
【上】AI踩雷碎碎念和text-generation-webui端口冲突的解决方案
自从deepseek火爆出圈,见证了deepseek无敌的中文语言,我赶一波AI浪潮研究起了本地部署,在尝试了各种本地方案后,我发现小白ai之路,简直是个无底洞,各种计算机、人工智能的概念,每个字拆开都认识,组合在一起就是摩斯密码。AI似乎是无所不能,然而每一次遇到问题搜索,我发现ai无法帮你解决认知之外的问题,还得靠自己检索,而我经常一搜就是成百上千行各位大佬提供的代码调试……哎,只能,当年没有
Part1:碎碎念
自从deepseek火爆出圈,见证了deepseek无敌的中文语言,我赶一波AI浪潮研究起了本地部署,在尝试了各种本地方案后,我发现小白ai之路,简直是个无底洞,各种计算机、人工智能的概念,每个字拆开都认识,组合在一起就是摩斯密码。AI似乎是无所不能,然而每一次遇到问题搜索,我发现ai无法帮你解决认知之外的问题,还得靠自己检索,而我经常一搜就是成百上千行各位大佬提供的代码调试……哎,只能,当年没有选择计算机专业是我今天在这流泪的原因。事已至此,由于客观原因限制,对问题根本无法追根溯源,根据前因后果调试,只能寻求一个合适自己的解决方案,那些浩如烟海的知识,能了解一点是一点,这是我摸索ai心路历程。
我在部署本地ai发现,ai并不能很好的回答,解决问题,无论是角色扮演,或者是疑问解答,甚至是绕过限制方面表现平平,在网上搜索教程,往往花心思大力调试并不一定有好的效果,比起现成的网页版满血ai进行日常使用,我还是选择了后者,只有在两个方面是我正在本地化ai的方向,一是本地文档数据的rag搭建,二ai的语音合成输出。
关于RAG的本地化部署搭建,曾看到某大佬批判网上小白盲目跟风被人骂,其实个人用户网络屁民,什么企业效率,客服性助手离我们太远,搞这些大部分都是私人目的,电脑里一些乱七八糟的文档,稍微搞点不正经的花活,说白了为了让AI回答网页端数据库里没有的知识,我有一堆网上下的电子书,或者是我写的很多软件的学习笔记,我希望ai能够检索这些方面回答我,而据我的了解,RAG技术组件分为三步,检索器阶段RAG(Retriever)的R,我们使用不同的索引工具,如dify/rag/anythingLLM/cherrystudio等工具,当我们文件上传提交解析,它们在检索阶段的实现方式和索引构建策略上可能会有所不同,导致检索结果可能完全不一样。
利用RAGflow和LM Studio建立食品法规问答系统_ragflow lmstudio-CSDN博客
在这一篇文章中博主测试了多个能够部署RAG的工具or平台,测试结果得到了完全不一样的答案。
而在生成模型(Generator)RAG的R上则情况则更加如此,是选择角色扮演smegemma、chatGLM模型,还是选择擅长写作的 gemma9B,辅助润色Phi4、还是自然语言流畅Halide12b,又或者是通用类的模型如deepseek,可选择的太多太多了。又由于本地部署的限制,显卡显存,内存CPU等等因素限制模型发挥能力,比如deepseek蒸馏版14B之下量化版的14B就是个弟中弟,某些模型检索生成对话时,出现胡言乱语前言不搭后语,不能理解问题正常回答的AI幻觉。
embedding文本处理方面的模型可选择同样很多,并且选择同样重要。它负责处理文本的语法、语义以及上下文关系,把这些文本转换为向量块,提供给不同的检索器排序和检索,把你输入框问的问题转化为向量(理解你问题),与上传到知识库离线数据转化过的向量块(embedding模型理解的文本)匹配关联起来,根据检索的内部信息处理,最后反馈给我们平时下载的大语言模型,生成最终的答案或响应,所谓RAG的A-G过程被称为生成增强。
因此embedding模型的能力选择,是各类软件检索的基础、各种大预言模型的理解基础,可以选择embedding模型也五花八门,如适合处理中文bge-large-zh-v1.5、很多软件集成的BAAI/bge-m3、长文本识别免费的nomic-embed-text:latest、阿里收费的text-embedding-v3。
如此以来决定RAG质量的可变因素实在是太多了,这也是为什么很多靠AI卖课发家致富的教你部署个RAG库只用三分钟,却没有在知识库文本的质量上更进一步,maybe一时半会真讲不明白,maybe那是保留节目收费的部分,B站一搜卖RAG知识库的遍地开花。
我想要搭建RGA知识库的想法,在我尝试若干种搭配方式收获甚微这一步的时就卡住了,我仅仅只是接触了工具的使用层面,我没有找到实现的方法。不同的RAG工具是不是影响embedding的质量关键?RAG分了一堆块,我如何保证给LLM模型片段是最接近我提问意思的片段?哪一种embedding模型能筛选出与问题最相关的片段?我选择哪一类LLM、多大参数的LLM能根据片段正确理解正确回复我的问题?像是prompt提示词方案,模型调参,等其他的方法是怎么样的?微调模型的变量参数如何影响模型记忆和注意机制,调参的TOP温度是否可以解决AI已读乱回的幻觉,时间成本上是否应该选择某一知识被训练微调的模型。


然后我就发现,我又回到了混沌之中,可控参数太多,盲区太多了,我做不了一个完全符合我目的的RAG库,而又不如直接把切片文档喂给网页版满血的deepseek,DeepSeek本身用于增强检索质量的大模型,所以说不定自己一番操作下来,还不如网页端,姿势不正确的RAG效果鸡肋,食之无味弃之可惜。
而我的planB方向,AI语音角色扮演,目前也是摸着石头过河,如何使用api的调用,我一边学python,一遍了解AI语音生成方面的内容,AI是如何实现语音生成,这一方面还没有收货性的成果,进度微小。
总结总结就是啥也做成,最近在刷B站的AI视频,看到一个UP主说人永远问不出自己认知以外的问题。这一点我深以为,UP提到现在可以用AI帮助我打破信息差,让我意识到我应该问出什么问题。
于是,我想到这一切是不是我想的太复杂了,能否让AI帮助我,在我能力范围内,做出一个距我目标接近的成果来。
因此我开始了测试,然而经过一天一夜的尝试,结果是我其实对AI有一点祛魅了。
因为AI可以把事件理解的很简单,但只是逻辑上的简单,动起手操作起来可一点儿也不简单,即你需要一步一步调试AI,不断地给AI反馈,再让AI解决问题,不断试错。在我想象中AI能顺利指导我完成目标的情况,并不存在。
Part2:一次尝试
前面提到,我本地部署RAG知识库让他理解长文本的时候效果并不好,但是经过一些思路上的调整,还是能做到能用。我选择了cherrystudio集成软件,在生成式大预言模型上我接入了满血版的deepseekAPI,而embedding方面我选择了收费的text-embedding-v3,进行测试,效果不算优秀,但也能够做到针对用户提供给它单一知识,正确的判断和回答。
有人提到说RAG分割文本的方式更加适合处理大量的独立文件信息,它在长关联的上下文,无法得到很好的回复。我觉得言之有理,我看网友们使用RAG有投喂民法典和医学专业知识的,似乎RAG强大的就是独立模块的信息检索,如果我就是想让它处理因果逻辑强的上下文,不用网页端的AI,不用RAG的方式,有没有其他的方法可以做呢?
我问deepseek提问,我希望有一个能够理解长篇文本和我讨论剧情的ai,它能够总结全文,分析人物,进行情感,有没有适合非专业人士的部署方式?
我不能从零开始写代码,deepseek给我推荐现成GUI工具OobaBooga的text-generation-webui,搭配Llama3-Chinese-8B的模型。于是在deepseek“1+1=2”通俗易懂的回答下,我一踩一个坑的测试开始了。
首先是,它甚至提出用到的工具要打包网盘给我,我好奇询问它要怎么打包,于是它这才意识到自己无法上传百度网盘,给了我一段自动下载软件的安装代码,经测试deepseek给出的下载代码完全无法执行。嗯,终于有点chatGPT硬凹的味道了。
于是人工智障派不上用场的情况下,我只能手动操作了。
光是安装text-generation-webui,我就经历了一键安装失败,但是找不到失败原因,搜到了解决方法照做后发现并不能解决我的问题 → 选择了planB的docker安装,成功打开,后发现无法指定本地模型,在解决容器内部端口与宿主机端口的映射,成功加载上模型了,发现它在我GPU的模型下,不工作等一系列大无语事件 → 换成了适合新手的planC,即我查找到其他用户发布的懒人包,随后又遇到了,端口冲突不工作的问题。于是有了这篇。
PlanA问题的解决方法:
结果:我未能解决环境冲突,安装失败
PlanB问题的解决方法:
docker run --name text-generation-dock -p 7774:7860 -v "P:\Docker\text-generation-webui\models:/workspace/text-generation-webui/models" nschle/oobabooga结果:我未能解决docker部署的TGW让其GPU运行的问题,模型调用失败
PlanC问题的解决方案:
更改监听端口? ·oobabooga/文本生成-webui ·讨论 #998
结果:成果运行,成功载入模型
Part.3:text-generation-webui
text-generation-webui 是运行大型语言模型(LLM)提供易于使用的 Web 用户界面,它支持多个推理后端,有丰富的插件扩展。(在我看来有点像进阶版pro版的LLM运行工具。)
text-generation-webui原下载地址:oobabooga/text-generation-webui: A Gradio web UI for Large Language Models with support for multiple inference backends.
B站大佬_Smzh_的懒人安装包下载地址:https://pan.baidu.com/s/1fe7iiHIAtoXW80Twsrv8Nw 提取码:pato
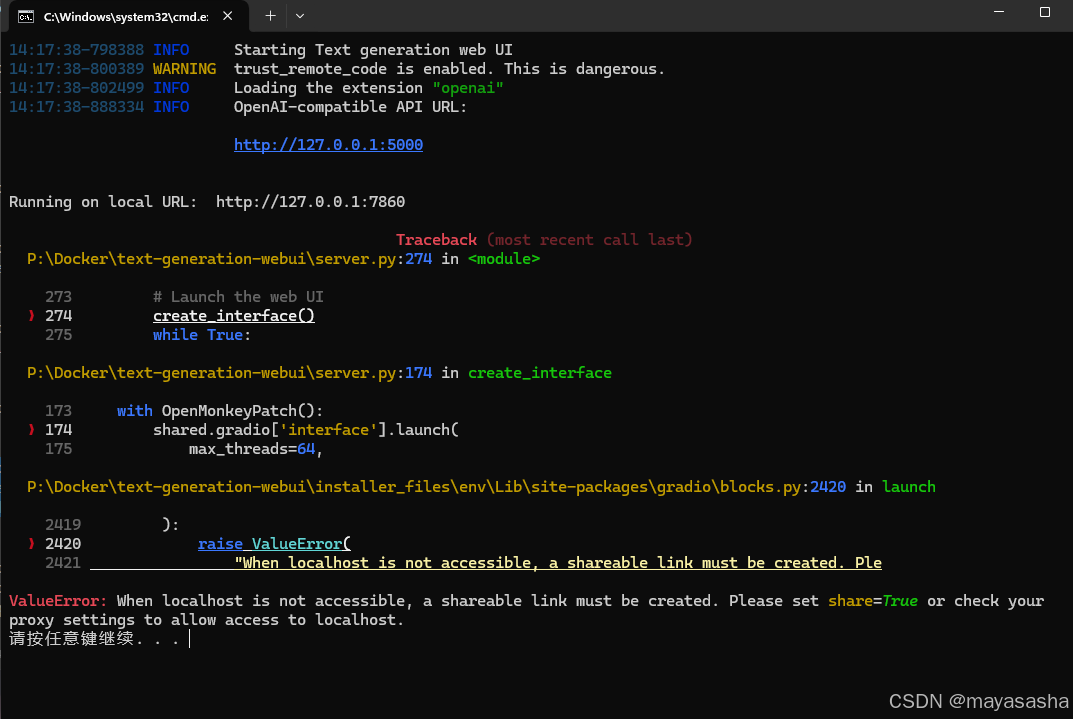
新版Text-Generation-Webui解压即用懒人包~本地大语言模型手把手部署教程~(2024年末重置版)_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1dVCzYUE7G/?spm_id_from=333.1387.collection.video_card.click&vd_source=e0e4e4122d077cc783600ddc34cdbd00我在使用大佬的安装包,时候遇到了下面的代码报错
https://www.bilibili.com/video/BV1dVCzYUE7G/?spm_id_from=333.1387.collection.video_card.click&vd_source=e0e4e4122d077cc783600ddc34cdbd00我在使用大佬的安装包,时候遇到了下面的代码报错
14:17:38-798388 INFO Starting Text generation web UI
14:17:38-800389 WARNING trust_remote_code is enabled. This is dangerous.
14:17:38-802499 INFO Loading the extension "openai"
14:17:38-888334 INFO OpenAI-compatible API URL:
http://127.0.0.1:5000
Running on local URL: http://127.0.0.1:7860
╭───────────────────────────────────────── Traceback (most recent call last) ──────────────────────────────────────────╮
│ P:\Docker\text-generation-webui\server.py:274 in <module> │
│ │
│ 273 # Launch the web UI │
│ ❱ 274 create_interface() │
│ 275 while True: │
│ │
│ P:\Docker\text-generation-webui\server.py:174 in create_interface │
│ │
│ 173 with OpenMonkeyPatch(): │
│ ❱ 174 shared.gradio['interface'].launch( │
│ 175 max_threads=64, │
│ │
│ P:\Docker\text-generation-webui\installer_files\env\Lib\site-packages\gradio\blocks.py:2420 in launch │
│ │
│ 2419 ): │
│ ❱ 2420 raise ValueError( │
│ 2421 "When localhost is not accessible, a shareable link must be created. Ple │
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your
proxy settings to allow access to localhost.
请按任意键继续. . .
解决方案1:它似乎是我和VPN代理端口冲突了,关闭VPN之后,该报错消失成功运行。
解决方案2:
根据报错打开CMD_FLAGS.txt加上--share可直接打开,但我想要修改TGW的端口。
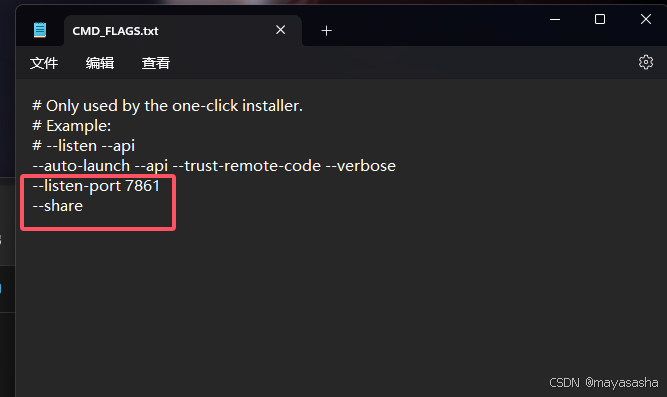
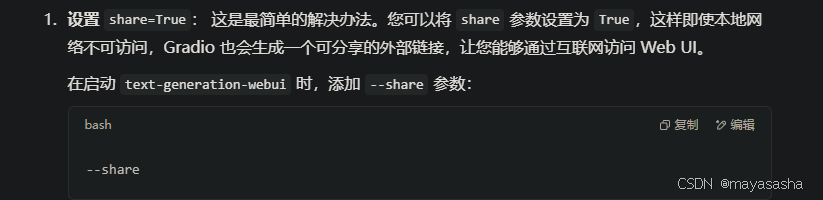
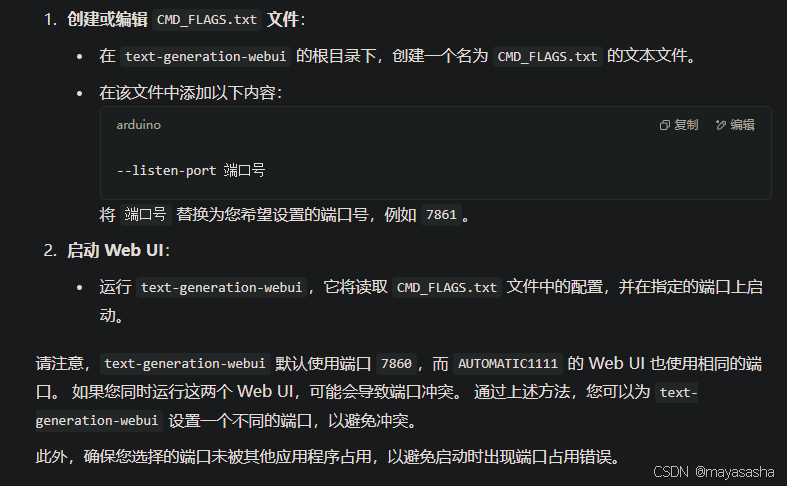
以上,我用一天做到了AI给我提供方案的工具步骤,下完了text-generation-webui,成功运行了Llama3-Chinese-8B的模型。
下篇我在研究一下TGW工具的使用,至于deepseek提供的回答,实在是有些过于难评,要么没有操作性,要么没有给出的操作它编的根本没有该选项。
这篇全说的是我个人碎碎念,有错的地方,欢迎各位佬指出。
未完待续。
扩展阅读:oobabooga-text-generation-webui手把手安装教程,同时评测Vicuna模型_哔哩哔哩_bilibili

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)