【AI】—— DeepSeek 核心技术大揭秘
一文了解deepseek的核心知识点
1. 知识点补充
1.1. DeepSeek V3和R1 关系
- DeepSeek-V3
- V3 是 Version 3 的缩写,表示这是 DeepSeek 系列的第三个版本。
- DeepSeek-V3 是一个混合专家模型(MoE),专注于提供通用的基础模型架构和预训练权重,适用于多种自然语言处理任务。
- V3 的含义:
- V 代表 Version(版本)。
- 3 代表这是第三个版本。 - DeepSeek-R1
- R1 是 Reasoning 1 的缩写,表示这是 DeepSeek 系列中专注于推理能力的第一个版本。
- DeepSeek-R1 是基于 DeepSeek-V3 的进一步优化,通过强化学习(RL)和蒸馏技术提升推理能力。
- R1 的含义:
- R 代表 Reasoning(推理)。
- 1 代表这是第一个专注于推理的版本。 - 总结
- V3 表示 Version 3,是 DeepSeek 系列的第三个版本,提供通用的基础模型。
- R1 表示 Reasoning 1,是 DeepSeek 系列中专注于推理能力的第一个版本。
通过这种命名方式,DeepSeek 清晰地划分了模型的版本和功能定位:
- V3 提供通用的基础能力。
- R1 在 V3 的基础上,专注于推理任务的优化。
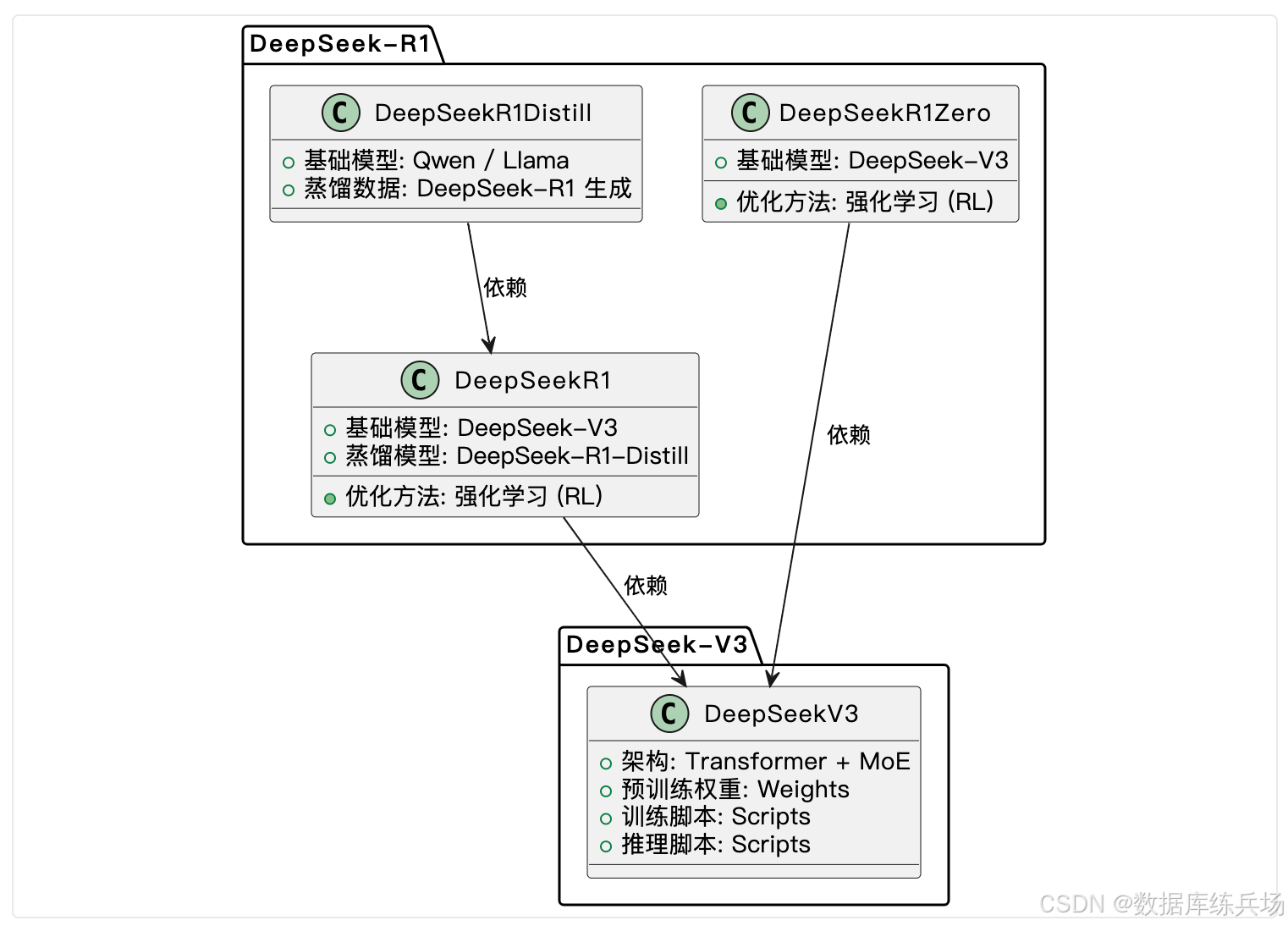
- DeepSeek-V3 是基础模型,提供了通用的模型架构和预训练权重。
- DeepSeek-R1 是基于 DeepSeek-V3 的进一步优化,专注于推理能力。
- DeepSeek-R1-Distill 是基于 DeepSeek-R1 的蒸馏模型,进一步提升了推理效率。
1.2. 什么是"模型蒸馏"
模型蒸馏(Knowledge Distillation)是一种知识迁移技术,旨在将复杂且高性能的教师模型知识,迁移至简单、小巧的学生模型。
教师模型如同知识渊博但需庞大资源支持的“学霸”,而学生模型则像是期望在资源有限条件下达到相似能力的“学神”。传统学生模型训练依赖“硬标签”,如同“死记硬背”。而模型蒸馏采用“软标签”,让学生模型学习教师模型的“解题思路”。例如,对于“2+2=?”的问题,硬标签直接给出答案“4”,软标签则会告知“3”和“5”也有一定可能性(概率较低),学生模型借此不仅学到答案,还掌握了教师模型的思考方式,泛化能力更强。模型蒸馏过程通常分为三步:首先训练强大的教师模型;接着教师模型对训练数据生成软标签,学生模型通过模仿软标签进行训练;最后学生模型成为轻量级且性能接近教师模型的存在。
在 DeepSeek-R1 训练过程中,研究人员通过知识蒸馏,让较小的模型也能具备较强的推理能力。例如,DeepSeek-R1-Distill-Qwen-32B 通过蒸馏学习到了 DeepSeek-R1 的推理模式,在多个基准测试上表现优异。
1.3. 什么是 AI 的“aha 时刻”?
在强化学习过程中,AI 的推理能力并不是线性增长的,而是会经历一些关键的“顿悟”时刻,研究人员将其称为“aha 时刻”。
这是 AI 在训练过程中突然学会了一种新的推理方式,或者能够主动发现并修正自己的错误,就像人类在学习时偶尔会有的“豁然开朗”时刻。
在 DeepSeek-R1 的训练过程中,研究人员观察到 AI 逐步形成了自我验证、自我反思、推理链优化等能力,这些能力的出现往往是非线性的,意味着 AI 在某个阶段突然学会了更高效的推理方法,而不是缓慢积累的过程。
1.4. 什么是“冷启动数据”?
在 AI 训练中,“冷启动”(Cold Start) 这个概念类似于刚买了一部新手机,开机后发现什么都没有,必须先安装应用、下载数据,才能正常使用。
DeepSeek-R1 的训练过程也类似,如果直接用强化学习(RL)进行训练,那么 AI 一开始就会像一个“什么都不会的孩子”,不断犯错,生成一堆毫无逻辑的答案,甚至可能陷入无意义的循环。
为了解决这个问题,研究人员提出了“冷启动数据”的概念,即在 AI 训练的早期阶段,先用一小批高质量的推理数据微调模型,相当于给 AI 提供一份“入门指南”。
冷启动数据的作用:
- 让 AI 训练更稳定:避免 AI 训练初期陷入“胡乱生成答案”的混乱状态。
- 提升推理质量:让 AI 在强化学习前就具备一定的推理能力,而不是完全从零开始。
- 改善语言表达:减少 AI 生成的语言混杂和重复内容,让推理过程更清晰、可读性更高。
1.5. MLA(Multi-Head Latent Attention)
在“attention”大一统的背景下,传统的多头注意力(MHA,Multi-Head Attention)的键值(KV)缓存机制事实上对计算效率形成了较大阻碍。缩小KV缓存(KV Cache)大小,并提高性能,在之前的模型架构中并未很好的解决。DeepSeek引入了MLA,一种通过低秩键值联合压缩的注意力机制,在显著减小KV缓存的同时提高计算效率。低秩近似是快速矩阵计算的常用方法,在MLA之前很少用于大模型计算。在这里我们可以看到DeepSeek团队的量化金融基因在发挥关键作用。当然实现潜空间表征不止低秩近似一条路,预计后面会有更精准高效的方法。
从大模型架构的演进情况来看,Prefill和KV Cache容量瓶颈的问题正一步步被新的模型架构攻克,巨大的KV Cache正逐渐成为历史。(事实上在2024年6月发布DeepSeek-V2的时候就已经很好的降低了KV Cache的大小)
简单说:这是对传统注意力机制的升级。在处理像科研文献、长篇小说这样的长文本时,它能更精准地给句子、段落分配权重,找到文本的核心意思,不会像以前那样容易注意力分散。比如在机器翻译专业领域的长文档时,它能准确理解每个词在上下文中的意思,然后翻译成准确的目标语言。
1.6. 混合专家架构(MoE)
MoE架构就像是一个有很多专家的团队。每个专家都擅长处理某一类特定的任务。当模型收到一个任务,比如回答一个问题或者处理一段文本时,它会把这个任务分配给最擅长处理该任务的专家去做,而不是让所有的模块都来处理。比如DeepSeek-V2有2360亿总参数,但处理每个token时,仅210亿参数被激活;DeepSeek -V3总参数达6710亿,但每个输入只激活370亿参数。这样一来,就大大减少了不必要的计算量,让模型处理复杂任务时又快又灵活。
1.7. 基于Transformer架构
Transformer架构是DeepSeek的基础,它就像一个超级信息处理器,能处理各种顺序的信息,比如文字、语音等。它的核心是注意力机制,打个比方,我们在看一篇很长的文章时,会自动关注重要的部分,Transformer的注意力机制也能让模型在处理大量信息时,自动聚焦到关键内容上,理解信息之间的关系,不管这些信息是相隔很近还是很远。
1.8. 无辅助损失负载均衡
在MoE架构中,不同的专家模块可能会出现有的忙不过来,有的却很空闲的情况。无辅助损失负载均衡策略就是来解决这个问题的,它能让各个专家模块的工作负担更均匀,不会出现有的累坏了,有的却没事干的情况,这样能让整个模型的性能更好。
1.9. 多阶段训练和冷启动数据
DeepSeek-R1引入了多阶段训练和冷启动数据。多阶段训练就是在不同的阶段用不同的训练方法,就像我们学习时,小学、中学、大学的学习方法和重点都不一样。冷启动数据就是在模型开始学习前,给它一些高质量的数据,让它能更好地开始学习,就像我们在做一件事之前,先给一些提示和引导。
2. DeepSeek 核心技术揭秘
探索 DeepSeek V1~R1 卓越之处,为技术爱好者、专业人士和从业者提供使用指引,同时启发更多关于人工智能创新发展的思考与探索。























欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)