OpenLLM:自托管LLMs变得简单、在云中运行任何开源LLMs的程序包,例如 DeepSeek 和 Llama,作为与 OpenAI 兼容的 API 终端节点
OpenLLM:自托管LLMs变得简单,OpenLLM 允许开发人员使用单个命令将任何开源LLMs(Llama 3.3、Qwen2.5、Phi3 等)或自定义模型作为与 OpenAI 兼容的 API 运行。它具有内置的聊天 UI、最先进的推理后端,以及用于使用 Docker、Kubernetes 和 BentoCloud 创建企业级云部署的简化工作流程。
一、软件介绍
文末提供下载
OpenLLM:自托管LLMs变得简单,OpenLLM 允许开发人员使用单个命令将任何开源LLMs(Llama 3.3、Qwen2.5、Phi3 等)或自定义模型作为与 OpenAI 兼容的 API 运行。它具有内置的聊天 UI、最先进的推理后端,以及用于使用 Docker、Kubernetes 和 BentoCloud 创建企业级云部署的简化工作流程。
GitHub作者:https://github.com/bentoml/OpenLLM
本信息图片均来源于作者GitHub地址
二、Get Started 开始使用
运行以下命令以安装 OpenLLM 并以交互方式探索它。
pip install openllm # or pip3 install openllm
openllm hello
三、支持的模型
OpenLLM 支持各种最先进的开源 LLMs.您还可以添加模型存储库以使用 OpenLLM 运行自定义模型。
$ openllm repo update
$ openllm model list
model version repo required GPU RAM platforms
------------- ------------------------------------------- ------- ------------------ -----------
deepseek deepseek:r1-671b-eb32 default 80Gx16 linux
deepseek:r1-distill-llama3.1-8b-626a default 24G linux
deepseek:r1-distill-qwen2.5-14b-3728 default 80G linux
deepseek:r1-distill-qwen2.5-32b-63b0 default 80G linux
deepseek:r1-distill-llama3.3-70b-4b47 default 80Gx2 linux
deepseek:r1-distill-qwen2.5-7b-math-2ca1 default 24G linux
deepseek:r1-distill-qwen2.5-14b-w8a8-4603 default 24G linux
deepseek:r1-distill-qwen2.5-32b-w8a8-9ce2 default 80G linux
deepseek:r1-distill-llama3.3-70b-w8a8-31b4 default 80G linux
deepseek:r1-distill-qwen2.5-14b-w4a16-0e8a default 24G linux
deepseek:r1-distill-qwen2.5-32b-w4a16-ca5e default 80G linux
deepseek:r1-distill-llama3.3-70b-w4a16-18c2 default 80G linux
deepseek:v3-671b-2e40 default 80Gx16 linux
gemma2 gemma2:2b-instruct-868c default 12G linux
gemma2:9b-instruct-e44c default 24G linux
gemma2:27b-instruct-3826 default 80G linux
hermes-3 hermes-3:deep-llama3-8b-1242 default 80G linux
hermes-3:llama3.1-405b-instruct-24ff default 80Gx6 linux
jamba1.5 jamba1.5:mini-4f7f default 80Gx2 linux
jamba1.5:large-e809 default 80Gx8 linux
llama3.1 llama3.1:8b-instruct-a995 default 24G linux
llama3.2 llama3.2:1b-instruct-6fa1 default 24G linux
llama3.2:3b-instruct-7d96 default 24G linux
llama3.2:11b-vision-instruct-eac2 default 80G linux
llama3.2:90b-vision-instruct-25ca default 80Gx2 linux
llama3.3 llama3.3:70b-instruct-f791 default 80Gx2 linux
mistral mistral:8b-instruct-f4ed default 24G linux
mistral:24b-small-instruct-2501-cc81 default 80G linux
mistral-large mistral-large:123b-instruct-2407-e1ef default 80Gx4 linux
phi4 phi4:14b-a515 default 80G linux
pixtral pixtral:12b-2409-a2e0 default 80G linux
pixtral:124b-2411-9886 default 80Gx4 linux
qwen2.5 qwen2.5:7b-instruct-dbe1 default 24G linux
qwen2.5:14b-instruct-d1f8 default 80G linux
qwen2.5:14b-instruct-awq-59be default 24G linux
qwen2.5:14b-instruct-gptq-w8a8-fa83 default 24G linux
qwen2.5:14b-instruct-gptq-w4a16-fa83 default 24G linux
qwen2.5:14b-instruct-ggml-q4-darwin-009a default darwin
qwen2.5:14b-instruct-ggml-q8-darwin-add0 default darwin
qwen2.5:32b-instruct-e0dc default 80G linux
qwen2.5:32b-instruct-awq-0fcd default 40G linux
qwen2.5:32b-instruct-gptq-w8a8-a809 default 40G linux
qwen2.5:32b-instruct-gptq-w4a16-66e8 default 40G linux
qwen2.5:32b-instruct-ggml-darwin-75c6 default darwin
qwen2.5:72b-instruct-8557 default 80Gx2 linux
qwen2.5:72b-instruct-awq-36de default 80G linux
qwen2.5:72b-instruct-gptq-w8a8-e038 default 80G linux
qwen2.5:72b-instruct-gptq-w4a16-b0c5 default 80G linux
qwen2.5:72b-instruct-ggml-q4-darwin-2a15 default darwin
qwen2.5-coder qwen2.5-coder:3b-instruct-63b0 default 24G linux
qwen2.5-coder:7b-instruct-a819 default 24G linux
qwen2.5-coder:7b-instruct-awq-63c9 default 24G linux
qwen2.5-coder:7b-instruct-ggml-linux-d531 default linux
qwen2.5-coder:7b-instruct-gptq-w4a16-dfcf default 24G linux
qwen2.5-coder:7b-instruct-gptq-w8a16-1ff4 default 24G linux
qwen2.5-coder:7b-instruct-ggml-darwin-33fb default darwin
qwen2.5-coder:14b-instruct-e2e9 default 40G linux
qwen2.5-coder:14b-instruct-awq-5456 default 40G linux
qwen2.5-coder:14b-instruct-gptq-w8a8-0910 default 40G linux
qwen2.5-coder:14b-instruct-gptq-w4a16-d2dc default 40G linux
qwen2.5-coder:32b-instruct-1950 default 80G linux
四、启动服务器LLM
要在本地启动LLM服务器,请使用命令 openllm serve 并指定模型版本。
OpenLLM 不存储模型权重。门控模型需要 Hugging Face 令牌 (HF_TOKEN)。源程序Hugging Face 访问不了,这里可以改为国内的门控模型,这个放这里只是举例用。
- 在此处创建您的 Hugging Face 令牌。
- 请求访问门控模型,例如 meta-llama/Llama-3.2-1B-Instruct。
- 通过运行以下命令将令牌设置为环境变量:
export HF_TOKEN=<your token>openllm serve openllm serve llama3.2:1b-instruct-6fa1
该服务器将 http://localhost:3000 访问,提供与 OpenAI 兼容的 API 进行交互。您可以使用支持 OpenAI 兼容 API 的不同框架和工具调用终端节点。通常,您可能需要指定以下内容:
API 主机地址:默认情况下,LLM托管在 http://localhost:3000。
模型名称:名称可能因您使用的工具而异。
API 密钥:用于客户端身份验证的 API 密钥。这是可选的。以下是一些示例:
OpenAI Python client OpenAI Python 客户端
LlamaIndex 骆驼指数
from llama_index.llms.openai import OpenAI llm = OpenAI(api_bese="http://localhost:3000/v1", model="meta-llama/Llama-3.2-1B-Instruct", api_key="dummy") ...五、Chat UI 聊天用户界面
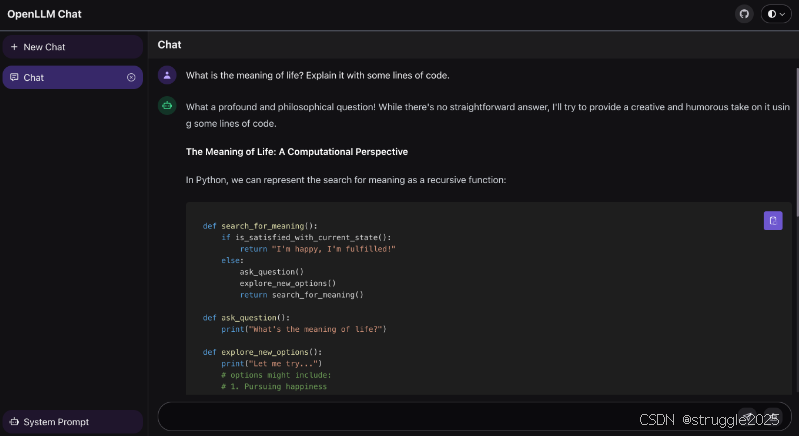
终端节点为 http://localhost:3000/chat 启动LLM的服务器提供聊天 UI。
六、程序及源码下载

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 17
17 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)