深度学习笔记3-机器学习基础(续1)
梯度下降法在直线搜索时可能会遇到学习率选择困难、局部最优、梯度消失或爆炸、震荡等问题。这些问题在高维非凸优化问题(如深度学习)中尤为突出。通过改进优化算法、调整学习率策略和初始化方法,可以有效缓解这些问题,提升梯度下降法的性能。------来自Deepseek回答。
2.6 梯度下降法
梯度下降法(Gradient Descent,GD)是一个最优化算法,常用于机器学习中的递归性逼近,通过求目标函数导数来获取最小值偏差的方法;如果是为了获取最大值,就相应地采用梯度上升法,两者是可以相互转化的。梯度下降法不一定能够找到全局最优解,有可能结果只是一个局部最优解。
其核心思想可以归纳为:
1)初始化参数,初始值可随机选取在取值范围内的任意值。
2)迭代,计算当前梯度(求导),更新参数,代入计算,判断误差是否终止,不终止则返回到第二步计算梯度,一直重复直到程序达到设定的终止条件。
3)得到全局最优解或者接近全局最优解。
以一个简单的线性回归模型,目标函数,其中
是模型的参数:
其中是模型的预测函数。
是样本数量。
和
是第i个样本的输入和输出,也就是实际值和预测值。
初始化我们的参数为:
计算梯度:目标函数对和
的偏导数
更新参数:
其中是学习率,也就是算法迭代步长。
重复上述步骤,直到目标函数收敛或者达到设定的终止条件(迭代次数或者最小误差)。
import numpy as np
import matplotlib.pyplot as plt
# 生成100个随机数据点
np.random.seed(42) # 设置随机种子以确保结果可重复
X = np.random.rand(100) * 10 # 生成100个在[0, 10)范围内的随机数作为X
y = 2 * X + 1 + np.random.randn(100) * 2 # 生成y = 2X + 1 + 噪声
# 初始化参数
theta0 = 0
theta1 = 0
# 学习率和迭代次数
alpha = 0.01
iterations = 1000
# 梯度下降算法
for i in range(iterations):
# 预测值
y_pred = theta0 + theta1 * X
# 计算梯度
d_theta0 = (1/len(X)) * np.sum(y_pred - y)
d_theta1 = (1/len(X)) * np.sum((y_pred - y) * X)
# 更新参数
theta0 = theta0 - alpha * d_theta0
theta1 = theta1 - alpha * d_theta1
# 每100次迭代打印一次损失函数值(可选)
if i % 100 == 0:
loss = (1/(2*len(X))) * np.sum((y_pred - y)**2)
print(f"Iteration {i}: Loss = {loss:.4f}, theta0 = {theta0:.4f}, theta1 = {theta1:.4f}")
# 输出最终参数
print(f"Final parameters: theta0 = {theta0:.4f}, theta1 = {theta1:.4f}")
# 绘制数据和拟合的直线
plt.scatter(X, y, label="Training Data")
plt.plot(X, theta0 + theta1 * X, color='red', label="Fitted Line")
plt.xlabel("X")
plt.ylabel("y")
plt.title("Linear Regression with Gradient Descent")
plt.legend()
plt.show()运行结果如下图:
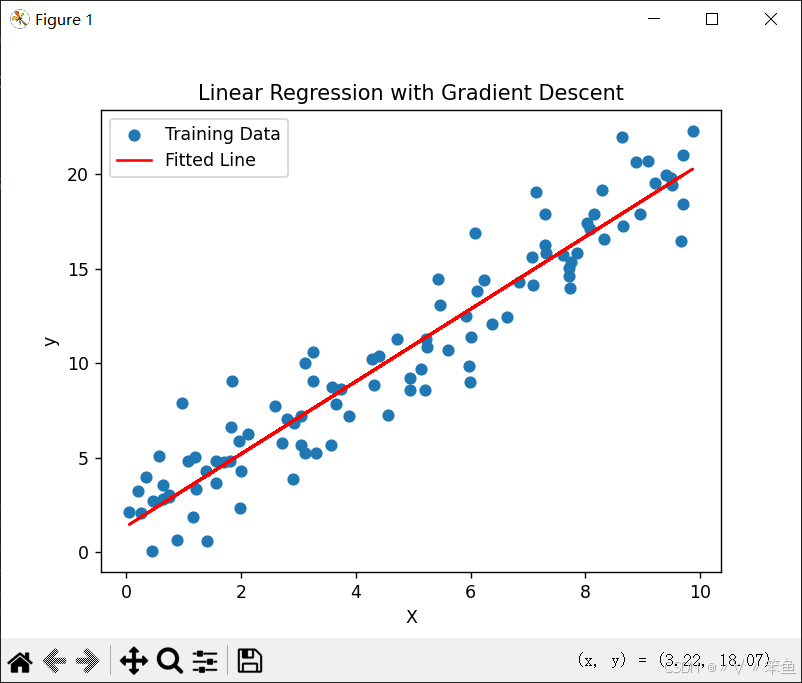
梯度下降法的存在的问题:
1. 学习率选择困难
-
问题:梯度下降法的性能高度依赖于学习率(步长)α 的选择。如果学习率太小,收敛速度会非常慢;如果学习率太大,可能会导致算法发散(即损失函数值震荡甚至无限增大)。
-
原因:直线搜索的目标是找到一个合适的学习率,使得每次迭代后损失函数值能够显著下降。然而,学习率的选择通常需要经验或试错,缺乏理论上的通用规则。
-
示例:如果学习率过大,梯度下降可能会“跳过”最优解,导致损失函数值在最小值附近震荡。
2. 非凸函数的局部最优
-
问题:当损失函数是非凸函数时,梯度下降法可能会收敛到局部最优解,而不是全局最优解。
-
原因:梯度下降法是一种贪心算法,每次迭代都沿着当前点的梯度方向下降。如果损失函数有多个局部最小值,算法可能会被困在其中一个局部最小值中。
-
示例:在高维非凸优化问题中(如神经网络的训练),梯度下降法容易陷入局部最优。
3. 梯度消失或梯度爆炸
-
问题:在深度学习中,梯度下降法可能会遇到梯度消失(Gradient Vanishing)或梯度爆炸(Gradient Explosion)问题。
-
原因:
-
梯度消失:当梯度的值非常小(接近于0)时,参数更新几乎停滞,导致训练速度极慢。
-
梯度爆炸:当梯度的值非常大时,参数更新会变得不稳定,导致算法发散。
-
-
示例:在深层神经网络中,反向传播时梯度可能会因为链式法则的连乘而变得非常小或非常大。
4. 震荡现象
-
问题:梯度下降法在优化过程中可能会出现震荡现象,即损失函数值在最小值附近来回波动,无法稳定收敛。
-
原因:
-
学习率过大。
-
损失函数的等高线呈狭长形(即条件数较大),导致梯度方向变化剧烈。
-
-
示例:在优化狭长的山谷形函数时,梯度下降法可能会在山谷两侧来回震荡,收敛速度很慢。
5. 对初始值敏感
-
问题:梯度下降法的结果可能对初始参数值非常敏感。
-
原因:不同的初始值可能会导致算法收敛到不同的局部最优解。
-
示例:在非凸优化问题中,初始值的选择可能会显著影响最终结果。
6. 高维空间中的“鞍点”问题
-
问题:在高维空间中,梯度下降法可能会遇到“鞍点”(Saddle Point),即梯度为零但既不是局部最小值也不是局部最大值的点。
-
原因:在高维空间中,鞍点比局部最小值更常见。梯度下降法可能会在鞍点附近停滞,导致训练速度变慢。
-
示例:在神经网络的训练中,鞍点是梯度下降法面临的主要挑战之一。
7. 直线搜索的计算开销
-
问题:精确的直线搜索(如找到使损失函数最小的最优学习率)通常需要多次函数评估,计算开销较大。
-
原因:每次迭代都需要计算损失函数的值,而精确搜索可能需要多次尝试不同的学习率。
-
示例:在实际应用中,通常使用固定的学习率或简单的启发式方法(如学习率衰减)来避免高昂的计算开销。
解决方法
为了缓解上述问题,可以采取以下改进措施:
-
自适应学习率:使用自适应优化算法(如Adam、RMSProp等),动态调整学习率。
-
动量法:引入动量(Momentum)来加速收敛并减少震荡。
-
学习率衰减:随着迭代次数的增加,逐渐减小学习率。
-
二阶优化方法:使用牛顿法或拟牛顿法(如L-BFGS)来利用二阶导数信息,加速收敛。
-
随机梯度下降(SGD):在小批量数据上计算梯度,减少计算开销并避免陷入局部最优。
-
初始化策略:使用更好的参数初始化方法(如Xavier初始化或He初始化)来避免梯度消失或爆炸。
总结
梯度下降法在直线搜索时可能会遇到学习率选择困难、局部最优、梯度消失或爆炸、震荡等问题。这些问题在高维非凸优化问题(如深度学习)中尤为突出。通过改进优化算法、调整学习率策略和初始化方法,可以有效缓解这些问题,提升梯度下降法的性能。
------来自Deepseek回答
2.7 线性判别分析
线性判别分析(Linear Discriminat Analysis,LDA)是一种监督学习的降维技术,数据集的每个样本都有类别输出。其核心思想是:通过将多维数据投影到一条直线上,将高维数据转化为一维数据。目标是让同类数据的投影点尽可能接近(类内方差最小),异类数据尽可能远离(类间方差最大),从而提高分类器的性能。
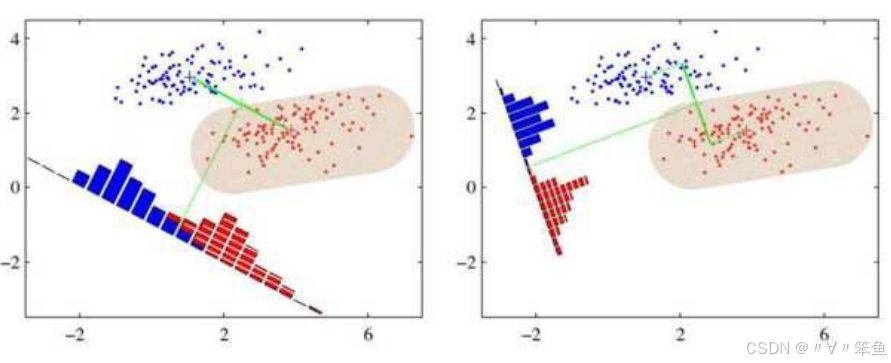
如上图所示:
-
假设有两类(蓝色和红色点云)二维数据,LDA的目标是将这些数据投影到一维空间。
-
左图展示了一种投影方式:让不同类别的平均点距离最远。
-
右图展示了另一种投影方式:让同类别的数据点尽可能接近。
-
右图的投影效果更好,因为同类数据更集中,异类数据更分散。
如果原始数据是多维的,LDA投影是一个低维的超平面,而不是直线。
1、LDA的数学原理
推导基于以下两个关键概念:
1)类内散度矩阵(Within-class scatter matrix):
衡量同一类别内数据的分散程度。对于第类,类内散度矩阵为:
其中,是第
类的均值向量。总的类内散度矩阵是所有类别的类内散度矩阵之和:
其中,是类别数。
2) 类间散度矩阵(Between-class scatter matrix)
衡量不同类别之间的分散程度,类间散度矩阵定义为:
其中,是所有数据的全局均值向量,
是第
类的样本数。
LDA的目标是找到一个投影方向 \(w\),使得投影后的类间散度与类内散度的比值最大化:
这个比值被称为Fisher准则。通过最大化 ,可以找到最优的投影方向。
2、LDA的求解过程
LDA的求解过程可以总结为以下步骤:
1. 计算每个类别的均值向量和全局均值向量
。
2. 计算类内散度矩阵和类间散度矩阵
。
3. 求解广义特征值问题:
其中,是特征值,
是特征向量。
4. 选择前 个最大的特征值对应的特征向量,构成投影矩阵
。
5. 将原始数据投影到低维空间:
其中,是原始数据,
是降维后的数据。
3、LDA的优缺点
优点:- LDA是一种监督学习方法,能够利用类别信息,因此在分类任务中通常比无监督方法(如主成分分析,Principal Component Analysis,PCA)更有效。
- 降维后的数据保留了类别之间的区分性,适合用于分类任务。
- 计算效率高,适合处理高维数据。
缺点:- LDA假设数据服从高斯分布,且各类别的协方差矩阵相同。如果这些假设不成立,LDA的效果可能会变差。
- LDA最多只能将数据降到 维,其中
是类别数。例如,对于二分类问题,LDA只能将数据降到一维。
- 对于非线性可分的数据,LDA的效果可能不如其他非线性降维方法(如核方法)。
4、LDA与PCA的区别
线性判别分析(LDA)与主成分分析(PCA)的主要区别在于目标、适用场景和数学原理。PCA是一种无监督学习方法,目标是最大化投影后的方差,从而保留数据的主要信息,适用于无标签数据的降维,常用于数据压缩和可视化;而LDA是一种监督学习方法,目标是最大化类间差异并最小化类内差异,从而保留分类信息,适用于有标签数据的降维,常用于分类任务。在数学原理上,PCA基于协方差矩阵的特征值分解,而LDA则基于类内散度矩阵和类间散度矩阵的广义特征值分解。
5、LDA扩展与改进
线性判别分析(LDA)的扩展与改进包括多类LDA、核LDA和正则化LDA。多类LDA通过选择多个投影方向(特征向量)来处理类别数的情况,从而实现降维;核LDA则通过核方法将非线性可分的数据映射到高维空间,并在高维空间中应用LDA以处理复杂的非线性问题;正则化LDA通过加入一个小的对角矩阵来稳定求解过程,解决类内散度矩阵
不可逆的问题,从而提高算法的鲁棒性。这些扩展和改进使LDA能够适应更多样化的数据场景和需求。
线性判别分析(LDA)在多个领域有广泛应用,包括模式识别(如人脸识别、语音识别)、生物信息学(如基因表达数据的分类)、文本分类(如新闻分类、情感分析)以及数据可视化(将高维数据降到2D或3D进行可视化)。此外,LDA与逻辑回归都是线性分类方法,但LDA假设数据服从高斯分布,而逻辑回归没有这种假设;同时,LDA与二次判别分析(QDA)也有区别,QDA是LDA的扩展,假设各类别的协方差矩阵可以不同,因此能够处理更复杂的数据分布。这些特点使得LDA在不同场景中具有灵活性和实用性。
2.8 主成分分析
主成分分析(Principal Component Analysis,PCA)是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫作主成分,各主成分之间互不相关(即具有正交性)。用以解决训练数据中可能存在的特征过多或者特征累赘的问题,将高维数据投影到低维空间,保留数据的主要特征。
算法流程:
1)数据标准化:
对数据进行标准化处理,使各特征均值为0,方差为1。
其中,是均值,
是标准差。
2)计算协方差矩阵:
计算标准化数据的协方差矩阵,反映特征间的线性关系。
3)特征值分解:
对协方差矩阵进行特征值分解,得到特征值和特征向量。
其中,是特征向量矩阵,
是特征值对角矩阵。
4)选择主成分:
按特征值大小排序,选择前k个最大特征值对应的特征向量作为主成分。
5)数据投影:
将原始数据投影到选定的主成分上,得到降维后的数据。
其中,是前
个特征向量组成的矩阵。
降维的必要性及目的
降维是数据预处理中的重要步骤,旨在减少数据集的特征数量,同时保留关键信息。降维的必要性在于解决高维数据带来的多重共线性、稀疏性、冗余性和复杂性等问题;而降维的目的则是简化数据结构、提高计算效率、增强模型解释性,并去除噪声。通过降维,可以在保留数据关键信息的同时,显著提升数据分析的效果和效率。
降维的必要性
1. 避免多重共线性和预测变量之间的关联:
- 多重共线性会导致模型解空间不稳定,影响结果的可靠性。
- 降维可以减少变量间的相关性,提升模型的稳定性和解释性。
2. 高维空间的稀疏性:
- 在高维空间中,数据分布往往稀疏,导致样本之间的距离难以有效衡量。
- 例如,一维正态分布有68%的值落在正负标准差之间,而在十维空间中,这一比例仅为2%。
3. 减少冗余变量:
- 过多的变量会增加数据复杂性,可能掩盖真正的规律。
- 降维可以去除冗余变量,简化数据结构。
4. 发现变量间的潜在联系:
- 在变量层面上分析可能忽略变量之间的内在关系。
- 降维可以将多个相关变量组合成少数几个综合变量,反映数据的本质特征。
降维的目的
1. 减少预测变量的数量:
- 降低数据维度,简化模型结构,提高计算效率。
2. 确保变量独立性:
- 降维后的变量通常相互独立,避免多重共线性问题。
3. 提供解释框架:
- 降维后的特征更能反映数据的关键信息,便于结果解释。
- 低维数据(如二维或三维)更易于可视化展示。
4. 简化数据处理:
- 低维数据更容易处理和分析,降低计算复杂度。
5. 去除噪声*:
- 降维可以过滤掉不重要的特征,减少噪声对模型的影响。
6. 低算法运算开销:
- 减少特征数量可以显著降低算法的计算成本,提高效率。
补充内容
降维不仅是数据预处理的重要步骤,也是数据分析和机器学习中的核心技术之一。通过降维,可以解决高维数据带来的诸多问题,同时提升模型的性能和可解释性。然而,降维也需要谨慎使用,避免信息丢失和过拟合风险。在实际应用中,结合具体问题和数据特点选择合适的降维方法,才能最大化其价值。
1. 降维的适用场景
高维数据可视化:
- 当数据维度超过3维时,直接可视化变得困难。降维(如PCA、t-SNE、UMAP)可以将数据降至2维或3维,便于直观展示和分析。
特征工程:
- 在机器学习中,降维可以作为特征工程的一部分,提取更有意义的特征,提升模型性能。
数据压缩:
- 降维可以减少存储空间和计算资源的需求,特别适用于大规模数据集。
2. 降维方法的分类
线性降维:
- 如主成分分析(PCA)、线性判别分析(LDA),适用于线性结构的数据。
非线性降维:
- 如t-SNE、UMAP、ISOMAP,适用于非线性结构的数据。
基于特征选择的降维:
- 通过选择重要特征(如基于统计检验、模型权重)来减少维度。
基于特征提取的降维:
- 通过构造新的特征(如PCA的主成分)来替代原始特征。
3. 降维的潜在风险
信息丢失:
- 降维可能会丢失部分信息,尤其是在选择过低维度时。
解释性下降:
- 降维后的特征可能是原始特征的线性或非线性组合,难以直接解释其物理意义。
过拟合风险:
- 在某些情况下,降维可能会过度简化数据,导致模型在训练集上表现良好,但在测试集上表现不佳。
4. 降维与其他技术的关系
与聚类分析结合:
- 降维可以简化数据,使聚类算法更高效地发现数据的内在结构。
与分类/回归模型结合:
- 降维可以减少特征数量,降低模型复杂度,同时提高泛化能力。
与深度学习结合:
- 在深度学习中,降维可以用于预处理数据或提取中间层特征。
5. 实际应用中的注意事项
数据标准化:
- 在降维前,通常需要对数据进行标准化处理,以避免某些特征因量纲不同而主导降维结果。
维度选择:
- 如何选择合适的维度是一个关键问题,可以通过累计方差贡献率(PCA)、特征值大小等方法确定。
2.9 模型评估
1、常用方法
模型评估是机器学习和数据分析中的关键步骤,用于衡量模型的性能和泛化能力。模型评估方法因任务类型(分类、回归、聚类)而异,常用的评估指标包括准确率、精确率、召回率、F1分数、MSE、MAE、R²、轮廓系数等。交叉验证和学习曲线等方法则用于全面评估模型的泛化能力。选择合适的评估方法,可以更好地理解模型性能并指导模型优化。
常用的模型评估方法可以分为以下几类:
1. 分类模型的评估方法
1)混淆矩阵(Confusion Matrix)
- 用于二分类或多分类问题,展示模型的预测结果与实际结果的对比。
- 关键指标:
- 真正例(True Positive, TP):实际为正,预测为正。
- 假正例(False Positive, FP):实际为负,预测为正。
- 真负例(True Negative, TN):实际为负,预测为负。
- 假负例(False Negative, FN):实际为正,预测为负。
2)准确率(Accuracy)
- 预测正确的样本占总样本的比例。
- 公式:
- 适用于类别均衡的数据集。
3)精确率(Precision)
- 预测为正的样本中,实际为正的比例。
- 公式:
- 适用于关注假正例的场景(如垃圾邮件检测)。
4)召回率(Recall)
- 实际为正的样本中,预测为正的比例。
- 公式:
- 适用于关注假负例的场景(如疾病诊断)。
5)F1分数(F1 Score)
- 精确率和召回率的调和平均值,综合衡量模型性能。
- 公式:
- 适用于类别不均衡的数据集。
6)ROC曲线与AUC值
- ROC曲线:以假正率(FPR)为横轴,真正率(TPR)为纵轴绘制的曲线。
- AUC值:ROC曲线下的面积,用于衡量分类器的整体性能。
- AUC值越接近1,模型性能越好。
7)对数损失(Log Loss)
- 用于评估分类模型的概率输出,衡量预测概率与真实标签的差异。
- 公式:
- 其中,是真实标签,
是预测概率。
2. 回归模型的评估方法
1)均方误差(Mean Squared Error, MSE)
- 预测值与真实值之间差异的平方的平均值。
- 公式:
- 对异常值敏感。
2)均方根误差(Root Mean Squared Error, RMSE)
- MSE的平方根,与目标变量量纲一致。
- 公式:
3)平均绝对误差(Mean Absolute Error, MAE)
- 预测值与真实值之间绝对差异的平均值。
- 公式:
- 对异常值不敏感。
4)R²(决定系数)
- 衡量模型对目标变量方差的解释程度。
- 公式:
- 其中,是目标变量的均值。
- 取值范围为 (- ,1],越接近1,模型性能越好。
3. 聚类模型的评估方法
1)轮廓系数(Silhouette Coefficient)
- 衡量聚类结果的紧密度和分离度。
- 公式:
- 其中,是样本与同簇其他样本的平均距离,
是样本与最近其他簇的平均距离。
- 取值范围为[-1,1],值越大表示聚类效果越好。
2)Calinski-Harabasz指数
- 衡量簇间分离度与簇内紧密度的比值。
- 值越大,聚类效果越好。
3)Davies-Bouldin指数
- 衡量簇内紧密度和簇间分离度的比值。
- 值越小,聚类效果越好。
4. 交叉验证(Cross-Validation)
- 将数据集划分为多个子集,轮流使用其中一部分作为验证集,其余作为训练集。
- 常用方法:
- K折交叉验证(K-Fold Cross-Validation)
- 留一法交叉验证(Leave-One-Out Cross-Validation)
5. 其他评估方法
- 学习曲线:分析模型在训练集和验证集上的表现,判断是否过拟合或欠拟合。
- 偏差-方差分解:衡量模型的偏差和方差,分析模型的泛化能力。
- 特征重要性分析:评估特征对模型预测的贡献。
2、误差、偏差和方差的区别和联系
在机器学习中,误差(Error)、偏差(Bias)和方差(Variance)存在以下区别和联系。
误差:一般我们把学习器的实际预测输出与样本真实值之间的差异称为“误差”。误差=偏差+方差+噪声,误差反映的是整个模型的准确度。
偏差:用于衡量模型拟合训练数据的能力,偏差反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精度。偏差越小,拟合能力越强(可能产生过拟合);反之,拟合能力越差(可能产生欠拟合)。偏差越大,越偏离真实数据。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据分布地越分散,模型的稳定成都越差。方差反映的是模型每一次的输出结果与模型输出期望之间的误差,即模型稳定性。反差越小,模型的泛化能力越强;反之,模型的泛化能力越差。
如果模型在训练集上的你和效果比较好,而在训练集上的你和效果比较差,则方差较大,说明模型的稳定程度较差,出现这种现象可能是由于对训练集过拟合。
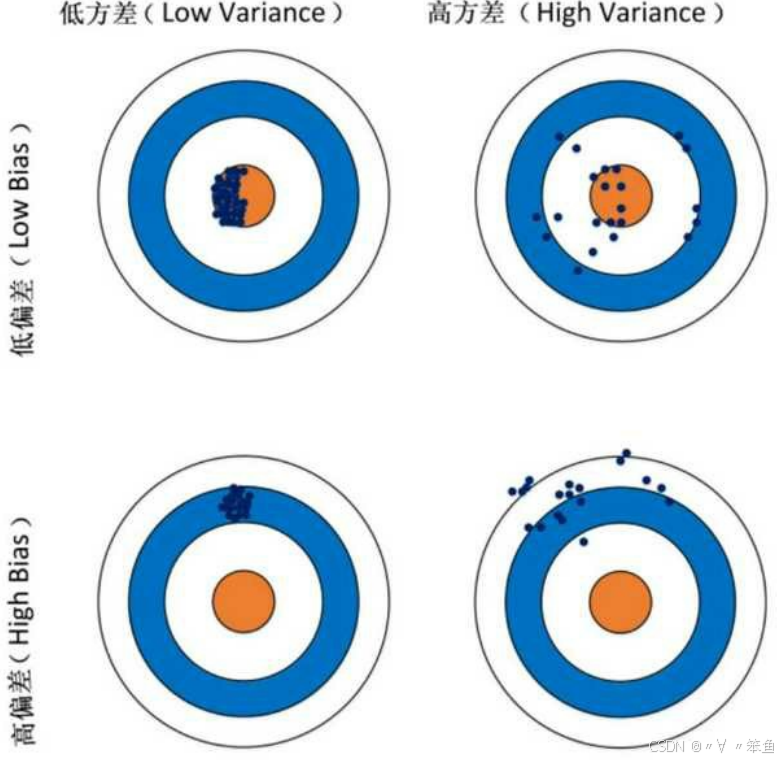
2、方差与标准差
方差和标准差是衡量数据离散程度的常用指标。以下是它们的计算公式:
样本方差(Variance):
样本标准差(Standard Deviation) :
其中,是样本数据个数,
是第
个数据点,
是样本均值。
如果时求总体的方差和标准差,则表示总体均值,且将
改为
即可。样本方差除以n-1而不是n的原因是为了进行无偏估计,为了纠正使用样本均值代替总体均值时引入的误差。总体均值是整个数据集总体数据的平均值,而样本均值是抽取出来的样本数据的均值,一般少于总体数量。
经验误差(Empirical Error)也叫训练误差,是模型在训练集上的误差。
泛化误差(Generalization Error)是模型在新样本集(测试集)上的误差。
模型欠拟合:在训练集和测试集上均有较大误差,模型偏差较大。
模型过拟合:在训练集上误差较小,在测试集上误差较大,模型方差较大。
交叉验证(Cross Validation):在给定的模型样本中,拿出大部分用以训练,留一小部分用于训练后的模型的预测,并求这小部分预测误差,记录他们的平方加权和。交叉验证的作用是为了得到更为文件可靠的模型,对模型的泛化误差进行评估,得到模型泛化误差的近似值。
折交叉验证:在训练数据过程中,当数据量不够大时,
折就是将数据集切分成
份,选择其中一份作为测试集,另外
-1份作为训练集,没训练和测试一次,交换测试集,用
次的结果来得到模型的最终平均泛化误差。
ROC全称受试者工作特征(Receiver Operating Characteristic),通过对俩对连续变量设置多个不同的临界值,从而计算一系列正例率(TPR)和假正例率(FPR),曲线下面积AUC(Area Under Curve)越大,推断准确性越高。
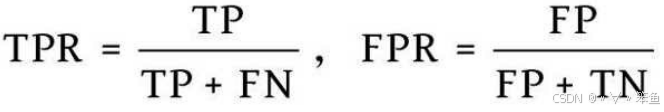
绘制ROC曲线示例:
假设有如下表样本,输入标签P代表正例,N代表负例。按照输出分数大小排序,选择不同的阈值对Score值进行划分。比如选择阈值为0.5时,大于或等于输出分数大于0.5的为正例,小于的则为负例,以此来计算TPR和FPR,并作为ROC曲线的纵轴和横轴坐标。
| 样本序号 | 输入标签 | 输出分数 | 样本序号 | 输入标签 | 输出标签 |
| 1 | P | 0.90 | 11 | P | 0.40 |
| 2 | P | 0.80 | 12 | N | 0.39 |
| 3 | N | 0.70 | 13 | P | 0.38 |
| 4 | P | 0.60 | 14 | N | 0.37 |
| 5 | P | 0.55 | 15 | N | 0.36 |
| 6 | P | 0.54 | 16 | N | 0.35 |
| 7 | N | 0.53 | 17 | P | 0.34 |
| 8 | N | 0.52 | 18 | N | 0.33 |
| 9 | P | 0.51 | 19 | P | 0.30 |
| 10 | N | 0.50 | 20 | N | 0.10 |
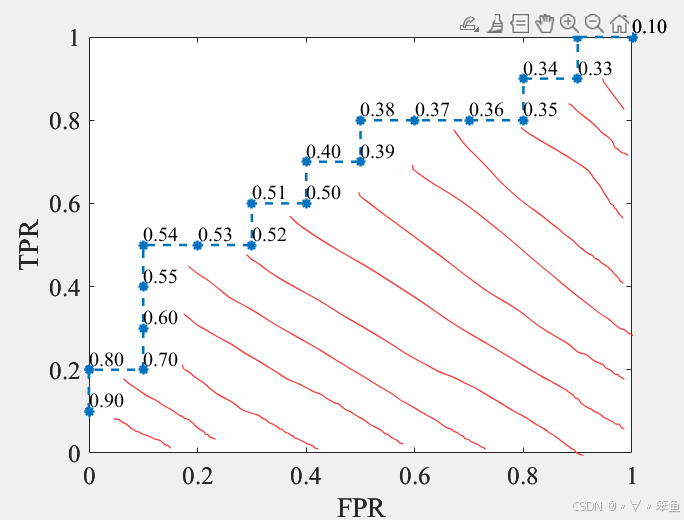
AUC就是红色斜线部分的面积。ROC曲线随着样本序号排序的变化而发生变化,但是AUC的值不会随着测试样本的排序发生变化,即所围成的面积与训练集的总体有关,而与数据的顺序无关。
2.10 决策树
决策树是一种分而治之的方法,将一个困难的预测问题,通过树的分支节点,不断地划分为两个或多个较为简单的子集。随着树深度的不断增加,所需要提的问题也逐渐简化。每个内部节点代表一个特征或属性的判断,每个分支代表一个可能的判断结果,而每个叶节点则代表最终的分类或回归结果。决策树的构建过程是从根节点开始,递归地选择最优特征进行分割,直到满足停止条件(如节点纯度达到一定标准或达到最大深度),这就是自上而下的停止阈值(Cutoff Threshold)法,有些也可以采用自下而上的剪枝(Pruning)法。例如,在判断一个人是否会购买某产品时,决策树可能会根据年龄、收入、性别等特征逐步划分,最终得出“购买”或“不购买”的结论。
熵是信息论中衡量不确定性的指标,决策树在构建过程中使用熵来选择最优分割特征。熵越大,表示数据的不确定性越高;熵越小,表示数据的纯度越高。决策树的目标是通过选择特征分割,使得分割后的子集熵最小化,从而提高分类的准确性。例如,在判断天气是否适合户外活动时,如果根据“湿度”特征分割后,子集的熵显著降低(如“高湿度”子集大多数情况下不适合活动),则“湿度”是一个有效的分割特征。通过不断选择使熵最小化的特征,决策树能够逐步提高分类的准确性。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 58
58 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)