
DeepSeek低成本高性能助推AI芯片厂商Cerebras爆单
AI 芯片厂商 Cerebras 部署 DeepSeek 服务后订单如潮水般涌来,出现爆单的火爆局面。DeepSeek 低成本高性能如何助力 Cerebras 爆单?
近期,一则令人瞩目的消息在科技界迅速传播:AI 芯片厂商 Cerebras 部署 DeepSeek 服务后订单如潮水般涌来,出现爆单的火爆局面。DeepSeek 低成本高性能如何助力 Cerebras 爆单?
DeepSeek-R1的技术突破
成本革命性下降
DeepSeek-R1的预训练成本仅为同类主流模型(如GPTo1)的十分之一,其训练算力租赁费用约600万美元,显著低于Meta Llama3.1405B的6000万美元。通过模型蒸馏技术,可将大模型压缩为小模型(如Llama70B)且精度几乎无损,进一步降低推理成本。
开源生态优势
DeepSeek-R1是首个顶级开源推理模型,允许企业基于HuggingFace公开的模型参数进行二次开发。这种开放性使得Cerebras等厂商能快速优化硬件适配,无需依赖闭源模型的黑箱调整。
性能对标头部产品
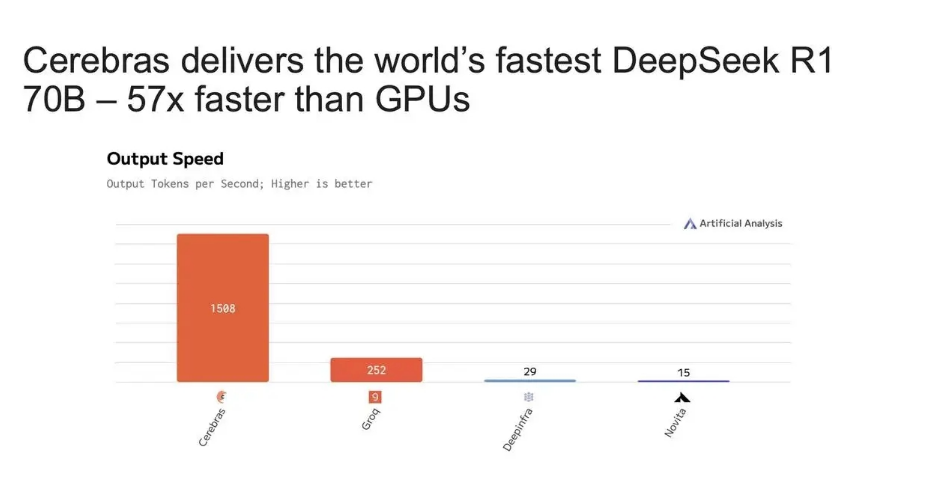
在数学与编程任务中,DeepSeek-R1的响应速度比OpenAI-o1快57倍,生成国际象棋代码仅需1.5秒(OpenAI需22秒)。其70B版本在Cerebras芯片上实现1508 tokens/s的推理速度,远超GPU方案。

Cerebras芯片的技术适配
晶圆级芯片优势
Cerebras的WSE-3芯片采用12英寸晶圆级设计,集成4万亿晶体管与90万AI核心,提供125PFLOPS峰值算力。其片外内存支持1.2PB容量,可高效处理DeepSeek-R1的6710亿参数模型。
推理服务提速
Cerebras基于WSE-3的CS-3超级计算机,部署DeepSeek-R1的推理速度比英伟达H100 GPU方案快10-20倍。与Mistral AI合作开发的LeChat应用实现每秒1100 tokens的响应速度,接近GPT-4o的10倍。
超节点部署能力
满血版DeepSeek-R1需要320个GPU的超节点部署,而Cerebras的晶圆级架构通过减少芯片间通信延迟,显著提升多节点协同效率,成为少数能承载超大规模推理的硬件商。
市场连锁反应
订单暴增现象
自2025年1月DeepSeek-R1发布后,Cerebras在10天内迎来需求激增,CEO Andrew Feldman直言"被订单压垮"。全球科技企业(包括微软、亚马逊云、英伟达)纷纷接入DeepSeek模型,间接推动Cerebras硬件采购。
行业格局冲击
DeepSeek的低成本模型迫使OpenAI调整技术路线,放弃单纯依赖Scaling Law的Orion项目,谷歌则加速推出Gemini 2.0 Flash以对标。花旗与银河证券均认为,这种成本下降将重塑AI芯片市场,边缘计算与混合云需求激增。
地缘政治影响
尽管美国部分机构以安全为由限制DeepSeek,但Cerebras通过托管服务规避风险,建议客户使用其本地化部署方案,成功平衡政策限制与市场需求。

未来趋势
端侧AI普惠化
DeepSeek的小模型蒸馏技术(如Llama70B适配)降低端侧部署门槛,云天励飞、中星微等厂商已将其整合至边缘计算芯片,预计将催生智能硬件新一轮升级周期。
供应链重构
英伟达GPU在训练端的垄断地位未受动摇,但推理市场出现分化。Cerebras、沐曦、燧原科技等通过适配DeepSeek模型,正在抢占推理芯片份额。
DeepSeek对Cerebras的作用体现在需求拉动、技术协同、市场定位强化三个层面:通过开源模型的高性价比和适配性,Cerebras不仅获得订单激增,还验证了其芯片在推理场景的领先性,从而在AI芯片竞争中占据独特优势。未来,双方在端侧AI和边缘计算领域的合作可能进一步扩大市场空间。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)