DeepSeek+Camel多智能体框架万字核心解析(附代码)
Hello,大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列是作者参加DataWhale 2025年2月份组队学习的技术笔记文档,这里整理为博客,希望能帮助学习Agent的开发者少走弯路!在上一篇文章中,我们详细讲解了Camel的基本环境配置,为后续的学习打下了坚实的基础。本文将深入探讨Camel的Agent设计思想及其完整组成。通过本文,你将全面了解Camel Agen

前言
Hello,大家好,我是
GISer Liu😁,一名热爱AI技术的GIS开发者。本系列是作者参加DataWhale 2025年2月份组队学习的技术笔记文档,这里整理为博客,希望能帮助学习Agent的开发者少走弯路!
在上一篇文章中,我们详细讲解了Camel的基本环境配置,为后续的学习打下了坚实的基础。本文将深入探讨Camel的Agent设计思想及其完整组成。通过本文,你将全面了解Camel Agent的核心概念、设计理念以及实际应用中的关键点。本文篇幅较长,内容丰富,适合收藏后反复观看和学习🙂🙂。
一、概论
1.什么是智能体?

理论上说,智能体指的是可以感知、思考并主动行动以完成预定目标的实体。它能够根据外界信息做出决策,并通过行为改变其所处环境,进而影响其长期目标的实现。
这样理解很抽象🤔,让我们从技术角度出发:
AI Agent是一个以 大语言模型(LLM)为核心的程序,旨在实现用户设定的一些目标或任务。LLM获取反馈信息,并选择使用预设或新建的工具(函数),以迭代运行方式完成任务。Agent拥有复杂的工作流程,模型本质上可以自我对话,而无需人类在每一部分驱动和交互。
🤔其具有以下性质,以基于《Minecraft》的VOYAGER项目为例:

-
- 自主性(Autonomy)
VOYAGER通过 **自动课程(Automatic Curriculum)和技能库(Skill Library)**实现高度自主决策。它能根据当前环境状态(如物品库存、地理位置、时间等)自动生成任务,并独立执行代码以完成目标。例如,当Agent检测到拥有木镐和石头时,会自动规划“制作石镐”任务,而无需人工干预。此外,其技能库通过存储已验证的代码片段(如挖矿、熔炼等),支持复杂行为的复用与组合,进一步强化了自主性。
-
- 响应性(Reactivity)
VOYAGER通过环境反馈和迭代式提示机制实时调整行为。例如,当代码执行失败时(如制作铁甲缺少铁块),系统会将错误信息反馈给GPT-4,后者据此优化代码直至任务完成。同时,Agent能感知昼夜变化和附近实体(如僵尸),动态调整策略(如夜晚优先攻击怪物)。这种实时响应机制确保了任务的高效推进。
-
- 主动性(Proactivity)
VOYAGER的自动课程系统基于“最大化探索多样性”的目标,主动生成难度递增的任务。例如,在沙漠环境中优先学习采集沙子而非冶铁,避免因资源不足而卡关。此外,Agent通过自我验证模块主动判断任务完成度,并在失败时生成改进建议,形成“探索-优化-再探索”的闭环。
-
- 适应性(Adaptability)
VOYAGER通过终身学习能力持续提升技能。其技能库利用向量数据库存储代码的语义嵌入,当新任务出现时,可快速检索相似技能并组合调用,显著减少重复试错。实验表明,VOYAGER解锁科技树(如从木器到钻石工具)的速度比基线方法快6-15倍,且能零样本迁移到新世界,验证了其强大的适应能力。
-
- 社交能力
虽然Agent的通用定义包含社交性(与其他Agent协作),但VOYAGER的设计更侧重于单智能体的开放式探索,未明确提及与其他Agent或玩家的交互机制。其核心交互对象为环境本身,而非多智能体协作场景。这里应该看MetaGPT的狼人杀游戏,以及ChatDev的合作开发;
2.智能体的分类
智能体(Agents)作为人工智能领域的重要组成部分,已经在多个行业中展现出其强大的能力。从虚拟助手到复杂的多智能体系统,智能体根据其功能、目的和交互方式可以分为不同的类型。本文将详细介绍四种常见的智能体类型:任务型智能体、学习型智能体、协作型智能体和对话型智能体。
| 类型 | 定义 | 特点 | 应用场景 | 示例 |
|---|---|---|---|---|
| 任务型智能体 | 专注于完成具体的任务,通常通过预设的功能和工具来执行特定的操作。 | - 专注于单一或特定范围的任务 - 通常具有明确的目标和执行路径 | 虚拟助手、智能客服、自动化脚本 | metagpt 或 llamaindex 中的单智能体,能够实现编码或写作任务 |
| 学习型智能体 | 通过与环境的交互不断优化其行为策略,通常采用强化学习等方法。 | - 能够从经验中学习并改进 - 通常具有记忆功能,能根据历史数据调整行为 | 个性化推荐系统、自适应控制系统 | ChatGPT 中的记忆功能,能够在对话中采集信息并优化后续交互 |
| 协作型智能体 | 多个智能体之间相互协作,形成多智能体系统来共同完成复杂任务。 | - 多个智能体之间能够传递信息和协调行动 - 适用于分布式决策和任务分解 | 复杂任务调度、分布式问题解决 | metagpt 的 Team 功能,llamaindex 和 camel 框架中的多智能体系统 |
| 对话型智能体 | 专注于自然语言处理和交流,能够与用户进行流畅的对话。 | - 强大的自然语言理解和生成能力 - 结合网络搜索、深度思考和 RAG 功能 | 对话机器人、语言模型、虚拟助手 | ChatGPT、DeepSeek 等,通过提示词工程和深度思考实现复杂对话功能 |
① 任务型智能体
🤔行业内常见的基本Agent大多属于任务型智能体,例如metagpt或llamaindex中的单智能体,其可以根据设计者构建的功能,工具和执行函数实现编码或写作的能力;

例如coze平台常见的这些明确任务的agent,就属于任务型agent
② 学习型智能体
这里作者在应用中见的不多,但是ChatGPT中的记忆功能,应该属于这里的学习型Agent,其在与用户的对话过程中就采集的一些预先信息,类似于个性化推荐系统的Agent版本😂;

这里是ChatGPT的记忆模块,其会在聊天过程中收集用户的信息以提供更好的服务;当然大多数平台的agent学习是在后端接口那边根据用户情绪态度打分,实现一定程度的基于人类反馈的强化学习;
③ 协作型智能体
如metagpt中提供的Team功能,llamaindex和camel框架中都提供了多智能体功能,多个agent之间相互传递信息,协作完成一项复杂任务,下面是一个ChatDev的例子;

斯坦福小镇也属于协作性多智能体Demo,我想宇树科技的具生智能机器狗也属于这个吧;🤔,当然这里仅仅是我的猜测😂!
④ 对话型智能体
常见的ChatGPT,DeepSeek都属于这类智能体,其实现相比于前三者简单,通常提示词工程应用较多,也拥有网络搜索,深度思考和RAG功能;


幽默~🤣🤣🤣
3.智能体框架发展时间线
作者整理了以下两年来一些重要智能体框架的发布历程,大家可以根据场景自行选择!🙂
| 框架名称 | 发布日期 | 描述 | 链接 |
|---|---|---|---|
| CAMEL | 2023年3月21日 | 旨在开发支持多智能体自主行为与交流的开源框架。 | CAMEL |
| Auto-GPT | 2023年3月30日 | 基于GPT-4,智能体能够自主进行决策并分步执行任务。 | Auto-GPT |
| HuggingGPT | 2023年3月30日 | 基于ChatGPT,通过Hugging Face模型解决多模态复杂任务。 | HuggingGPT |
| Westworld | 2023年4月7日 | 小镇模拟环境,展示AI智能体在社会环境中的交互与行为。 | Westworld |
| VOYAGER | 2023年5月25日 | 在Minecraft中通过大语言模型展示AI的自主学习能力。 | VOYAGER |
| MetaGPT | 2023年7月 | 将LLM转化为多个协作角色,完成软件开发过程的智能体框架。 | MetaGPT |
| ChatDev | 2023年8月28日 | 支持增量开发和多智能体协作的开发工具,适用于软件开发场景。 | ChatDev |
| XAgent | 2023年10月23日 | 具有工作记忆和自我反思能力的多功能自主智能体框架。 | XAgent |
| Amazon Bedrock | 2023年11月 | 支持企业级应用的智能体开发平台,支持Claude、Llama等多种模型。 | Amazon Bedrock |
| OpenAssistant | 2024年1月 | 旨在构建开放透明的AI助手生态系统,支持多语言和多任务处理。 | OpenAssistant |
| Ray | 2024年 | 分布式计算框架,支持大规模强化学习和智能体协作。 | Ray |
| OpenAI Swarm | 2024年初 | OpenAI推出的多智能体协作框架,简化了智能体的协调与任务分配。 | OpenAI Swarm |
作者最常用的就是Cursor的Agent模式,写代码,嘎嘎快👍👍👍!
4.Agent的设计原则与方法
在构建大型语言模型(LLM)驱动的智能体(Agent)时,遵循一系列设计原则和方法至关重要,以确保系统的有效性和可靠性。我们一般综训下面这个逻辑:
① 设计原则
- 目标导向性:每个智能体的行为应明确服务于预定目标。在设计时,需要清晰定义智能体的任务和预期结果,确保其所有操作都朝着这些目标前进。
- 模块化设计:将智能体的功能划分为独立的模块,如感知、决策和执行模块。这种模块化结构不仅提高了代码的可维护性,还增强了系统的灵活性和可扩展性。
- 迭代开发:采用迭代开发方法,首先实现基本功能,然后通过不断的测试和反馈来完善系统。在此过程中,注重收集和分析性能数据,根据实际运行情况调整设计参数和策略。
② 核心模块
一个典型的智能体包含三个核心部分:
- 感知模块:处理输入信息,如传感器数据或用户输入。
- 决策模块:制定行动计划,通常涉及规划和推理。
- 执行模块:实施具体行动,如控制硬件或调用外部API。
这三个模块形成一个完整的循环,使智能体能够持续有效地工作。

③ 采用设计模式
在LLM Agent的设计中,常用的设计模式包括:
- ReAct(Reason and Act):通过思维链引导LLM将复杂问题拆分,并一步步进行推理和行动。
- Plan and Solve:先进行任务规划,然后执行解决方案。
- REWOO:结合反思和优化的设计模式。
- 核心模块形成一个闭环,确保智能体能够持续运行
- 外部工具集成扩展了智能体的能力
- 迭代开发确保系统不断优化和提升
二、智能体的技术构成
现代智能体的实现通常基于几个核心技术模块,这些技术赋能智能体的认知、规划、记忆和工具使用能力。

1.Agent中LLM的意义
① Agent中的LLM
在AI智能体(Agent)的架构中,模型(Model) 是其核心组件,扮演着“大脑”的角色。它负责处理所有的输入和输出数据,能够根据任务需求执行文本分析、图像识别、复杂推理等操作。而在CAMEL框架中提供了一系列标准化且可定制的接口,并与多种组件无缝集成,用于大语言模型(LLM)的应用程序开发。
下面是Camel框架目前支持的模型:

② 通过 API 调用模型

在 CAMEL 中,模型的调用非常简便。通过 ModelFactory 的 create 方法,各位开发者可以快速创建并配置所需的模型。以下是调用模型的核心参数:
model_platform:指定模型平台(如智谱AI、DeepSeek等)。model_type:选择具体的模型类型(如 GLM-4、GPT-4 等)。model_config_dict:配置模型参数(如温度系数temperature等)。
下面我们使用DeepSeek进行调用:这里的模型参数兼容OpenAI的接口风格:
import os
from camel.agents import ChatAgent
from camel.configs import DeepSeekConfig
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=os.getenv("MODEL_TYPE"),
url=os.getenv("OPENAI_API_BASE"),
api_key=os.getenv("OPENAI_API_KEY"),
model_config_dict=DeepSeekConfig(temperature=0.2).as_dict()
)
# 设置系统提示
sys_msg = BaseMessage.make_assistant_message(
role_name="Assistant",
content="You are a helpful assistant.",
)
# 初始化代理
camel_agent = ChatAgent(system_message=sys_msg, model=model, output_language="zh")
user_msg = BaseMessage.make_user_message(
role_name="User",
content="你好,请向GIS开发者GISerLiu问好, 也向CAMEL AI 这个致力于自主交互式智能体研究的开源社区问好。",
)
# 调用模型
response = camel_agent.step(user_msg)
print(response.msgs[0].content)

具体的环境变量配置步骤看之前的文章,作者这里不作赘述!
2.任务规划和自我反思
① 任务分解和规划
首先Agents会将用户给定的一个大型任务,根据可行性和现有资源分解为更小的,可实现,可管理的子目标,从而能够有效的处理复杂的任务;这里我以一个WebGIS程序开发的任务为例,讲述如何利用LLM来进行任务分解和规划
我的提示词如下:
我现在要开发一款webgis程序,请你将完成这个任务的过程进行拆分。然后用json格式输出整个任务列表,便于我的循环,每个任务包括任务名称,任务类型,任务调用函数,任务完成状态,任务优先级等属性,请给我结果;
这里我以DeepSeek为例,测试其任务分解能力,其表现相对于其他模型,不会输出多余的信息,很适合用于格式化生成,我常常用它生成模拟数据,只需要给它需要的字段;😂😂😂;运行结果如下:
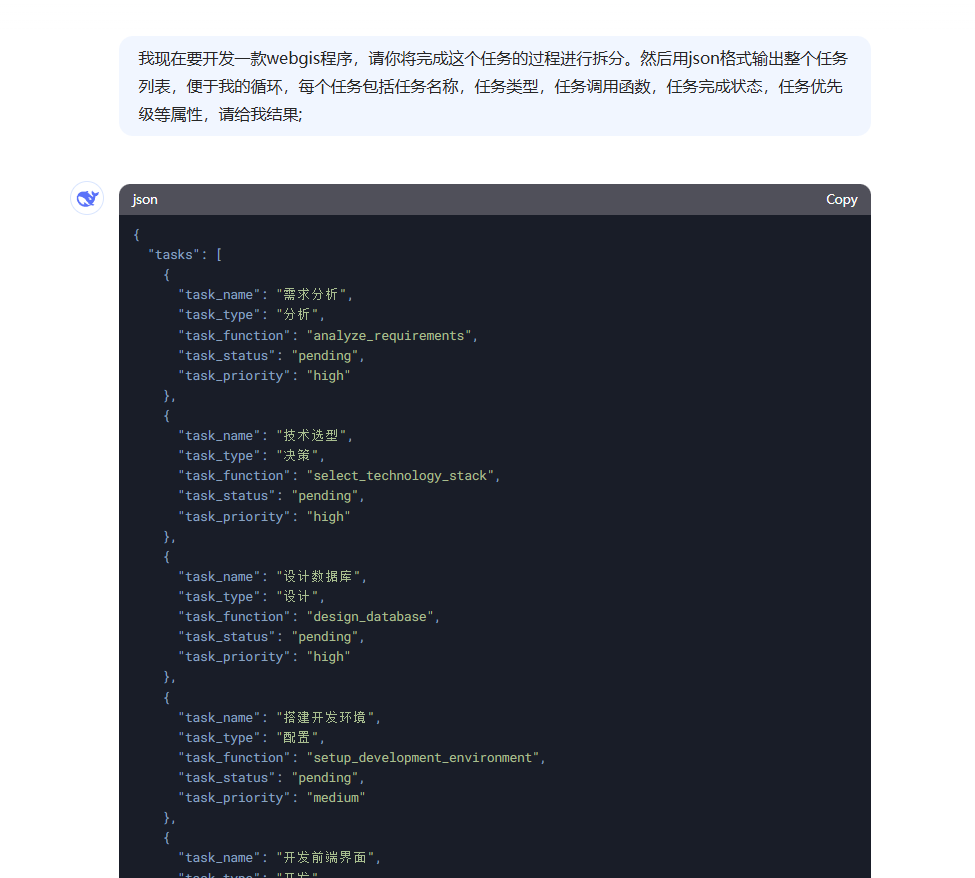
其完整的将我给它的任务进行了分解,我们可以对其迭代继续分解,直到我们得到原子任务树;我们只需要遍历这个原子任务树,便可以逐步解决完整问题;
下面是调用代码:
# 任务分解
# 测试OpenAI的模型调用是否成功
from openai import OpenAI
client = OpenAI(base_url="https://api.deepseek.com",
api_key='sk-Oxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx4a')
completion = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个项目管理,负责专业任务发布."},
{"role": "user", "content": "我现在要开发一款webgis程序,请你将完成这个任务的过程进行拆分。然后用json格式输出整个任务列表,便于我的循环,每个任务包括任务名称,任务类型,任务调用函数,任务完成状态,任务优先级等属性,请给我结果;"}
]
)
print(completion.choices[0].message.content)
输出如下:

② 自我反思
自我反思和自我优化:Agents可以对过去自己的操作行为或者输出内容进行自我批评和自我反思,然后从错误中总结经验,并在未来的输出和行为中进行优化,从而提高下一次结果的质量;
下面是测试代码:
import os
from colorama import Fore, Style, init
from camel.agents import ChatAgent
from camel.configs import DeepSeekConfig
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
# 初始化 colorama
init(autoreset=True)
# 初始化模型
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=os.getenv("MODEL_TYPE"),
url=os.getenv("OPENAI_API_BASE"),
api_key=os.getenv("OPENAI_API_KEY"),
model_config_dict=DeepSeekConfig(temperature=0.2).as_dict()
)
# 初始化 Critic 和 Ideator 的系统提示
critic_sys_msg = BaseMessage.make_assistant_message(
role_name="Critic",
content="你是一个严谨的评论员,专注于发现和改进想法的不足之处。你需要从逻辑、可行性和创新性等方面提出建设性批评。不要输出markdown格式,可以使用表情符号,更加真人,100字以内",
)
ideator_sys_msg = BaseMessage.make_assistant_message(
role_name="Ideator",
content="你是一个富有创造力的思想家,专注于提出新颖且可行的想法。你需要不断优化和改进自己的思想,并积极接受反馈。不要输出markdown格式,可以使用表情符号,更加真人,100字以内",
)
# 初始化 Critic 和 Ideator 代理
critic_agent = ChatAgent(system_message=critic_sys_msg, model=model, output_language="zh")
ideator_agent = ChatAgent(system_message=ideator_sys_msg, model=model, output_language="zh")
# 初始化反馈
critic_feedback = ""
ideator_feedback = ""
# 循环交互
for i in range(10): # 循环10次
print(Fore.YELLOW + "\n" + "=" * 50 + f" 第 {i + 1} 轮交互 " + "=" * 50 + "\n")
if i % 2 == 0:
# Ideator 提出想法
ideator_msg = BaseMessage.make_user_message(
role_name="Ideator",
content="请评论我的这个想法:设计一个自动将PDF文件转换为WORD文件的程序" + " " + ideator_feedback,
)
ideator_response = ideator_agent.step(ideator_msg)
print(Fore.GREEN + f"{ideator_agent.system_message.role_name}: {ideator_response.msgs[0].content}")
# Critic 评论
critic_msg = BaseMessage.make_user_message(
role_name="Critic",
content=ideator_agent.system_message.role_name + ": " + ideator_response.msgs[0].content,
)
critic_response = critic_agent.step(critic_msg)
print(Fore.RED + f"{critic_agent.system_message.role_name}: {critic_response.msgs[0].content}")
# 更新反馈
ideator_feedback = f"反馈:{critic_response.msgs[0].content}需要优化的地方有哪些?"
else:
# Critic 提出想法
critic_msg = BaseMessage.make_user_message(
role_name="Critic",
content="请评论我的这个想法:创造一个可以使用太阳能充电的智能手机" + " " + critic_feedback,
)
critic_response = critic_agent.step(critic_msg)
print(Fore.RED + f"{critic_agent.system_message.role_name}: {critic_response.msgs[0].content}")
# Ideator 评论
ideator_msg = BaseMessage.make_user_message(
role_name="Ideator",
content=critic_agent.system_message.role_name + ": " + critic_response.msgs[0].content,
)
ideator_response = ideator_agent.step(ideator_msg)
print(Fore.GREEN + f"{ideator_agent.system_message.role_name}: {ideator_response.msgs[0].content}")
# 更新反馈
critic_feedback = f"反馈:{ideator_response.msgs[0].content}需要优化的地方有哪些?"
运行结果如下:

有趣😎,商业互吹!
3.Agent如何使用工具
① 原理
Agent可以通过调用函数或API_获取模型权重和数据库中不存在的信息。常见的Agent工具包括网络检索工具、文件读写工具、API调用工具。例如,让Agent使用Google Search API,以及调用聚合数据来获取常见的天气信息和股票数据等。也可以通过访问高德API来获取位置,调用SD的API来实现图像生成。
微软的Copilot就是一个常见的案例,当用户输入问题时,它会分解问题,然后调用不同的工具来规划分解任务,调用工具检索,然后在代码生成器中执行。ChatGPT中的open-interpreter也是类似的思路;
下面作者对Agent工具调用的思想进行讲解:
- 工具支持:本质就是将现有的一切功能通过API接口和函数的方式交给Agent使用;

- 格式化参数提取:通过提示词工程LLM解析用户输入,并提取出结构化参数信息,然后输入到对应的工具API中,得到API反馈的结果;
- 提示词工程:然后将API或函数返回的结果通过提示词工程与其他信息包装起来输入给LLM,LLM按照要求生成回复,如此循环迭代,直到得到结果;

如图所示,这里从用户输入中提取出参数,然后根据线性流程或者并行流程输入到我们的工具流(工作流)中,得到规范的结果;最终合并输出;
在 CAMEL 框架中,工具(Tools) 和 多智能体协作(Multiple Agent Collaboration) 是两个核心概念。工具让 LLM 能够与外部世界交互,而多智能体协作则通过角色扮演和任务分解,实现复杂任务的自动化处理。
② 工具使用
在 CAMEL 框架中,工具(Tools) 和 工具包(Toolkits) 是增强 LLM 和 Agent 能力的关键组件。工具允许 LLM 与外部世界交互,而工具包则是为特定任务设计的工具集合。
记得安装pip install ‘camel-ai[tools]’
工具的基础使用
工具是 LLM 与外部世界交互的桥梁。我们可以通过定义工具,让 LLM 执行特定任务,如数学计算、搜索信息等。这里我们定义一个工具,支持以下功能:
- 列表数据的加减乘除。
- 统计指标计算:均值、方差、标准差等。
- 数据可视化:绘制折线图和柱状图。
from camel.toolkits import FunctionTool
import numpy as np
import matplotlib.pyplot as plt
def list_operations(data: list, operation: str, value: float = None) -> list:
r"""对列表数据进行加减乘除操作。
Args:
data (list): 输入的列表数据。
operation (str): 操作类型,支持 'add', 'subtract', 'multiply', 'divide'。
value (float): 操作的数值。
Returns:
list: 操作后的列表数据。
"""
if operation == 'add':
return [x + value for x in data]
elif operation == 'subtract':
return [x - value for x in data]
elif operation == 'multiply':
return [x * value for x in data]
elif operation == 'divide':
return [x / value for x in data]
else:
raise ValueError("不支持的操作类型。")
def calculate_statistics(data: list) -> dict:
r"""计算列表数据的统计指标。
Args:
data (list): 输入的列表数据。
Returns:
dict: 包含均值、方差、标准差的字典。
"""
mean = np.mean(data)
variance = np.var(data)
std_dev = np.std(data)
return {
'mean': mean,
'variance': variance,
'std_dev': std_dev
}
def plot_data(data: list, plot_type: str = 'line') -> str:
r"""绘制列表数据的图表。
Args:
data (list): 输入的列表数据。
plot_type (str): 图表类型,支持 'line' 和 'bar'。
Returns:
str: 图表保存的路径。
"""
plt.figure()
if plot_type == 'line':
plt.plot(data)
elif plot_type == 'bar':
plt.bar(range(len(data)), data)
else:
raise ValueError("不支持的图表类型。")
save_path = "plot.png#pic_center"
plt.savefig(save_path)
plt.close()
return save_path
# 用 FunctionTool 包装这些函数
list_operations_tool = FunctionTool(list_operations)
statistics_tool = FunctionTool(calculate_statistics)
plot_tool = FunctionTool(plot_data)
生成假数据
我们生成一些假数据来测试工具的功能。
# 生成假数据
data = [10, 20, 30, 40, 50]
print("原始数据:", data)
# 对数据进行加法操作
data_add = list_operations(data, 'add', 5)
print("加法操作后的数据:", data_add)
# 对数据进行乘法操作
data_multiply = list_operations(data, 'multiply', 2)
print("乘法操作后的数据:", data_multiply)
# 计算统计指标
stats = calculate_statistics(data)
print("统计指标:", stats)
# 绘制折线图
plot_path = plot_data(data, 'line')
print("折线图已保存至:", plot_path)
输出:


可想而知,这个功能蛮有用的!👍
将工具集成到 ChatAgent
我们将这些工具集成到 ChatAgent 中,让 LLM 能够调用工具完成任务。
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
from camel.toolkits import FunctionTool
import numpy as np
import matplotlib.pyplot as plt
# 加载环境变量
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
def list_operations(data: list, operation: str, value: float = None) -> list:
r"""对列表数据进行加减乘除操作。
Args:
data (list): 输入的列表数据。
operation (str): 操作类型,支持 'add', 'subtract', 'multiply', 'divide'。
value (float): 操作的数值。
Returns:
list: 操作后的列表数据。
"""
if operation == 'add':
return [x + value for x in data]
elif operation == 'subtract':
return [x - value for x in data]
elif operation == 'multiply':
return [x * value for x in data]
elif operation == 'divide':
return [x / value for x in data]
else:
raise ValueError("不支持的操作类型。")
def calculate_statistics(data: list) -> dict:
r"""计算列表数据的统计指标。
Args:
data (list): 输入的列表数据。
Returns:
dict: 包含均值、方差、标准差的字典。
"""
mean = np.mean(data)
variance = np.var(data)
std_dev = np.std(data)
return {
'mean': mean,
'variance': variance,
'std_dev': std_dev
}
def plot_data(data: list, plot_type: str = 'line') -> str:
r"""绘制列表数据的图表。
Args:
data (list): 输入的列表数据。
plot_type (str): 图表类型,支持 'line' 和 'bar'。
Returns:
str: 图表保存的路径。
"""
plt.figure()
if plot_type == 'line':
plt.plot(data)
elif plot_type == 'bar':
plt.bar(range(len(data)), data)
else:
raise ValueError("不支持的图表类型。")
save_path = "plot.png#pic_center"
plt.savefig(save_path)
plt.close()
return save_path
# 用 FunctionTool 包装这些函数
list_operations_tool = FunctionTool(list_operations)
statistics_tool = FunctionTool(calculate_statistics)
plot_tool = FunctionTool(plot_data)
# 创建模型实例
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
# 初始化 ChatAgent
agent = ChatAgent(
system_message="你是一个数据分析师,擅长处理列表数据并生成统计报告。",
model=model,
tools=[list_operations_tool, statistics_tool, plot_tool], # 集成工具
output_language='中文'
)
# 用户消息
usr_msg = "我有一个数据列表 [44, 65, 37, 56, 56],请计算其统计指标并绘制折线图。"
# 发送消息给 Agent
response = agent.step(usr_msg)
# 打印 Agent 的回复
print("\033[92mAgent 回复:\033[0m", response.msgs[0].content)
# 检查工具调用记录
print("\033[93m工具调用记录:\033[0m", response.info['tool_calls'])
输出:


③ Arivx工具包下载论文
工具包是为特定任务设计的工具集合。CAMEL 提供了多种内置工具包,如 SearchToolkit、MathToolkit 等。CAMEL 提供了多种内置工具包,涵盖从学术搜索到金融数据分析的多种任务。以下是部分工具包的介绍:
| 工具包名称 | 描述 |
|---|---|
| ArxivToolkit | 用于与 arXiv API 交互,搜索和下载学术论文。 |
| SearchToolkit | 用于执行网络搜索,支持 Google、Wikipedia 等搜索引擎。 |
| MathToolkit | 用于执行基本数学运算,如加法、减法、乘法等。 |
| WeatherToolkit | 用于获取城市天气数据,基于 OpenWeatherMap API。 |
| GitHubToolkit | 用于与 GitHub 仓库交互,包括获取问题和创建拉取请求。 |
| OpenBBToolkit | 用于访问和分析金融市场数据,包括股票、ETF、加密货币等。 |
使用 SearchToolkit
我们这里将使用 ArxivToolkit 来搜索和下载论文。
from camel.toolkits import ArxivToolkit
# 初始化 ArxivToolkit
arxiv_toolkit = ArxivToolkit()
# 获取工具列表
tools = arxiv_toolkit.get_tools()
# 打印工具列表
for tool in tools:
print(f"工具名称: {tool.get_function_name()}, 工具描述: {tool.get_function_description()}")
将工具包集成到 ChatAgent
我们可以将工具包中的工具集成到 ChatAgent 中,让 Agent 能够调用这些工具完成任务。完整代码如下:
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
from camel.toolkits import FunctionTool
import numpy as np
import matplotlib.pyplot as plt
from camel.toolkits import ArxivToolkit
# 加载环境变量
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
# 初始化 ArxivToolkit
arxiv_toolkit = ArxivToolkit()
# 获取工具列表
tools = arxiv_toolkit.get_tools()
# 打印工具列表
for tool in tools:
print(f"工具名称: {tool.get_function_name()}, 工具描述: {tool.get_function_description()}")
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
# 初始化 ChatAgent
arxiv_agent = ChatAgent(
system_message="你是一个学术助手,擅长搜索和下载 arXiv 上的论文。",
model=model,
tools=tools, # 集成 ArxivToolkit
output_language='中文'
)
# 用户消息:搜索 GIS 相关的最新论文
usr_msg = "搜索 GIS 相关的最新论文,并下载第一篇论文。"
# 发送消息给 Agent
response = arxiv_agent.step(usr_msg)
# 打印 Agent 的回复
print("\033[92mAgent 回复:\033[0m", response.msgs[0].content)
# 检查工具调用记录
print("\033[93m工具调用记录:\033[0m", response.info['tool_calls'])
输出:


可以看到,下载成功!🎉👍👍
4.Agent如何传递信息?
Camel中如何设计消息传递?答案是 Message🖼️ 机制!
① 什么是Message
想象一下,你和朋友聊天或向小爱同学发出指令时,每句话都是一个“包裹”,里面装着你想传递的信息,被传递给了代理。在AI世界里,Message就是这样的“快递小哥”,负责在用户和AI之间传递“包裹”。
- 这里的“代理”🤖 既可以是AI,也可以是人,也可以是一个能执行指令的智能程序
- 这里的“信息”📖 则是你传递的指令、问题或数据
为什么需要Message? 🤔
- 统一格式:就像快递单一样,Message为所有信息提供了标准格式和处理方式
- 多模态支持:不仅能传文字,还能传图片、视频,甚至自定义数据
- 上下文管理:帮助AI记住之前的对话,让聊天更连贯
在Camel框架中,BaseMessage是所有消息对象的基类,其为所有信息(文本,图片,视频)传递提供了统一的结构和标准化的处理方式;这样就可以提高代码的可维护性和可读性,为后续的功能模块(如消息过滤、路由、多轮对话管理)提供一个统一的数据基础;
下面是BaseMessage的参数配置:
- role_name:给消息一个容易辨识的名称,如 “User”、“Assistant” 或 “System”。在更复杂的场景中,可能会有多个用户或多个 Agent,通过
role_name可以帮助追踪消息来源。- role_type:角色类型一般来自
RoleType枚举,以明确此消息在对话中的身份。例如:RoleType.USER: 表示该消息来自用户。RoleType.ASSISTANT: 表示该消息来自智能助手。- content:消息的核心载体,一般是文本,也可能是解析指令、问题描述或描述性文字。
- meta_dict(可选):消息的可选元数据字典。
- video_bytes(可选):与消息关联的视频字节数据。
- image_list(可选):与消息关联的 PIL Image 对象列表。
- image_detail(可选):与消息关联的图像的细节级别,默认为
"auto"。- video_detail(可选):与消息关联的视频的细节级别,默认为
"low"。
ok,我们接下来在代码中使用试试看🙂:
② 消息类型
- 纯文本消息
from camel.messages import BaseMessage
from camel.types import RoleType
# 创建一个简单的用户消息
msg = BaseMessage(
role_name="User",
role_type=RoleType.USER,
content="你好,AI!",
meta_dict={} # 元数据,可以放一些额外信息
)
print(msg)
输出:

- 带图片的消息 🖼️
from camel.messages import BaseMessage
from camel.types import RoleType
# print(msg)
from PIL import Image
import requests
from io import BytesIO
# 下载一张图片
url = "https://f.chongwunet.com/chongwunet/202302/9c/ab17f49d6149ae.png#pic_center"
img = Image.open(BytesIO(requests.get(url).content))
# 创建带图片的消息
img_msg = BaseMessage(
role_name="User",
role_type=RoleType.USER,
content="看看这只猫!",
meta_dict={},
image_list=[img] # 把图片放进消息里
)
print(img_msg)
输出:

这里也可以放视频,,但是如果包含图片或视频信息时,meta_dict似乎要必须配置🫤
③ 消息操作:📨
这里我们通过demo创建与转换不同类型的消息
from camel.messages import BaseMessage
from camel.types import OpenAIBackendRole
# 创建用户消息
user_msg = BaseMessage.make_user_message(
role_name="GISer",
content="你好,ds!"
)
# 创建助手消息
assistant_msg = BaseMessage.make_assistant_message(
role_name="DeepSeek",
content="你好,佬儿!有什么可以帮你的?"
)
print("GISerLiu消息:", user_msg)
print("DeepSeek消息:", assistant_msg)
# 基于现有消息创建新消息
updated_msg = user_msg.create_new_instance("你好,ds!今天天气怎么样?")
print("更新后的消息:", updated_msg)
# 转换为字典
msg_dict = user_msg.to_dict()
print("消息字典:", msg_dict)
# 转换为OpenAI兼容格式
openai_msg = user_msg.to_openai_message(role_at_backend=OpenAIBackendRole.USER)
print("OpenAI格式消息:", openai_msg)
camel内置了方法快速生成系统、助手、用户消息的实例,并提供了相互转换的方法;

④ 与ChatAgent协作:让消息“活”起来 🤖
ChatAgent 是 CAMEL 系统中负责处理对话的核心组件。它不仅能处理文本消息,还能处理包含图片、视频等多模态信息的消息。下面我们通过一个完整的 Demo,展示如何与 ChatAgent 进行交互,包括文本对话和多模态消息处理。
- 1.首先,我们需要初始化 ChatAgent,并设置它的系统消息(用于定义 AI 的角色和行为)。
- 2.我们可以直接使用字符串与 ChatAgent 进行文本对话,ChatAgent 会自动将字符串转换为 BaseMessage。
- 3.ChatAgent 支持处理包含图片的多模态消息。我们可以通过 BaseMessage 将图片传递给 ChatAgent,并获取它的分析结果。
- 4.我们还可以在消息中添加元数据(
meta_dict),帮助 ChatAgent 更好地理解用户意图。
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType, RoleType
from PIL import Image
import requests
from io import BytesIO
import os
from dotenv import load_dotenv
# 初始化
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
chat_agent = ChatAgent(
model=model,
system_message="你是一个友好的助手,可以帮助用户回答问题或分析图片。",
output_language='zh'
)
# 文本对话
user_msg = "你好!你能做什么?"
response = chat_agent.step(user_msg)
print("助手回复:", response.msgs[0].content)
# 多模态消息:图片描述
url = "https://img0.baidu.com/it/u=2205376118,3235587920&fm=253&fmt=auto&app=120&f=JPEG?w=846&h=800"
res = requests.get(url)
print(res.content)
img = Image.open(BytesIO(res.content))
user_image_msg = BaseMessage.make_user_message(
role_name="User",
content="请描述这张图片的内容",
image_list=[img]
)
response_with_image = chat_agent.step(user_image_msg)
print("助手的图片描述:", response_with_image.msgs[0].content)
# 结合元数据
user_msg_with_meta = BaseMessage.make_user_message(
role_name="User",
content="我对人工智能框架感兴趣,能推荐一些吗?",
meta_dict={"兴趣领域": "人工智能框架"}
)
response_with_meta = chat_agent.step(user_msg_with_meta)
print("助手的回复:", response_with_meta.msgs[0].content)

因为deepseek并没有图片理解的接口,因此这里使用魔搭社区提供的通义千问的接口;
这个图片描述输出怪怪的?🤔
⑤ 解析 AI 的响应 🛠️
在 CAMEL 系统中,ChatAgentResponse 是 Agent 响应的核心数据结构。它不仅包含 AI 生成的消息,还提供了会话状态、调试信息等关键数据。让我们通过一个完整的 Demo 来深入理解它的用法。
▍ChatAgentResponse 的结构
一个典型的 ChatAgentResponse 对象包含以下三部分:
- 消息内容(
msgs)- 这是 AI 生成的消息列表,每条消息都是一个 BaseMessage 对象。
- 可能包含文本、图片、视频等多模态内容。
- 如果列表为空,表示消息生成失败。
- 会话状态(
terminated)- 一个布尔值,表示当前会话是否已结束。
True:会话已终止,AI 不会再回复。False:会话仍在继续。
- 附加信息(
info)- 一个字典,包含与本次交互相关的额外信息。
- 例如:Token 使用量、调试信息、工具调用结果等。
▍ 使用 ChatAgentResponse 的测试案例
下面代码中展示了如何创建、解析和使用 ChatAgentResponse:
from camel.responses import ChatAgentResponse
from camel.messages import BaseMessage
from camel.types import RoleType
# 创建一个 ChatAgentResponse 实例
response = ChatAgentResponse(
msgs=[
BaseMessage(
role_name="Assistant", # 助手的角色名称
role_type=RoleType.ASSISTANT, # 角色类型
content="你好,我可以帮您做什么?", # 消息内容
meta_dict={} # 元数据(可选)
)
],
terminated=False, # 会话未终止
info={
"usage": {"prompt_tokens": 10, "completion_tokens": 15}, # Token 使用量
"debug": "本次交互正常完成" # 调试信息
}
)
# 访问消息内容
messages = response.msgs
print("消息内容:", messages[0].content)
# 检查会话状态
is_terminated = response.terminated
print("会话是否终止:", is_terminated)
# 分析 Token 使用量
prompt_tokens = response.info["usage"]["prompt_tokens"]
completion_tokens = response.info["usage"]["completion_tokens"]
total_tokens = prompt_tokens + completion_tokens
print(f"本次交互消耗了 {total_tokens} 个 Token。")
输出:

这里还可以根据不同api接口的输入输出价格配置来计算消耗的token价格成本;🙂
▍ 结合 ChatAgent 使用
在实际开发中,ChatAgentResponse 通常由 ChatAgent 生成。以下是一个完整的例子:
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
# 初始化 ChatAgent
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
chat_agent = ChatAgent(
model=model,
system_message="你是一个友好的助手。",
output_language='zh'
)
# 用户发送消息
user_msg = "你好!你能做什么?"
# 获取 AI 的响应
response = chat_agent.step(user_msg)
# 解析响应
print("助手回复:", response.msgs[0].content)
print("会话是否终止:", response.terminated)
print("附加信息:", response.info)
输出:

⑥ 实践案例
这里我们整理一个案例来整合我们刚才学习的功能!代码如下:
from camel.agents import ChatAgent
from camel.messages import BaseMessage
from camel.models import ModelFactory
from camel.types import ModelPlatformType, OpenAIBackendRole
from PIL import Image
import requests
from io import BytesIO
import os
from dotenv import load_dotenv
# 初始化
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
chat_agent = ChatAgent(
model=model,
system_message="你是一个友好的助手,可以帮助用户回答问题或分析图片。",
output_language='zh'
)
# 任务 1:扩展消息属性
user_msg_with_meta = BaseMessage.make_user_message(
role_name="User",
content="我喜欢科幻电影,能推荐一些吗?输出限制200字,不能使用markdown格式,假装真人回答",
meta_dict={"用户偏好": "科幻电影", "语言": "中文"}
)
response = chat_agent.step(user_msg_with_meta)
print("\033[92m助手回复:\033[0m", response.msgs[0].content)
# 任务 2:多轮对话
user_msg_1 = "CAMEL 是什么?输出限制200字,不能使用markdown格式,假装真人回答"
response_1 = chat_agent.step(user_msg_1)
print("\033[93m第一轮回复:\033[0m", response_1.msgs[0].content)
user_msg_2 = "它能做什么?输出限制200字,不能使用markdown格式,假装真人回答"
response_2 = chat_agent.step(user_msg_2)
print("\033[93m第二轮回复:\033[0m", response_2.msgs[0].content)
# 任务 3:多模态消息
url = "https://img0.baidu.com/it/u=2205376118,3235587920&fm=253&fmt=auto&app=120&f=JPEG?w=846&h=800"
img = Image.open(BytesIO(requests.get(url).content))
user_image_msg = BaseMessage.make_user_message(
role_name="User",
content="请描述这张图片的内容,输出限制200字,不能使用markdown格式,假装真人回答",
image_list=[img]
)
response_with_image = chat_agent.step(user_image_msg)
print("\033[94m助手的图片描述:\033[0m", response_with_image.msgs[0].content)
# 任务 4:与 OpenAI 整合
openai_msg = user_msg_with_meta.to_openai_message(role_at_backend=OpenAIBackendRole.USER)
print("\033[95mOpenAI 格式消息:\033[0m", openai_msg)
- 扩展消息属性:通过
<font style="color:rgb(64, 64, 64);">meta_dict</font>增强上下文。 - 多轮对话:保持上下文连贯性。
- 多模态消息:发送图片并获取描述。与 OpenAI 整合:转换消息格式。
输出如下:

ok,我们继续讲解记忆模块!🎉
5.Agent如何进行记忆?
Memory 模块 是 CAMEL 系统中用于存储、检索和管理 Agent 记忆的核心组件。它支持多种存储方式(如键值存储、向量数据库),并通过权重衰减机制和语义检索功能,确保 Agent 能够高效利用历史信息。
感觉比langchain的好很多👍😂👌
① 构建 Memory 模块
首先,我们需要初始化 Memory 模块,包括 ChatHistoryBlock(用于存储聊天历史)和 VectorDBBlock(用于语义检索),创建一些假数据存进去。
from camel.memories import LongtermAgentMemory, MemoryRecord, ScoreBasedContextCreator, ChatHistoryBlock, VectorDBBlock
from camel.messages import BaseMessage
from camel.types import ModelType, OpenAIBackendRole
from camel.utils import OpenAITokenCounter
from camel.embeddings import SentenceTransformerEncoder
# 初始化 Memory 模块
memory = LongtermAgentMemory(
context_creator=ScoreBasedContextCreator(
token_counter=OpenAITokenCounter(ModelType.GPT_4O_MINI), # Token 计数器
token_limit=1024 # Token 限制
),
chat_history_block=ChatHistoryBlock(keep_rate=0.8), # 聊天历史块(权重衰减率 0.8)
vector_db_block=VectorDBBlock( # 向量数据库块
embedding=SentenceTransformerEncoder(model_name="BAAI/bge-m3") # 使用 bge-m3 模型
)
)
# 创建记忆记录
records = [
MemoryRecord(
message=BaseMessage.make_user_message(
role_name="User",
content="什么是 CAMEL AI?"
),
role_at_backend=OpenAIBackendRole.USER,
),
MemoryRecord(
message=BaseMessage.make_assistant_message(
role_name="Agent",
content='''
### 2025年新发生事件:海南岛正式封关,打造离岸金融中心 🚀
2025年12月31日,中国海南岛正式实施封关政策,标志着海南自由贸易港建设进入全新阶段。这一事件不仅是海南岛发展的里程碑,也是中国推动高水平对外开放的重要举措。
---
#### ▍ 1. 封关政策的核心内容
- **一线放开,二线管住**:
- **一线**:海南岛与境外之间的货物流动完全放开,99%的货物免关税进入海南岛。
- **二线**:海南岛与内地之间实行货物监管,确保海南岛成为“境内关外”的特殊区域。
- **离岸金融中心**:
封关后,海南岛将重点发展离岸金融业务,推动人民币国际化,目标是成为东盟成员国的核心货币市场。
---
#### ▍ 2. 对普通人的影响
1. **免税购物天堂**:
外国货物进入海南岛免关税,岛内个税和企业税上限为15%,吸引全球消费者和投资者。
2. **房产投资机会**:
海南岛房产从“全国市场”变为“全球市场”,吸引了大量国际买家。2025年,海南岛楼市成交量创下新高,尤其是三亚和海口的热门湾区房产。
3. **离岸金融服务**:
海南岛居民在兑换外币额度和便利度上享有更多优惠政策,为个人和企业提供更多金融便利。
---
#### ▍ 3. 经济与政策意义
- **高水平开放的试验田**:
海南岛封关是中国建设更高水平开放型经济体制的重要一步,旨在打造新时代改革开放的新标杆。
- **推动人民币国际化**:
通过离岸金融业务,海南岛将成为人民币国际化的重要支点,助力中国在全球金融体系中占据更重要的地位。
---
#### ▍ 4. 未来展望
- **全球投资热点**:
随着封关政策的实施,海南岛将成为全球投资者关注的焦点,尤其是在房地产、金融和旅游业领域。
- **政策持续优化**:
未来,海南岛可能会进一步放宽政策,吸引更多国际企业和人才,推动区域经济高质量发展
'''
),
role_at_backend=OpenAIBackendRole.ASSISTANT,
),
]
# 写入记忆
memory.write_records(records)
# 检索上下文
context, token_count = memory.get_context()
# 打印上下文和 Token 消耗
print("\033[94m上下文:\033[0m", context)
print("\033[94mToken 消耗:\033[0m", token_count)
不同类型的数据存储方法不一样吗?🤔
这里注意,运行这里的代码时,其会去huggingface上下载Embedding模型,因此国内网络需要挂全局代理!

② 结合ChatAgent实现记忆功能
将上面的记忆功能整合到我们之前构建的agent上后,代码如下:
from camel.memories import LongtermAgentMemory, MemoryRecord, ScoreBasedContextCreator, ChatHistoryBlock, VectorDBBlock
from camel.messages import BaseMessage
from camel.types import ModelType, OpenAIBackendRole
from camel.utils import OpenAITokenCounter
from camel.embeddings import SentenceTransformerEncoder
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
import os
from dotenv import load_dotenv
# 初始化 Memory 模块
memory = LongtermAgentMemory(
context_creator=ScoreBasedContextCreator(
token_counter=OpenAITokenCounter(ModelType.GPT_4O_MINI),
token_limit=1024
),
chat_history_block=ChatHistoryBlock(keep_rate=0.8),
vector_db_block=VectorDBBlock(
embedding=SentenceTransformerEncoder(model_name="BAAI/bge-m3")
)
)
# 创建记忆记录
records = [
MemoryRecord(
message=BaseMessage.make_user_message(
role_name="User",
content="海南岛最近发生了什么事情?"
),
role_at_backend=OpenAIBackendRole.USER,
),
MemoryRecord(
message=BaseMessage.make_assistant_message(
role_name="Agent",
content='''
### 2025年新发生事件:海南岛正式封关,打造离岸金融中心 🚀
2025年12月31日,中国海南岛正式实施封关政策,标志着海南自由贸易港建设进入全新阶段。这一事件不仅是海南岛发展的里程碑,也是中国推动高水平对外开放的重要举措。
---
#### ▍ 1. 封关政策的核心内容
- **一线放开,二线管住**:
- **一线**:海南岛与境外之间的货物流动完全放开,99%的货物免关税进入海南岛。
- **二线**:海南岛与内地之间实行货物监管,确保海南岛成为“境内关外”的特殊区域。
- **离岸金融中心**:
封关后,海南岛将重点发展离岸金融业务,推动人民币国际化,目标是成为东盟成员国的核心货币市场。
---
#### ▍ 2. 对普通人的影响
1. **免税购物天堂**:
外国货物进入海南岛免关税,岛内个税和企业税上限为15%,吸引全球消费者和投资者。
2. **房产投资机会**:
海南岛房产从“全国市场”变为“全球市场”,吸引了大量国际买家。2025年,海南岛楼市成交量创下新高,尤其是三亚和海口的热门湾区房产。
3. **离岸金融服务**:
海南岛居民在兑换外币额度和便利度上享有更多优惠政策,为个人和企业提供更多金融便利。
---
#### ▍ 3. 经济与政策意义
- **高水平开放的试验田**:
海南岛封关是中国建设更高水平开放型经济体制的重要一步,旨在打造新时代改革开放的新标杆。
- **推动人民币国际化**:
通过离岸金融业务,海南岛将成为人民币国际化的重要支点,助力中国在全球金融体系中占据更重要的地位。
---
#### ▍ 4. 未来展望
- **全球投资热点**:
随着封关政策的实施,海南岛将成为全球投资者关注的焦点,尤其是在房地产、金融和旅游业领域。
- **政策持续优化**:
未来,海南岛可能会进一步放宽政策,吸引更多国际企业和人才,推动区域经济高质量发展。
---
'''
),
role_at_backend=OpenAIBackendRole.ASSISTANT,
),
]
# 写入记忆
memory.write_records(records)
# 检索上下文
context, token_count = memory.get_context()
print("\033[94m上下文:\033[0m", context)
print("\033[94mToken 消耗:\033[0m", token_count)
# 初始化 ChatAgent
load_dotenv()
api_key = os.getenv('QWEN_API_KEY')
model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type="Qwen/Qwen2.5-72B-Instruct",
url='https://api-inference.modelscope.cn/v1/',
api_key=api_key
)
agent = ChatAgent(
system_message="你是一个好奇的智能体,正在探索万事万物的奥秘。",
model=model
)
# 将 Memory 模块赋值给 Agent
agent.memory = memory
# 用户消息
usr_msg = "告诉我基于我们讨论的内容,海南岛最近发生了什么事情?输出限制200字,不能使用markdown格式,假装真人回答"
# 发送消息给 Agent
response = agent.step(usr_msg)
print("\033[92mAgent 回复:\033[0m", response.msgs[0].content)
# 语义检索
keyword = "框架"
retrieved_records = memory.vector_db_block.retrieve(keyword=keyword, limit=3)
print("\033[93m语义检索结果:\033[0m")
for record in retrieved_records:
print(f"UUID: {record.memory_record.uuid}, 消息: {record.memory_record.message.content}, 相似度: {record.score}")

表现良好!👌👍
总结
通过本文的学习,我们对Camel的Agent设计思想和完整组成有了深入的理解。Camel作为一个强大的工具,其Agent的设计不仅体现了模块化和灵活性的特点,还为我们提供了丰富的功能和扩展性。无论是初学者还是有经验的开发者,都能从中获得宝贵的知识和启发。希望本文的内容能够帮助你在Agent开发的道路上少走弯路,进一步提升你的技术能力。如果你有任何问题或建议,欢迎在评论区留言讨论,我们一起进步!😊
文章参考
项目地址

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 2
2- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)