OpenAI 与 DeepSeek:谁更懂 Kotlin?
这篇文章比较了 DeepSeek-R1 与 OpenAI 模型在 Kotlin 编程语言方面的表现,评估了它们在代码生成、问题解答和推理能力上的优劣,并提供了相关基础。
随着 AI 模型的快速发展,DeepSeek-R1 作为 OpenAI 的有力竞争者正在引起广泛关注。那么,这些模型对 Kotlin 的理解程度如何?它们能否生成可靠的代码,解释复杂概念,并协助调试呢?
JetBrains Research 团队针对最新的 AI 模型,包括 DeepSeek-R1、OpenAI o1 和 OpenAI o3-mini,进行了测试。他们采用了 KotlinHumanEval 和一个全新的 Kotlin 问答基准,用以评估这些模型的综合表现,排名并分析了 DeepSeek 模型在实际 Kotlin 问题中的回答能力,帮助开发者了解这些模型的优势与局限。
AI 模型 Kotlin 能力评测
KotlinHumanEval 基准
长期以来,OpenAI 的 HumanEval 基准一直是衡量 AI 模型编程能力的关键指标,它通过检测模型根据文档字符串生成函数并通过单元测试的能力来评分。JetBrains Research 团队此前推出了 KotlinHumanEval,该基准测试采用与 HumanEval 相同的测试,但针对的是符合 Kotlin 语言习惯的代码。
自发布以来,各模型在 KotlinHumanEval 上的得分显著提升。其中,OpenAI 的领先模型成功率达到 91%,创下新高。而开源的 DeepSeek-R1 也表现不俗,能够完成大部分任务。以下是各模型在 KotlinHumanEval 基准上的表现:
| 模型名称 | 成功率(%) |
|---|---|
| OpenAI o1 | 91.93% |
| DeepSeek-R1 | 88.82% |
| OpenAI o1-preview | 88.82% |
| OpenAI o3-mini | 86.96% |
| OpenAI o1-mini | 86.34% |
| Google Gemini 2.0 Flash | 83.23% |
| Anthropic Claude 3.5 Sonnet | 80.12% |
| OpenAI GPT-4o | 80.12% |
| OpenAI GPT-4o mini | 77.02% |
新兴基准测试
除 KotlinHumanEval 外,近年来还出现了一些新的多语言评测基准。例如,McEval 涵盖了 40 种编程语言,包括 Kotlin,并提供解释示例;M2rc-Eval 也声称支持 Kotlin,但目前尚未公开相关数据集。
尽管现有基准主要考察代码生成能力,但 JetBrains Research 发现,开发者在代码生成之外,还常用 AI 工具来解释代码,例如理解错误原因或分析代码含义。因此,仅靠传统基准无法全面评估模型在 Kotlin 领域的表现。
Kotlin_QA 问答基准
为弥补这一不足,JetBrains Research 推出了 Kotlin_QA 基准。他们收集了 47 个 Kotlin 相关问题,这些问题由开发者宣传大使准备,或来自 Kotlin 公开 Slack 频道。每个问题均由 Kotlin 专家给出参考答案,然后邀请不同的 AI 模型作答。
以下为 Slack 频道中一位开发者提出的示例问题:
“我有一个 Kotlin 服务端应用程序运行在 k8s 的 pod 中。在某些情况下,k8s 会发送 SIGTERM 或 SIGKILL 信号终止我的应用程序。在 Kotlin 中,有没有比 Runtime.getRuntime().addShutdownHook(myShutdownHook) 更优雅的关闭方式?”
开发者可以尝试自己回答,然后对比 AI 模型的答案。
AI 模型回答质量评估
JetBrains Research 采用 LLM-as-a-judge 方法评估模型回答质量,即用 AI 模型充当评委,对比各模型的回答与专家答案,评分范围为 1 到 10。
由于常见 LLM 模型的评判结果可能不一致,团队特别筛选了评审模型,考察标准包括:
- 能识别无意义回答,例如随机字符串;
- 评分与人类评估 OpenAI o1-preview 回答的结果一致性;
- 能区分简单模型与综合能力强的模型。
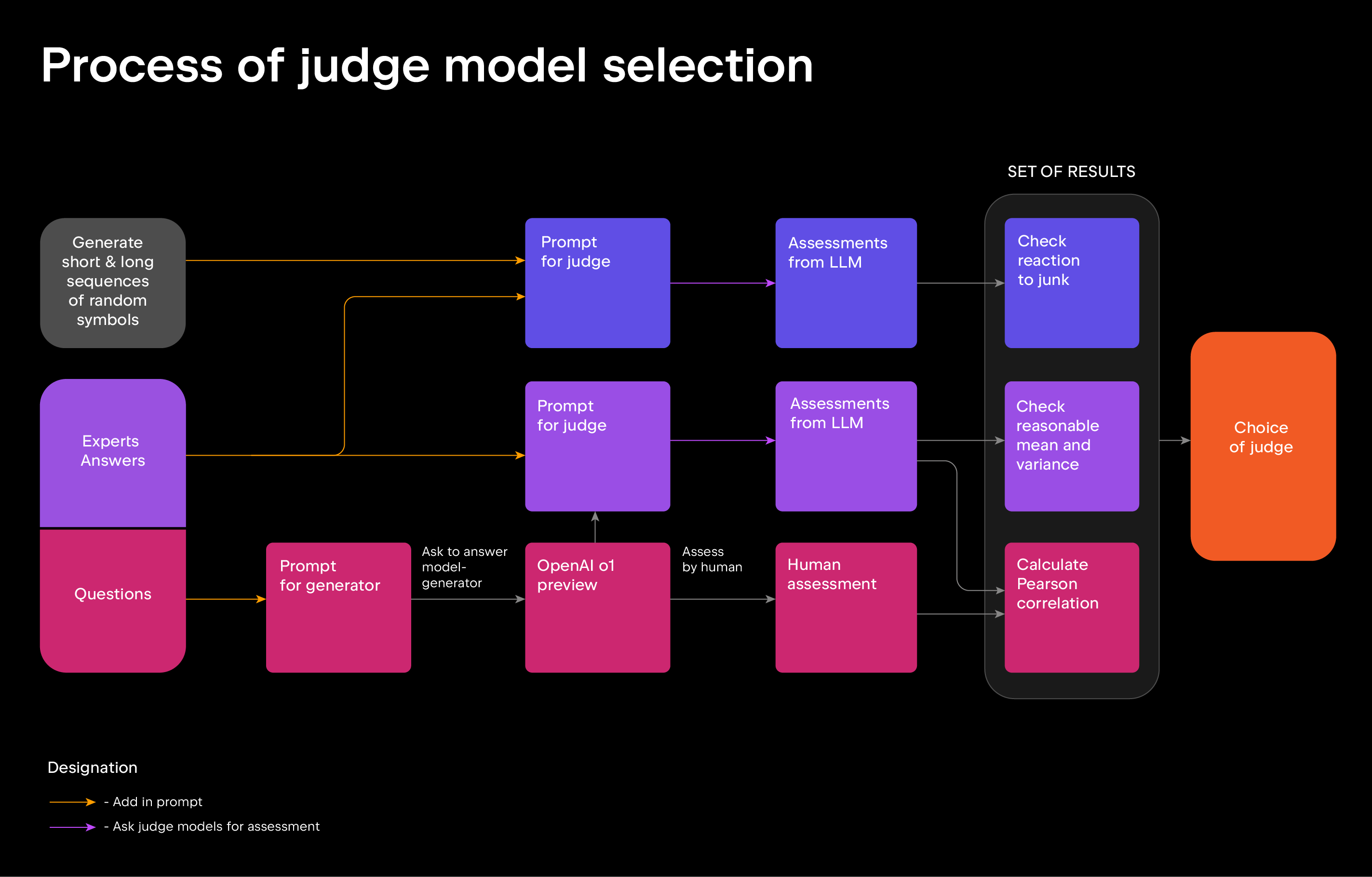
最终测试表明,GPT-4o(2024 年 6 月 8 日版本)是最可靠的评审模型,它的评分与人类评估高度一致,并能有效识别低质量回答。
Kotlin_QA 排行榜
| 模型名称 | 平均评分 |
|---|---|
| DeepSeek-R1 | 8.79 |
| OpenAI o3-mini | 8.70 |
| OpenAI o1 | 8.62 |
| OpenAI o1-preview | 8.60 |
| OpenAI o1-mini | 8.40 |
| OpenAI GPT-4o (2024-11-20 版本) | 8.40 |
| Anthropic Claude 3.5 Sonnet | 8.38 |
整体来看,最新的 OpenAI 模型和 DeepSeek-R1 在 Kotlin 领域表现优异。DeepSeek-R1 在开放性问题和推理能力方面略胜一筹。然而,所有模型仍存在知识不完整、信息滞后以及常见 LLM 错误(如计数错误、上下文丢失)等问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)