曝光 :DeepSeek - R1 最低成本打造超强 AI 性能→附硬件配置全攻略
预算有限或承担轻量级推理任务的用户,有两种优化方案。若追求高性能,可选择 NVIDIA Jetson Orin Nano 方案,成本 3500 元,借助 TensorRT 加速,性能提升至 12 tokens/s,特别适合边缘计算、智能设备及物联网 AI 推理这类对效率要求高的小型 AI 模型开发场景。企业级应用中,单卡模式下,8 - bit 量化时显存占用 21.3GB,推理速度达 42 tok
在 AI 技术日新月异的当下,硬件配置对深度学习模型性能的影响至关重要。DeepSeek - R1 系列凭借其出色的计算能力和丰富的硬件组合,为不同规模的 AI 模型需求提供了全面解决方案。本文将深入剖析 DeepSeek - R1 各参数规模的硬件配置、价格参考及成本优化策略,助力开发者、企业和科研机构精准选型。
小型模型:DeepSeek - R1 - 1.5B
预算有限或承担轻量级推理任务的用户,有两种优化方案。低成本方案采用 8GB 内存搭配 USB3.0 SSD,仅需 1200 元,在 4 - bit 量化下性能可达 0.8 tokens/s,适用于小规模聊天机器人搭建、简单数据分析等,性价比高。若追求高性能,可选择 NVIDIA Jetson Orin Nano 方案,成本 3500 元,借助 TensorRT 加速,性能提升至 12 tokens/s,特别适合边缘计算、智能设备及物联网 AI 推理这类对效率要求高的小型 AI 模型开发场景。
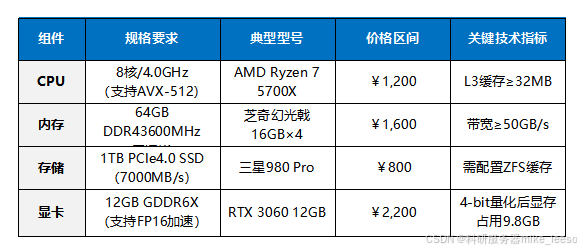
中型模型:DeepSeek - R1 - 7B
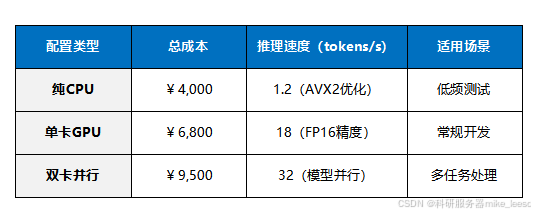
中型模型领域,配置选择多样。纯 CPU 适用于预算紧张且对推理速度要求不高的场景,如低频测试、小规模数据处理。单卡 GPU 性价比高,适合中型 AI 模型常规训练与推理,常用于企业级文本生成、情感分析等项目。若面临多任务处理、大规模数据分析等对推理及并行处理能力要求更高的任务,双卡并行配置则能发挥更大作用。

大型模型:DeepSeek - R1 - 14B
企业级应用中,单卡模式下,8 - bit 量化时显存占用 21.3GB,推理速度达 42 tokens/s,能满足对推理速度要求高的大型 AI 模型任务,如企业级复杂数据分析、自然语言处理。双卡模式通过显存池化,获得 48GB 可用显存,推理速度提升至 78 tokens/s,适合高并发、高吞吐量场景,如大型企业 AI 项目及跨部门协作模型训练。


超大规模模型:DeepSeek - R1 - 671B
超大规模模型部署对硬件要求极高。关键技术指标上,单节点 FP8 算力 32 PFLOPS,全集群理论峰值 256 PFLOPS。HBM3 显存总容量达 8 节点 ×640GB = 5.12TB,通过 NVIDIA NVSwitch 实现统一内存地址空间,能效比出色,每 token 能耗仅 0.18mWh,优于 GPT - 4 的 0.25mWh。超大规模集群配置适用于科研机构或大型企业的超复杂深度学习任务,如超级计算、AI 训练平台及全球分布式推理,可高效处理海量数据,满足高端应用快速迭代需求。成本优化方面,使用 AutoGPTQ 实现 4 - bit 量化,可使 14B 模型显存需求从 24GB 降至 12GB;采用混合精度训练(FP16 主权重 + FP8 梯度计算),训练速度提升 2.3 倍,显存占用降低 40% 。

个人开发者选择 7B 量化版本,搭配 RTX 4060 Ti 与 64GB 内存,控制预算在 10000 元内,可满足一般 AI 应用开发需求。企业用户采用 14B 模型结合双卡配置,并借助 vLLM 服务化部署,能构建高效的企业级 AI 模型开发与生产环境。科研机构优先申请超算中心资源,或尝试 Groq LPU 等新型架构,为前沿科研注入强大动力。通过合理运用这些硬件配置与成本优化方案,不同需求主体均可优化 AI 模型运行效率与性价比,DeepSeek - R1 系列将为 AI 技术的持续发展提供有力支撑。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)