论文精读(3)——精读DeepSeek技术报告系列
关于Deepseek-V2版本技术点的创新确实很多,因此会发布三篇文章来深入浅出的讲解。这篇主要串一下整体的流程并详细讲解第一个技术创新:Multihead latent Attention(MLA);个人认为技术创新一定有规律遵循,就好比搭积木一点一点搭起来的,每理解清楚一层再走到下一层才会更加坦然
DeepSeek-V2:A strong, Economical, and efficient Mixture-of-Experts Language Model
paper:DeepSeek-V2
code:Github
关于V2版本技术点的创新确实很多,因此会发布三篇文章来深入浅出的讲解。这篇主要串一下整体的流程并详细讲解第一个技术创新:Multihead latent Attention(MLA);个人认为技术创新一定有规律遵循,就好比搭积木一点一点搭起来的,每理解清楚一层再走到下一层才会更加坦然
其实写这类型的文章并不轻松,一开始我只当做是对自己所学习的东西的总结和输出,但近日有人竟表示从其中学到了内容,这令我属实高兴,因此打算坚持下去,非常感谢有人对此的喜爱和支持!
前言
个人认为DeepSeek-V2是技术集合并第一次迸发的时候,关键的创新点其实有三个:
-
Multihead latent Attention(MLA), 应该是受到了LoRA的启发,同样做了个压缩向量,用于保存KV cache,性能上超过了MQA, GQA, 做到了既比肩MHA又减少KV cache;
-
DeepSeek MoE, 以MoE为基础进行创新,通过稀疏计算以经济的成本实现强大模型的计算;
-
Group Relative Policy Optimization (GRPO),群体相对策略优化,避免了像PPO那样需要额外的价值函数近似, 且使用对同一问题的多个采样输出的平均奖励作为基线
一、Introduction
1.预训练过程使用了更高质量的数据,所包含的中文数据量更多;
2.采用创新的模型架构,大幅度减少KV cache,提高运算效率;
3.微调时利用SFT+GPRO的策略,进一步使模型与人类偏好保持一致
二、Architecture
1.MLA:目的在于减少KV cache,提高推理效率。其实之前也有很多减少KV cache的方法,其中比较有名的包括Multi-Query Attention (MQA),Grouped-Query Attention (GQA),但是性能上为了减少缓存导致了降低,下图展示了MHA,MQA,GQA,MLA四者的架构:

(1)标准注意力机制:首先再次理解一下注意力机制:
q t = W Q h t , k t = W K h t , v t = W V h t \mathbf{q_t = W_Q h_t,k_t = W_K h_t,v_t = W_V h_t} qt=WQht,kt=WKht,vt=WVht
这里的 h t \mathbf{h_t} ht表示输入多头注意力中第t个token, W Q , W K , W V \mathbf{W_Q, W_K, W_V} WQ,WK,WV是随机初始化好的权重矩阵,通过模型的训练修改权重值(也就是可学习的);
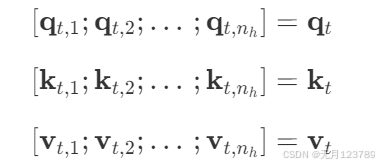
这里的 n h \mathbf{n_h} nh表示多头注意力的头数, q t , k t , v t \mathbf{q_t,k_t,v_t} qt,kt,vt的维度分别为 n h × d h \mathbf{n_h \times d_h} nh×dh
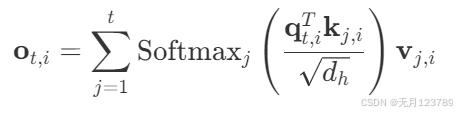
详细说下这个式子:首先注意到 q t \mathbf{q_t} qt和 k j , v j \mathbf{k_j, v_j} kj,vj两者下标不同,直观来看意思是一个 q t \mathbf{q_t} qt和 t \mathbf{t} t个 k j , v j \mathbf{k_j, v_j} kj,vj进行计算,这便是精髓之处: q ( q u e r y ) \mathbf{q(query)} q(query)代表的是当前位置,对应的就是 t \mathbf{t} t; k ( k e y ) \mathbf{k(key)} k(key)代表的是每个token,当前位置要和前t个token都进行计算相关,再softmax呈现出概率分布形式,最后乘每个值向量 v ( v a l u e ) \mathbf{v(value)} v(value),i表示第i个头的注意力得分
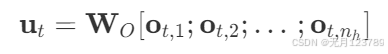
最后就是合成向量的形式
其实到这里为啥会有kv cache就很清晰了,在推理阶段每个token都要存储 2 n h d h l \mathbf{2n_h d_h l} 2nhdhl个矩阵(l表示层数),可想而知这是十分巨大的缓存了
(2)Low-rank key-value joint compression:低秩联合压缩
个人认为受到LoRA启发,也在k,v之间加入了压缩向量,用于保存kv cache,具体方法如下:
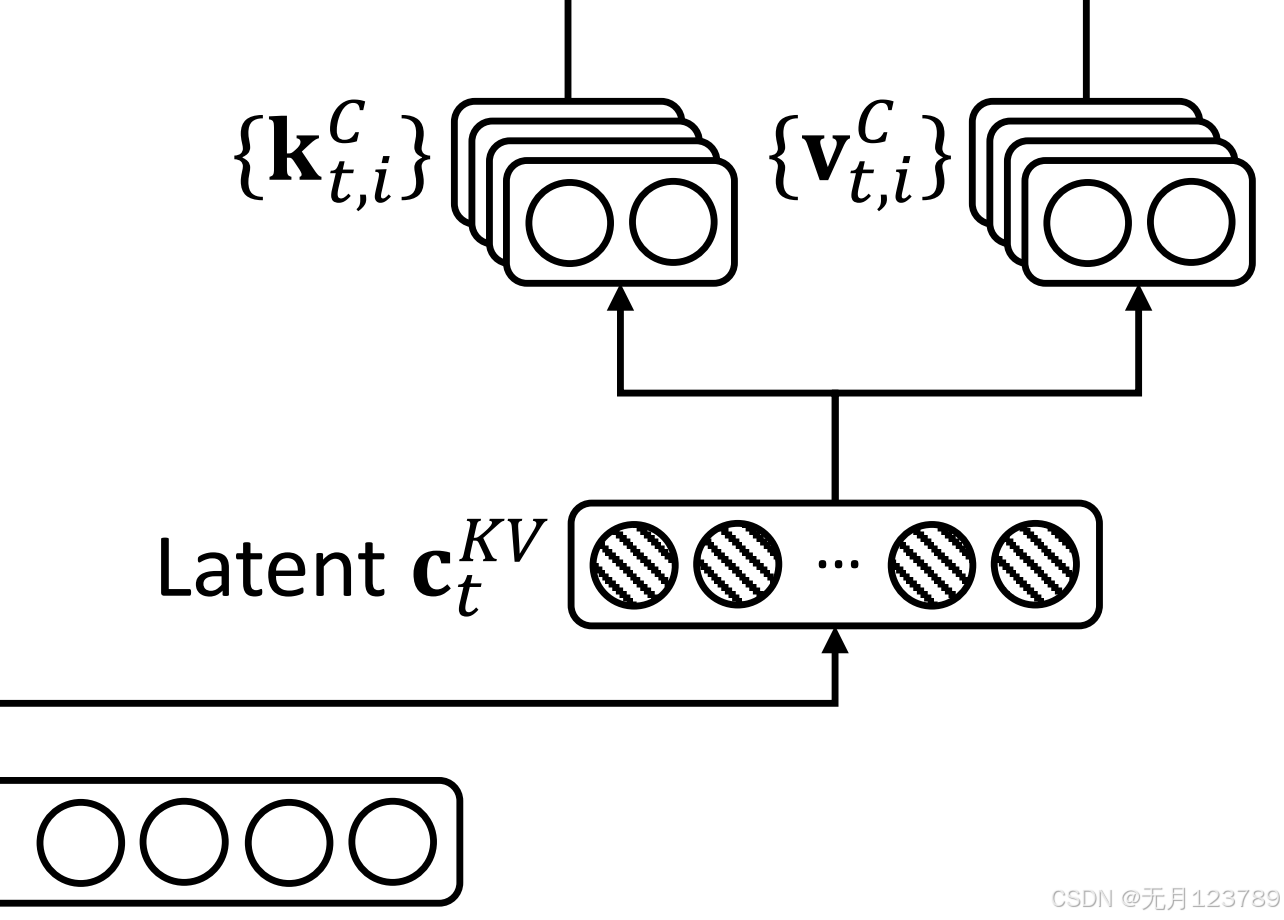
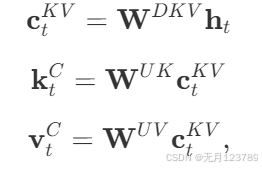
-
首先先将kv cache压缩到一个潜在向量 c t K V \mathbf{c_t}^{KV} ctKV中,其实就用了一个降维映射矩阵 W D K V \mathbf{W}^{DKV} WDKV和模型输入 h t \mathbf{h_t} ht得到,这里的维度将会远远小于 n h d h \mathbf{n_h d_h } nhdh维度
-
然后再用 W U K \mathbf{W}^{UK} WUK和 W U V \mathbf{W}^{UV} WUV两个升维矩阵将其还原为为 k t C \mathbf{k_t}^{C} ktC和 v t C \mathbf{v_t}^{C} vtC,这样就减少了kv cache的大小,提高了推理效率
-
在推理过程中,仅需要缓存压缩向量部分,再还原回去即可
接下来对q压缩升维,虽然并没有减少缓存,但显著降低了训练过程中的激活内存,和对kv的处理一样,如下所示:
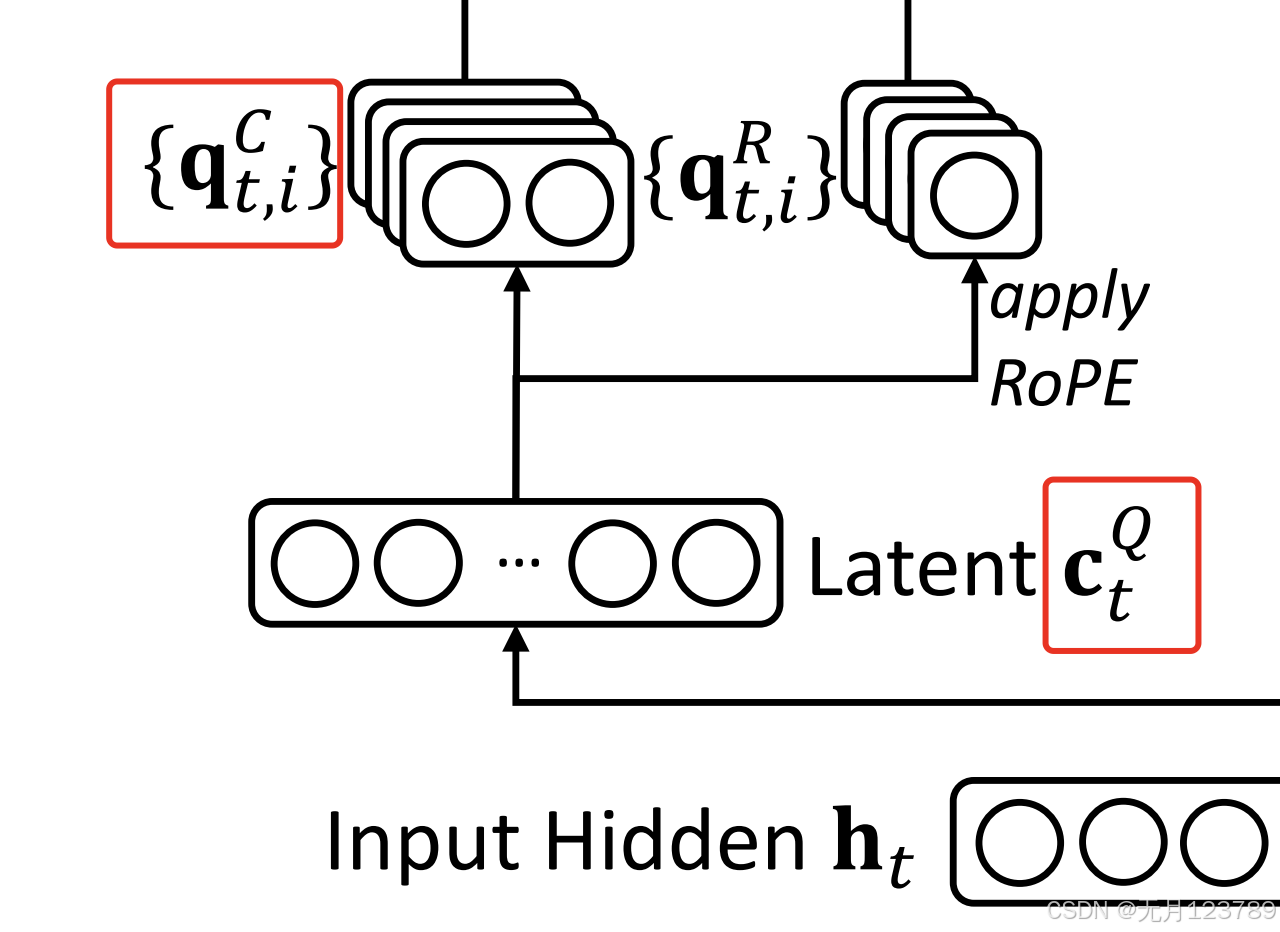
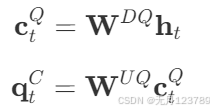
也是利用了降维映射矩阵 W D Q \mathbf{W}^{DQ} WDQ和升维矩阵 W U Q \mathbf{W}^{UQ} WUQ对q进行压缩
(3) Decoupled Rotary Position Embedding:解耦旋转位置嵌入
由于利用MLA会导致信息压缩,压缩后的信息放入位置编码是不等价于完整的Q和K上应用位置编码(因为压缩信息会导致信息损失),也就是说MLA和RoPE不兼容
为了解决这个问题,DeepSeek-V2在Q和K的结尾处加入了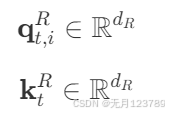
这两部分来承载RoPE,也就是将信息存储和旋转位置编码分开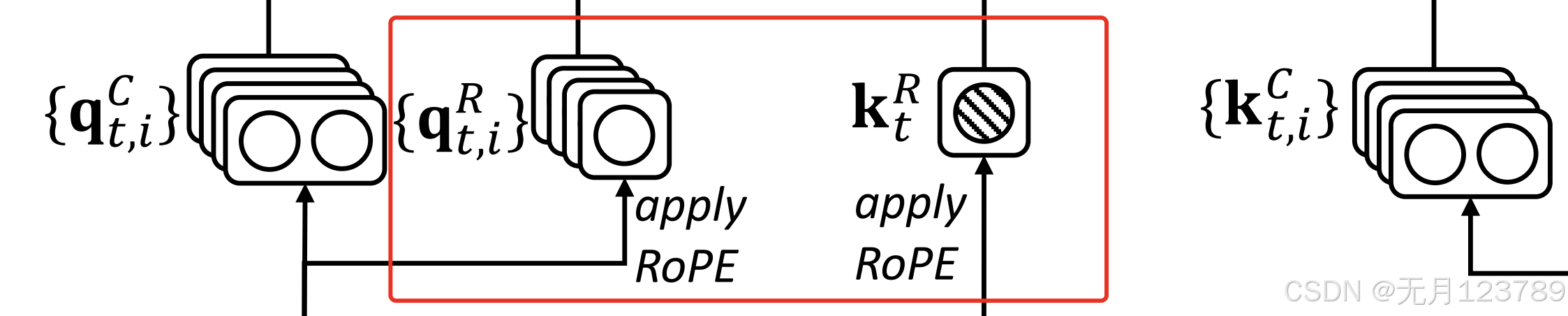
MLA+RoPE结合后的图和式子如下所示:
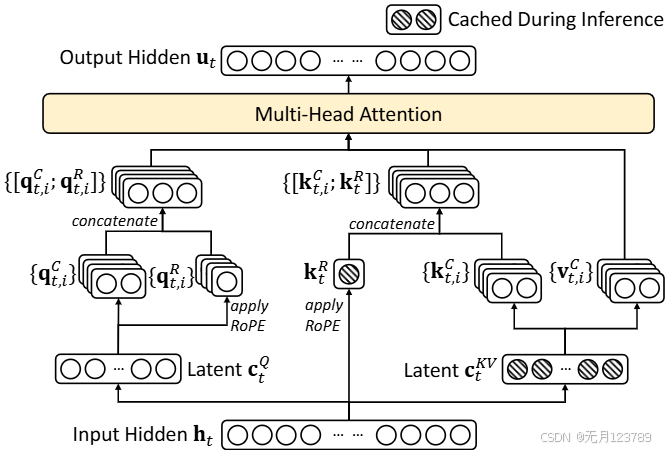
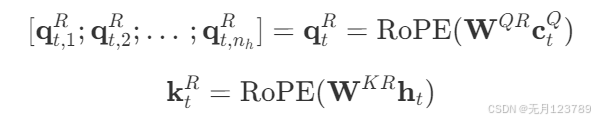
这里就是设计的两个变量
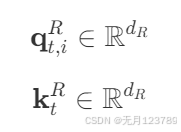
对其进行旋转位置编码并插入到一起进行注意力计算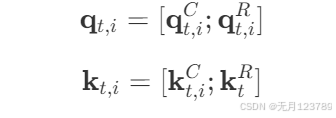
带信息压缩的是 q t , i C , k t , i C \mathbf{q}_{t, i}^C,\mathbf{k}_{t, i}^C qt,iC,kt,iC,带旋转位置编码的是 q t , i R , k t R \mathbf{q}_{t, i}^R,\mathbf{k}_{t}^R qt,iR,ktR,两者结合后再进行注意力计算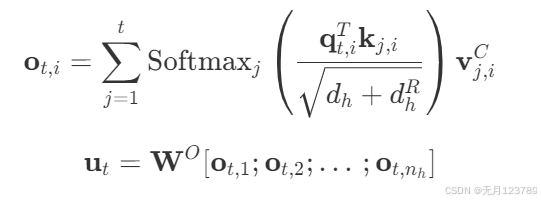
这里有一个点需要特别强调一下,注意这两个式子:
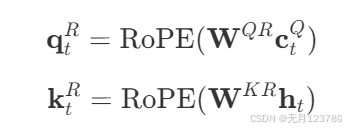
会发现对q进行旋转位置编码是压缩向量 c t Q \mathbf{c_t}^{Q} ctQ,而对k进行旋转位置编码是模型输入 h t \mathbf{h_t} ht,也就是k不进行降维升维这一操作直接进行位置编码,而q是降维后进行位置编码的
因此单个token所包含的缓存为 ( d c + d h R ) l \mathbf{(d_c + d_h^R)l} (dc+dhR)l,即使如此也远小于先前的 2 n h d h l \mathbf{2n_h d_h l} 2nhdhl
2.DeepSeekMoE:以经济成本训练强大的模型
后面会专门写一篇文章来讲解,从最基础的MoE开始直到DeepSeekMoE架构的生成,这里简单说下创新的地方:
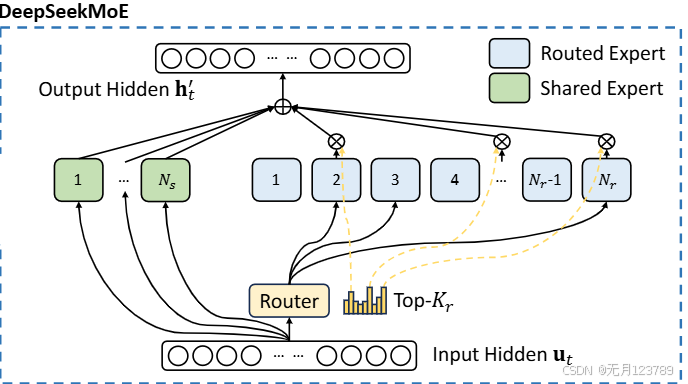
首先从1到Ns为共享专家的数量,这一部分的专家是一直保持激活状态的,剩余的从1到Nr就是普通的专家;流程就是隐藏层部分输入进来后经过Router对输入进行softmax成为概率分布,再利用top-k选择最高概率部分的专家激活,这部分激活后再乘以对应的权重求和即可
另一个创新点在于细粒度专家分割,也就是拆分FFN中间的隐藏维度,将其减少到1/m,也就是分成了m个更小的FFN,那么增加激活专家的数量到𝑚倍,以保持相同的计算成本。潜在的组合,组合灵活性的激增增强了实现更准确和有针对性的知识获取的潜力
最后由于设备数量有限,就提出了受设备限制的路由机制:在选前k个的基础上,确保每个token目标专家分布在至多M个设备中
三、Pre-training
大体的训练流程几乎和Deepseek LLM类似,可以关注我先前写的文章:DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
这里再简略提及一下:
1.数据构建:沿着之前67B的数据集,扩充了数据集并提升了数据质量。优化清理流程从而恢复大量误删的数据;并采集了更多的中文数据,过滤了具有争议性的数据等
分词器(tokenizer)同样采用BBPE算法,共8.1T数据
2.超参数设置:
(1)模型超参数:
- 60层Transformer,隐藏层5120,对每个可学习的部分采用0.006标准差随机初始化;
- MLA部分,注意力头数 n h \mathbf{n_h} nh为128,压缩向量维度 d c \mathbf{d_c} dc为512,查询压缩向量维度 d c ′ \mathbf{d_c'} dc′为1536,解耦的查询和键值,每头维度 d h R \mathbf{d_h^R} dhR为64;
- DeepSeekMoE部分,将除了第一层外所有的FFN都设置为MoE,2个共享专家数量,160个路由专家数量;隐藏维度1536,每个token会激活6个专家,
- 由于低秩压缩和细粒度专家分割将影响层的输出规模,因此,在实践中,在压缩的潜在向量之后使用额外的RMSNorm层,并在宽度瓶颈处(即压缩的潜在向量和路由专家的中间隐藏状态)乘以额外的缩放因子,以确保训练的稳定性
(2)训练超参数:
- AdamW优化器,超参数设置为:β₁ = 0.9,β₂ = 0.95,权重衰减 = 0.1;
- 学习率采用热身 - 阶跃衰减策略进行调度;最初,在前2000步中学习率从0线性增加到最大值;随后,在训练了大约60%的标记(token)后,学习率乘以0.316;在训练了大约90%的标记后再乘以0.316;最大学习率设定为2.4×10⁻⁴,梯度裁剪范数设定为1.0;
- 还使用一种批次大小调度策略,在训练前2250亿个标记时,批次大小从2304逐渐增加到9216,然后在剩余训练中保持9216不变;
- 将最大序列长度设定为4000;
- 利用管道并行将模型的不同层部署在不同设备上,并且对于每层,路由专家将均匀部署在8个设备(D = 8)上。
- 对于设备受限的路由,每个标记最多发送到3个设备(M = 3);
- 对于平衡损失,我们将α₁设为0.003,α₂设为0.05,α₃设为0.02
3.基础设施
基本和Deepseek-LLM相同,可以看我先前详细写的;
4.长上下文扩展:
由于大模型的input horizon一般来说越大越好,因此会有很多大模型长度扩展的方法,这里采用的是YaRN,让窗口长度从4K扩展到128K;
对于YaRN,该研究将比例s设置为40,α设置为1,β设置为32,并且将目标最大上下文长度设置为160K。在这些设置下,可以预期到该模型在128K的上下文长度下能够有良好的响应
5.评估过程可以直接看原文,这里不再详细展示各种实验结果
四、Alignment
1.SFT:基于之前的Deepseek-LLM的研究,整理了包含 150 万实例的指令微调数据集,其中包括 120 万个有用性实例和 30 万个安全性实例
同样为了评估DeepSeek-V2 Chat
- 基于生成的基准测试
- 指令跟随评估IFEval
- 使用LiveCodeBench 问题来评估聊天模型
- 还在开放式对话基准测试中评估模型
2.Reinforcement Learning(RL)
因为我自己对RL研究不多,所以下文只是对原论文内容做了个简略的介绍,更多内容可以看原论文
采用GPRO算法;

在具体的训练策略上,采用了两阶段的强化学习训练策略,首先进行推理对齐,然后进行人类偏好对齐

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)