必看!DeepSeek-R1 :知识蒸馏与服务器硬件揭秘!
近期,DeepSeek 团队发布的 DeepSeek-R1 引发了 AI 领域的广泛关注。其将 670B 参数大模型的能力,通过强化学习与蒸馏技术成功迁移至 7B 参数的轻量模型中,这一成果不仅让蒸馏后的模型超越同规模传统模型,甚至接近 OpenAI 的顶尖小模型 OpenAI-o1-mini。这背后关键的知识蒸馏技术,正逐渐成为解决 AI 模型在实际应用中诸多难题的核心。
近期,DeepSeek 团队发布的 DeepSeek-R1 引发了 AI 领域的广泛关注。其将 670B 参数大模型的能力,通过强化学习与蒸馏技术成功迁移至 7B 参数的轻量模型中,这一成果不仅让蒸馏后的模型超越同规模传统模型,甚至接近 OpenAI 的顶尖小模型 OpenAI-o1-mini。这背后关键的知识蒸馏技术,正逐渐成为解决 AI 模型在实际应用中诸多难题的核心。
知识蒸馏技术解析
知识蒸馏是一种机器学习技术,旨在把预先训练好的大型模型(教师模型)的学习成果转移到较小的 “学生模型” 中。在深度学习里,它作为模型压缩和知识转移的形式,在大规模深度神经网络应用中发挥重要作用。
其工作原理如下:首先选择一个训练好、泛化性能和表示能力出色的深度学习模型作为教师模型。教师模型对训练数据集进行预测,生成包含输入数据丰富信息的软标签(概率分布)。接着初始化一个相对简单的学生模型,其参数初始化可从教师模型随机选取或采用其他策略。然后定义损失函数,如常用的 Kullback-Leibler (KL) 散度和交叉熵,来衡量学生模型输出和教师模型软标签之间的差异。为确保准确性,学生模型还需直接学习真实标签。通过温度参数调整软标签平滑程度,温度高时,概率分布平滑,利于学生模型学习泛化特征;温度低时,分布接近真实标签,便于学习具体信息。最后,利用损失函数指导学生模型训练,训练中不断评估和优化其性能。
知识蒸馏与 GPU
在知识蒸馏过程中,GPU(图形处理器)扮演着至关重要的角色。无论是教师模型的训练,还是学生模型在模仿教师模型输出时的复杂计算,都需要强大的计算能力支持。GPU 具有大量的计算核心,能够并行处理多个任务,大大加速了深度学习模型训练和推理过程。
以 DeepSeek-R1 的模型蒸馏过程为例,将 670B 参数大模型的知识迁移到 7B 参数模型,涉及海量数据的计算和复杂的算法运算。GPU 可以在短时间内完成大量矩阵乘法、卷积运算等操作,显著缩短模型训练和蒸馏的时间。如果没有 GPU 的并行计算能力,完成这样大规模的模型蒸馏任务可能需要耗费数倍甚至数十倍的时间,这对于追求高效和快速迭代的 AI 研发来说是难以接受的。
知识蒸馏与服务器
服务器是支撑 AI 模型训练和部署的基础硬件设施,在知识蒸馏技术应用中同样不可或缺。在模型训练阶段,服务器提供稳定的运行环境和强大的数据存储与处理能力。大规模的训练数据集需要存储在服务器的高性能存储设备中,服务器的 CPU(中央处理器)和内存协同工作,负责调度和管理数据的读取与传输,配合 GPU 进行模型训练。
当涉及到多个 GPU 并行计算时,服务器的网络架构至关重要。高速、低延迟的网络连接可以确保多个 GPU 之间的数据传输顺畅,提高计算效率。例如,在知识蒸馏过程中,可能需要同时使用多台服务器上的多个 GPU 进行分布式训练,服务器之间的网络性能直接影响整个蒸馏任务的进度和效果。
在模型部署阶段,服务器的性能决定了模型能否在实际应用场景中稳定运行。对于经过知识蒸馏得到的小型模型,虽然其计算需求相对降低,但仍然需要服务器提供稳定的计算资源和网络服务,以满足实时或近实时推理的需求。特别是在移动设备和嵌入式系统等资源受限环境下,服务器需要对模型进行优化和适配,确保模型能够在这些设备上高效运行。
DeepSeek-R1 的成功体现了知识蒸馏技术的巨大潜力,而 GPU 和服务器作为底层硬件支撑,为知识蒸馏技术的应用和发展提供了坚实保障。随着 AI 技术的不断发展,知识蒸馏技术与硬件设施的协同发展将推动 AI 模型在更多领域实现更高效、更广泛的应用。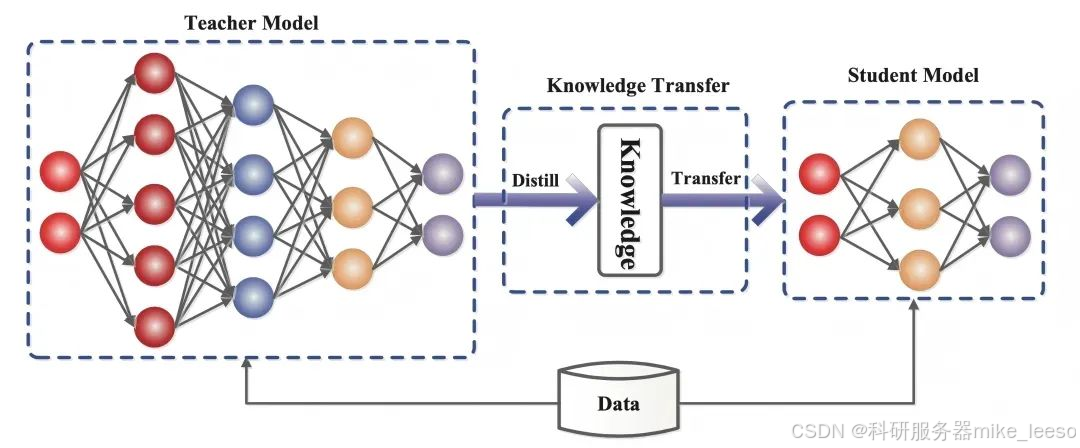

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)