ktransformers 单机单卡4090部署与推理测试
总体来讲,单卡服务器可用性大大扩展,受测试机内存限制,没法尝试更大参数的deepseek模型,待使用其他服务器另行测试,期待ktransformers后续版本增加并发和更多模型支持。
前言
近期deepseek爆火,大家都想用小资源干大事,正好结合ktransformers框架,拿手头的单卡4090配合内存搞搞之前不敢高攀的更大参数模型。
项目地址
https://github.com/kvcache-ai/ktransformers
https://kvcache-ai.github.io/ktransformers/en/install.html
服务器信息
显卡 4090 24g * 1
cpu i7 12700 12 核 20 线程 * 1
内存 64g
安装
conda
conda create --name env_ktransformers python=3.11
conda activate env_ktransformers
pip install torch packaging ninja cpufeature numpy -i https://mirrors.huaweicloud.com/repository/pypi/simple
pip install flash_attn -i https://mirrors.huaweicloud.com/repository/pypi/simple (编译不通过则下载whl文件安装)
ktransformers
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
bash install.sh
测试
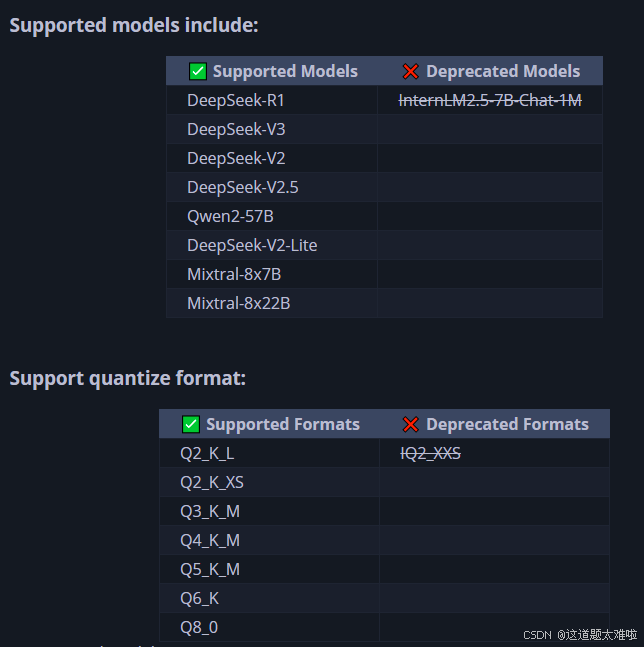
目前支持的模型和格式
本次测试使用模型:Qwen2-57B-A14B-Instruct-Q4K-M
交互命令行
python -m ktransformers.local_chat --model_path /xxxx/Qwen2-57B-A14B-Instruct --gguf_path /xxxx/Qwen2-57B-A14B-Instruct-GGUF-Q4K-M
注意先下载Qwen2-57B-A14B-Instruct模型相关文件(不需要权重文件)
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/Qwen/Qwen2-57B-A14B-Instruct
否则可能遇到
“OSError: We couldn't connect to 'https://huggingface.co' to load this file”, try:。。。
![]()
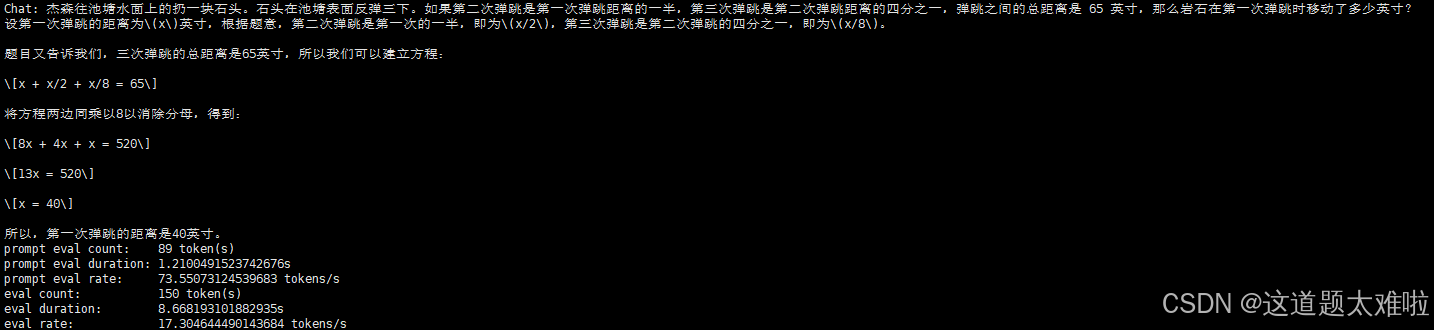
推理速度:约17 tps 左右
推理资源使用:
显存5.5g、推理gpu使用率20%左右,内存35g、推理cpu使用率约10逻辑核心(总体50%)
API接口
ktransformers --model_path /xxxx/Qwen2-57B-A14B-Instruct --gguf_path /xxxx/Qwen2-57B-A14B-Instruct-GGUF-Q4K-M --port 10240
推理速度、资源使用情况与命令行基本一致
cpu配置
--cpu_infer 可设置使用cpu核数 默认10
对于单例服务 本机测试
10核推理速度大概17tps
18核(官方推荐最大核数-2)反而降到5-11tps不等
15核为15tps
5核为13tps
似乎并不是使用核数越多越好,猜测应该是每个与offload到cpu的任务数以及调度策略相关,使用时酌情调整。
并发
api接口服务方式启动,目前ktransformers不支持并发,实测默认情况下一个服务同时只支持一个请求调用处理。
通过启动多个server实例,可实现多请求负载,其中显存占用加倍,内存的buffer/cache占用仅一份。
实测本机64g内存可支撑超过2个server实例。
2实例并行执行测试结果
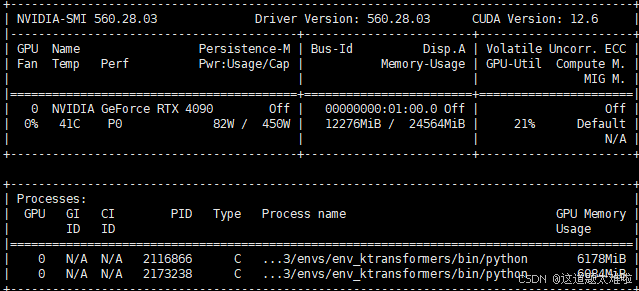

推理速度:每个server 6 tps 左右
推理资源使用
显存12g、推理gpu使用率20%左右(与单实例持平),内存35g、推理cpu使用率约20逻辑核心(总体100%,2实例均分)
3实例并行执行测试结果
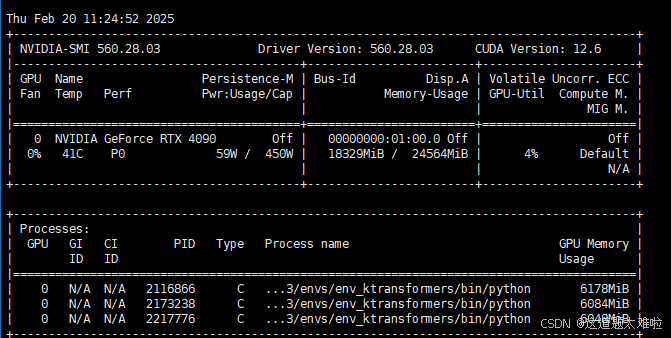
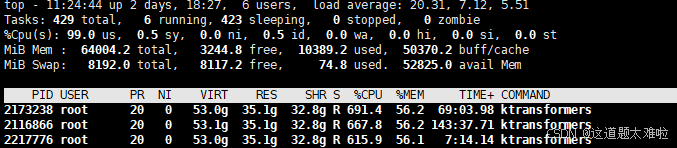
推理速度:每个server 0.7 tps 左右
推理资源使用
显存18g、推理gpu使用率不足5%,内存35g、推理cpu使用率约20逻辑核心(总体100%,3实例均分)
猜测多实例并发时cpu和内部带宽争用成为推理运算瓶颈,且整体降速非线性,2实例降速为原1/3,3实例降为原1/24
总结
总体来讲,单卡服务器可用性大大扩展,测试机的配置并发双服务实例基本是上限,超过2个推理速度惨不忍睹。
部署更大参数的deepseek模型需要更大内存,官方提供了对应模型和资源占用情况
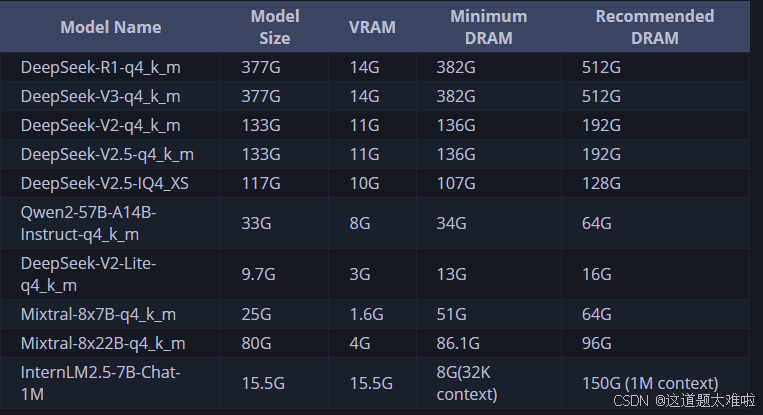
目前项目处于初期状态,期待ktransformers后续版本增加并发和更多模型支持。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)