了解DeepSeek,本地部署并使用DeepSeek
参数规模是衡量模型能力的重要指标之一,参数就像是模型的 “记忆细胞”,参数越多,模型能够学习和表示的知识就越丰富,理论上可以处理更复杂的任务,对各种语言现象和语义理解的能力也更强。在内容创作方面,7B 参数的模型可以根据用户提供的主题和要求,生成结构清晰、内容丰富的文章,无论是新闻报道、故事创作还是学术论文的撰写,都能提供有价值的参考。训练一个拥有大量参数的模型,如 7B 参数的模型,需要强大的计
一、DeepSeek的几个大版本
- DeepSeek-V1 :2024年1月发布,作为 DeepSeek 家族的首款产品,它的出现为后续版本的发展奠定了坚实的基础。
突出功能1:支持多种编程语言,如 Python、Java、C++ 等,能够满足软件开发人员在不同项目中的需求 。
突出功能2:拥有长上下文窗口,能够理解和处理较长的文本内容,这使得它在长文档处理方面表现出色。
局限1:然而,DeepSeek-V1也存在一些局限性,例如多模态能力有限,无法很好地处理图像、音频等非文本信息。
局限2:推理能力不足,在面对一些需要深度推理的问题时,表现不尽如人意。
- DeepSeek-V2 系列 :2024 年上半年发布的系列,采用创新架构,在性能上有了显著的提升。
突出功能1:在文本生成任务中,DeepSeek-V2 系列能够生成更加连贯、自然的文本,无论是撰写文章、故事还是对话,都能表现出较高的水平。
突出功能2:具备强大的代码生成能力,能够根据用户的需求生成高质量的代码,并且在代码的可读性和可维护性方面也有很好的表现。
突出功能3:该系列还具有成本低的优势,且开源商用,这使得更多的企业和开发者能够使用它来开发各种应用。
局限1:多模态能力有限的问题,在处理图像、音频等多模态数据时存在一定的困难。
局限2:推理速度也有待提升,在面对复杂的推理任务时,响应时间较长。
- DeepSeek-V2.5 系列 :2024 年 9 月发布的系列,在多个方面都有了明显的能力提升。
突出功能1:在数学、编码、写作和推理方面能力提升。
突出功能2:在教育辅导和代码调试等场景中,系列凭借其强大的能力,为用户提供了高效、准确的服务。
突出功能3:支持联网搜索功能,这使得它能够获取最新的信息,为用户提供更全面、准确的回答。
局限1:API 不支持联网搜索功能,多模态能力仍有限。
- DeepSeek-V3 系列 :2024 年 12 月 26 日发布的系列,平均表现超过了大部分同类开源和闭源模型。
突出功能1:在知识问答、长文本处理、代码生成、数学能力等方面实力强大,生成速度快。
突出功能2:开源且支持本地部署。
- DeepSeek-R1 系列 :2025 年 1 月 20 日发布的系列,以强大推理能力著称。
突出功能1:在解决复杂数学问题、代码逻辑推理等任务时表现出色。
突出功能2:开源生态完善,为开发者提供了丰富的资源和工具,促进了 AI 技术的发展和应用。
突出功能3:该系列根据推理模型大小分为1.5B、7B、8B、14B、32B、70B、671B等版本,数字越大推理能力越强。
局限1:多模态任务支持方面有限。
- *DeepSeek-R1蒸馏版:是R1的轻量版,通过知识蒸馏技术压缩了参数规模,降低了计算资源需求,但保留了核心功能。
- DeepSeek-R3:网文创作版,专为网文创作优化,集成在阅文集团的“作家助手”应用中,提供智能问答、灵感获取和文本润色功能。*
目前 DeepSeek-R1系列在科研、技术开发和教育等领域,得到了广泛的应用,为相关工作的开展提供了有力的支持,例如在生成逻辑严谨的技术文档或学术论文、提升智能客服复杂任务解决效率以及帮助内容创作者生成高质量技术文章等方面,都发挥了重要作用。
二、1.5B、7B 等分类的奥秘
(一)参数规模决定能力
在 DeepSeek 的版本体系中,我们常常看到 1.5B、7B 这样的标识,这里的 B 代表十亿(Billion),1.5B 即 15 亿参数,7B 则表示 70 亿参数 ,这些数字代表的是模型的参数规模。参数规模是衡量模型能力的重要指标之一,参数就像是模型的 “记忆细胞”,参数越多,模型能够学习和表示的知识就越丰富,理论上可以处理更复杂的任务,对各种语言现象和语义理解的能力也更强。在回答复杂的逻辑推理问题、处理长文本上下文信息时,7B 的模型就可能会比 1.5B 的模型表现得更出色。这是因为更多的参数能够让模型捕捉到更细微的语言模式和语义关系,从而做出更准确的判断和回答。
参数规模的增大也意味着需要更多的计算资源和更长的训练时间。训练一个拥有大量参数的模型,如 7B 参数的模型,需要强大的计算设备,如高性能的 GPU 集群,并且可能需要花费数周甚至数月的时间来完成训练。而 1.5B 参数的模型,由于其参数规模较小,训练所需的计算资源和时间相对较少,这使得它在一些资源有限的情况下更具可行性。
(二)适用场景各有不同
不同参数规模的 DeepSeek 模型,适用场景也各有不同。1.5B 参数的模型,由于其轻量级的特点,适合在资源有限的环境中运行,如个人电脑、移动设备等。它可以快速加载和运行,能够在较短时间内给出结果,满足用户对简单任务的即时需求,如基础问答、简单的文本摘要等。在手机端的智能助手应用中,1.5B 参数的模型可以快速响应用户的提问,提供简洁明了的回答,并且不会对手机的性能造成过大的负担。
7B 参数的模型则在性能和资源需求之间达到了一个较好的平衡,它具备更强的语言理解和生成能力,能够处理更复杂的任务,如内容创作、智能客服等。在内容创作方面,7B 参数的模型可以根据用户提供的主题和要求,生成结构清晰、内容丰富的文章,无论是新闻报道、故事创作还是学术论文的撰写,都能提供有价值的参考。在智能客服领域,7B 参数的模型能够理解用户的复杂问题,并给出准确、详细的回答,大大提高了客服的效率和质量。
(参考链接:https://blog.csdn.net/u012069313/article/details/145450698)
| 模型版本 | 模型定位 | 参数量 | 硬件需求 | 特点 | 使用场景 | 预计费用 |
|---|---|---|---|---|---|---|
| DeepSeek-R1-1.5B | 轻量级 | 15亿 | CPU:4核 ;内存:8G;GPU:非必需 | 运行速度快,性能有限 | 实时文本生成(聊天机器人、简单问答);嵌入式系统或物联网设备 | 2000~5000 |
| DeepSeek-R1-7B | 平衡型 | 70亿 | CPU:8核 ;内存:16G;GPU:8G+(如:RTX3060) | 性能较好,硬件需求适中 | 本地开发测试;中等复杂度任务(翻译、文本摘要);轻量级多轮对话系统 | 5000~10000 |
| DeepSeek-R1-8B | 平衡型 | 80亿 | CPU:8核 ;内存:16G;GPU:8G+(如:RTX4060) | 略强于7B模型 | 需要高精度的轻量级任务(如代码生成、逻辑推理) | 5000~10000 |
| DeepSeek-R1-14B | 平衡型 | 140亿 | CPU:12核 ;内存:32G;GPU:16G+(如:RTX4090) | 擅长复杂任务(数学推理、代码生成等) | 企业级复杂任务(合同分析、报告生成);长文本理解与生成(书籍/论文辅助写作) | 20000~30000 |
| DeepSeek-R1-32B | 高性能 | 320亿 | CPU:16核 ;内存:64G;GPU:24G+(如:A100 40G) | 性能强大,适合高精度任务 | 高精度专业领域任务(医疗/法律咨询);多模态任务预处理(需结合其他框架) | 40000~100000 |
| DeepSeek-R1-70B | 顶级 | 700亿 | CPU:32核 ;内存:128G;GPU:2-4卡(如:2xA100 80G/4xRTX4090) | 性能极强,适合大规模计算和高度复杂任务 | 科研机构/大型企业(金融预测、大规模数据分析);高度复杂生成任务(创意写作、算法设计) | 400000+ |
| DeepSeek-R1-671B | 超顶级 | 6710亿 | CPU:64核 ;内存:512G;GPU:8+卡(如:8x A100 / H100 >=80G) | 性能卓越,推理速度快,适合极高精度需求 | 国家级/超大规模AI研究所 | 20000000+ |
三、部署使用
1.下载并安装Ollama
访问官网:https://ollama.com 下载并安装
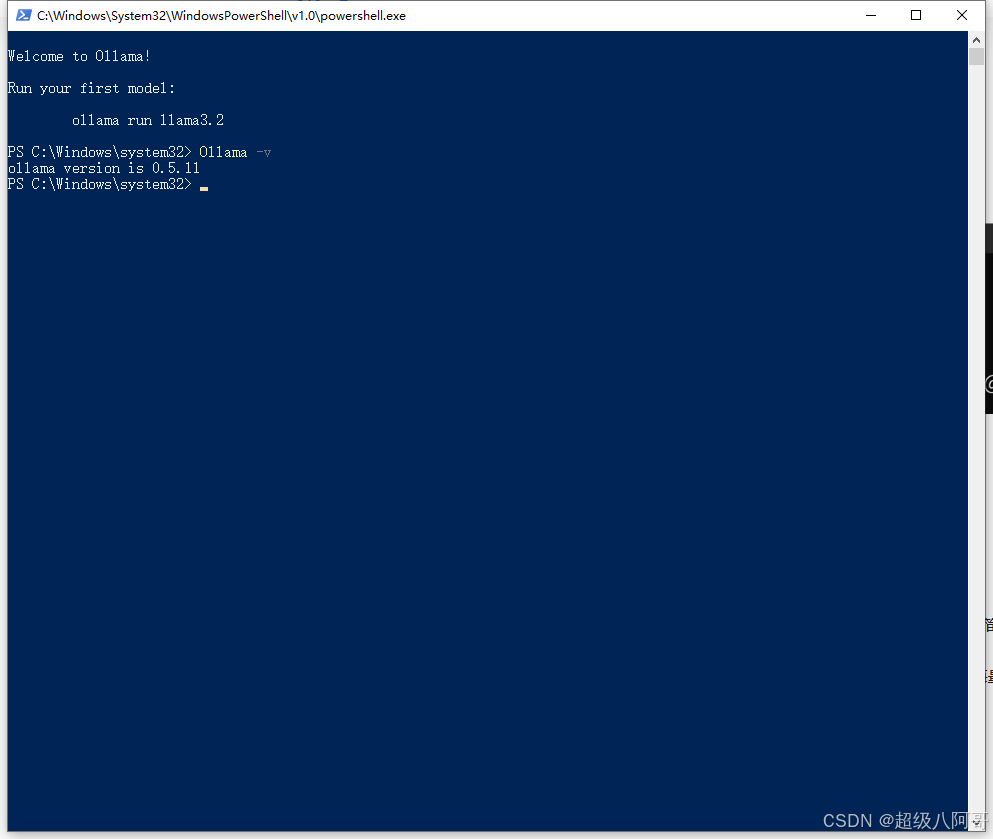
2.检验Ollama是否安装成功
命令行输入 ollama -v 命令,出现如下版本号说明安装成功
3.通过 Ollama命令拉取 DeepSeek 模型
本地部署测试,我选择1.5B的模型,模型大小1.1 GB。
1.5B:适用于轻量级任务,如边缘设备(如智能手表、物联网设备)上的简单交互、小型智能问答系统等。目前开源的最小版本。
命令行输入:ollama run deepseek-r1:1.5b 拉取DeepSeek模型
拉取成功
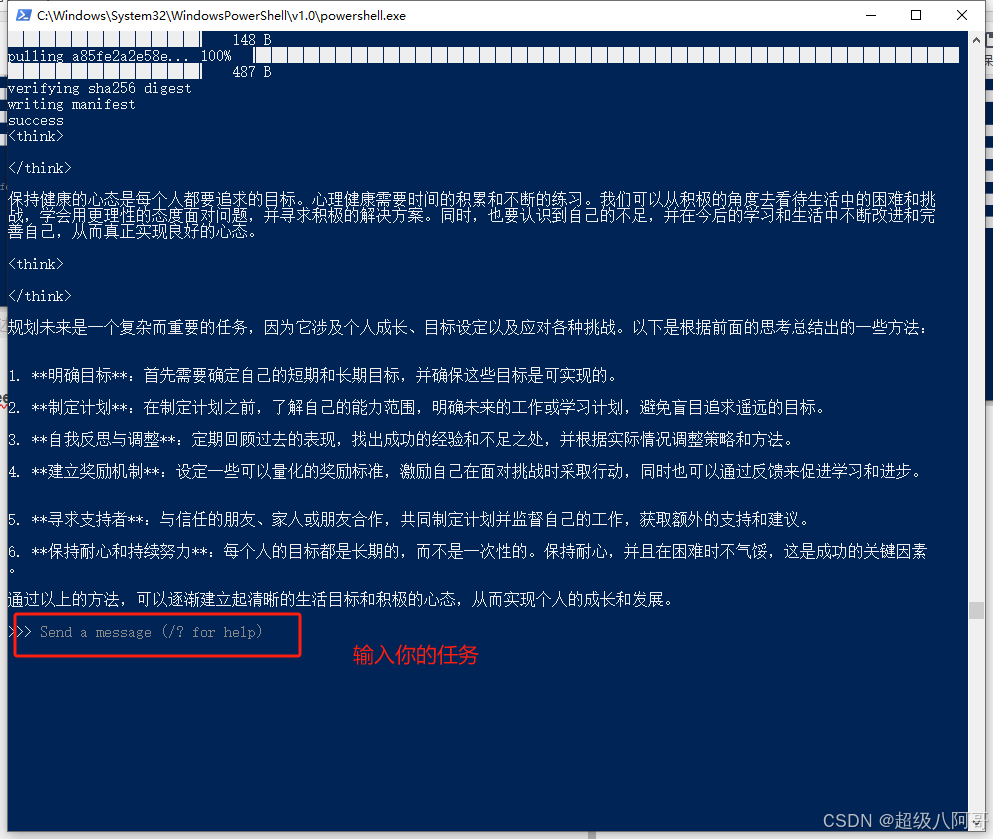
4.和deepseek对话
5.利用浏览器Page Assist插件与DeepSeek对话
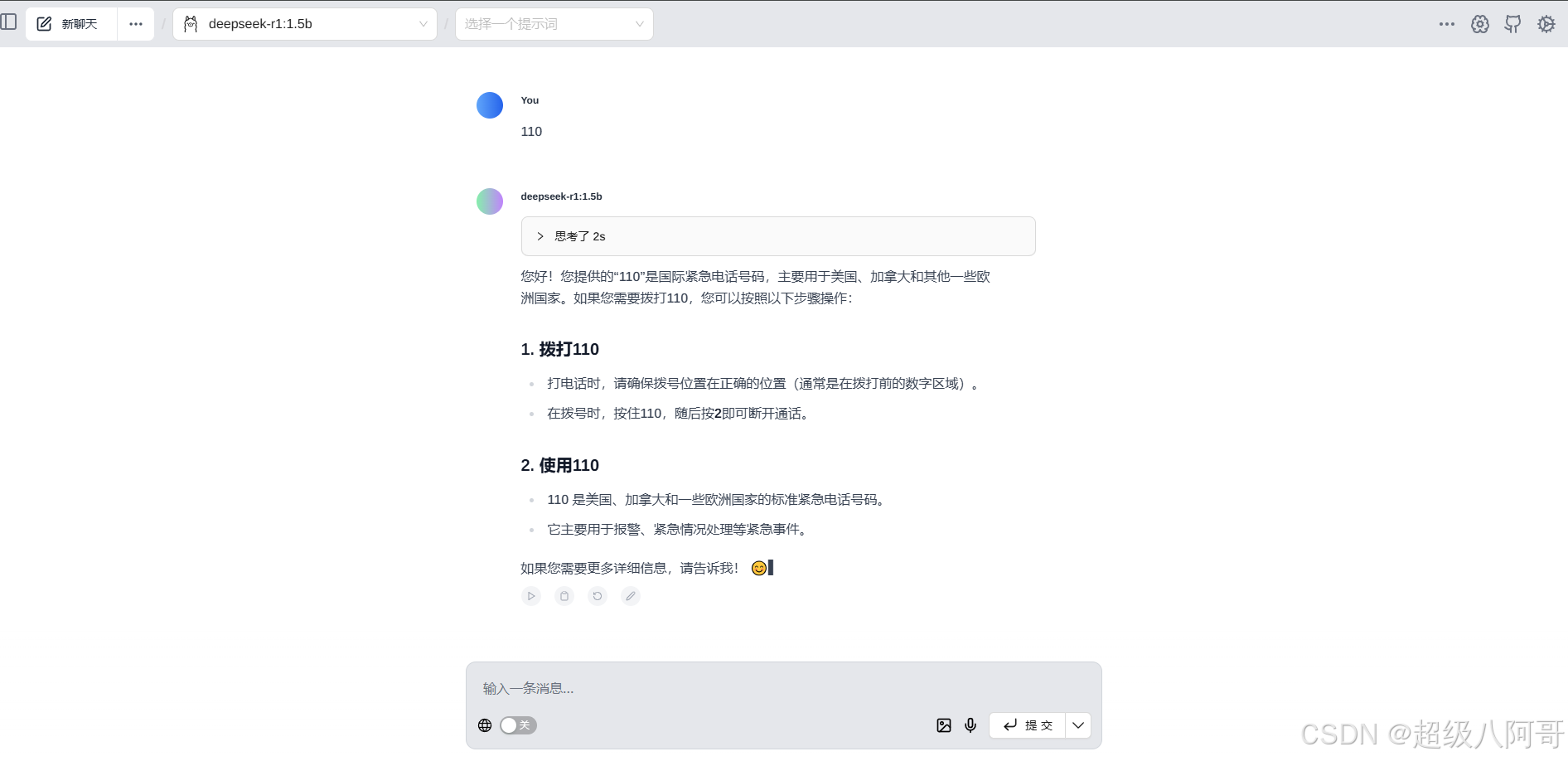
6.利用API工具调用DeepSeek的API对话
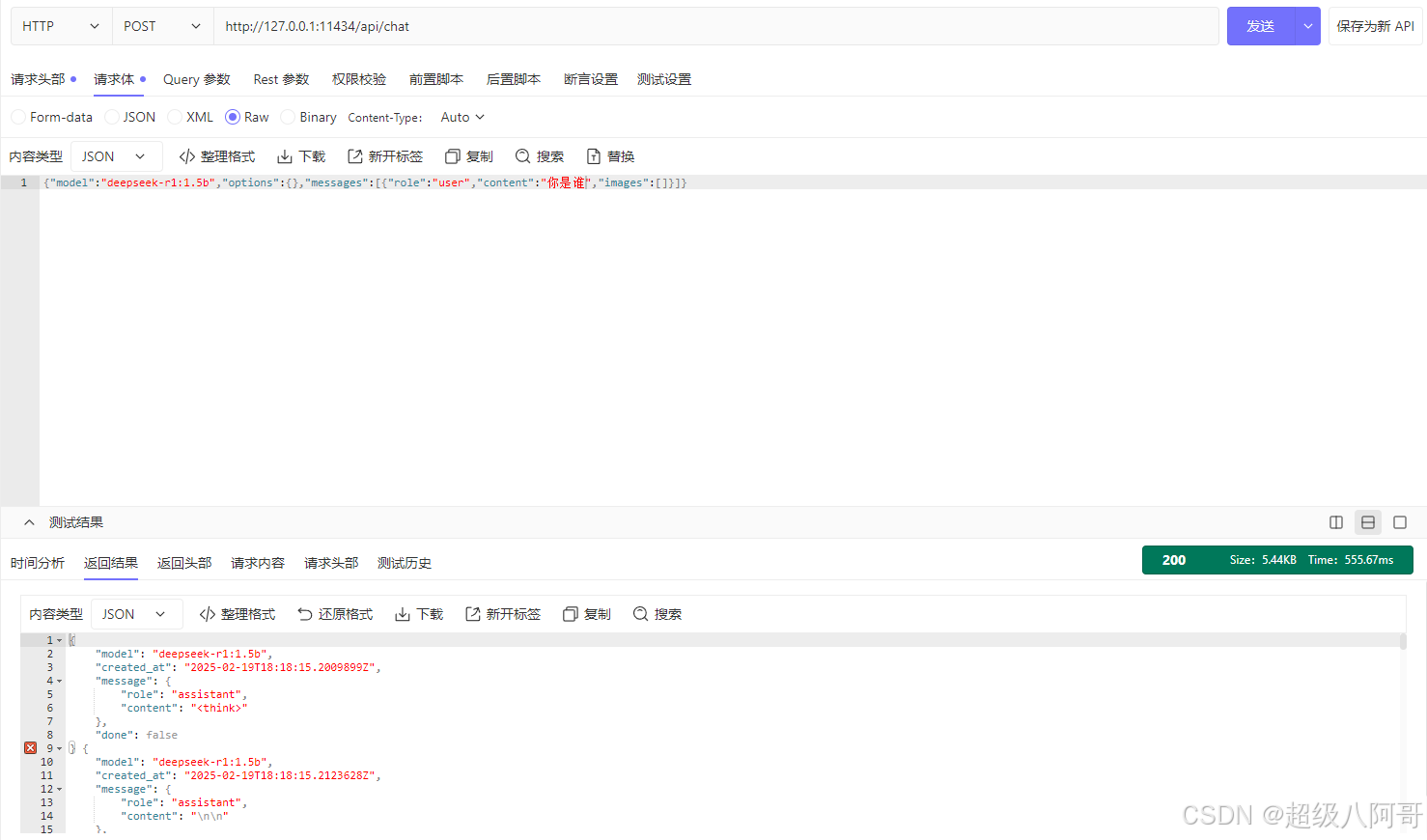
API调用信息,访问官网查看:https://api-docs.deepseek.com/zh-cn/ 或者看ollama官网:
DeepSeek是选择本地部署、云部署,还是直接调用?怎么选最合适?
请看:https://baijiahao.baidu.com/s?id=1823749974787940331&wfr=spider&for=pc

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)