业发展关键。
台积电持续加大资本开支,先进制程产能储备全球领先,中国大陆仍存在代差。2025年台积电资本开支预计将提升至380-420亿美金。约70%将投资于先进制程技术,包括3纳米及2纳米。7nm月产能预计在15-20万片/月,5nm月产能预计超20万片/月,3nm扩产积极预计24年底月产能在12.5万片/月,2nm预计在25年下半年量产,预计月产能达5-6万片,并在26年实现产能翻倍。中国大陆7nm及以下先进制程产能与台积电等代工厂依然有数量级差距,对应晶体管数量约有几十倍的差距,先进制程供应能力亟待提升。
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)
⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 22
22 0
0- 0



 已为社区贡献96条内容
已为社区贡献96条内容

所有评论(0)