(2025|DeepSeek-AI,原生稀疏注意力 / NAS,动态路径选择,硬件优化)硬件对齐且原生可训练的稀疏注意力
本文提出 NSA(原生稀疏注意力),它通过算法创新和硬件优化相结合,实现高效的长文本建模。NSA 采用动态分层稀疏策略,结合粗粒度的 token 压缩和精细粒度的 token 选择,在保留全局上下文感知的同时确保局部精度。
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention

目录
1. 引言
长文本建模是下一代语言模型的关键能力,但标准注意力机制的高计算成本成为主要瓶颈。稀疏注意力提供了一种有效的解决方案,以提高计算效率,同时保持模型性能。
本文提出NSA(Natively Sparse Attention,原生稀疏注意力),它通过算法创新和硬件优化相结合,实现高效的长文本建模。NSA 采用动态分层稀疏策略,结合粗粒度的 token 压缩和精细粒度的 token 选择,在保留全局上下文感知的同时确保局部精度。本文的两项核心创新包括:
- 通过算术强度平衡的算法设计,优化实现并适配现代硬件,从而大幅提高计算速度。
- 端到端可训练性,在减少预训练计算成本的同时,保证模型性能不下降。
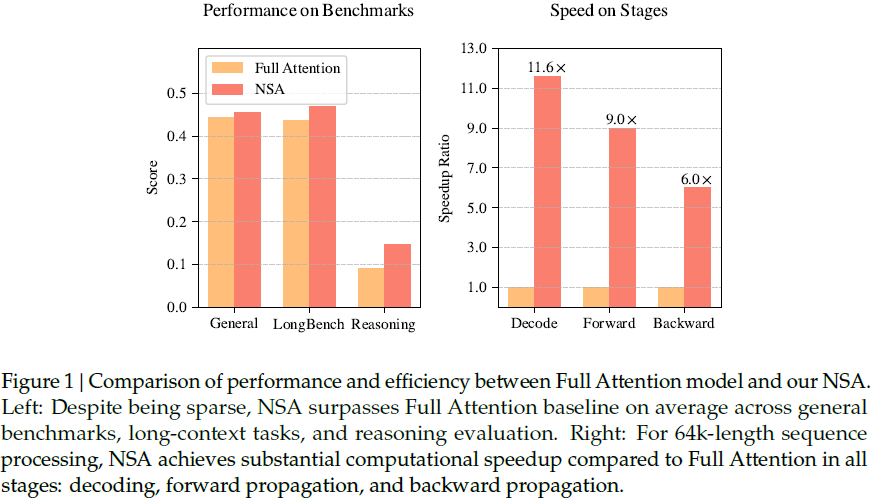
实验表明,预训练采用 NSA 的模型在通用基准测试、长文本任务和指令推理任务中均优于全注意力(Full Attention)模型。同时,在 64k 长度序列的解码、前向传播和反向传播阶段,NSA 显著加速,验证了其高效性。
1.1 关键词
稀疏注意力(Sparse Attention);长上下文建模(Long-context Modeling);硬件优化(Hardware Optimization);动态路径选择(Dynamic Path Selection);Triton 内核(Triton Kernel)。
2. 重新思考稀疏注意力方法
当前的稀疏注意力方法在理论上降低了计算复杂度,但许多方法主要在推理阶段应用,而保留了全注意力的预训练结构,这可能导致无法充分利用稀疏注意力的优势。本文分析了现有方法的两大局限:
1)高效推理的幻觉
- 许多方法仅在推理的特定阶段(如自回归解码)应用稀疏性,而预填充(prefilling)阶段仍然需要大量计算(如 H2O)。
- 现有方法难以兼容现代高效解码架构,如多查询注意力(Mulitiple-Query Attention,MQA) 和分组查询注意力(Grouped-Query Attention,GQA),导致推理速度未能显著提高。
2)可训练性稀疏的误区
- 直接对全注意力模型进行剪枝,会导致性能下降,如检索头(retrieval heads)在推理阶段易被剪掉。
- 现有方法在训练阶段缺乏高效的计算策略,例如非可训练的操作(如 k-means 聚类)会阻碍梯度传播,或导致内存访问效率低下(如 HashAttention)。
鉴于这些挑战,本文提出NSA,它通过原生稀疏建模,兼顾计算效率和训练可行性。
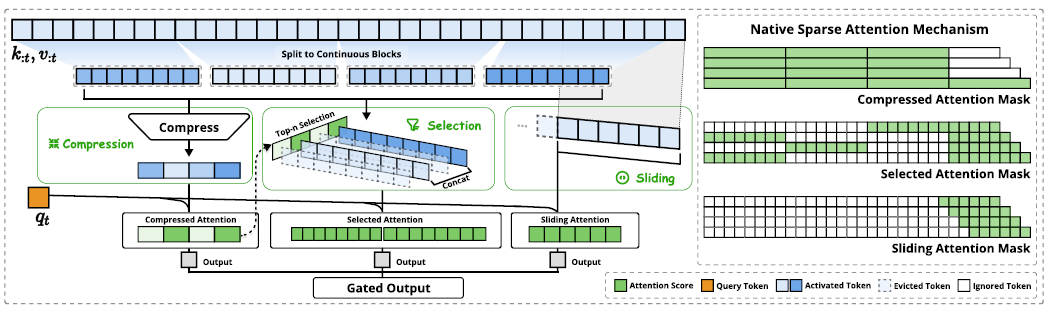
图 2:NSA 架构概览。
- 左图:该框架通过三个并行的注意力分支处理输入序列:对于给定的查询,前面的键和值被处理为粗粒度模式(patterns)的压缩注意力、重要 token 块的选定注意力和局部上下文的滑动注意力。
- 右图:每个分支产生的不同注意力模式(patterns)的可视化。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
3. 方法
NSA 结合算法优化与内核优化,核心思想是替换传统的 query-key-value(QKV)计算方式,以更紧凑的信息表示来减少计算开销。主要设计包括:
3.1 整体框架
采用三条并行注意力路径:
- 压缩注意力(Compressed Attention):对 token 进行块级(block-level)压缩,以保留粗粒度信息。
- 选择注意力(Selected Attention):从原始 token 选择重要部分,保留细粒度信息。
- 滑动窗口注意力(Sliding Attention):处理局部上下文,确保局部一致性。
3.2 算法设计
1)token 压缩:将多个 token 压缩成块级表示,以减少计算负担。
2)token 选择
块级选择(Blockwise Selection)对于在现代 GPU 上实现高效计算至关重要。这是因为与基于索引的随机读取相比,现代 GPU 架构在连续块访问方面表现出更高的吞吐量。此外,分块计算可以实现 Tensor Core 的最佳利用。这种架构特性已将分块内存访问和计算确立为高性能注意力实现的基本原则,FlashAttention 的基于块的设计就是一个例证。
块级选择:将键、值序列划分为块,基于每个块的重要性分数,确定对注意力计算最重要的块。
- 重要性分数计算(Importance Score Computation):利用压缩 token 的中间注意力分数推测块重要性。
- Top-n 选择策略(Top-n Block Selection):从高重要性块中选择前 n 个 token 进行计算。
3)滑动窗口:独立处理局部上下文,以防止局部信息干扰全局模式学习。
3.3 内核优化
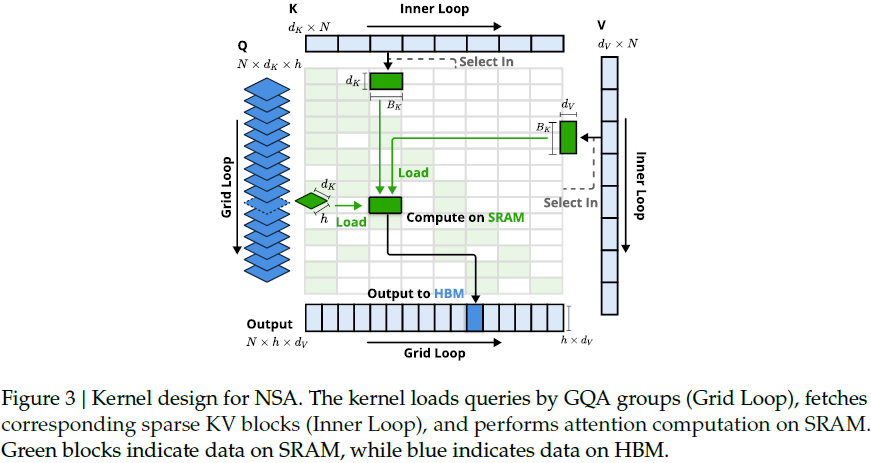
为了在训练和预填充阶段实现与 FlashAttention 级别的加速,我们在 Triton 上实现了硬件优化的稀疏注意力内核。考虑到 多头注意力(MHA) 在解码过程中因高内存访问需求而效率低下,我们的优化重点放在 共享 KV 缓存 的架构(如 GQA 和 MQA)上。
- 组中心数据加载(Group-Centric Data Loading):在每次计算循环中,将 GQA 组内的所有查询头加载到片上存储器(SRAM),并同时获取它们共享的稀疏 KV 块索引。
- 共享 KV 获取(Shared KV Fetching):按照索引 顺序加载 KV 块,确保内存访问连续,减少带宽占用。
- 网格循环调度(Outer Loop on Grid):由于每个查询块的选择块数量大致相同,我们将查询/输出计算置于 Triton 的网格调度中,以优化计算负载。
4. 实验
本文在 The Pile 语言建模基准和 BigBench、GSM8K 推理任务上评估了 NSA,使用 8 张 A100 GPU,序列长度扩展至 64k。
实验从通用基准测试、长文本任务和链式推理任务三个方面评估 NSA 的性能。
1)预训练
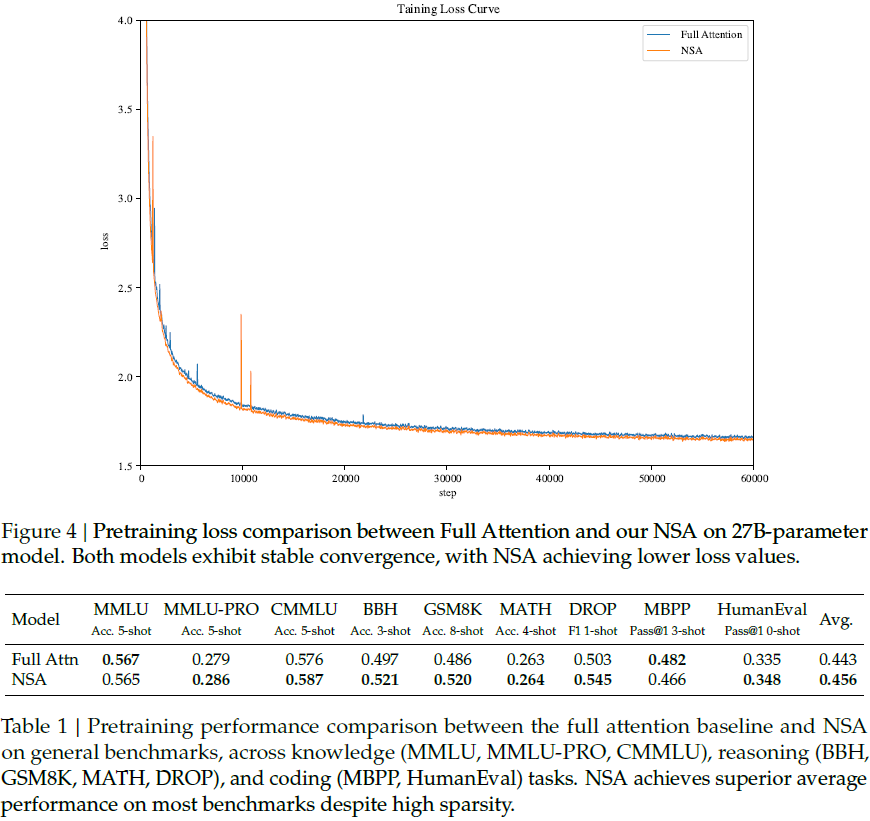
- 采用 27B 参数 Transformer,使用 270B token 进行训练,随后进行长文本适配训练。
- 结果表明,相比 Full Attention,NSA 训练损失更低,收敛更平滑。
2)基准测试
在知识、推理和代码任务(如 MMLU、GSM8K、HumanEval)中,NSA 在大多数指标上优于全注意力模型。
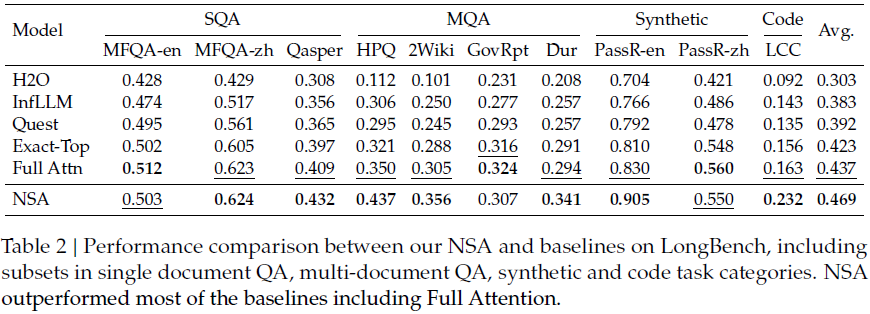
3)长文本任务
在 64k-context 任务(如 LongBench)中,NSA 超过 Full Attention 模型,同时超越所有现有稀疏注意力方法。
在 needle-in-a-haystack 测试中,NSA 在全长 64k 语境中实现 100% 准确率。
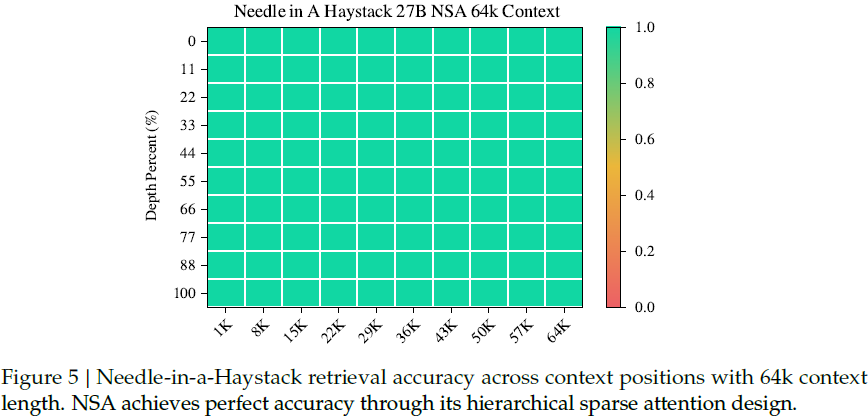
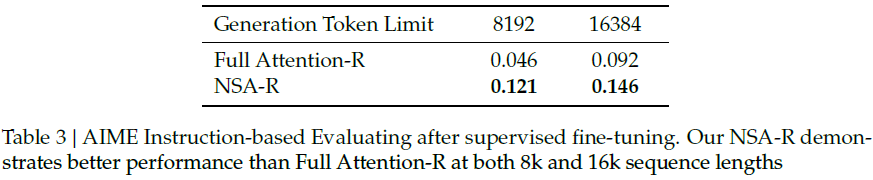
4)链式推理
在数学推理任务(AIME 24)中,经过监督微调的 NSA-R 在 8k 和 16k 生成长度下均超越 Full Attention-R,表明其能够高效学习逻辑推理能力。
5. 效率分析
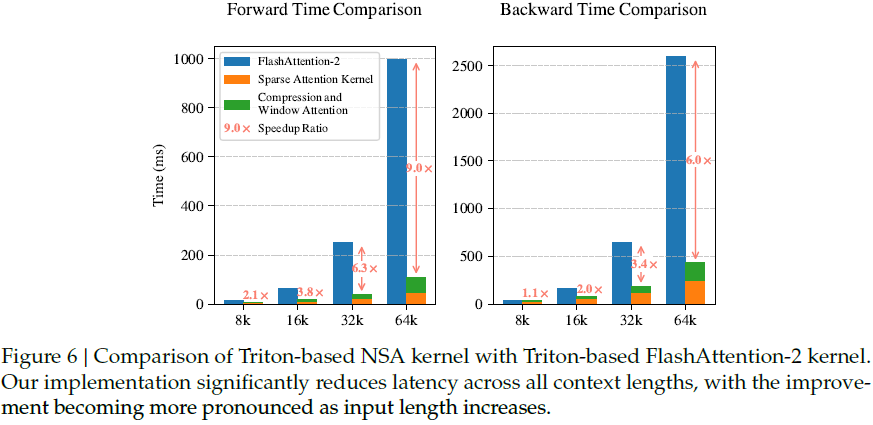
NSA 在8-GPU A100 服务器上的效率测试表明:
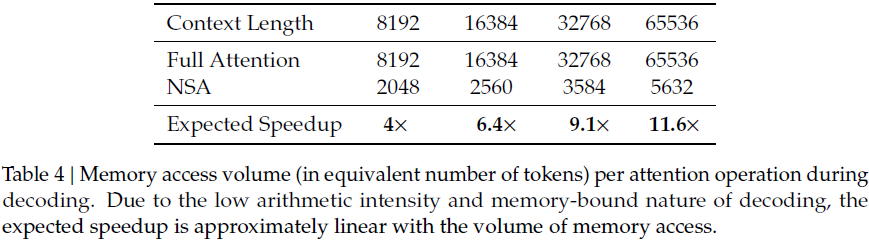
- 训练速度:在 64k 序列下,NSA 前向传播加速 9.0×,反向传播加速 6.0×。
- 解码速度:由于解码受 KV 访问限制,NSA 在64k 长度下实现 11.6× 加速。
6. 讨论
为什么选择块级选择?
- 实验表明,基于块的选择比单 token 选择更高效,且更易于 GPU 优化。
- 现有方法(如 Quest, InfLLM)在训练时存在性能下降问题,而 NSA 的选择策略确保了模型性能不受影响。
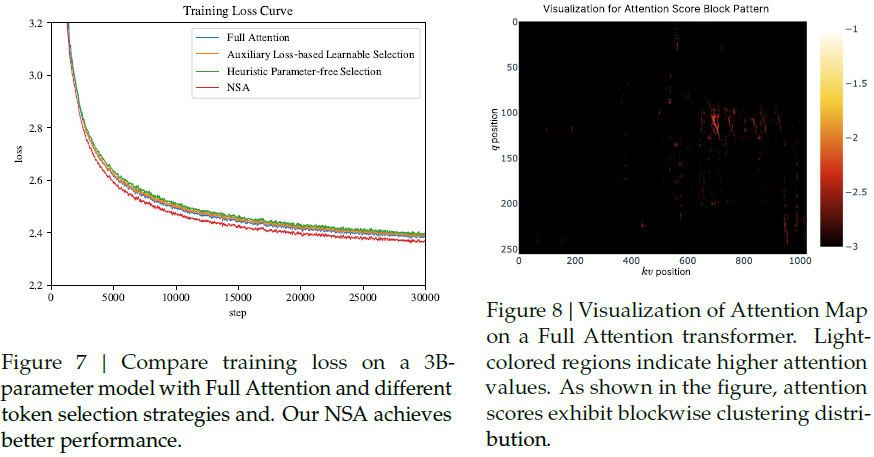
可视化:可视化分析表明,注意力模式呈现块级聚类特性,这支持了 NSA 的设计选择。
7. 相关工作
本文对比了三类稀疏注意力方法:
- 固定稀疏模式(如 SlidingWindow)——计算效率高,但上下文感知能力有限。
- 动态 token 剪枝(如 H2O, SnapKV)——能够减少 KV 缓存,但无法高效训练。
- 基于查询选择(如 Quest, ClusterKV)——通常难以优化,或者计算成本过高。
NSA 结合了固定模式的高效性、动态剪枝的适应性和查询选择的灵活性,以优化稀疏注意力。
论文地址:https://arxiv.org/abs/2502.11089
进 Q 学术交流群:922230617 或加 V:CV_EDPJ 进 V 交流群

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)