Why is Deepseek? 研究DeepSeek的第一篇
deepseek刷屏了一阵子, 导师最终还是让我看看其中的真假了.LLM Speculative sampling一直在寻找如何压缩更小的参数到草稿模型,以至于形成更精确的target model猜测, 确实需要对参数可解释性与输出分布可解释性有所了解.本着先忠于原著, 不看二次解读的做法, 就想着自己先读一遍.开篇的我确实不太懂deepseek究竟有啥用处, so just read it.
deepseek刷屏了一阵子, 导师最终还是让我看看其中的真假了.
LLM Speculative sampling一直在寻找如何压缩更小的参数到草稿模型,以至于形成更精确的target model猜测, 确实需要对参数可解释性与输出分布可解释性有所了解.
本着先忠于原著, 不看二次解读的做法, 就想着自己先读一遍.
开篇的我确实不太懂deepseek究竟有啥用处, so just read it.
第一篇文章:DeepSeek LLM Scaling Open-Source Language Models with Longtermism
链接:https://arxiv.org/abs/2401.02954
deepseek在arxiv上发的第一篇文章, 本文还是有SFT与DPO(隐藏的RL), 还是decoder-only的架构, pre-training to instructed to X-PO 的三阶段训练. 主要价值点在于提出了一个模型规模缩放规律.
deepseek说:早期的俩篇论文
openAI提出的Scaling Laws for Neural Language Models(https://arxiv.org/abs/2001.08361)与DeepMind提出的Training Compute-Optimal Large Language Models(https://arxiv.org/abs/2203.15556)
探究还不够充分。
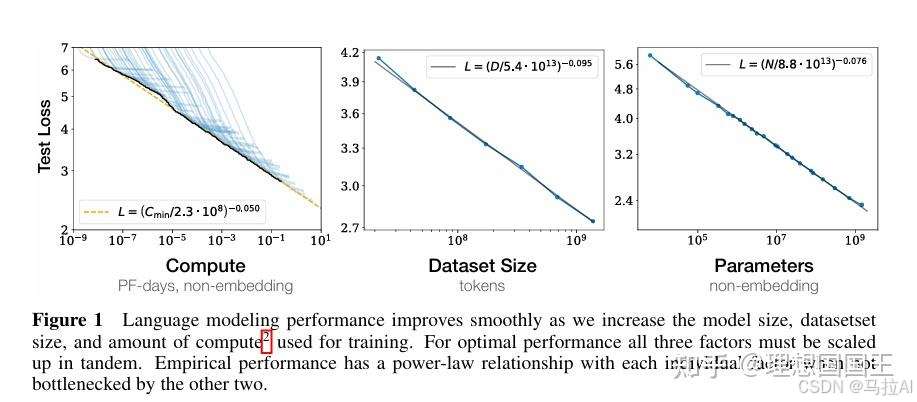
这里可以说一个有趣的现象,可以从图1看到一条明显的计算规模收敛线,哪怕有个模型能逾越这条线一个数量级,其就能增加10倍训练效率。(哈哈哈,这不是废话的吗)
OpenAI认为模型性能主要取决于三个因素:模型参数数量 N、数据集大小 D和训练计算量 C。
观点有:
- 在合理的范围内,模型性能对网络宽度或深度等架构超参数的依赖性非常弱。
- 过拟合的普遍性惩罚:当同时增加模型大小和数据集大小时,性能会有所提升,但如果固定其中一个因素而增加另一个,性能提升会进入递减阶段。过拟合的惩罚可以通过 N^0.74/D的比例来预测。
- 训练曲线遵循可预测的幂律,其参数大致与模型大小无关。通过外推训练曲线的早期部分,可以大致预测长时间训练后的损失。
- 大模型比小模型更样本高效,达到相同性能所需的优化步骤和数据点更少。通过外推训练曲线的早期部分,可以大致预测长时间训练后的损失.
- 在固定计算预算 C的情况下,最优性能是通过训练非常大的模型并在显著收敛之前停止来实现的。计算效率最高的训练方式比基于小模型收敛的训练方式样本效率更高。
- 训练这些模型的最优批量大小大致是损失的幂函数,并且可以通过测量梯度噪声尺度来确定。
deepmind的观点也大差不差, 强调参数量,数据大小与训练计算量C
(由批次决定,C≈6NBS, N非嵌入参数数量,B是批量大小(Batch Size),S是训练步数(Steps),因子 6 考虑了前向传播和反向传播的计算量(通常反向传播的计算量是前向传播的两倍)。)
其架构也是遵循LLaMA架构,但是余弦学习率调度器替换为多步学习率调度器。然后2万亿个token做预训练,100实例对做SFT,DPO做人类偏好对齐。

transformer设计上也没有说很亮眼的设计, 常规的4096*n隐藏层维度设计, 毕竟此时还是对标着LlaMa2.5与GPT-3.5而已.
然后第二章就是一些训练技巧的赘述, 包括training状态的保存/多步学习率调度器(这可能方便了一点), 可以帮助初级入门的学者的一些工程性的trick, 如果已经玩过很多次的LLM人就不用看了, 宛如LOL的新手教程.
最有价值的可能是第三章: dpsk提出的超参数的缩放规律(Scaling laws of hyperparameters)
1、首先训练的时候就要调,最好的调参方法如下
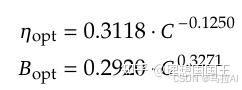
学习率与batch size的设定如上
这个结论是大量实验拟合出来的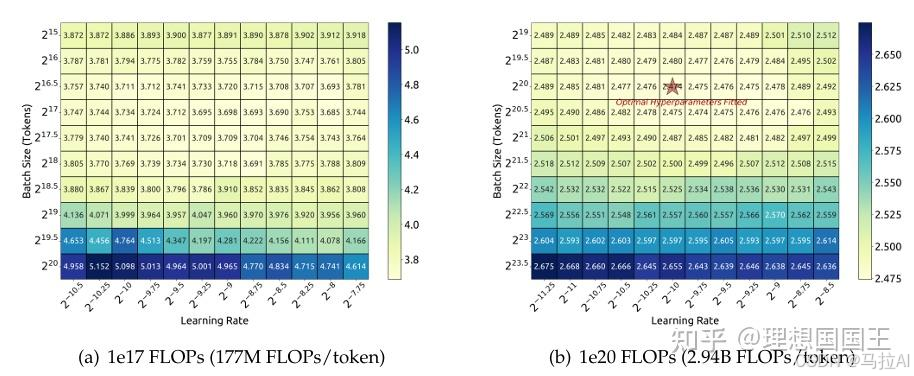
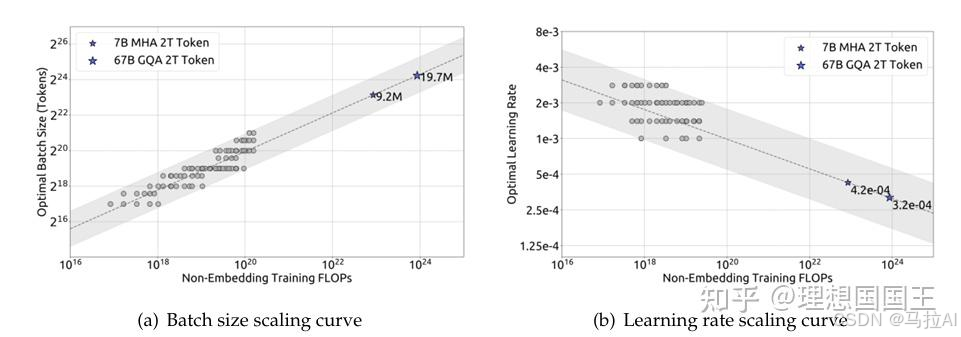
关键发现:
- 小模型需分阶段训练以平衡能力与流畅性,而大模型单阶段训练即可达到最优。
- 大模型(67B)能有效利用系统提示提升指令遵循,而小模型(7B)可能因提示冲突导致性能下降(表14)。

第二/三/四篇文章:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model & DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models & Deepseekmath: Pushing the limits of mathematical reasoning in open language models
关注点:
1、MLA与MHA的区别
2、DeepseekMoE架构的浅了解
俩篇文章一起讲是因为V2采用了DeepSeekMoE,是绕不过的。
MLA与MHA的区别
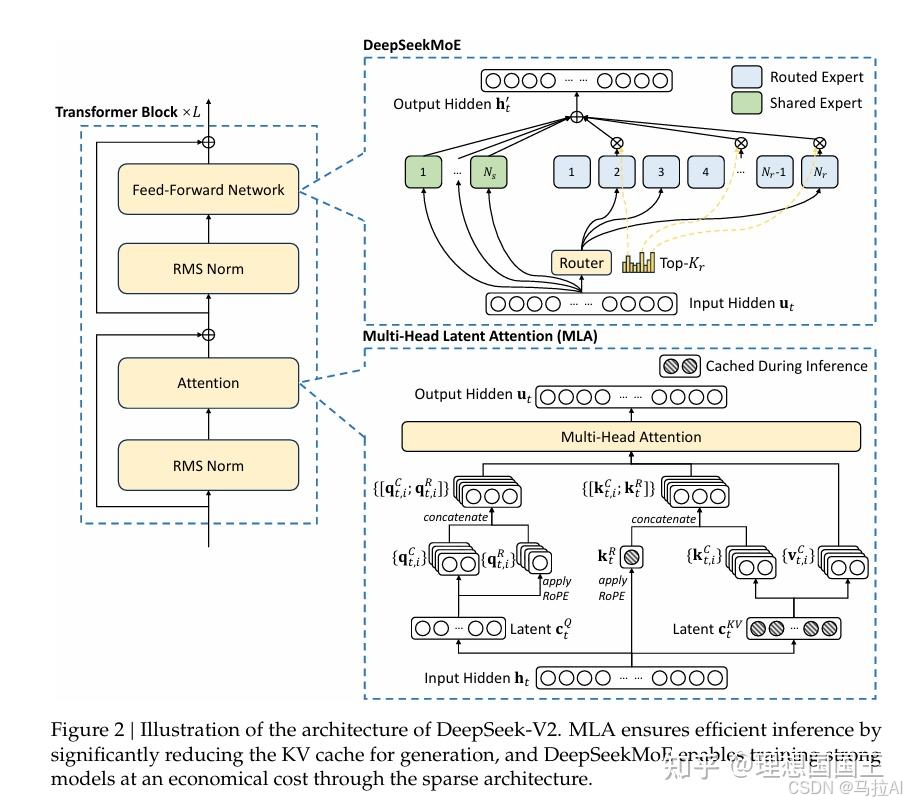
多头注意力机制无非就是将隐藏层的每个维度单独计算,注意力然后再以某个权重参数concat在一起。
本人认为因为是concat的没有维度间的norm的计算,所以MHA的优点主要是并行计算能力。(目前
没有看到多个子空间依赖可解释性的文章,WOW^{O}WO也与V有点冗余)。
本文谈到:
一个token所需的元素 (指一个数值)为nh∗dn∗ln_h*d_n*lnh∗dn∗l去构成KV缓存,nhn_hnh为参数头的数量,dnd_ndn为一
个参数头的维度,lll为transformer的层数。
然后为了压缩这个KV缓存的,本文用了一个参数去做了线性映射,把其映射到秩更低的空间(你也可以理解为维度更小的空间)

去构成KV。
这样做与直接降低隐藏层dim的做法有所不同,直接降低dim会造成信息捕捉不够充分。
但这样的线性映射是捕捉到了更多dim中的信息,然后再缩放到更小的维度,这样的做法是有选择的考虑不同维度信息的重要性。
ctKVc_t^{KV}ctKV 是dcd_cdc 的降维,ctKV⇒ktCc_t^{KV} \Rightarrow k_t^CctKV⇒ktC or vtCv_t^CvtC 是dcd_cdc 到nh∗dhn_h * d_hnh∗dh 的升维,只要保存了
WDKV,WUK,WUV,ctKVW^{DKV}, W^{UK}, W^{UV}, c_t^{KV}WDKV,WUK,WUV,ctKV
就能还原出原本的kv,
MHA: (2∗dh∗nh∗Lseq)∗l(2*d_h*n_h*L_{seq})*l(2∗dh∗nh∗Lseq)∗l
MLA: (dc∗Lseq+dc∗d+2∗dc∗dh∗nh)∗l(d_c*L_{seq} + d_c*d + 2*d_c*d_h*n_h)*l(dc∗Lseq+dc∗d+2∗dc∗dh∗nh)∗l
这样代价就小了很多,如果去掉映射秩矩阵。
MHA: (2∗dh∗nh∗Lseq)∗l(2*d_h*n_h*L_{seq})*l(2∗dh∗nh∗Lseq)∗l
MLA: (dc∗Lseq)∗l(d_c*L_{seq})*l(dc∗Lseq)∗l
可以简单的看成前者是后者的(2∗dh∗nh)/dc(2*d_h*n_h)/d_c(2∗dh∗nh)/dc 倍。
但是在这里我得提出一个疑问,kv缓存的本意不就是为了减少计算时间吗?即h乘以Wk or Wv的时间,这样做了转换,计算时间的代价会上升多少呢?为什么不直接存下隐藏层呢?
评论区有人给出,说:“这个是io bound”。
也就是说io的计算量级远远大于w与c的矩阵乘法时间。
那么就代表着取n个kv缓存需要2n个io时间,而取n个c计算的话只需要n个io时间(w可以预载入)。
第二个问题是如果取h计算的话,时间上和取c计算是差不多的。(c可能多了上下采样的时间)
但是c的占用缓存又比h小。
综合下来将h压缩成c做缓存是一个好方法。
sorry,本人对研究io与显存计算的背景研究薄弱,不过根据本科计算机组成原理那一点知识大概可以想到io速度大概率会成为瓶颈
看起来是用时间换空间了,可能也是现在显卡难得的原因。
后文在训练的时候也做了缩放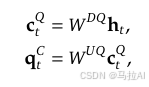
然后看到了Decoupled Rotary Position Embedding,其实这是因为采用了MLA方法,dpsk想让Q与K的c直接做位置编码变换(如果不直接做会影响推理效率),所以根据公式推理出了一个decoupled RoPE strategy (解耦RoPE策略)

本人认为这个公式暂时看不出其价值。
出乎我意料的是,其居然变更强了,全文推理中没有看出哪里做了增强。。。。
等等,难道是低秩压缩的时候产生的映射其实又可看做一次变化吗?可解释性暂时不清楚。
DeepSeekMoE: Training Strong Models at Economical Costs又便宜又好的训练方法
2.1pre-knowledge
之前有听过MoE的transformer,但是因为一直做的是应用了解就没去深究,看来这里绕不过去了。
可以参考这篇文章,去学习:https://huggingface.co/blog/zh/moe
简单单来说,混合的专家,是对“注意力分数”的专家,不同的FFN(实际上就是一个resnet)。
本来的单个FFN就是通过处理注意力分数,来得到某个专家,专家的脑袋就是FFN,FFN可以决策,FFN能产出对应的潜在特征。
MoE架构最常见的就是由一个门控网络作为选择专家的专家,然后产生不同的激活权值。
所以将多个FFN结合起来使用,就是不同的专家的脑子放在一起讨论,然后由门控专家来决定使用哪些专家的决策潜在特征。
这样使得原本的黑箱更黑了,各个专家之前的决策是否相近呢?门控专家的决策是否正确呢?
这显然是一个可训不好训的架构,是个理想的架构。
Llama这样的开源模型其实都还没用上MoE架构,因为其训练太难训了(或泛化差,训练规模大了又可能过拟合,此处不深究)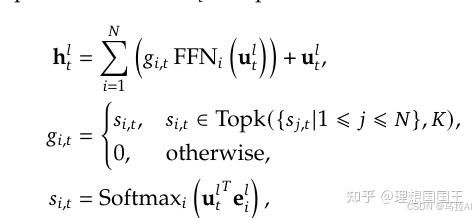
可以先来看看的传统公式是这个,是一个ToK策略的MoE层,u代表的是注意力机制分数计算后再残差操作的中间特征,e是固定的中心向量(不知道是如何选取的)
2.2DeepSeekMoE
这篇文章提到了原来的MoE存在的问题https://arxiv.org/abs/2401.06066
(1)知识混合:现有的 MoE 实践通常使用有限数量的专家(例如 8 或 16),因此分配给特定专家的 token 可能会覆盖多种知识。结果,指定的专家会倾向于在其参数中组装非常不同的知识类型,这些知识难以同时利用。
(2)知识冗余:分配给不同专家的 token 可能需要共同知识。
(这非常像我的毕设,采用共同yolo的backbone,然后多个头作为多个专家,虽然我的毕设在效果上不好,哈哈哈哈)
其关注点主要有:
1、新的DeepSeekMoE架构。
2、DeepSeekMoE节约的计算量,与其产生的能力提升。
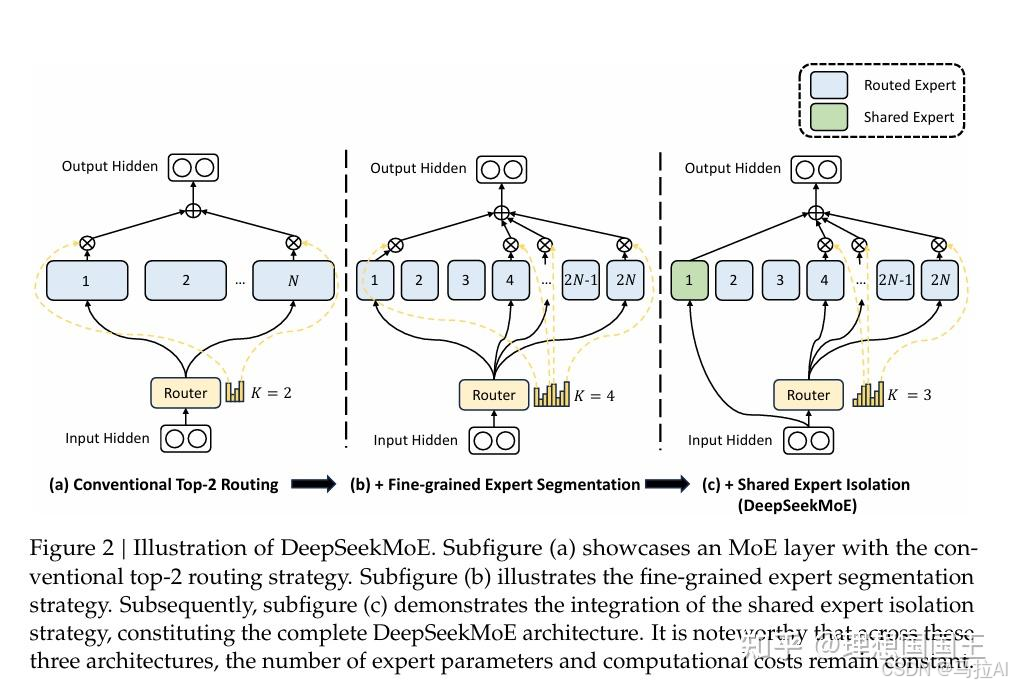
从左到右是从Top-2,Fine-grained,DeepSeekMoE的MoE策略对比。
图a就是上文提到的传统MoE,图b初看没有啥区别,好像就是一个更多的FFN,与更大的K。
DeepSeek最后策略是保留Ks为稳定的嘉宾(五常),其余的使用Top-K策略(带上了细粒度,okok,Working is all I need)
这个专家隔离的概念其最早由Rajbhandari et al. (2022).提出https://csacademy.com/app/graph_editor/
这样做的好处就是稳定的这几个FFN或许会被长期训练,从而变得通用而不专用,就像一个公司里面有几个百事通出主义,什么都考虑的它会考虑的更全面,能统揽全局。
此外,在训练策略上防止了负载不均衡问题,就是不能老是有专家吃干饭,有的专家总是累死累活,要求要患不均,要公平。(深得社会主义思想渲染)

N′ 是激活的专家数量,gi 是第 i 个专家的负载,1(⋅) 是指示函数。
这样既有通识专家,也有均衡的不同专家讨论,就使得网络在稳定性与均衡性上较好。
当然还有一个工程级别的均衡,就是不同FFN层会被分到不同的设备上。
但是这些训练却是Deepseek剩钱的一个底层原因,能从模型的角度考虑也是很勇敢的。
而且DevBal居然采用了更大的权重因子,也就是DevBal_Loss会被考虑的更多。
回到V2
除了这些DeepSeekMoE与MLA的创新
这里有一个损失是让设备也均衡的。这个很值得疑惑,设备的分配策略似乎不该出现在模型训练中。因为本人没有做很多分布式人工智能的研究,就不加评论了。(本人认为这个分配策略应该由硬件层完成,可能是来自SE的偷懒与甩锅,哈哈哈哈)
最后还有一个Communication Balance Loss.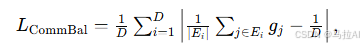
这个也是硬件段的设置,也是同上的评论。
此外还有一些小trick,就是Token-Dropping Strategy, 关于令牌丢弃的,但这似乎对全文主题的把握不是很重要。不过如你要复现论文,或者train自己的论文,这个是很重要的。
2.3更多训练策略
因此引入了第四篇论文:https://arxiv.org/abs/2402.03300
GRPO策略是其SFT训练后的采用的RL算法,因为网上都在说Deepseek是在这个端有更好的效果。
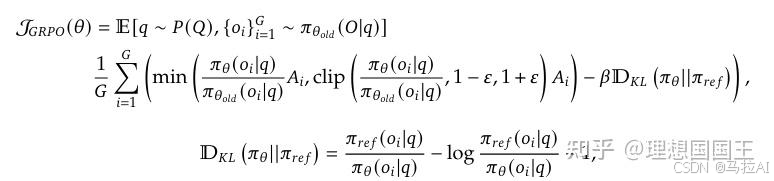
关注点:
1、GRPO策略从何提出?为什么要这个策略?作用是什么?
在DeepSeekMath提出的GRPO训练策略,主要是为了解决数学这样的复杂问题。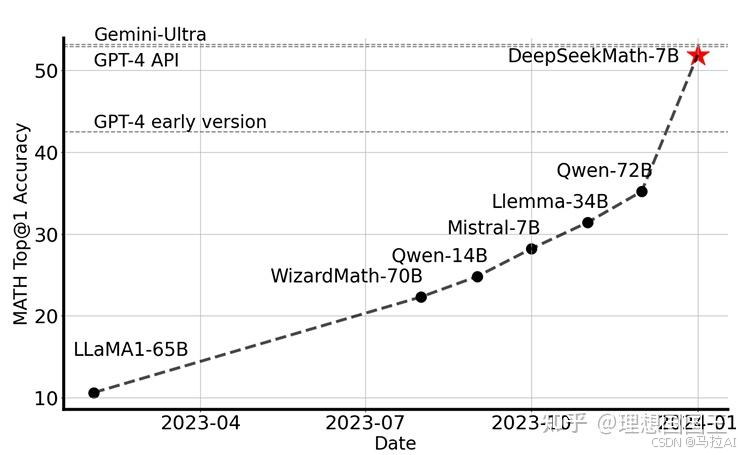
由于原文关注的数学问题太多(数据清洗,选择,Cot,格式等等),本文又主要是了解Deepseek科技,我就直接给出GRPO的设计解释与其优点有什么。
设计:
承接于PPO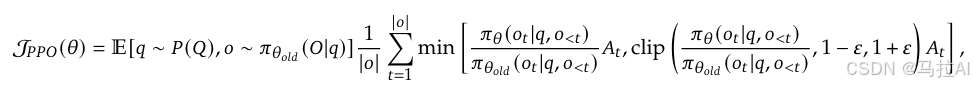
有兴趣的同学可以像我一样从策略梯度算法一直学到PPO:https://hrl.boyuai.com/chapter/2/dqn%E7%AE%97%E6%B3%95
不愿看到同学简单说一下进化史:
策略梯度: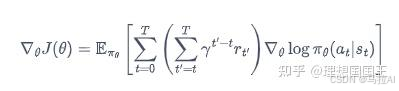
for i in reversed(range(len(reward_list))): # 从最后一步算起
reward = reward_list[i]
state = torch.tensor([state_list[i]],
dtype=torch.float).to(self.device)
action = torch.tensor([action_list[i]]).view(-1, 1).to(self.device)
log_prob = torch.log(self.policy_net(state).gather(1, action))# self.policy_net是神经网络,什么都可以,只要有梯度
G = self.gamma * G + reward
loss = -log_prob * G # 每一步的损失函数
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 梯度下降
可以看到他的loss的计算无非就是某个状态下产生的某个动作,然后累积上动作链的人为奖励,乘以这个概率就是期望了。
Actor-Critic 算法: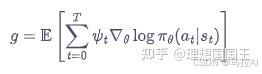
此时的奖励不再由一个人为定义,而是另一个价值网络决定,奖励是一种状态价值的时序差分误差(就看做一个增长值吧)
作者:理想国国王
链接:https://zhuanlan.zhihu.com/p/20930750671
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
#时序差分目标
td_target = rewards + self.gamma * self.critic(next_states) * (1 -
dones)
td_delta = td_target - self.critic(states) # 时序差分误差
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 均方误差损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 计算策略网络的梯度
critic_loss.backward() # 计算价值网络的梯度
self.actor_optimizer.step() # 更新策略网络的参数
self.critic_optimizer.step() # 更新价值网络的参数
是一个双网络模型。
TRPO 算法:
大概就是当决策网络上非常深的网络的时候,其梯度与步长的关系很难把握(简单的RL很难选学习率)
因此不如直接预测怎么样的参数一定会使得期望汇报增值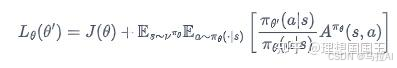
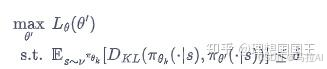
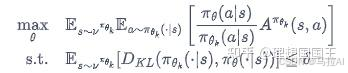
拉来了KL散度等各种公式一大推计算(还没搞懂),最终使得训练训更好了
TRPO 算法也是双网络,A是优势函数的计算方法,还有一个策略网络。
PPO:
有俩种形式
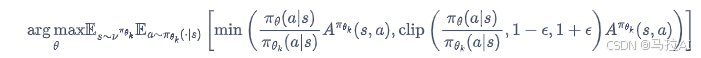

PPO就是把KL散度放到了训练中,从损失变成一个约束。
公式1与公式2效果是一样的,更多的公式2出现在了Deepseek里。
GRPO: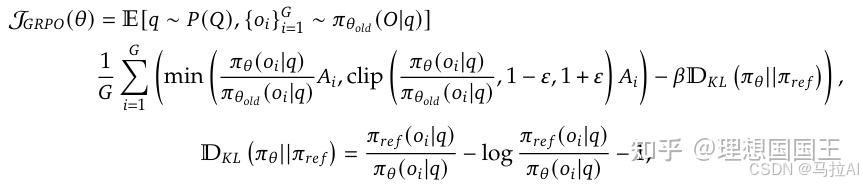
这个图太好看了,更清楚地了解了其损失是如何优化的。
GRPO去掉了价值函数,给出了r,这个功劳是DPO给的。
然后分组的价值函数进行优化,可以理解为一种多组DPO,r更高的就是所需的。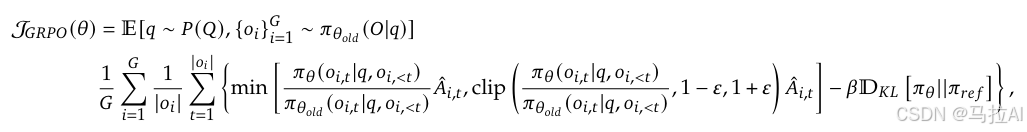
现在都是流行的DPO类的去价值函数XPO调优,因此其提出这个也是很好的idea。
(让我想到了一个好点子)
末结:
其已经非常接近GPT-4了,超域了其6月份推出的模型。当然后面o1又干回来了。
值得提的一点是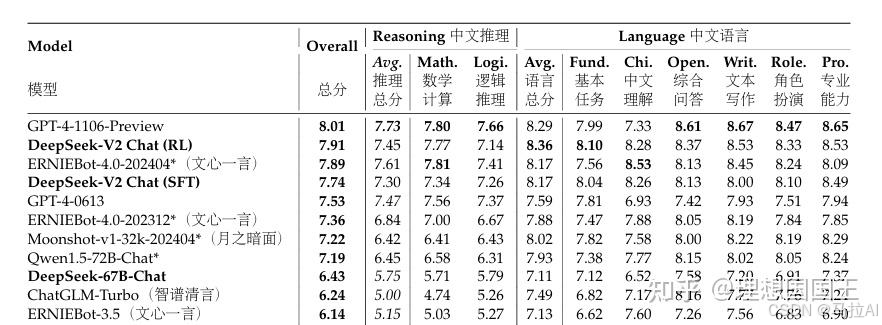
终于看到了论文中有中文出现了,不是我的翻译,而是论文自带,的泪目,说明科研的主体权逐渐也开始被中国AI占领。
已经开始打破我期望留学的念头了,清北能读个博我也是很愿意的。(虽然目前还是暂定NUS)
第五篇:DeepSeek-V3 Technical Report
集成了V2的MoE,各种省钱的训练法,MLA架构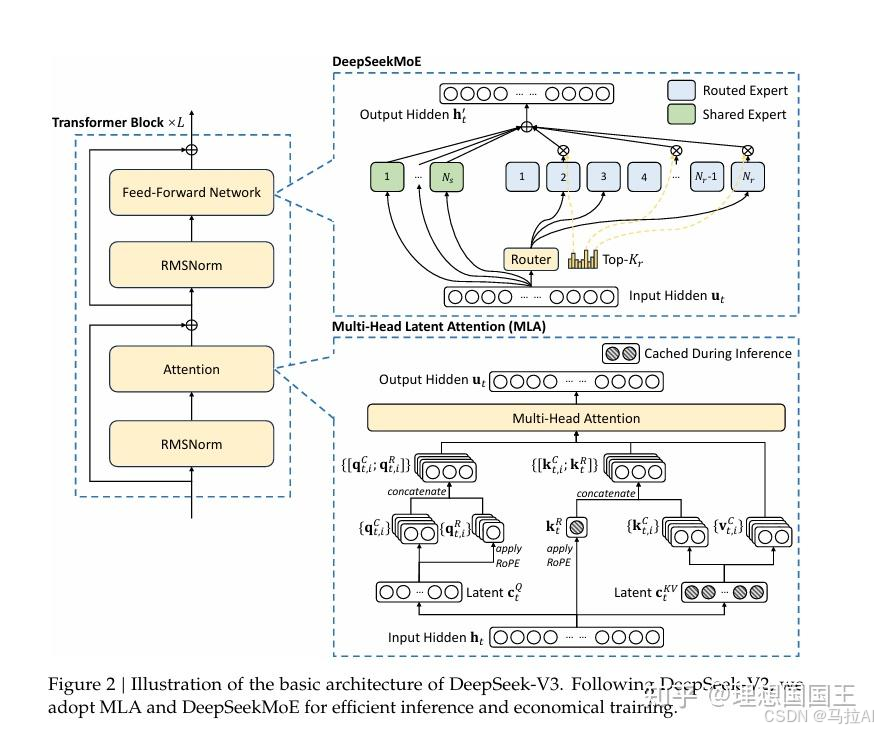
比V2多的就是MTP
MTP:
OMG,OMG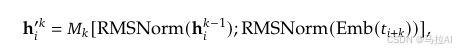
可以看到这个吗?这不是Eagle吗!哈哈哈哈哈,撞上了,和我研究的方向撞上了。
没事就是激动一下啊,这个MTP给了我很多灵感与idea。要复现这些idea我要花些时间了,等我的顶刊吧!希望能做出来,目前我的东西都还没做出来。55555
简单来说就是把上一层的隐藏层特征与本层的嵌入层特征给cat起来,然后做线性映射得到本层的隐藏层,这样做是合理的,Eagle这样做了得到了更好的预测,(不过Eagle是上一时刻,因为Eagle草稿模型就一层)
当然也有特定的训练方式
这个其实是一个交叉损失函数,就是把这个方法对齐了,没有什么其他更多的设计。
这个方法我认为确实能让train的精确,算是一种residual的网络映射思想。
结果也是祝贺V3超过4o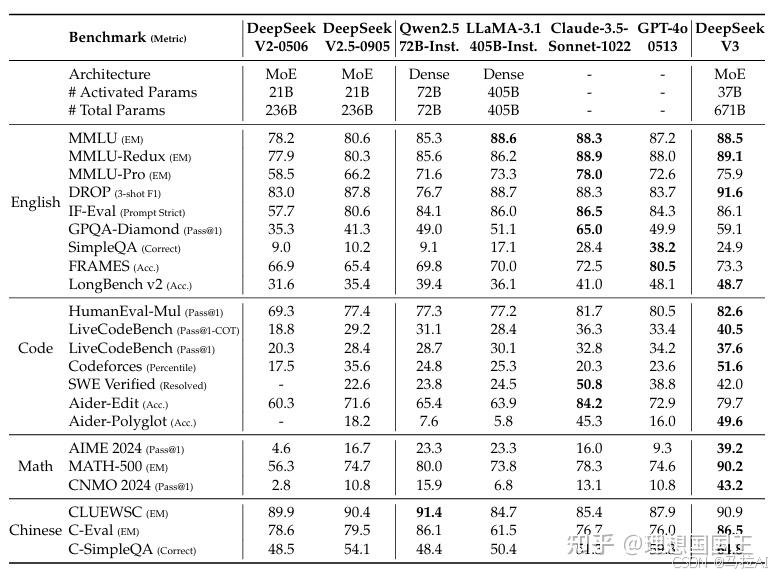
第六篇:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
本篇也就是网上解读的那般,DeepSeek-R1-Zero完全去掉了SFT,从pretrain直接到RL。
创新点:
1、cot的promote engineering,一个新的格式。
2、新的训练范式,无SFT直接RL。
关注点:
1、什么RL方法可以跳过SFT?其范式是怎么样的?
本文介绍了俩个模型,一个DeepSeek-R1-Zero,一个DeepSeek-R1
3.1DeepSeek-R1-Zero: Reinforcement Learning on the Base Mode
这是一个直接去掉SFT的模型,采用了GRPO直接RL。
3.1.1直接RL
也就是上文提到的GRPO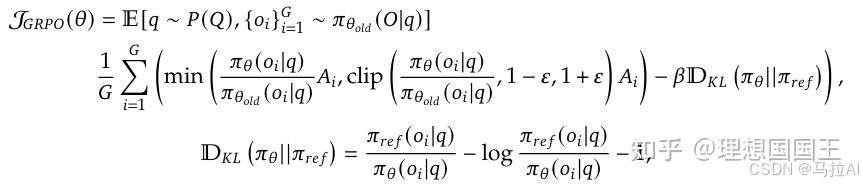

A的奖励函数被做了正则化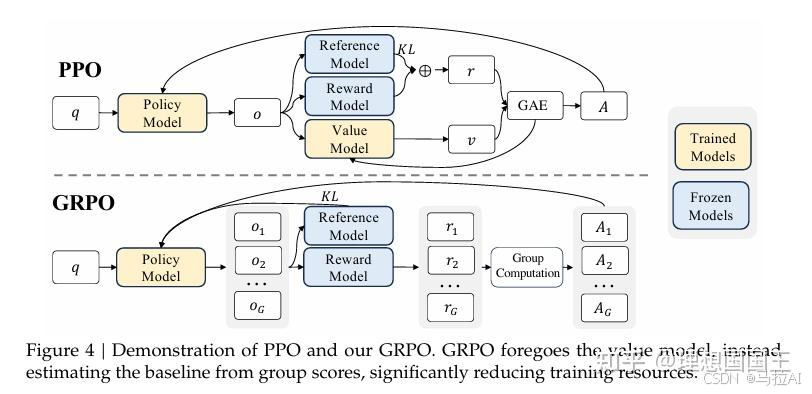
再结合一些奖励设置:格式奖励与准确性奖励。
论文没有给出对应的loss公式,其也没有开源其训练代码,所以我也不知道其具体如何将这种奖励组合计算的。
3.1.2新的promote engineering

这种反思格式很像Agent的反思架构,虽然其没有说参考了Agent的架构。
在训练中,这种promote Template也被train进去了。
目前这种提示工程设计多偏感性与哲学,可解释性低。(硬要解释就是Cot,Cot解释我可解释为:通过自我生成多种约束条件,从而达到更好的生成效果。)
这个格式作为一种格式奖励。
准确性奖励就是最后的推理结果进行直接验证。
不知道这几种奖励在r的具体计算方式,论文没有给出。
结论:
1、论文提到一个自我进化,论文把回答长度越来越长,称为思考的越来越多。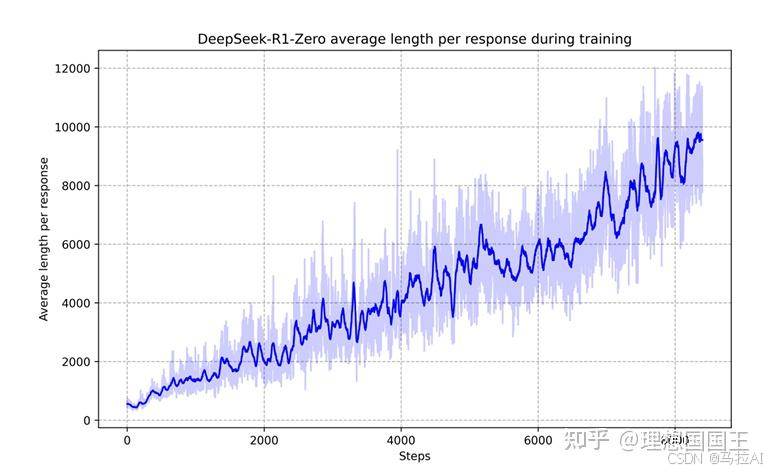
如果随着步长越来越长,回答长度越来越长且回答准确率越来越高,这确实是一种深度思考。
结合这俩张图来看,确实是对的。
2、顿悟时刻:论文把人的顿悟性回答称为transformer的顿悟现象。
也就是红色的回答,这样的顿悟本人认为是一种附加约束,可解释的话就是think模板的语料中或许有非常多这样的顿悟约束。
deepseek的哲学就是越像人越好约束。
从文本的内在特征联系这样确实是正确的。要解释的话可以放出顿悟时刻后的每个token对顿悟时刻每个token的最后一层注意力分数,或许这是一种约束力查看方式。(更多是一种讲故事的方式吧,可解释性差,前面的RL价值更大)
3.2DeepSeek-R1: Reinforcement Learning with Cold Start
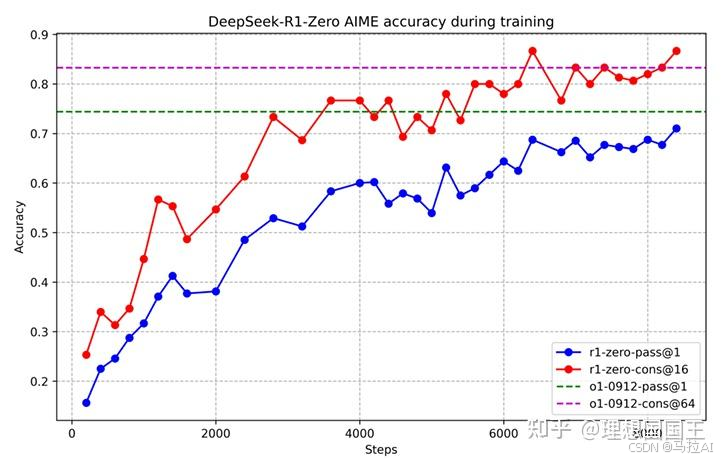
因为DeepSeek-R1-Zero早期的准确率太低了,浪费了很多步长。
文章用了这四个阶段做了这个收敛加速实现了DeepSeek-R1
用了俩个DeepSeek-R1,称为一号和二号吧。
- 冷启动:用了一点CoT的数据做监督微调一号DeepSeek-V3-Base。
- 面向推理的强化学习:冷启动后引入一致性的奖励,就是让语言相同(不要一会中文一会英文,可能是没有SFT直接RL的一个副作用),当然这个奖励的实现方式论文没有给出。
- 拒绝采样和监督微调:一号DeepSeek-V3-Base的RL收敛后提前终止,让其生产出推理与非推理数据。生产大概 80 万个样本,然后喂给二号DeepSeek-V3-Base进行SFT,
- 对二号DeepSeek-V3-Base的面向所有场景的强化学习:此处没有给出数据,就当他是全场景的数据都给一点进行rl吧。
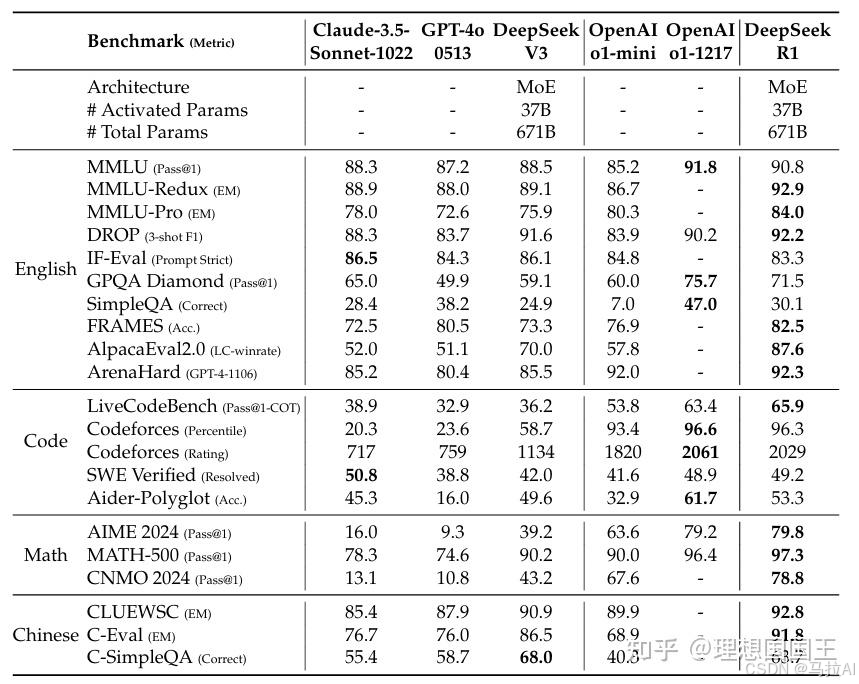
最后这样做成功在大部分benchmark上超过了o1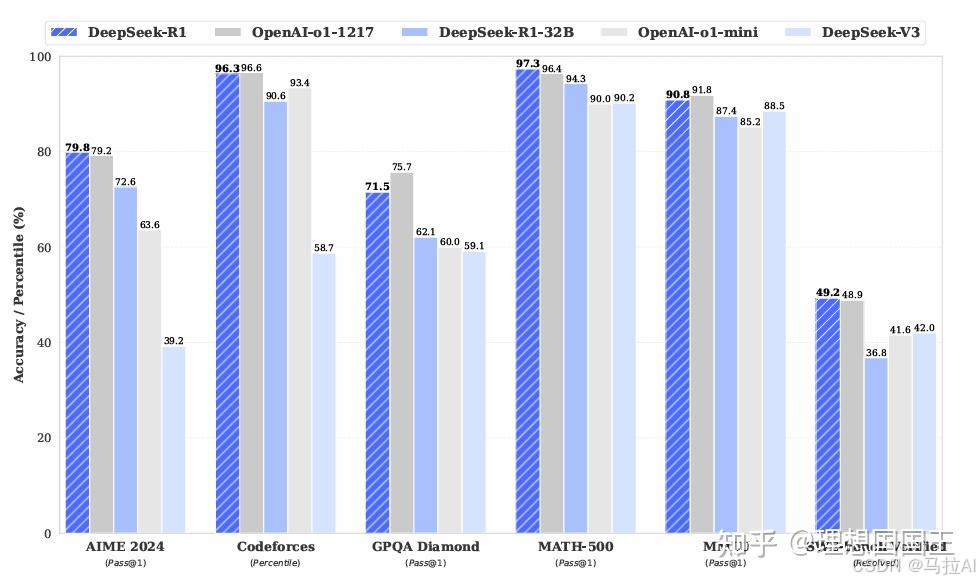
最后恭喜一下deepseek吧,希望能把ai话语权移到中国来,这样我就不用去北美学ai了。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)