普通人也能轻松训练AI:快速搭建Dify和DeepSeek的指南
01背景AI已然成为当今的热门话题。过去,由于私有化部署成本极高,大多数使用者仅停留在简单的问答阶段,极少有人尝试训练大模型。然而,随着DeepSeek R1的问世,其部署成本仅为chatGPT的十分之一,这让许多企业和个人看到了参与的希望。未来,必将有越来越多的垂直领域AI大模型或应用出现,这或许是一个巨大的机遇。那么,普通人要如何参与呢?要如何训练自己的AI呢?本文将介绍一种简单且无需编写代码
01
背景
AI已然成为当今的热门话题。过去,由于私有化部署成本极高,大多数使用者仅停留在简单的问答阶段,极少有人尝试训练大模型。然而,随着DeepSeek R1的问世,其部署成本仅为chatGPT的十分之一,这让许多企业和个人看到了参与的希望。未来,必将有越来越多的垂直领域AI大模型或应用出现,这或许是一个巨大的机遇。那么,普通人要如何参与呢?要如何训练自己的AI呢?本文将介绍一种简单且无需编写代码的方法,帮助您轻松训练AI应用。
02
Ollama的安装
Ollama 是一个用go语言开发的开源框架,可用于本地运行和管理大语言模型(LLM,Large Language Model)。我们将使用 Ollama 来运行和管理 DeepSeek 大模型。Ollama 支持在 CPU 或 GPU 环境下运行,具体安装步骤如下。
-
基于CPU运行
DeepSeek R1:7b大模型在cpu环境也能跑,但不是很流畅,个人或者实验用的话倒也无所谓,运行Ollama指令如下:
docker run -d -v /data/ollama:/root/.ollama -p 11434:11434 --name ollama registry.cn-hangzhou.aliyuncs.com/yilingyi/ollama
-
基于GPU运行
经测试,DeepSeek R1:7b大模型在10G以上显存的环境可以很流畅,使用GPU需要先配置依赖环境。
2.1. apt方式安装
- 配置仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \` `| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg``curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \` `| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \` `| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list``sudo apt-get update
- 安装NVIDIA Container Toolkit
sudo apt-get install -y nvidia-container-toolkit
2.2. yum or dnf方式安装
- 配置仓库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo \` `| sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
- 安装NVIDIA Container Toolkit
sudo yum install -y nvidia-container-toolkit
- 配置docker,让其支持NVIDIA驱动
sudo nvidia-ctk runtime configure --runtime=docker``sudo systemctl restart docker
-
运行ollama
在完成上述依赖环境配置后,运行如下指令,比CPU的方式多了一个参数–gpus,通过它来指定使用宿主机的GPU。
docker run -d --gpus=all -v /data/ollama:/root/.ollama -p 11434:11434 --name ollama registry.cn-hangzhou.aliyuncs.com/yilingyi/ollama
03
运行DeepSeek大模型
**通过如下指令进行下载和运行DeepSeek R1:7b大模型:**
docker exec -it ollama ollama run deepseek-r1:7b
下载可能需要花点时间,不过没关系,我们可以边下载,边继续部署Dify,搭建一个可视化的管理平台。
04
Dify的安装
Dify 是一款开源的大语言模型(LLM)应用开发平台。它结合了后端即服务(Backend as a Service)和 LLMOps 的理念,使开发者能够快速构建生产级的生成式 AI 应用。即使是非技术人员,也可以参与到 AI 应用的定义和数据运营中。通过 Dify,不仅可以实现知识库应用,还能开发更多功能。
-
使用Docker-Compose安装
这里使用Docker-Compose V2进行安装,用V1的时候遇到异常。
mkdir -p ~/.docker/cli-plugins/``curl -SL https://github.com/docker/compose/releases/download/v2.20.2/docker-compose-linux-x86_64 -o ~/.docker/cli-plugins/docker-compose
- 克隆Dify仓库
git clone https://github.com/langgenius/dify.git
- 运行Dify
- 进入 Dify 源代码的 Docker 目录
cd dify/docker
- 复制环境配置文件
cp .env.example .env
- 启动 Docker 容器
docker compose up -d
-
Dify初始化
替换成你的服务器IP,访问后设置你的账号和密码。
http://your_server_ip/install
到此,我们完成了Dify和DeepSeek大模型的部署,接下来需要在Dify进行大模型配置和创建我们的AI应用。
05
Dify添加大模型
在完成上述安装后,我们需要在Dify控制台上添加我们部署的DeepSeek R1:7b大模型,操作如下:
- 登录控制台后,点击右上角–>设置
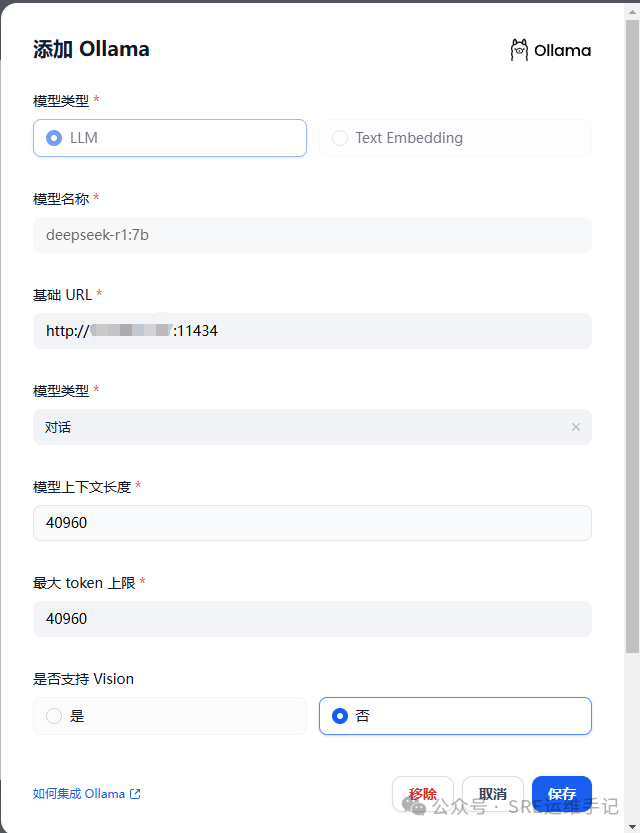
- 在弹窗左侧栏目选择“模型供应商”,然后添加Ollama配置
06
创建AI应用
好的,终于到了这个环节,我们可以借助Dify快速创建我们的AI应用,并赋予它处理的逻辑。
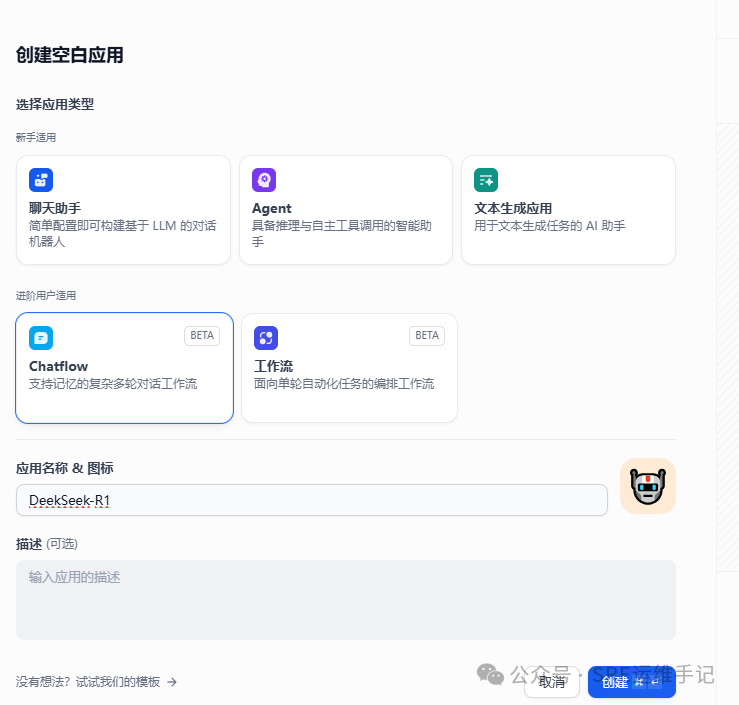
- 创建一个空白应用,选择Chatflow
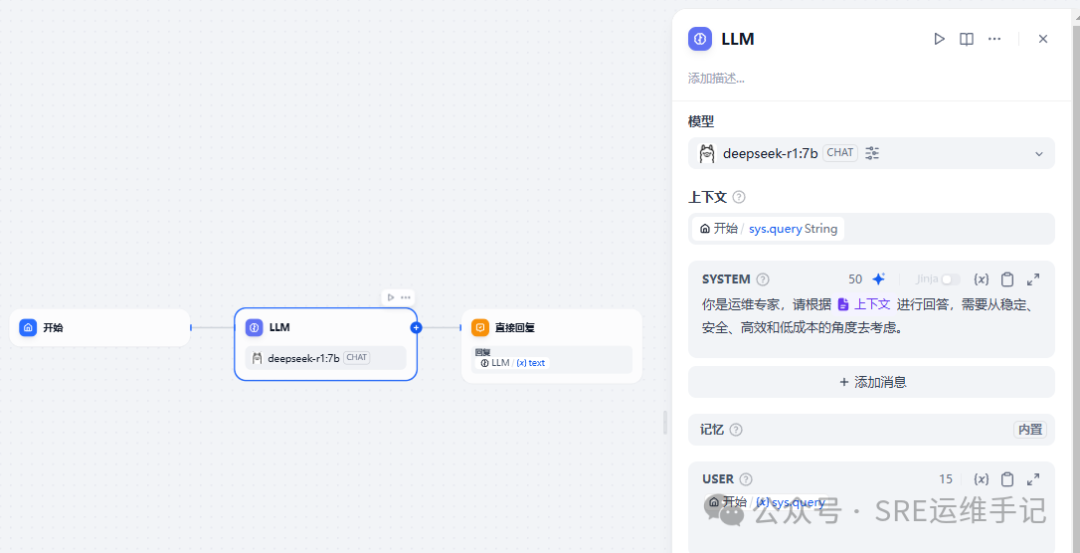
- 创建后,在LLM节点选择deepseek-r1:7b大模型,然后设置上下文为用户查询变量sys.query,接着在SYSTEM处设置提示词(Prompt)赋予它处理逻辑。
- 在预览没问题后,发布应用即可
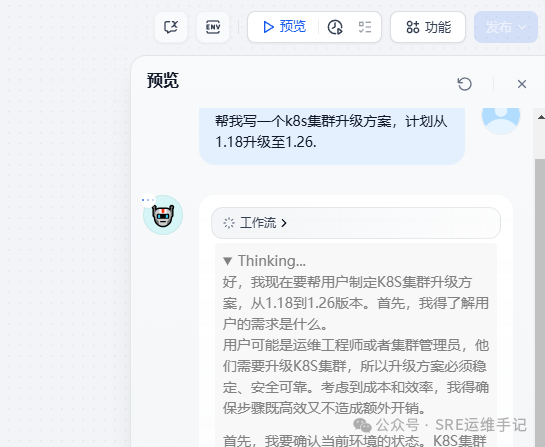
07
结 语
通过上述内容,我们了解了 DeepSeek 大模型的部署和 AI 应用的搭建,并尝试了 Chatflow 和 Prompt 的使用。由于一些条件限制,许多人无法进行基础模型的开发或微调,但 Chatflow 和 Prompt 为我们展示了另一种训练的方向。本期内容到此为止,下一期我们将深入探讨 Chatflow 和 Prompt 的高级应用。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献280条内容
已为社区贡献280条内容

所有评论(0)