ollama+deepseek+RAG打造本地知识库

安装Ollama
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
Ollama 提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,使得机器学习不再是只有深度技术背景的开发者才能触及的领域。
Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。
官方下载 https://ollama.com/download
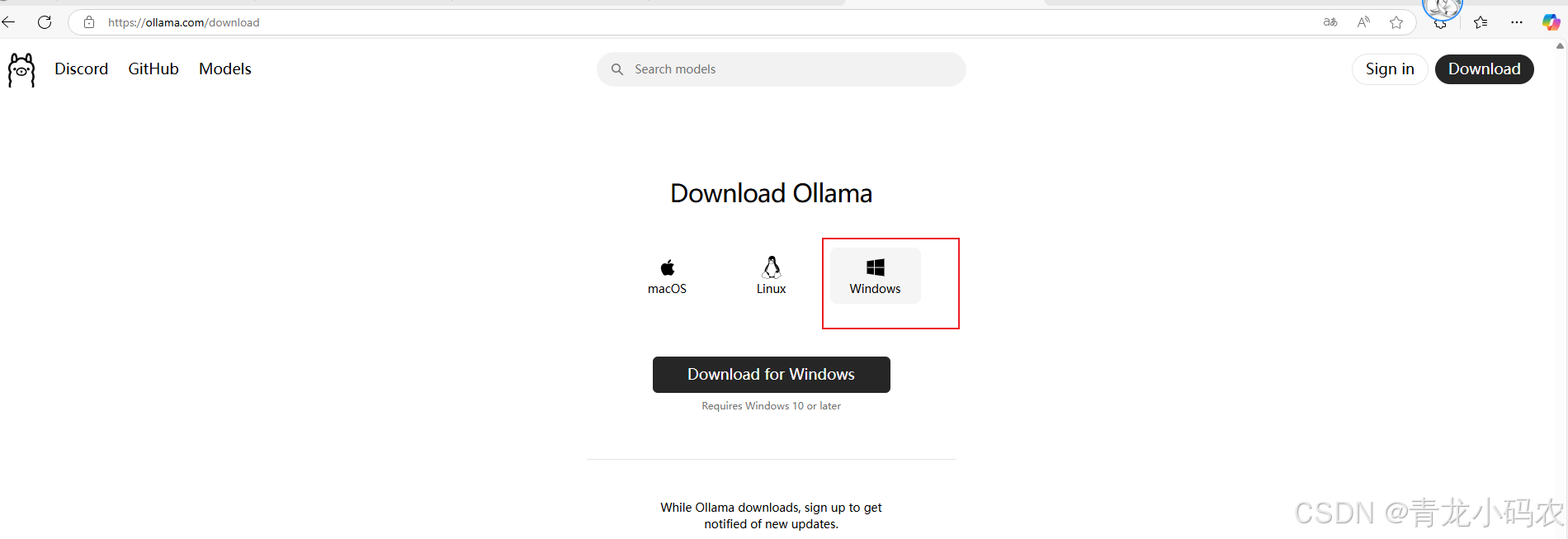
在电脑上看到 Ollama 的图标,双击打开即可(安装完成后默认是启动的):
本地安装 Ollama
安装位置:C:\Users\用户名\AppData\Local\Programs\Ollama
访问地址: http://localhost:11434
开启IP访问(增加系统变量):OLLAMA_HOST=0.0.0.0:11434

模型(Model)
在 Ollama 中,模型是核心组成部分。它们是经过预训练的机器学习模型,能够执行不同的任务,例如文本生成、文本摘要、情感分析、对话生成等。
Ollama 支持多种流行的预训练模型,常见的模型有:
- deepseek:深度求索提供的大型语言模型,专门用于文本生成任务。
- LLama2:Meta 提供的大型语言模型,专门用于文本生成任务。
- GPT:OpenAI 的 GPT 系列模型,适用于广泛的对话生成、文本推理等任务。
- BERT:用于句子理解和问答系统的预训练模型。
- 其他自定义模型:用户可以上传自己的自定义模型,并利用 Ollama 进行推理。
模型的主要功能:
- 推理(Inference):根据用户输入生成输出结果。
- 微调(Fine-tuning):用户可以在已有模型的基础上使用自己的数据进行训练,从而定制化模型以适应特定的任务或领域。
模型通常是由大量参数构成的神经网络,通过对大量文本数据进行训练,能够学习语言规律并进行高效的推理。
任务(Task)
Ollama 支持多种 NLP 任务。每个任务对应模型的不同应用场景,主要包括但不限于以下几种:
- 对话生成(Chat Generation):通过与用户交互生成自然的对话回复。
- 文本生成(Text Generation):根据给定的提示生成自然语言文本,例如写文章、生成故事等。
- 情感分析(Sentiment Analysis):分析给定文本的情感倾向(如正面、负面、中立)。
- 文本摘要(Text Summarization):将长文本压缩为简洁的摘要。
- 翻译(Translation):将文本从一种语言翻译成另一种语言。
通过命令行工具,用户可以指定不同的任务,并加载不同的模型来完成特定任务。
推理(Inference)
推理是指在已训练的模型上进行输入处理,生成输出的过程。
推理过程:
- 输入:用户向模型提供文本输入,可以是一个问题、提示或者对话内容。
- 模型处理:模型通过内置的神经网络根据输入生成适当的输出。
- 输出:模型返回生成的文本内容,可能是回复、生成的文章、翻译文本等。
微调(Fine-tuning)
微调是指在一个已预训练的模型上,基于特定的领域数据进行进一步的训练,以便使模型在特定任务或领域上表现得更好。
Ollama 支持微调功能,用户可以使用自己的数据集对预训练模型进行微调,来定制模型的输出。
微调过程:
- 准备数据集:用户准备特定领域的数据集,数据格式通常为文本文件或 JSON 格式。
- 加载预训练模型:选择一个适合微调的预训练模型,例如 LLama2 或 GPT 模型。
- 训练:使用用户的特定数据集对模型进行训练,使其能够更好地适应目标任务。
- 保存和部署:训练完成后,微调过的模型可以保存并部署,供以后使用。
下载Deepseek
| DeepSeek模型版本 | 参数量 | 特点 | 适用场景 | 硬件配置 |
|---|---|---|---|---|
| DeepSeek-R1-1.5B | 1.5B | 轻量级模型,参数量少,模型规模小 | 适用于轻量级任务,如短文本生成、基础问答等 | 4核处理器、8G内存,无需显卡 |
| DeepSeek-R1-7B | 7B | 平衡型模型,性能较好,硬件需求适中 | 适合中等复杂度任务,如文案撰写、表格处理、统计分析等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或更高 |
| DeepSeek-R1-8B | 8B | 性能略强于7B模型,适合更高精度需求 | 适合需要更高精度的轻量级任务,比如代码生成、逻辑推理等 | 8核处理器、16G内存,Ryzen7或更高,RTX 3060(12GB)或4060 |
| DeepSeek-R1-14B | 14B | 高性能模型,擅长复杂的任务,如数学推理、代码生成 | 可处理复杂任务,如长文本生成、数据分析等 | i9-13900K或更高、32G内存,RTX 4090(24GB)或A5000 |
| DeepSeek-R1-32B | 32B | 专业级模型,性能强大,适合高精度任务 | 适合超大规模任务,如语言建模、大规模训练、金融预测等 | Xeon 8核、128GB内存或更高,2-4张A100(80GB)或更高 |
| DeepSeek-R1-70B | 70B | 顶级模型,性能最强,适合大规模计算和高复杂任务 | 适合高精度专业领域任务,比如多模态任务预处理。这些任务对硬件要求非常高,需要高端的 CPU 和显卡,适合预算充足的企业或研究机构使用 | Xeon 8核、128GB内存或更高,8张A100/H100(80GB)或更高 |
| DeepSeek-R1-671B | 671B | 超大规模模型,性能卓越,推理速度快,适合极高精度需求 | 适合国家级 / 超大规模 AI 研究,如气候建模、基因组分析等,以及通用人工智能探索 | 64核、512GB或更高,8张A100/H100 |
打开电脑的终端命令行工具,输入命令 ollama run deepseek-r1:8b
#主要命令
运行(首次是安装,已经安装了就会运行):
ollama run deepseek-r1:8b
查看已经安装模型
ollama list
删除
ollama rm deepseek-r1:8b
停止
ollama stop deepseek-r1:8b
验证安装效果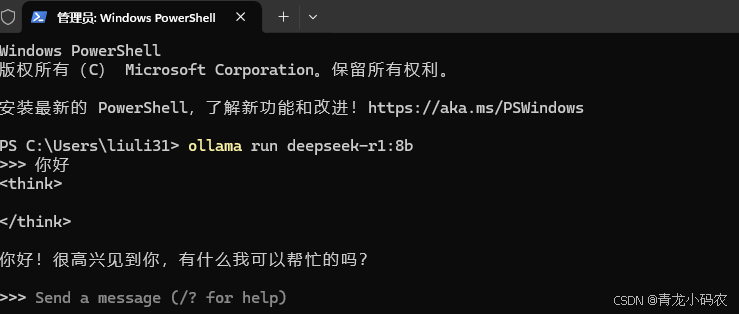
下载RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索技术和生成模型的方法,可以提升自然语言处理系统的性能。
简单的说,RAG可以将本地知识库中的内容进行处理,便于大语言模型使用。这里需要安装合适的嵌入模型,推荐以下两种模型。
| 模型名称 | 使用场景 | 安装命令 |
|---|---|---|
| nomic-embed-text | 功能强大的英文文本嵌入模型 | ollama pull nomic-embed-text |
| bge-m3 | 适用于多种高级自然语言处理任务 | ollama pull bge-m3 |
安装
客户端
Page Assist+本地知识库
谷歌浏览器 (需要有翻墙能力)
插件安装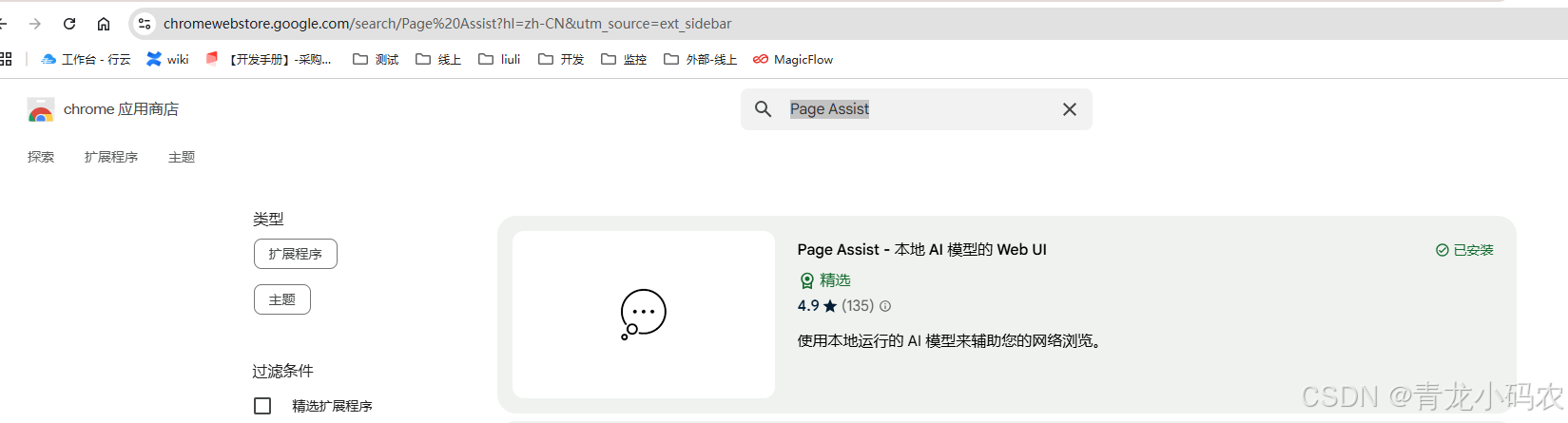
Ollama-deepseek配置
chrome-extension://jfgfiigpkhlkbnfnbobbkinehhfdhndo/options.html
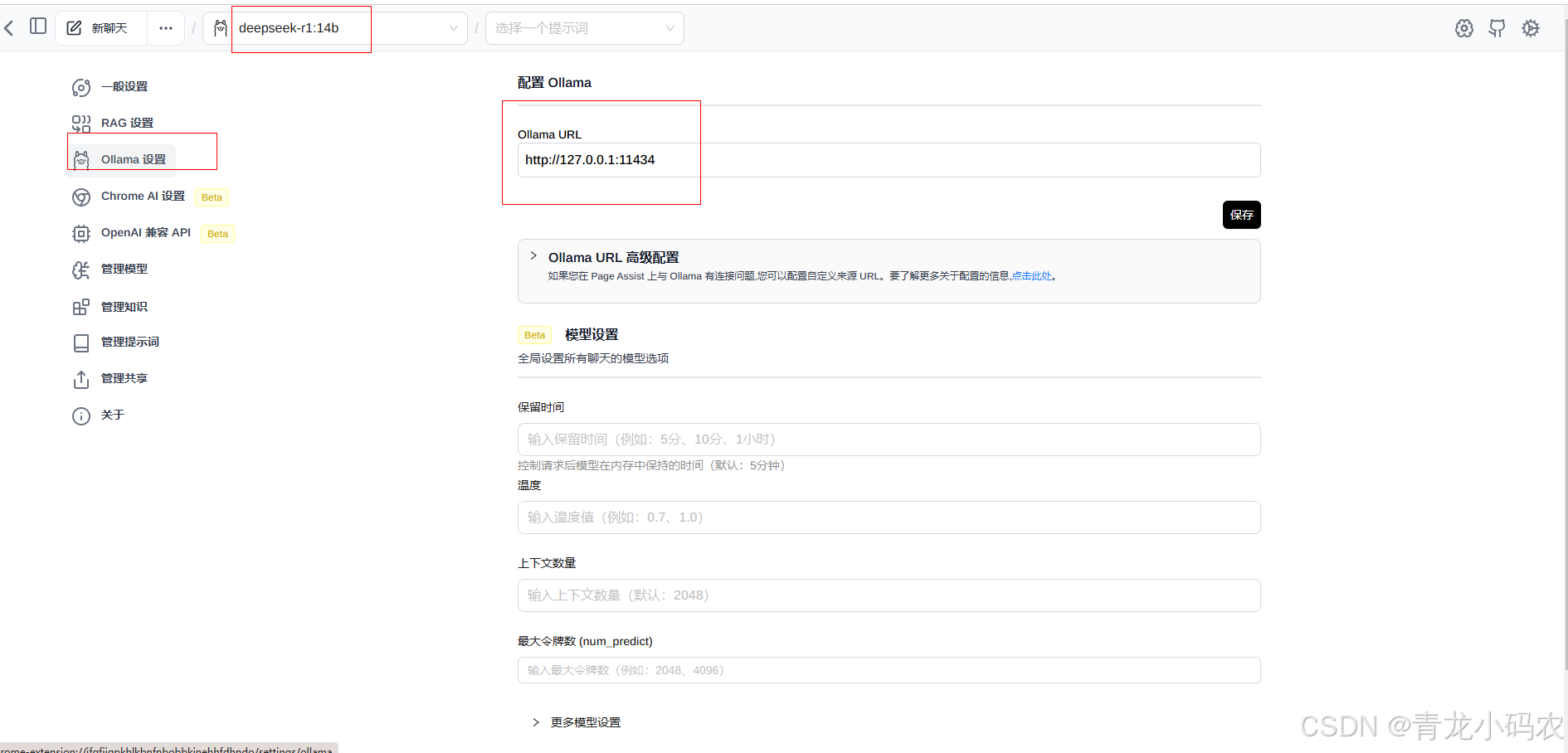
PAG配置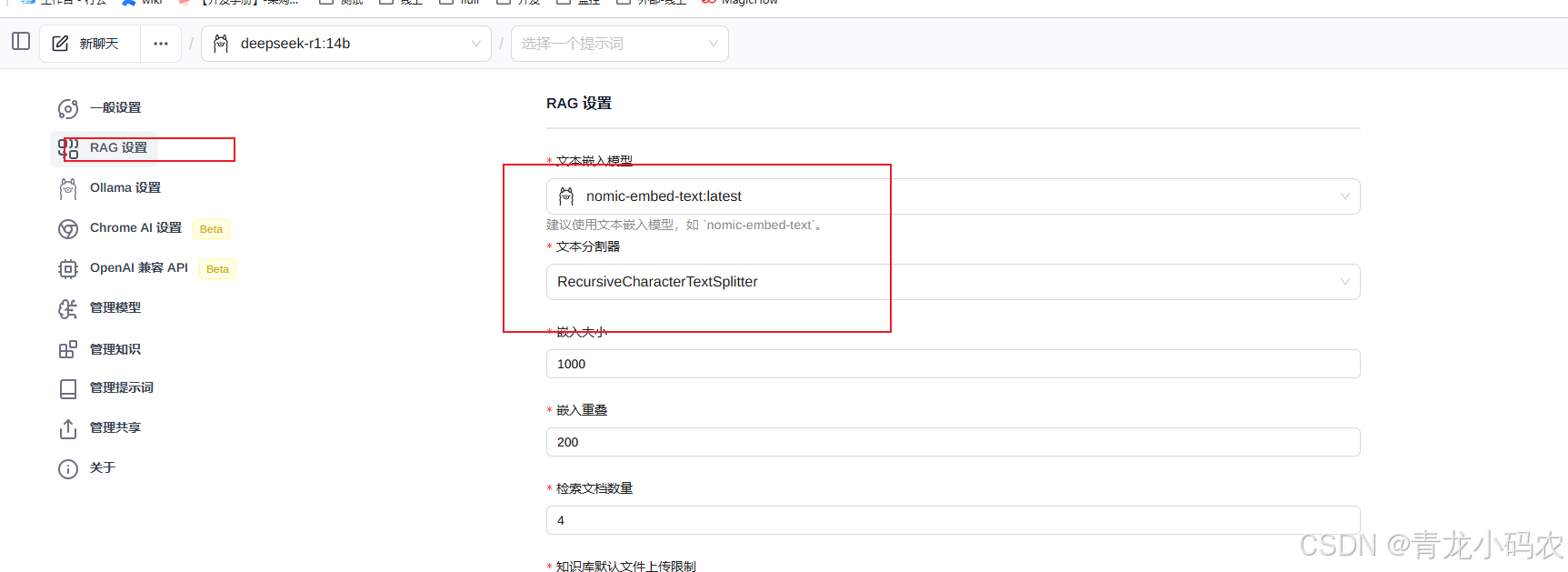
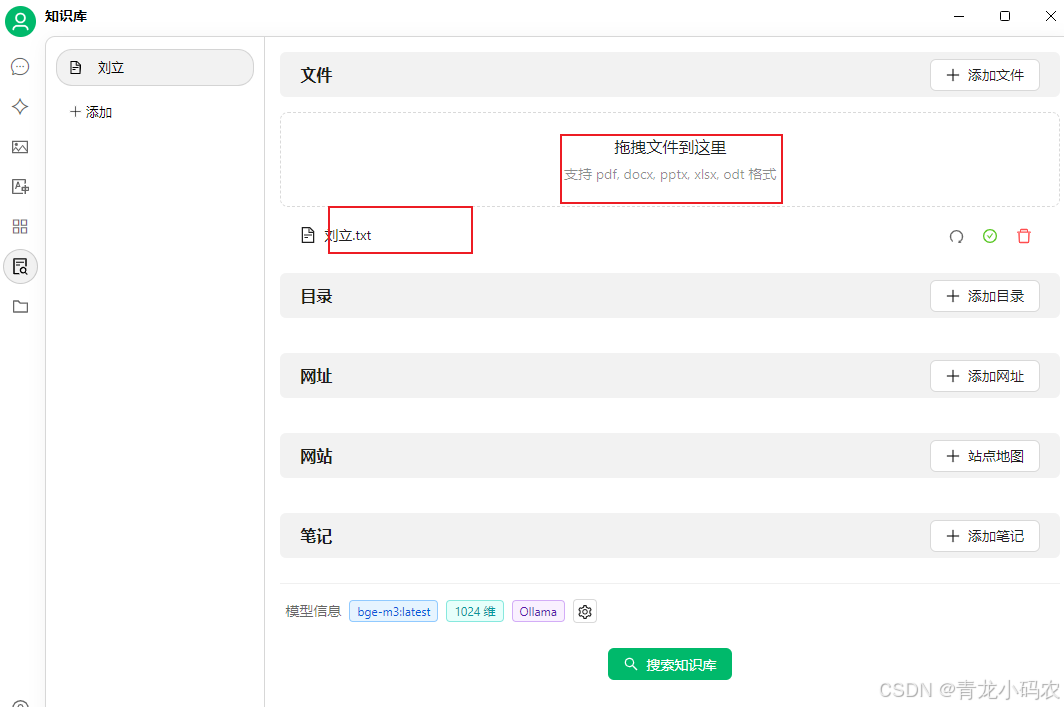
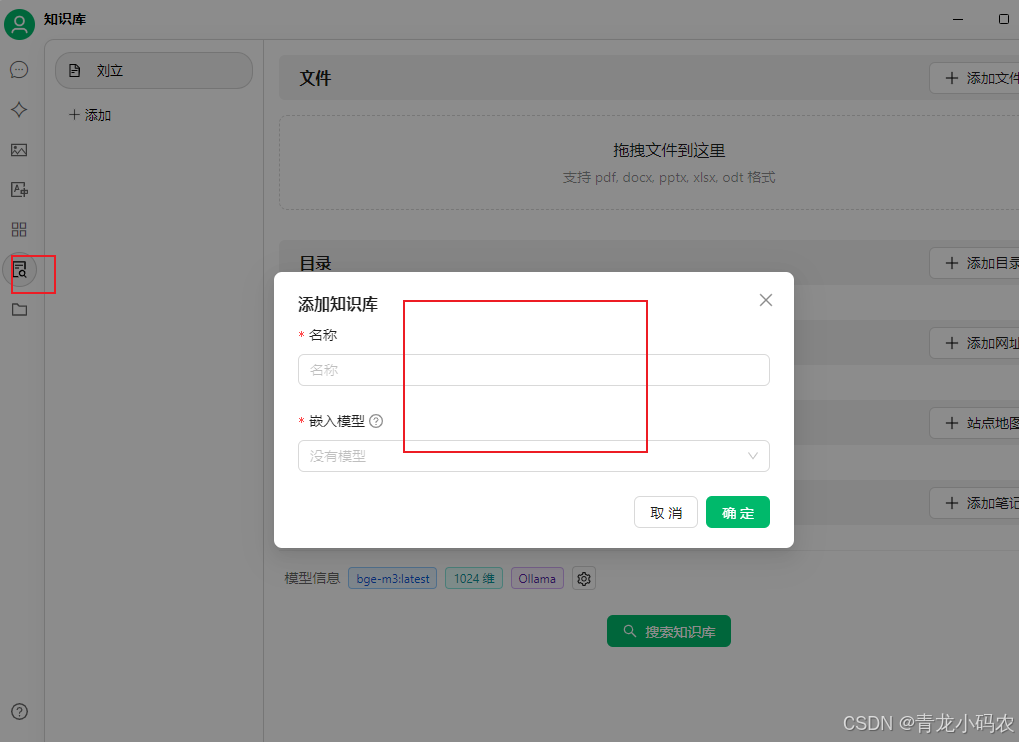
本地知识库
上传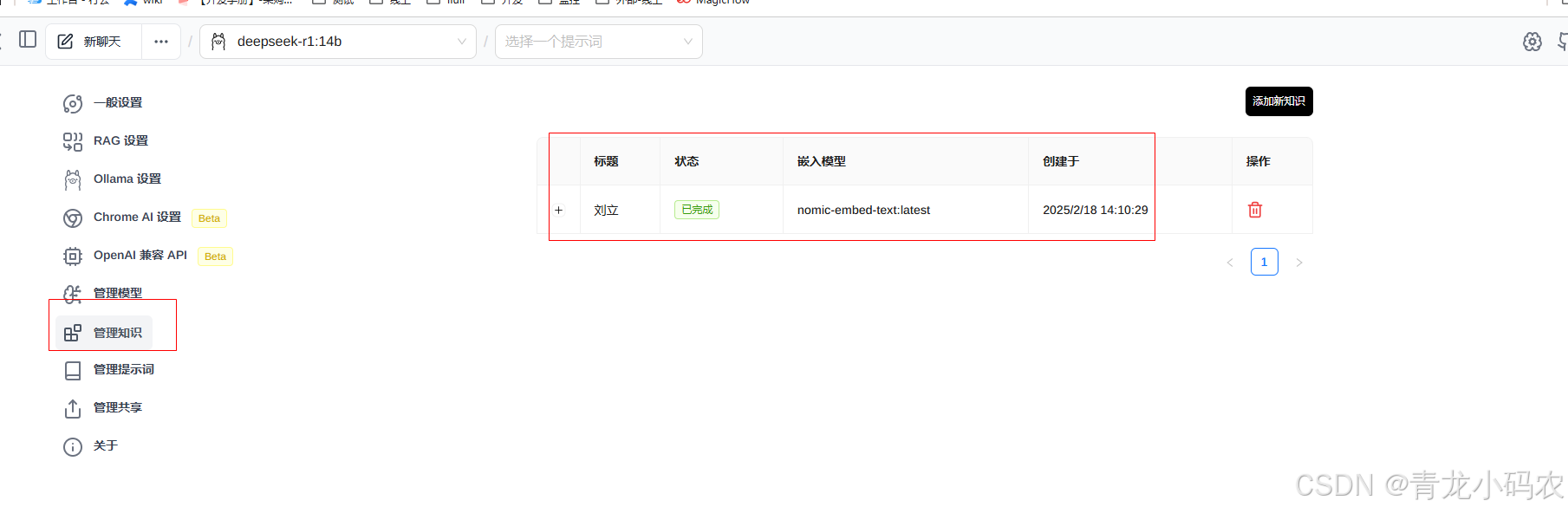
运行本地知识库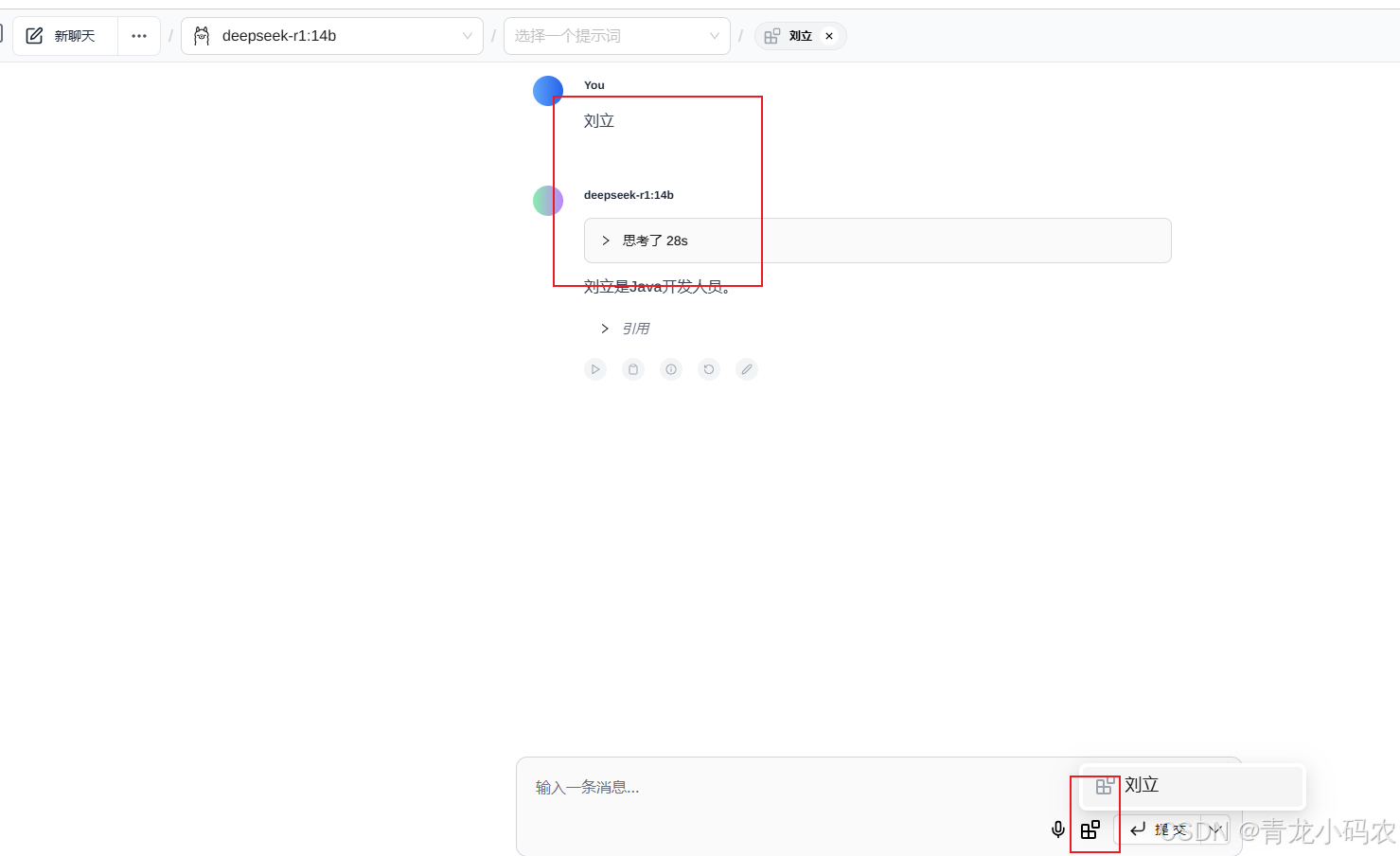
其他功能可自己探索
ChatBox+本地知识库
ChatBox 是一款多平台 AI 客户端,支持文档、图片和代码处理,强调本地数据存储和隐私保护。
https://chatboxai.app/
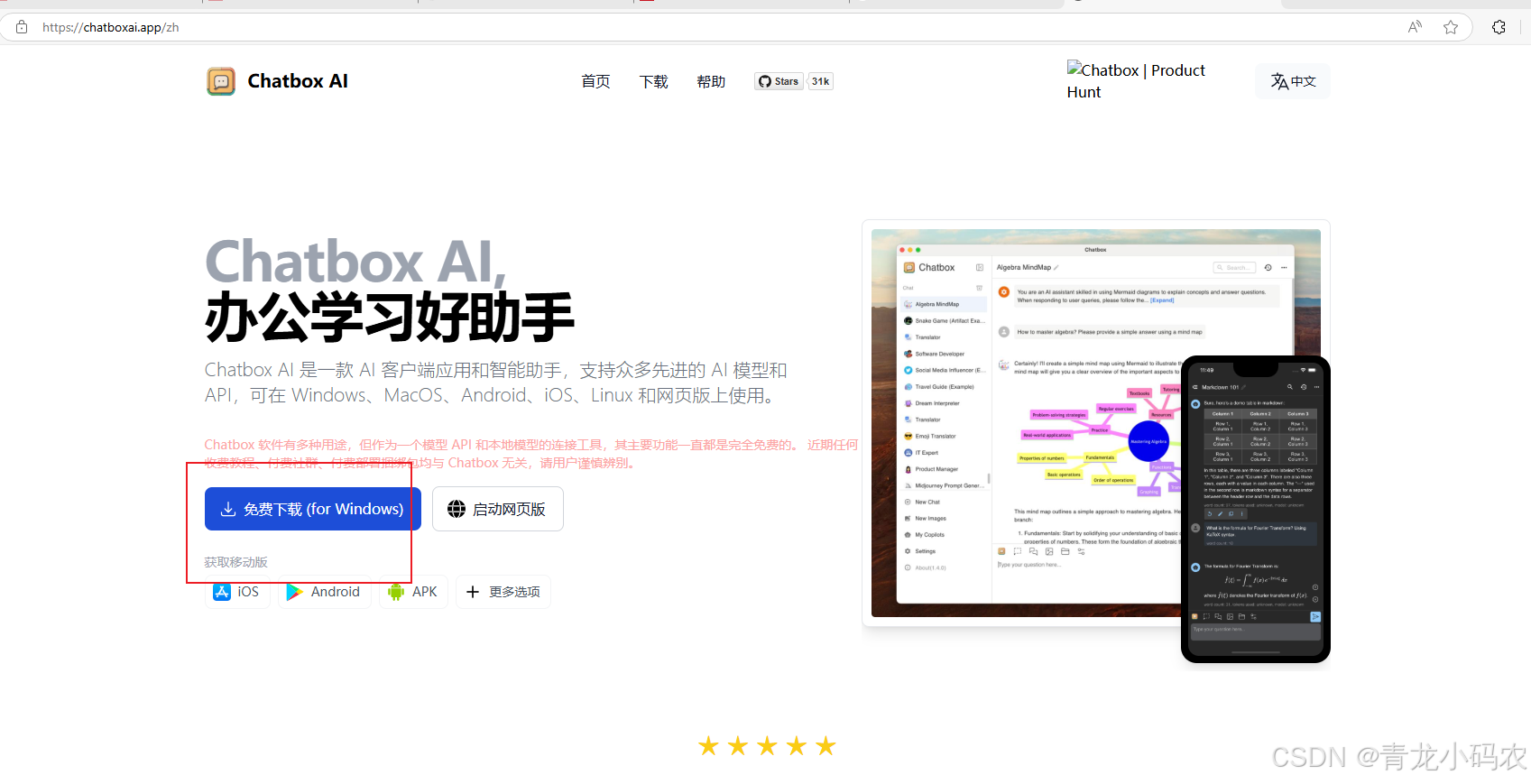
配置deepseek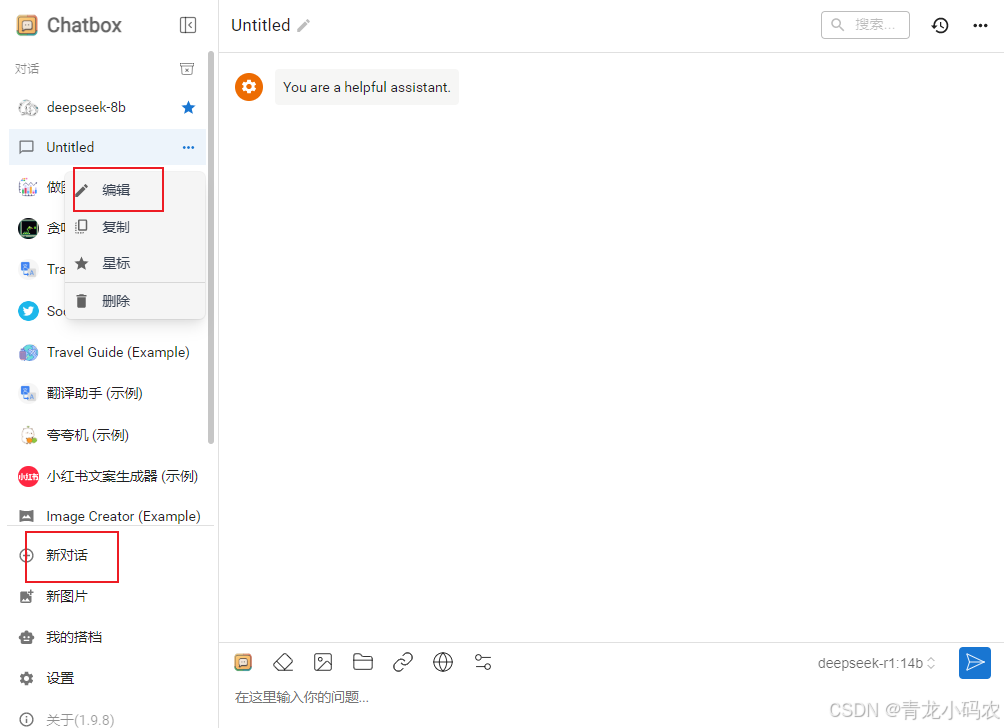
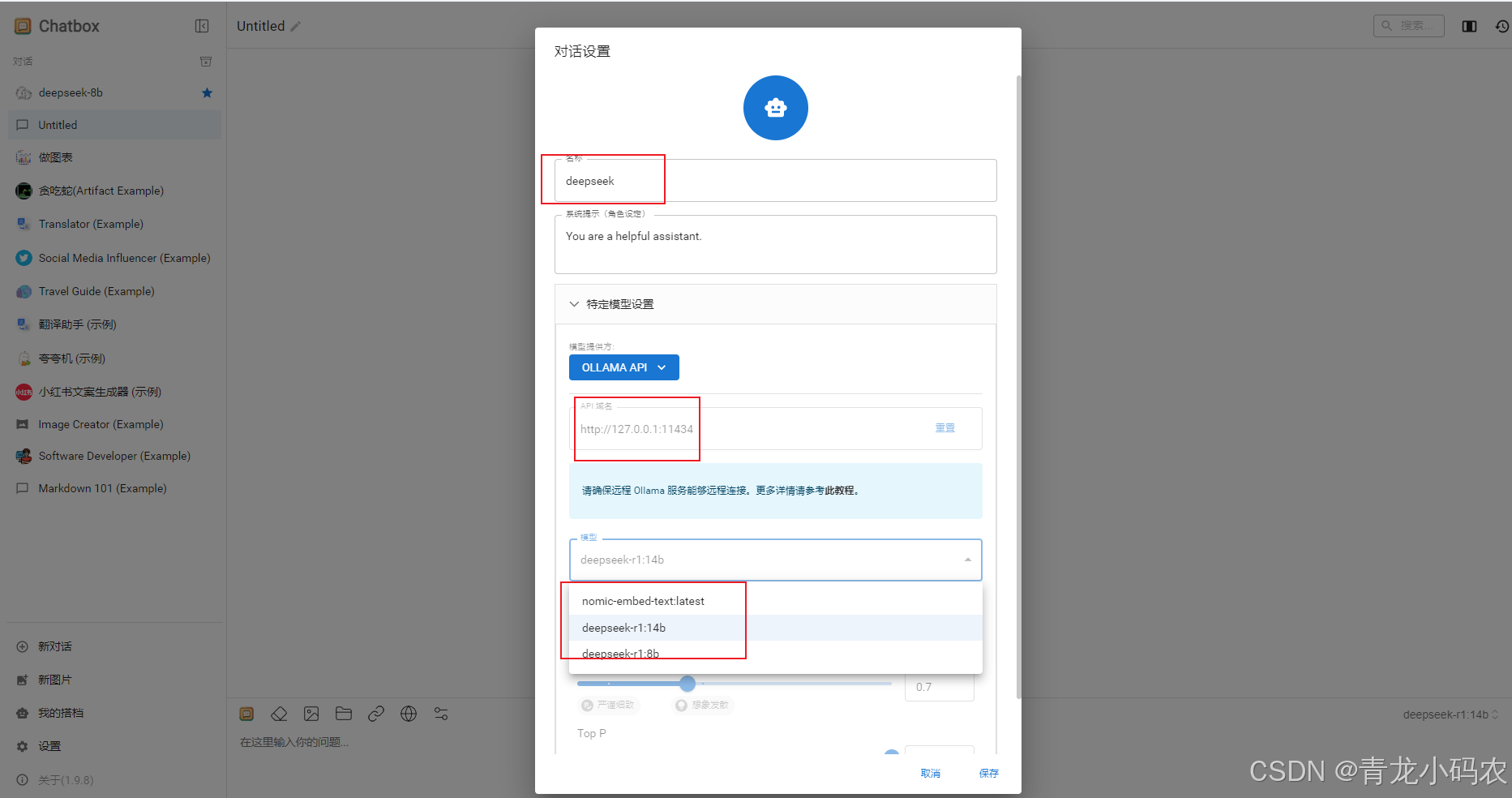
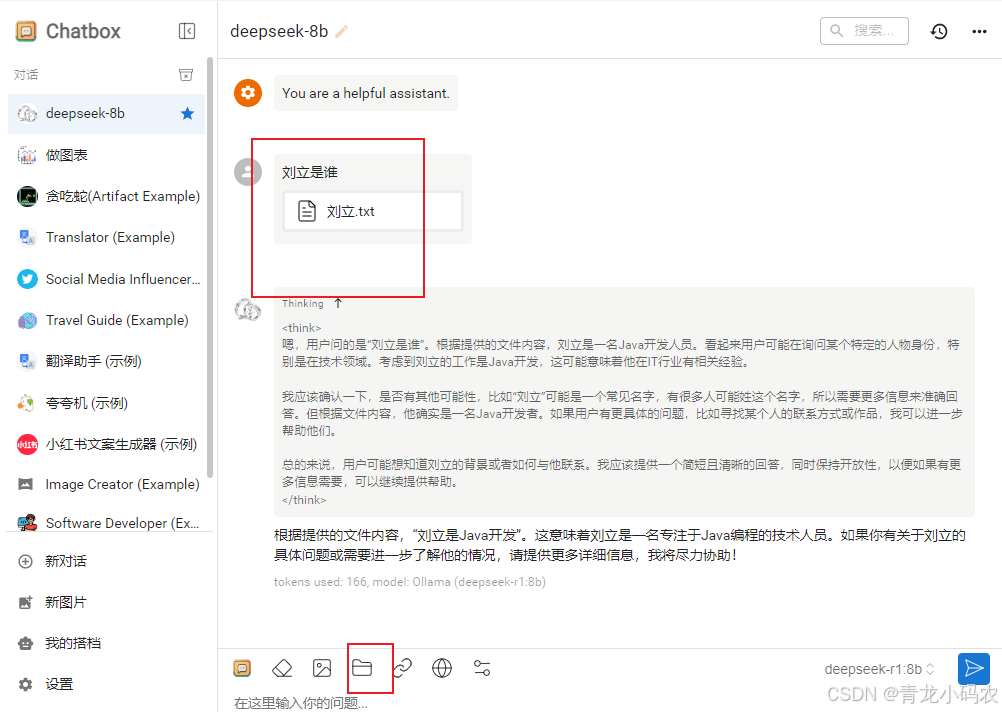
其他功能可自己探索
CherryStudio+本地知识库
CherryStudio 是一款好用的 AI 客户端,支持多种大型语言模型的服务,提供直观的可视化界面和远程 API 接口,旨在降低对本地硬件的依赖,提升使用效率。
官方网址:https://cherry-ai.com/
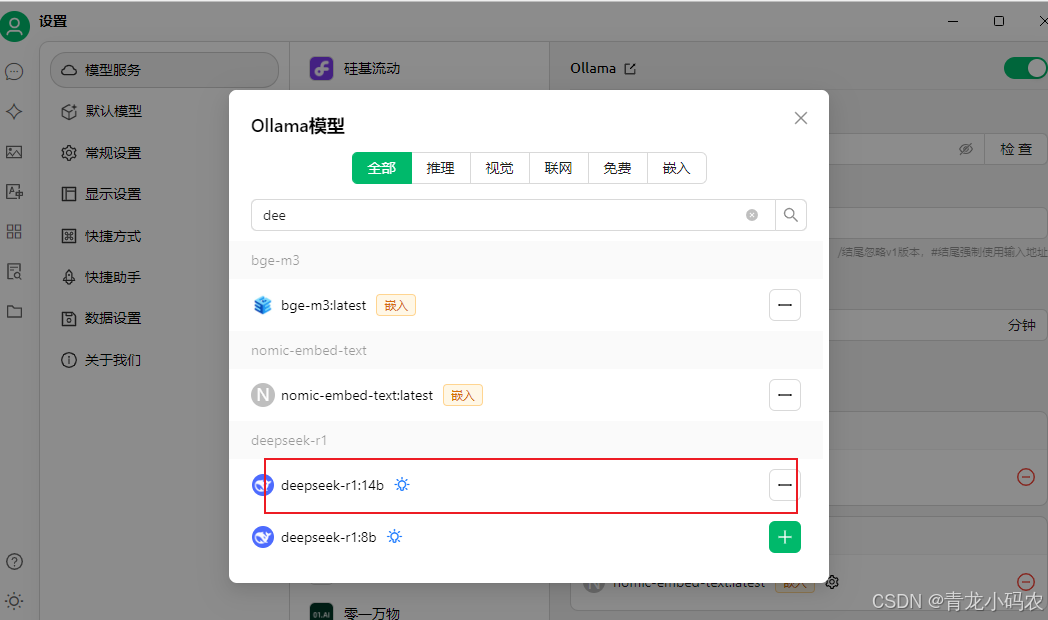
首先点击左下角设置,然后操作如下:
- 点击“模型服务”
- 点击“Ollama”
- 在模型中,点击“管理”,添加前面安装的 DeepSeek 模型
- 启用服务
知识库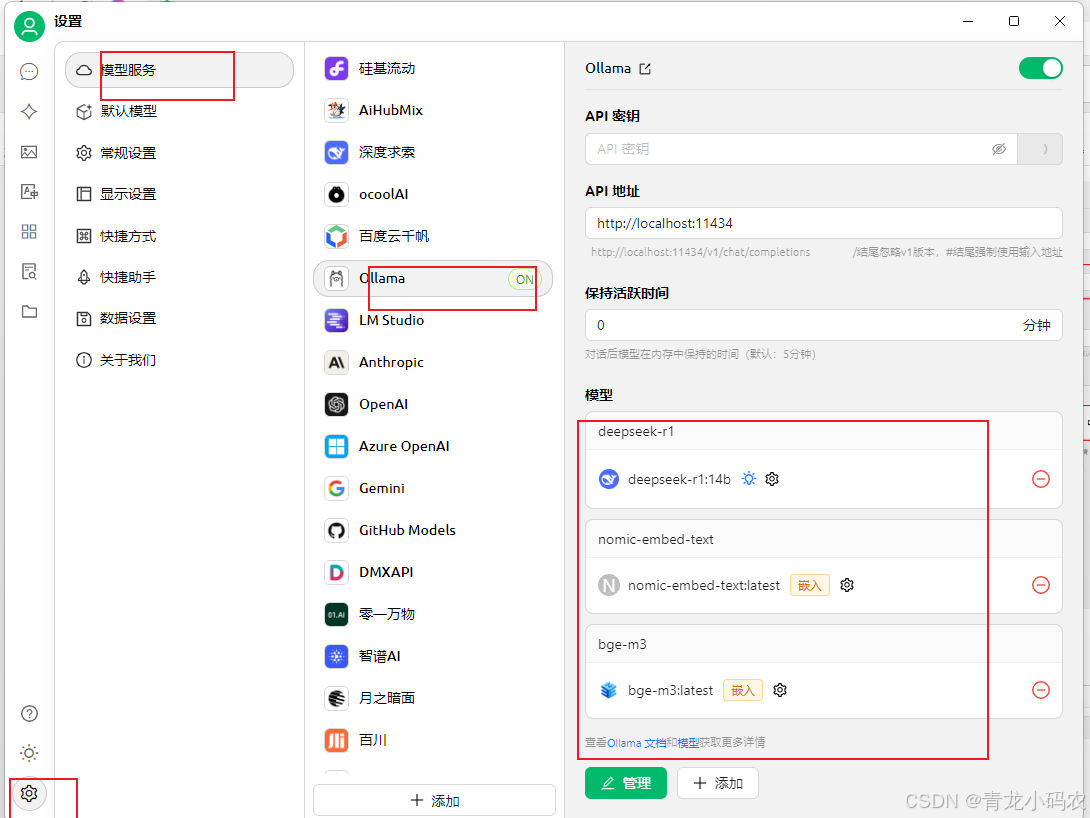
会话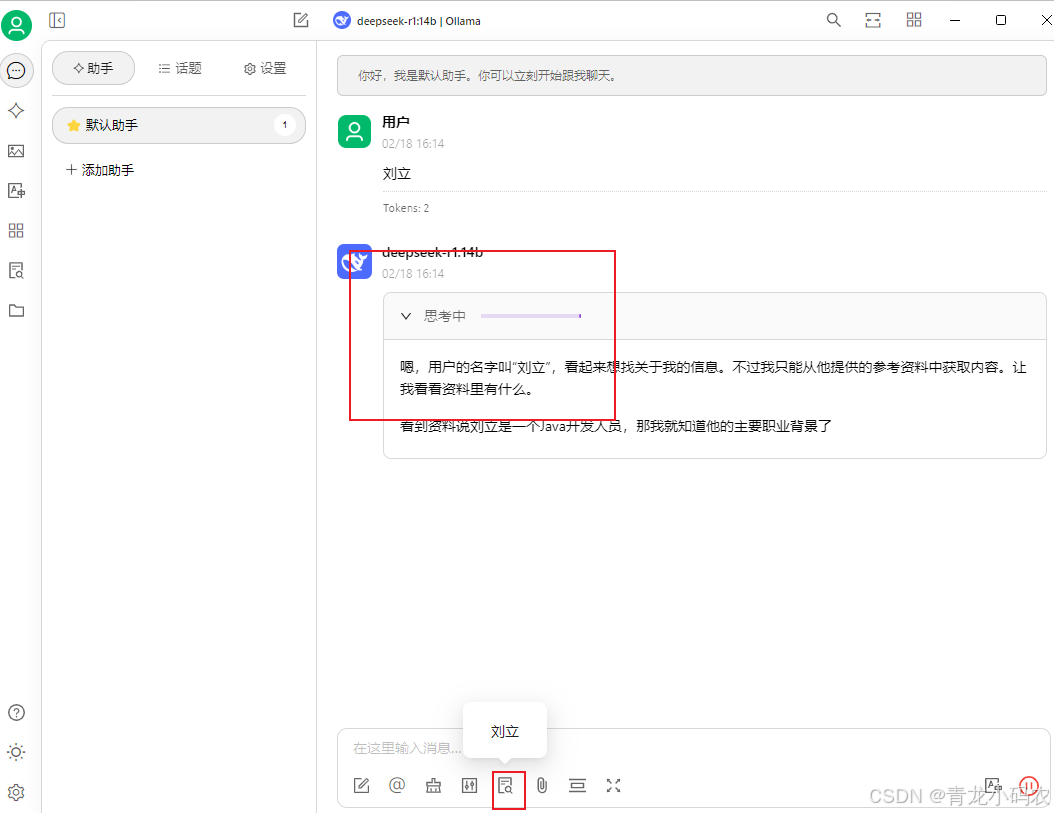
AnythingLLM+本地知识库
AnythingLLM 是一款支持本地部署的 AI 工具,允许用户在本地运行和管理大型语言模型,提供可视化界面,方便用户与模型进行交互。
官方网址:https://anythingllm.com/
新建工作区

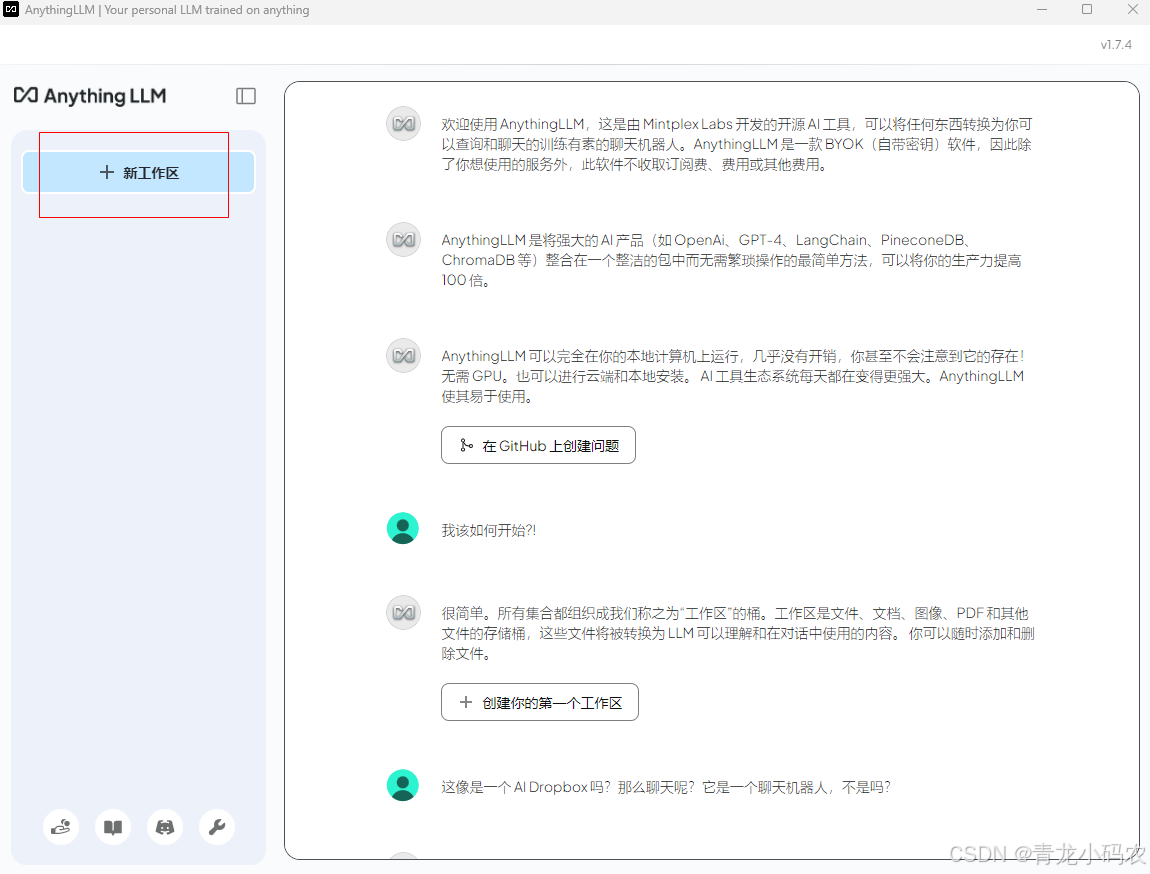
配置deepseek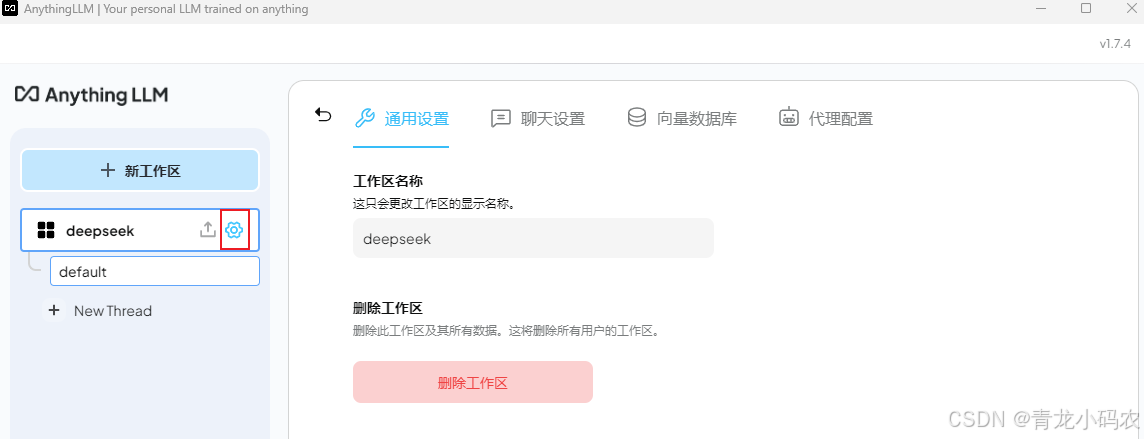
聊天设置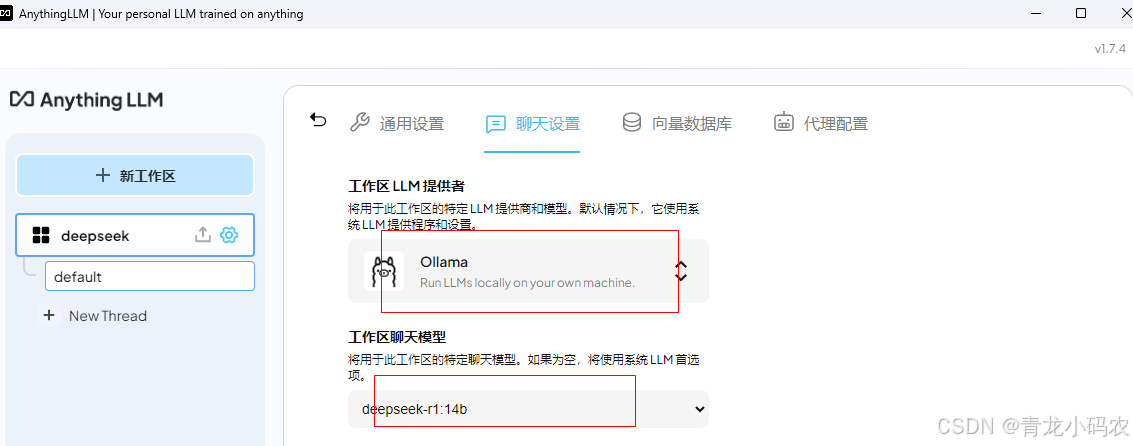
代理设置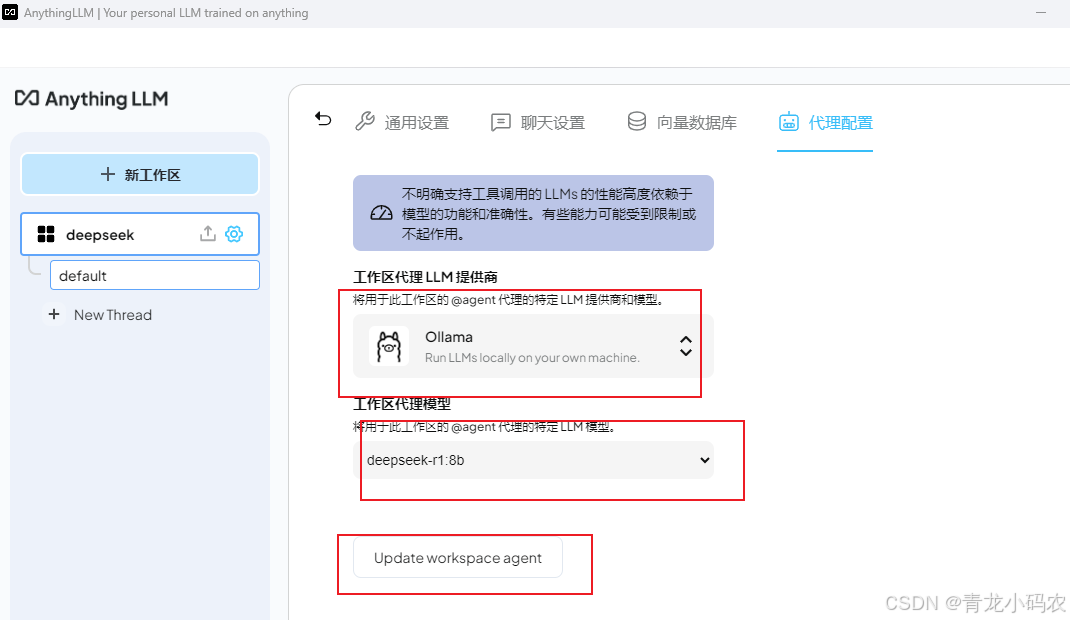
本地知识库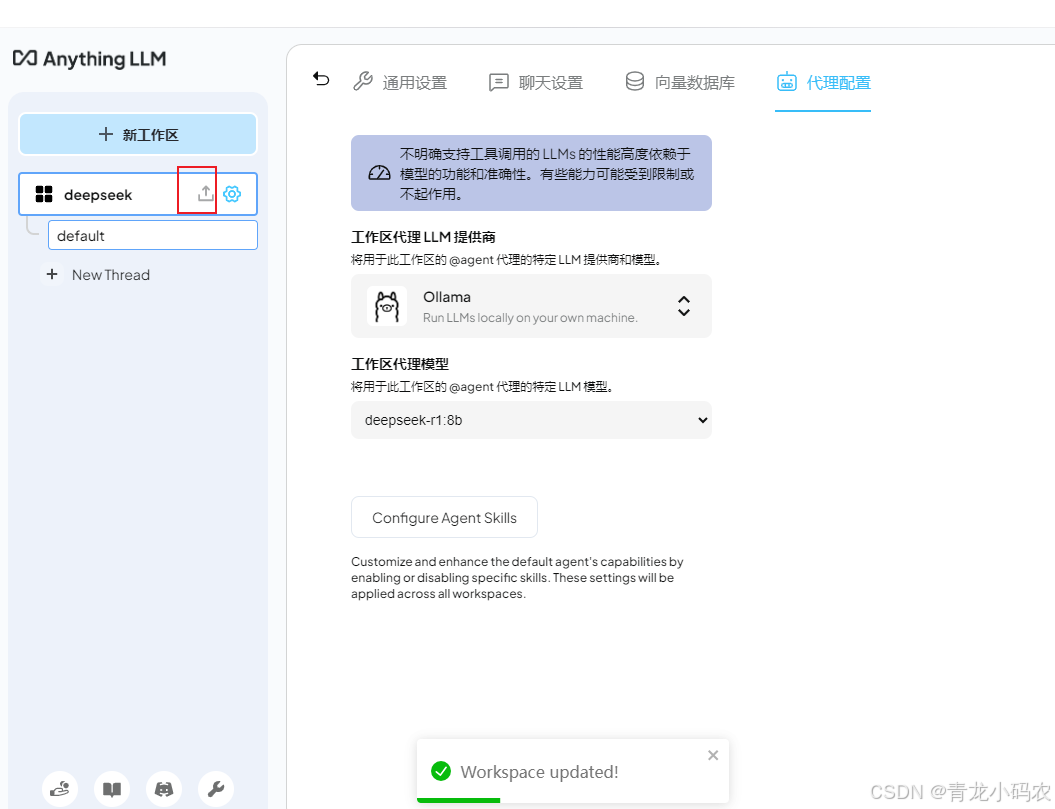
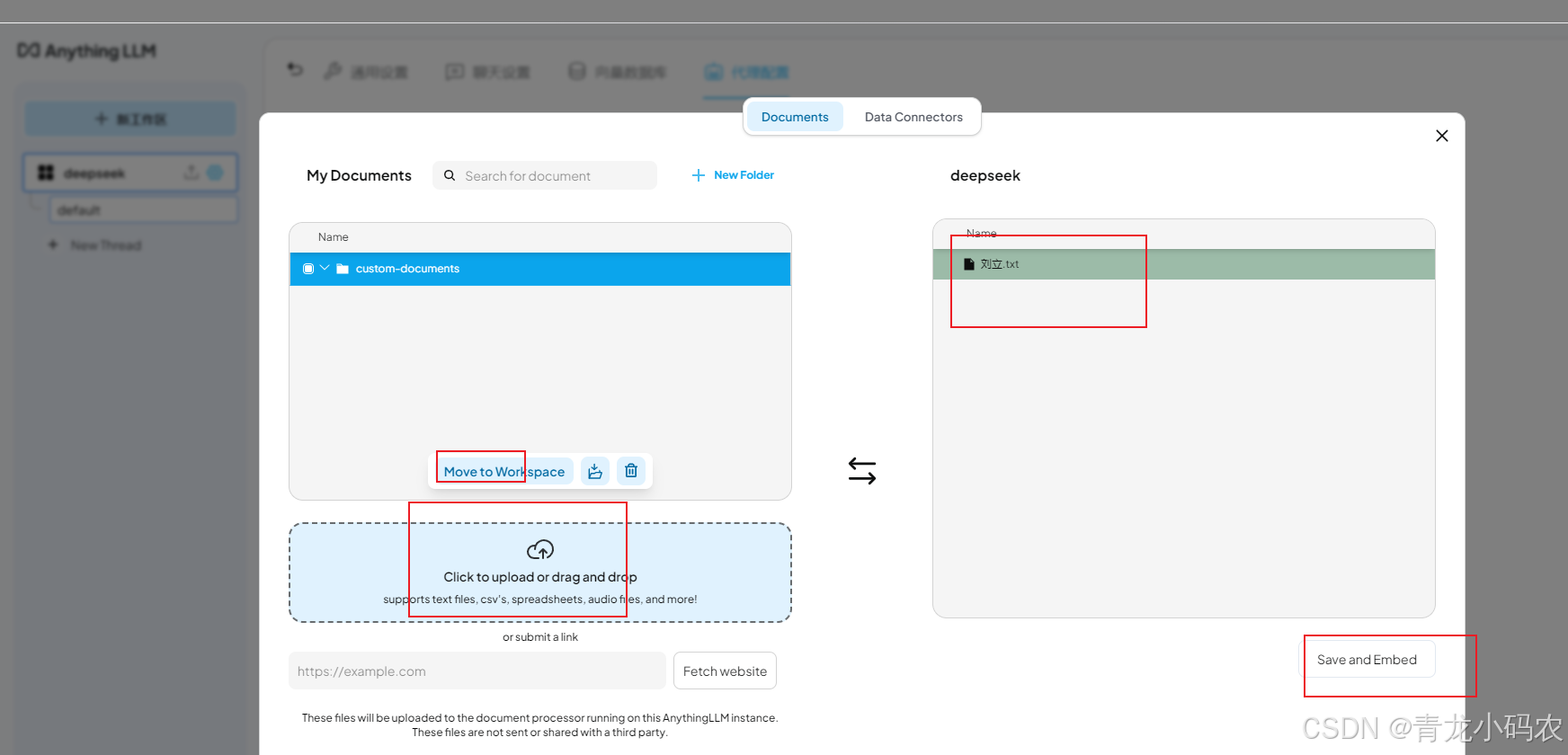
Embeder配置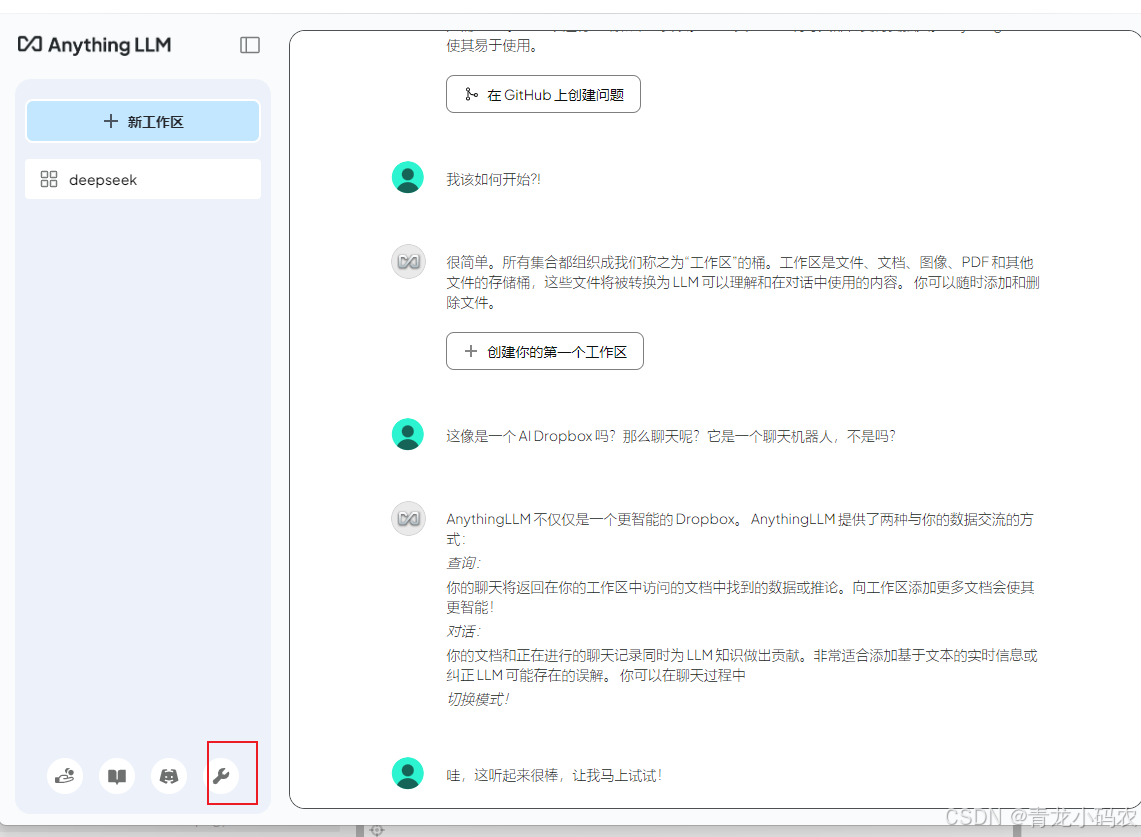
测试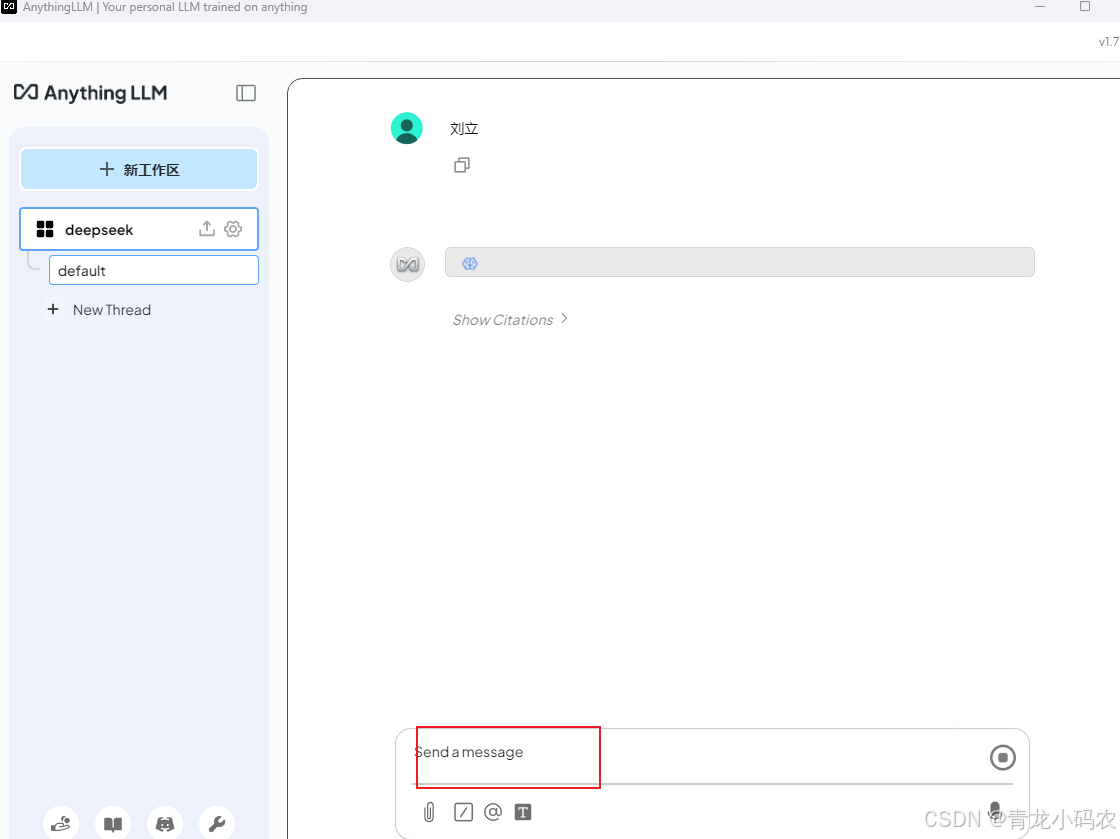
JAVA API 调用
import cn.hutool.http.HttpRequest;
import cn.hutool.http.HttpUtil;
import com.alibaba.fastjson.JSONObject;
import util.CommonHttpUtil;
import java.util.HashMap;
import java.util.Map;
/**
* https://github.com/ollama/ollama/blob/main/docs/api.md
*/
public class Generate {
public static void main(String[] args) {
String url = "http://localhost:11434/api/generate";
HttpRequest request = HttpUtil.createPost(url);
Map<String, String> headers = new HashMap<>();
headers.put("Authorization", "");
request.addHeaders(headers);
JSONObject jsonObject = new JSONObject();
jsonObject.put("model","deepseek-r1:14b");
jsonObject.put("prompt","刘立是谁");
jsonObject.put("stream",false);
String body =JSONObject.toJSONString(jsonObject);
System.out.println("入参========"+body);
String backInfo = CommonHttpUtil.postJson(url, headers,body,300000);
System.out.println("出参========"+backInfo);
}
}

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)