【深入 DeepSeek-R1:从 TRPO 到 GRPO】
在优化领域,信任域是一种用于约束优化问题的方法。它的基本思想是:在每一步优化中,我们只允许解在一个有限的区域内变化(即信任域),而不是完全自由地更新。这个区域内的更新被认为是可靠的(因此称为信任域),因为我们相信在这个范围内,模型的行为是可控的,不会导致性能的剧烈下降。在 TRPO 中,信任域的概念被用来限制新策略与旧策略之间的偏差。具体来说:新策略的更新必须保持在旧策略的某个信任域内。这样可以确
深入 DeepSeek-R1:从 TRPO 到 GRPO
原创 煦若射
机器学习与数学
科技自媒体
机器学习、人工智能涉及的数学知识及算法基础。
2025年02月18日 17:59 浙江
DeepSeek 最近在全世界掀起了一阵轰动,凭借其在成本控制方面的卓越表现,让国内外各家大厂纷纷接入。
为什么一个小厂能做到这点?这就有必要去深入剖析大型语言模型(LLM)的训练方法,探究其背后的奥秘。
在本文中,我们将重点关注强化学习在 LLM 训练总的应用,从 TRPO 开始,到 PPO,再到 DeepSeek 最近提出的 GRPO。
回顾
首先,为了小白也能理解本文,我们回顾一下强化学习(Reinforcement Learning,RL)的基本概念以及相应的数学公式,并结合一个简单易懂的例子来说明强化学习的流程。
¸强化学习的基本概念
强化学习的核心是让一个代理(Agent)通过与环境(Environment)交互来学习如何采取行动(Action),以最大化累积奖励(Reward)。以下是关键术语及其定义:
1、状态(State,用 表示)
-
环境的当前情况。代理在每个时间步都会观察到一个状态。
-
例如:在一个迷宫游戏中,状态可以是机器人当前所在的位置。
2、行动(Action,用 表示)
-
代理在某个状态下可以选择的行为。
-
例如:机器人可以选择向前移动、向左转或向右转。
3、奖励(Reward,用 表示)
-
环境对代理行为的反馈,通常是一个标量值,用于指导代理的学习。
-
例如:机器人走出迷宫时获得正奖励(+10),撞墙时获得负奖励(-1)。
4、策略(Policy,)
- 决定代理在某个状态下采取哪个行动的规则。策略通常用概率分布表示:

其中, 是模型参数, 表示在状态 下选择行动 的概率。
5、价值函数(Value Function,)
- 衡量从某个状态 开始,按照当前策略行动所能获得的预期累积奖励:
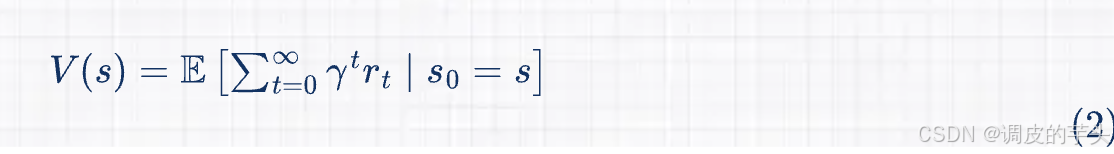
其中, 是折扣因子,用于权衡当前奖励和未来奖励的重要性。
6、优势函数(Advantage Function, )
- 衡量在状态 下选择行动 相对于平均表现的优劣:

其中, 是动作价值函数,表示在状态 下采取行动 后的预期累积奖励。
7、目标(Objective)
- 强化学习的目标是找到一个最优策略 ,使得代理能够最大化累积奖励:

基础知识就回顾到这里,下面用一个例子来说明强化学习的应用场景,可以对照上述概念来理解。
举个栗子
¸场景描述
假设我们正在训练一辆自动驾驶汽车学会在一个简单的十字路口环境中安全驾驶。目标是让汽车学会在不同交通信号灯状态下采取正确的行动,以避免事故并高效通行。
首先,看一下强化学习的基本概念在本例中的体现。
1、状态(State,)
-
环境的当前情况。例如:
-
当前交通信号灯的颜色(红灯、绿灯、黄灯);
-
汽车的位置(接近路口、在路口、远离路口);
-
周围车辆的状态(是否有其他车辆在附近)。
2、行动(Action,)
-
汽车可以选择的行为。例如:
-
加速前进;
-
减速停车
-
转弯。
3、奖励(Reward,)
-
环境对汽车行为的反馈。例如:
-
如果汽车在绿灯时顺利通过路口,获得正奖励(+10)。
-
如果汽车在红灯时闯红灯,获得负奖励(-50)。
-
如果汽车因等待太久而浪费时间,获得小的负奖励(-1)。
4、策略(Policy,)
-
决定汽车在某个状态下采取哪个行动的规则。例如:
-
在红灯状态下,策略可能建议减速停车的概率为 90%,加速前进的概率为 10%。
5、价值函数(Value Function,)
-
衡量从某个状态 开始,按照当前策略行动所能获得的预期累积奖励。例如:
-
如果汽车在绿灯状态下接近路口,其价值函数可能会很高,因为顺利通过的可能性大。
-
如果汽车在红灯状态下接近路口,其价值函数可能会很低,因为需要等待或可能闯红灯。
6、优势函数(Advantage Function,)
-
衡量在状态 下选择行动 相对于平均表现的优劣。例如:
-
在红灯状态下,选择“减速停车”的优势值会很高,因为它避免了负奖励。
-
在红灯状态下,选择“加速前进”的优势值会很低,因为它可能导致严重的负奖励。
¸强化学习流程
1、初始化策略
-
初始策略可能是随机的。例如:
-
在红灯状态下,汽车有 50% 的概率选择“减速停车”,50% 的概率选择“加速前进”。
2、与环境交互
-
汽车开始行驶,并根据当前策略选择行动。例如:
-
在红灯状态下,汽车选择了“加速前进”,结果闯了红灯,获得了 -50 的奖励。
-
在绿灯状态下,汽车选择了“加速前进”,顺利通过路口,获得了 +10 的奖励。
3、计算优势
-
根据每轮的结果,计算每个行动的优势值。例如:
-
在红灯状态下,“减速停车”的优势值为 +40,因为它避免了 -50 的负奖励。
-
在绿灯状态下,“加速前进”的优势值为 +20,因为它比其他行动(如减速停车)获得了更高的奖励。
4、更新策略
-
根据优势值调整策略。例如:
-
在红灯状态下,增加“减速停车”的概率,减少“加速前进”的概率。
-
在绿灯状态下,增加“加速前进”的概率,减少其他行动的概率。
5、重复迭代
- 不断重复上述步骤,直到汽车学会一种稳定的策略,能够在各种交通信号灯状态下采取最佳行动。
¸小结
在这个例子中,状态会随着汽车的行动和环境的变化而不断更新。例如:
-
当汽车接近路口时,交通信号灯可能会从绿灯变为黄灯,再变为红灯。
-
汽车的位置也会从“远离路口”变为“接近路口”,再到“通过路口”。
这种动态变化使得强化学习的过程更加直观:汽车通过观察环境反馈(奖励),逐步优化自己的行为策略,最终学会如何安全高效地驾驶。
通过这个例子可以看出,强化学习的核心是通过试错(Trial and Error)不断改进策略,以最大化长期奖励。
尽管数学公式可能看起来复杂,但其背后的逻辑非常直观:代理通过观察环境反馈(奖励)来调整自己的行为,最终学会如何在特定任务中表现得更好。
RL & LLM
在深入探讨 RL 在 LLM 中应用的细节之前,我们先简要回顾一下训练大型语言模型的三个主要阶段:
1、预训练:模型在大规模数据集上训练,以根据前面的 token 预测序列中的下一个 token。
2、监督微调(SFT):模型在更有针对性的数据上进行微调,并与特定指令对齐。
3、强化学习(通常称为 RLHF,即带有人类反馈的强化学习):这是本文的重点。主要目标是直接通过反馈中学习,进一步优化响应与人类偏好的对齐。
可以用一个图说明上面的步骤流程。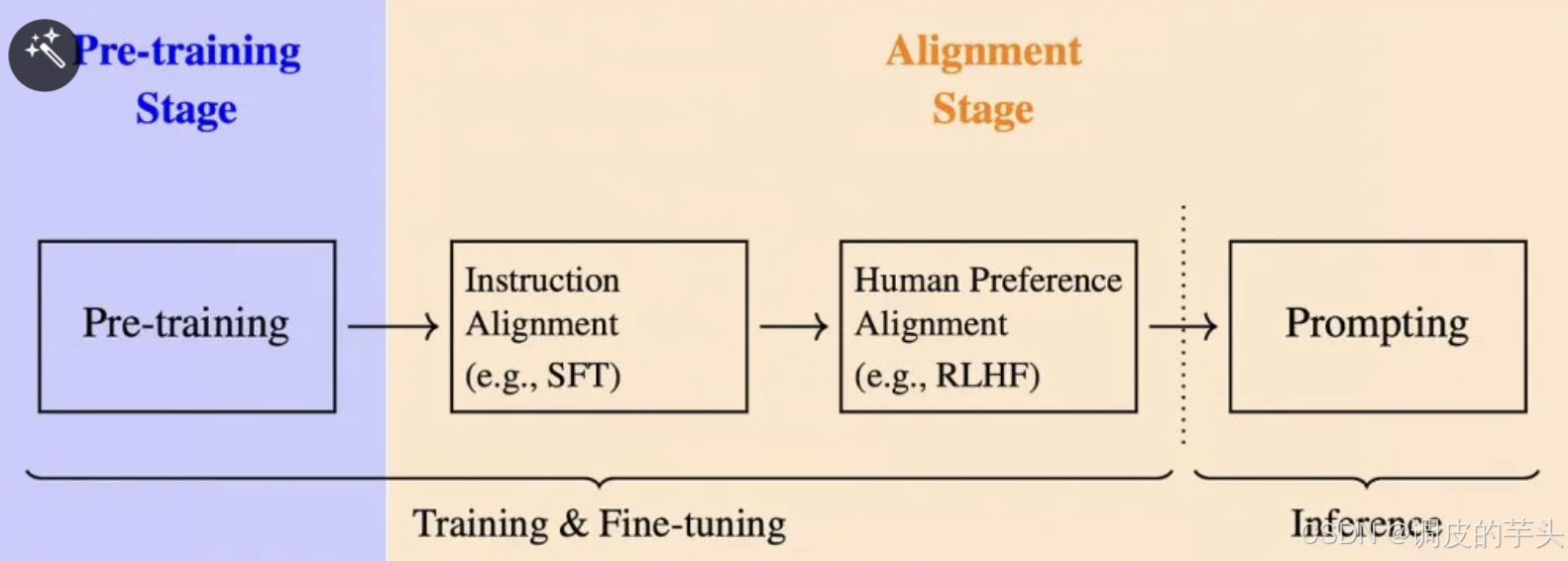
╱╲LLM 训练的三个步骤
之前我们说了,RL 非常直观,即代理处于环境中的某个状态,并通过行动过渡到其他状态。每个行动都会从环境中获得奖励:这是环境提供的反馈,引导代理后续的行动。
现在,我们可以将 RL 类比到 LLM 的训练中。
¸RL 在 LLM 中的应用
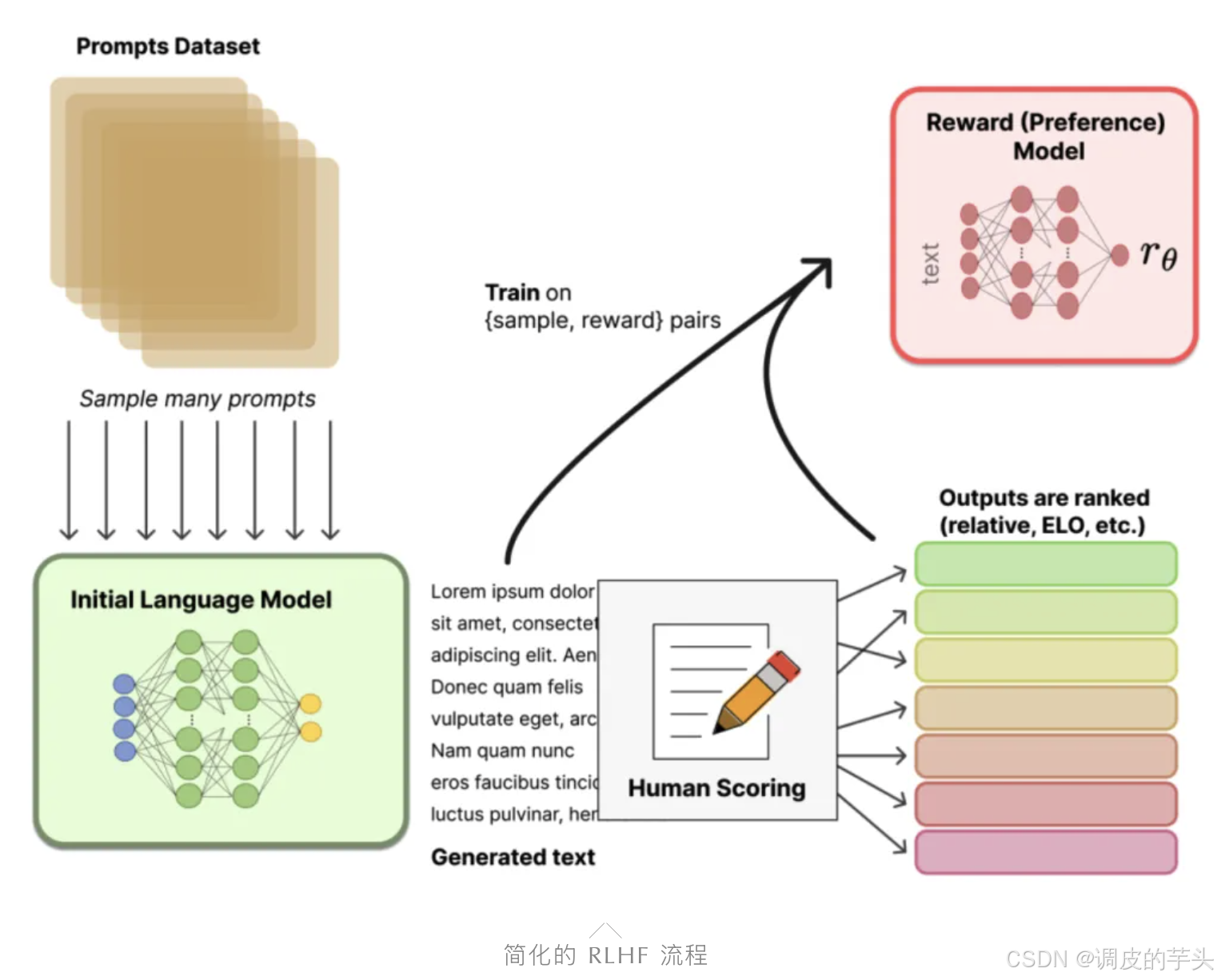
╱╲简化的 RLHF 流程
在 LLM 训练中,RL 由以下组成部分定义:
-
代理:LLM 本身。
-
环境:LLM 外部的一切,包括用户提示、反馈系统以及其他上下文信息。这基本上是 LLM 在训练过程中互动的框架。
-
行动:对查询的响应。更具体地说,这些是 LLM 决定生成的 token。
-
状态:当前正在回答的查询以及 LLM 生成的 token(即部分响应)。
-
奖励:这在 LLM 的上下文中有些复杂。通常没有二元奖励。在 LLM 中,奖励通常来自一个单独的奖励模型,该模型为每个(查询、响应)对输出一个得分。该模型是通过人工标注数据训练的,因此称为 RLHF。标注者对不同响应进行排序,目标是让高质量的响应获得更高的奖励。
-
策略:在 RL 术语中,策略是决定采取哪个行动的策略。在 LLM 的情况下,策略输出每一步可能 token 的概率分布:简而言之,这是模型用来采样下一个要生成的 token 的依据。具体来说,策略由模型的参数(权重)决定。在 RL 训练过程中,我们调整这些参数,使 LLM 更有可能产生更好的 token,即产生更高奖励得分的 token。
我们通常将策略写为:
其中 是行动(要生成的 token), 是状态(查询以及已生成的 token), 是模型的参数。
找到最佳策略是 RL 的核心思想!不像监督学习中的那样,这里没有标注数据,因此我们使用奖励来调整策略以采取更好的行动。在 LLM 任务中通过调整 LLM 的参数以生成更好的 token。
TRPO
让我们先简要回顾一下监督学习的工作原理。有标注数据,因此可以使用损失函数(如交叉熵)来衡量模型预测与真实标签之间的差异。
我们可以使用算法(如反向传播和梯度下降)来最小化损失函数并更新模型的权重 。
回想一下,我们的策略也是输出概率。在这点上,它类似于监督学习中模型的预测。我们可能会写出类似的公式,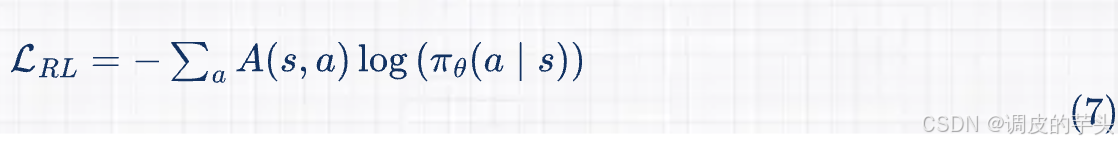
其中 是当前状态, 是可能的行动。 称为优势函数,衡量在当前状态下选择的行动与基线相比的优劣。这与监督学习中的标签类似,但是从奖励中派生出来的,而不是显式标注的。
为了简化,我们可以将优势写为:
优势奖励基线
实际上,基线通过价值函数计算,其衡量的是如果我们继续按当前策略行事,从状态 开始可能获得的预期奖励。
¸TRPO 是什么?
TRPO(Trust Region Policy Optimization,信任域策略优化)这个名字来源于其核心思想和算法设计中的一个关键概念,即信任域。为了深入解释这个名字的由来,我们需要从以下几个方面入手:
1、什么是信任域?
在优化领域,信任域是一种用于约束优化问题的方法。它的基本思想是:
-
在每一步优化中,我们只允许解在一个有限的区域内变化(即信任域),而不是完全自由地更新。
-
这个区域内的更新被认为是可靠的(因此称为信任域),因为我们相信在这个范围内,模型的行为是可控的,不会导致性能的剧烈下降。
在 TRPO 中,信任域的概念被用来限制新策略与旧策略之间的偏差。具体来说:
-
新策略 的更新必须保持在旧策略 的某个信任域内。
-
这样可以确保每次更新不会偏离太远,从而避免训练过程中的不稳定或崩溃。
2、为什么需要信任域?
在强化学习中,策略优化的目标是找到一个最优策略 ,使得代理能够最大化累积奖励。然而,直接优化策略可能会带来以下问题:
(1) 策略更新可能过于激进
-
如果新策略 与旧策略 差异过大,可能会导致性能大幅下降。
-
比如,在某些情况下,新策略可能会尝试探索一些高风险的动作,结果反而导致奖励急剧减少。
(2) 数据分布的变化
-
强化学习的数据分布是由当前策略生成的(即
on-policy方法)。如果策略更新过大,数据分布会发生显著变化,导致之前的经验(旧数据)不再适用。 -
这种不稳定性会使得训练难以收敛。
通过引入信任域,TRPO 能够有效地控制策略更新的幅度,确保新策略与旧策略之间的差异在可接受范围内,从而避免上述问题。
3、TRPO 如何实现信任域?
TRPO 使用了 KL 散度(Kullback-Leibler Divergence)来量化新策略与旧策略之间的差异,并将其作为约束条件。具体来说:
(1) KL 散度的定义
KL 散度衡量两个概率分布之间的差异:
- 它表示新策略 和旧策略 在状态 下的动作分布之间的差异。
(2) 信任域约束
TRPO 的优化目标是最大化策略的改进,同时确保新策略与旧策略之间的 KL 散度不超过某个阈值 :
-
第一行是目标函数,表示我们希望最大化策略的改进,这点可通过优势函数 衡量。
-
第二行是约束条件,表示新策略与旧策略之间的 KL 散度必须小于等于 ,即新策略必须保持在“信任区域”内。
(3) 为什么用 KL 散度?
-
KL 散度是一个自然的选择,因为它直接衡量了两个策略之间的分布差异。
-
通过限制 KL 散度,我们可以确保新策略不会偏离旧策略太远,从而保证训练的稳定性。
4、TRPO 的核心思想?
TRPO 的名字之所以包含信任域,是因为它通过以下方式体现了这一概念:
(1) 稳定性保障
-
通过限制策略更新的幅度(即信任域),TRPO 避免了因策略更新过于激进而导致的性能下降。
-
这使得 TRPO 在理论上具有单调改进的性质,即每次更新都能保证策略的性能不会变差。
(2) 平衡探索与利用
-
在强化学习中,探索和利用之间需要平衡。如果策略更新过于保守,可能会限制探索;如果更新过于激进,可能会导致不稳定。
-
TRPO 的信任域提供了一个折中方案:既允许一定程度的探索,又确保更新不会破坏现有的性能。
(3) 可控的优化过程
-
通过将优化问题转化为带约束的优化问题,TRPO 提供了一种可控的优化框架。
-
这种框架不仅适用于强化学习,也可以推广到其他需要稳定优化的场景。
¸5、为什么叫信任域策略优化?
-
信任域:指新策略与旧策略之间的差异被限制在一个可控的范围内(通过 KL 散度约束实现)。
-
策略优化:指算法的目标是通过优化策略参数 来最大化累积奖励。
因此,TRPO 的名字准确地概括了其核心思想:通过限制策略更新的幅度(信任域),确保优化过程的稳定性和可靠性,同时逐步改进策略的性能。
¸6、打个比方
为了更直观地理解信任域,可以想象以下场景:
-
假设你正在爬一座陡峭的山峰,但你不知道前方的地形是否安全。
-
为了防止滑倒或掉入悬崖,你决定每次只迈出一小步(即信任域),并确保每一步都站在稳固的地面上。
-
这样,即使你不知道整个路径,你也能一步步接近山顶,而不会因为迈步过大而陷入危险。
TRPO 就像是一条谨慎的老狗,通过信任域确保每一步都安全可靠,从而稳步提升策略的性能。
PPO
虽然 TRPO 是一个重大突破,但由于其计算密集型的梯度计算,它在实际中已不再广泛使用,特别是在训练 LLM 时。而 PPO 现在是大多数 LLM 架构(包括 ChatGPT、Gemini 等)中的首选方法。
PPO(Proximal Policy Optimization,近端策略优化)这个名字来源于其核心思想和算法设计中的一个关键概念,即近端(Proximal)。为了深入解释这个名字的由来,我们需要从以下几个方面入手:
¸1、什么是近端?
近端在数学和优化领域通常指的是靠近当前点的意思。在 PPO 中,近端具体指代的是新策略 和旧策略 之间的关系。PPO 的目标是确保新策略的更新不会偏离旧策略太远,从而保持训练过程的稳定性和可靠性。
换句话说,近端强调的是策略更新的幅度被限制在一个合理的范围内,以避免因更新过大而导致性能下降或训练不稳定。
¸2、为什么需要近端约束?
在强化学习中,策略优化的目标是找到一个最优策略 ,使得代理能够最大化累积奖励。然而,直接优化策略可能会带来以下问题:
(1) 策略更新可能过于激进
-
如果新策略 与旧策略 差异过大,可能会导致性能大幅下降。
-
比如,在某些情况下,新策略可能会尝试探索一些高风险的动作,结果反而导致奖励急剧减少。
(2) 数据分布的变化
-
强化学习的数据分布是由当前策略生成的(即
on-policy方法)。如果策略更新过大,数据分布会发生显著变化,导致之前的经验(旧数据)不再适用。 -
这种不稳定性会使得训练难以收敛。
通过引入近端约束,PPO 能够有效地控制策略更新的幅度,确保新策略与旧策略之间的差异在可接受范围内,从而避免上述问题。
¸3、PPO 如何实现近端约束?
PPO 使用了一种称为截断替代目标(Clipped Surrogate Objective)的方法来隐式地限制策略更新的幅度。以下是其核心机制:
(1) 替代目标
- 在强化学习中,我们希望最大化策略改进。PPO 的替代目标函数如下:
其中:
-
是策略比率,衡量新策略相对于旧策略的概率变化。
-
是优势函数,表示在状态 下采取行动 的优劣。
-
是一个超参数,用于定义策略比率的允许范围(例如, 表示策略比率只能在 之间变化)。
(2) 截断操作 (Clipping)
-
剪切操作的核心思想是:如果策略比率 超出了范围 ,则将其截断到该范围内。
-
这样可以防止策略更新过于激进,从而确保新策略与旧策略之间的差异保持在近端范围内。
(3) 隐式的信任域
-
虽然 PPO 没有像 TRPO 那样显式地使用 KL 散度作为约束条件,但通过截断操作,PPO 实现了一个隐式的信任域。
-
这种方法既简化了优化过程,又保留了策略更新的稳定性。
¸4、PPO 的核心思想?
PPO 的名字之所以包含近端,是因为它通过以下方式体现了这一概念:
(1) 稳定性保障
-
通过限制策略更新的幅度,PPO 避免了因策略更新过于激进而导致的性能下降。
-
这使得 PPO 在实践中更加稳健,能够适应各种复杂的任务。
(2) 平衡探索与利用
-
在强化学习中,探索和利用之间需要平衡。如果策略更新过于保守,可能会限制探索;如果更新过于激进,可能会导致不稳定。
-
PPO 的近端提供了一个折中方案:既允许一定程度的探索,又确保更新不会破坏现有的性能。
(3) 可控的优化过程
-
通过将优化问题转化为带剪切的目标函数,PPO 提供了一种可控的优化框架。
-
这种框架不仅适用于强化学习,也可以推广到其他需要稳定优化的场景。
¸5、为什么叫近端策略优化?
-
近端:指新策略与旧策略之间的差异被限制在一个合理的范围内(通过截断操作实现)。
-
策略优化:指算法的目标是通过优化策略参数 来最大化累积奖励。
因此,PPO 的名字准确地概括了其核心思想:通过限制策略更新的幅度(近端),确保优化过程的稳定性和可靠性,同时逐步改进策略的性能。
下面用一个图分别解释 PPO 目标函数的各个部分,
╱╲分别解释公式的各个部分
¸6、打个比方
为了更直观地理解近端,可以想象以下场景:
-
假设你正在驾驶一艘船,试图穿越一片波涛汹涌的海域。
-
为了安全起见,你决定每次调整航向时只做小幅度的改变(即所谓近端),而不是突然大幅度转向。
-
这样,即使你不知道整个航线,你也能一步步接近目的地,而不会因为转向过大而失去控制。
PPO 就像是一个谨慎的船长,通过近端确保每次调整都安全可靠,从而稳步提升策略的性能。
GRPO
GRPO(Group Relative Policy Optimization,群组相对策略优化),这个名字来源于其核心思想和算法设计中的两个关键概念,群组和相对。
为了深入解释这个名字的由来,我们需要从以下几个方面入手。
¸1、什么是群组?
在 GRPO 中,群组指的是为每个查询生成的一组响应(Responses)。具体来说:
-
对于一个给定的查询(例如 2+2 等于多少?),GRPO 不会只生成一个响应,而是生成多个响应(例如 4、3.999、5 等)。
-
这些响应构成了一个群组,并且每个响应都会根据奖励模型获得一个奖励值。
通过这种方式,GRPO 能够利用一组响应之间的相对关系来进行策略优化,而不是依赖传统的价值函数来预测单个响应的价值。
¸2、什么是相对?
相对是 GRPO 的另一个核心概念,它体现在如何计算每个响应的优势值(advantage)。GRPO 使用了一种基于归一化的方法,将每个响应的奖励与其所在群组的平均奖励进行比较。具体公式如下:
其中:
-
是第 个响应的奖励。
-
和 分别是该群组中所有响应奖励的均值和标准差。
这种相对优势的计算方式使得 GRPO 不再需要单独训练一个价值模型(Value Model),因为每个响应的优势值可以直接通过群组内的奖励分布计算得出。
¸3、为什么要群组和相对?
(1) 消除对价值模型的需求
-
在传统的强化学习方法(如 PPO)中,价值模型用于预测每个状态或行动的未来预期奖励。然而,训练价值模型需要额外的计算资源,并且可能引入误差。
-
GRPO 通过使用群组生成多个响应,并通过相对计算优势值,直接消除了对价值模型的需求。这种方法不仅简化了训练流程,还降低了计算成本。
(2) 提高训练效率
- 通过生成一组响应并进行归一化处理,GRPO 能够更高效地评估每个响应的质量。相比传统方法中逐个评估响应,这种方法能够更好地利用批量计算的优势。
(3) 增强鲁棒性
- 使用群组和相对计算的优势值具有更强的鲁棒性,因为它不依赖于绝对奖励值,而是基于群组内的相对表现。这使得 GRPO 在面对奖励模型输出不稳定的情况下仍然能够保持较好的性能。
¸4、如何实现群组相对优化?
GRPO 的核心机制可以总结为以下步骤,
(1) 生成群组响应
- 对于每个查询,GRPO 使用低温度采样生成一组响应(例如 个响应)。这些响应构成了一个群组。
(2) 计算奖励
- 每个响应都会通过奖励模型获得一个奖励值 。
(3) 归一化计算优势
-
使用上述公式 ,
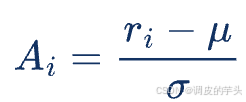
-
计算每个响应的相对优势值。这种方法确保了优势值的计算仅依赖于群组内的奖励分布,而不需要额外的价值模型。
(4) 更新策略
-
GRPO 使用 KL 散度惩罚项来限制新策略与旧策略之间的偏差,同时最大化策略目标函数。具体公式如下,
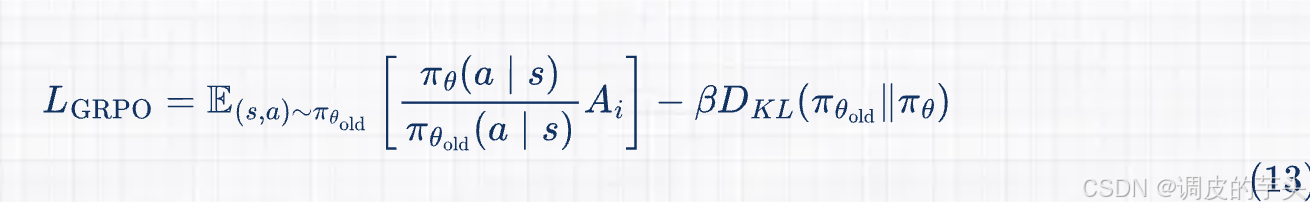
-
其中,第一项是策略改进目标,第二项是 KL 散度惩罚,用于确保策略更新的稳定性。
¸5、如何体现 GRPO 的核心思想?
GRPO 的名字之所以包含群组相对,是因为它通过以下方式体现了这一概念:
(1) 群组生成
- GRPO 利用群组生成多个响应,充分利用 LLM 的非确定性输出能力。这种方法不仅提高了数据利用率,还增强了模型的探索能力。
(2) 相对优势
- GRPO 通过归一化计算相对优势值,避免了对绝对奖励值的依赖。这种方法更加稳定,尤其是在奖励模型输出可能存在噪声的情况下。
(3) 简化优化
- 通过消除价值模型的需求,GRPO 大大简化了训练流程,同时保留了强化学习的核心思想,即通过奖励信号优化策略。
GRPO 的优秀之处一方面体现在通过群组相对策略来去掉了价值模型。
最后,GRPO 直接在其目标中添加了一个 KL 散度项(确切地说,GRPO 使用 KL 散度的简单近似来进一步改进算法),将当前策略与参考策略(通常是 SFT 后的模型)进行比较。
最后用一个图分别解释 GRPO 目标函数的各个部分,
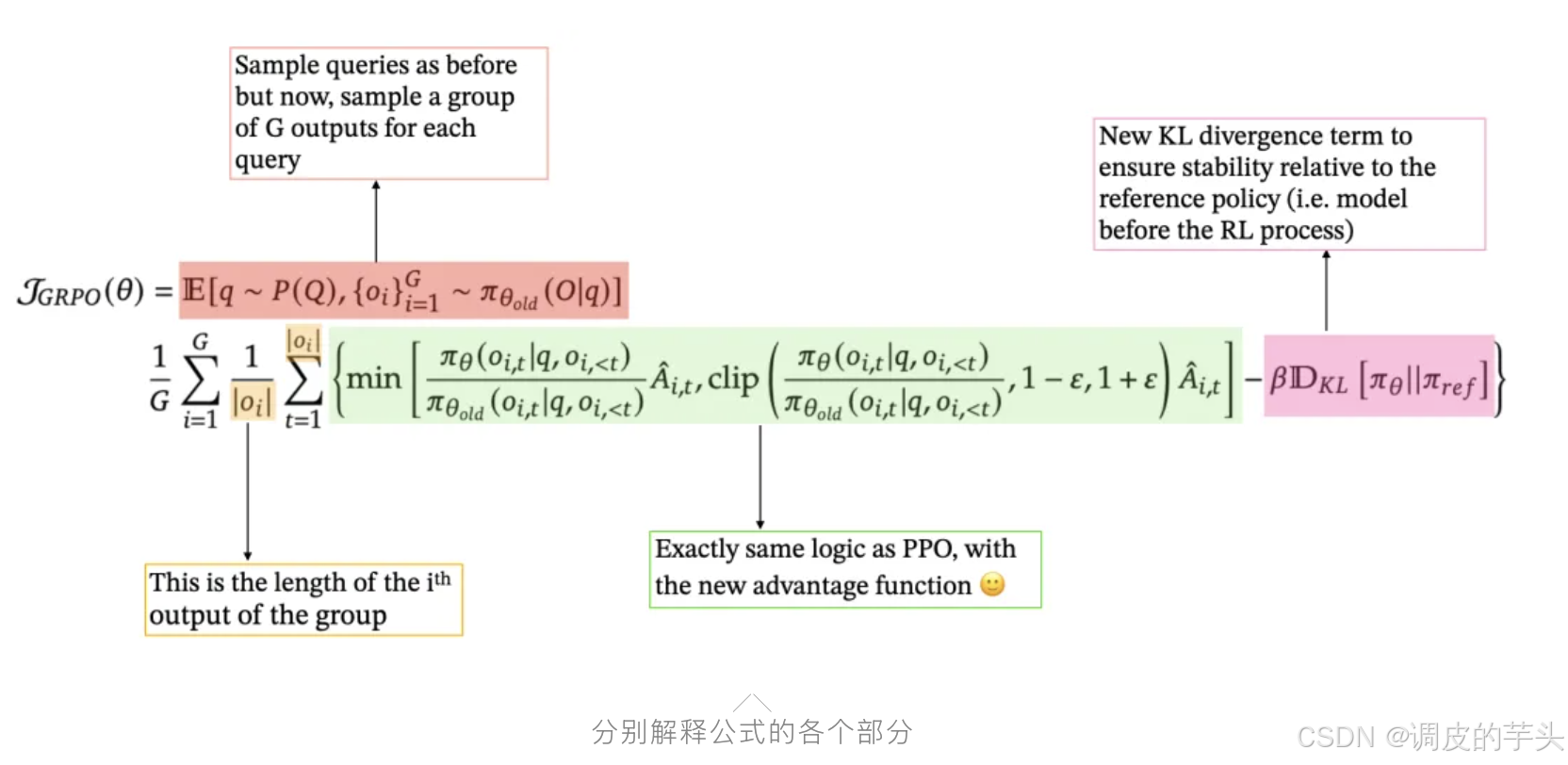
╱╲分别解释公式的各个部分
¸6、为什么叫群组相对策略优化?
-
群组:指为每个查询生成的一组响应,用于增强模型的探索能力和数据利用率。
-
相对:指通过归一化计算每个响应的相对优势值,避免对价值模型的依赖。
-
策略优化:指算法的目标是通过优化策略参数 来最大化累积奖励。
因此,GRPO 的名字准确地概括了其核心思想:通过生成一组响应并计算其相对优势值,简化优化过程,同时逐步改进策略的性能。
可以对照论文中的这张图。
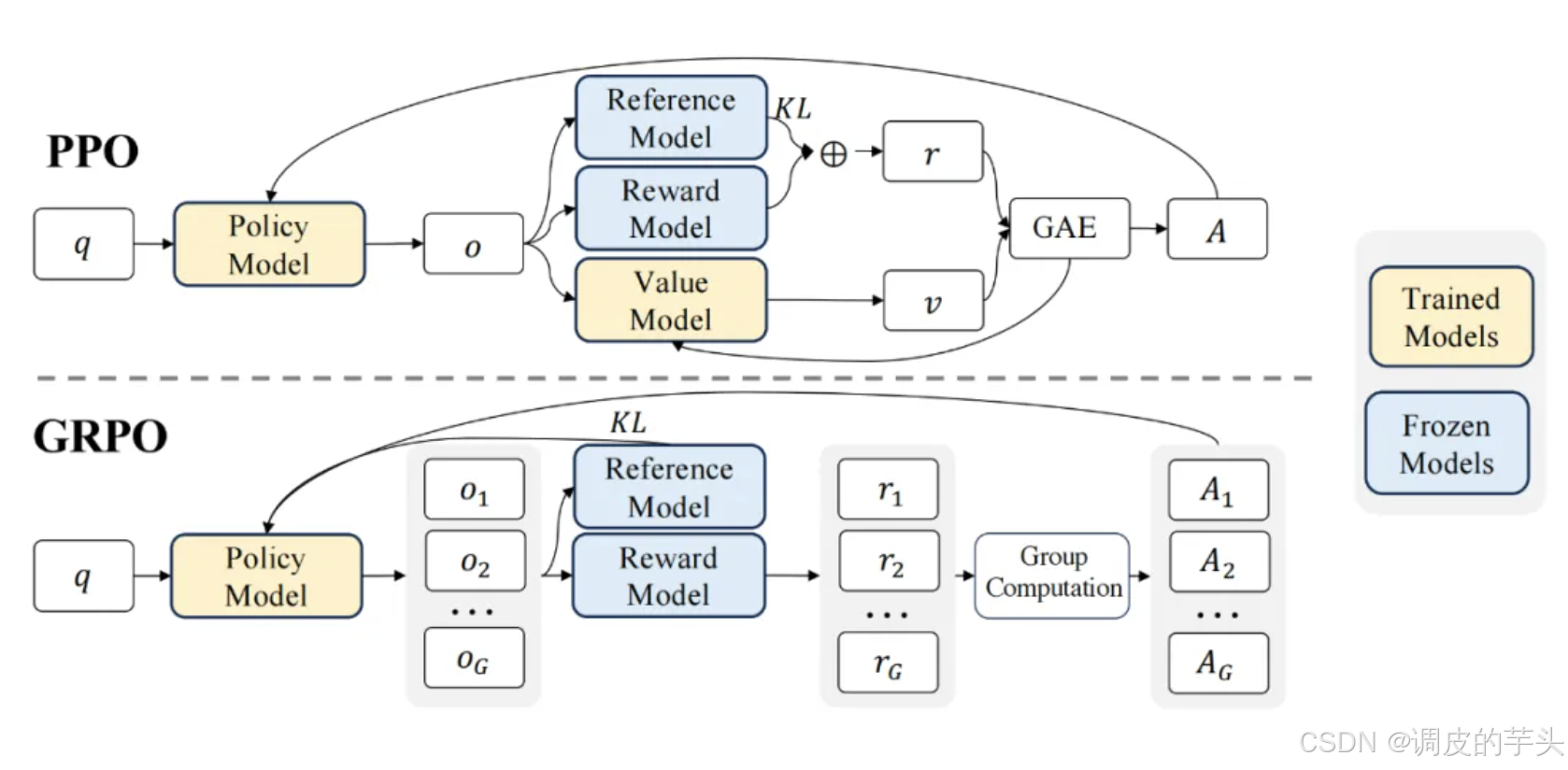
¸7、打个比方
为了更直观地理解群组相对,可以想象以下场景:
-
假设你是一名老师,正在批改学生的作文。
-
传统方法(如 PPO)需要你为每篇作文打一个绝对分数(类似于价值模型预测奖励)。
-
GRPO 的方法则是将所有学生的作文放在一起,先计算平均分和标准差,然后根据每篇作文相对于平均分的表现给出一个相对评分。
-
这种方法不仅简化了评分过程,还能更公平地反映每篇作文的质量。
GRPO 就像是一个聪明的老师,通过“群组相对评分”确保每次批改都高效可靠,从而稳步提升学生的写作水平。
我们也可以将 PPO 和 GRPO 放一起做个类比。
假设你是一名运动员,正在为一场马拉松比赛做准备。教练有两种训练方法:
PPO:单人训练营
-
在 PPO 中,教练会给你安排一个详细的训练计划,每天记录你的跑步速度、耐力等数据,并通过复杂的公式(比如 GAE,广义优势估计)计算你的表现是否达标。
-
每次训练后,教练都会拿出一本厚厚的笔记本,仔细分析你的进步:“嗯,你今天跑了 10 公里,比昨天快了 2 分钟,但根据你的潜力模型(价值函数),你还可以再快 30 秒!”
-
这种方法虽然精确,但需要大量时间和精力去计算和调整每个人的训练计划。
GRPO:团队竞赛
-
GRPO 则完全不同。教练不再单独评估每个人的表现,而是把所有运动员召集在一起,组织了一场团队竞赛。
-
每天,大家跑完后,教练会公布每个人的跑步成绩,并计算一个“相对表现分数”:比如你跑了 10 公里,而团队平均是 12 公里,那么你的相对表现就是“落后 2 公里”。这就是 GRPO 的群组归一化。
-
教练还会时不时提醒大家:“别偏离之前的训练风格太远!如果你突然改变节奏,可能会受伤。”这相当于 GRPO 中的 KL 散度惩罚,确保策略更新不会过于激进。
-
这种方法省去了复杂的潜力模型计算,直接通过群体比较来激励每个人进步。
小结
-
PPO 像是一个精打细算的私人教练,注重个人的每一步细节,但计算成本较高。
-
GRPO 则像一个聪明的团队教练,通过组织“团队竞赛”,让每个人在对比中找到自己的不足,从而快速提升整体水平。
小结
强化学习已经成为训练现代大型语言模型(LLM)的核心技术,尤其是在 PPO 和最近的 GRPO 方法中得到了广泛应用。
这些方法虽然都基于强化学习的基本框架,状态、行动、奖励和策略,但各自引入了独特的改进,以在稳定性、效率以及与人类偏好的对齐之间找到最佳平衡:
-
TRPO:通过 KL 散度约束,严格限制新旧策略之间的偏差,确保训练过程的稳定性。
-
PPO:则通过截断目标简化了优化过程,在保持稳定性的同时提升了训练效率。
-
GRPO:更进一步,完全取消了价值模型的需求,并通过基于群组的奖励归一化来计算优势值,从而显著降低了计算复杂度并提高了训练效率。
随着技术的发展,强化学习将在 LLM 的训练中扮演越来越重要的角色,不仅提升模型性能,还能超越传统的预训练和监督微调(SFT),为未来的创新开辟更多可能性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)