使用DeepSeek实现一个复杂旅游规划智能体
ReActAgent是一个结合推理(Reasoning)和行动(Acting)的动态LLM(大语言模型)Agent框架。它的核心思想是通过推理和行动交替进行,以动态的方式完成复杂的任务。简单来说,ReActAgent不仅仅依靠大语言模型单纯地生成回答,而是通过交替推理和执行操作来更有效地完成任务。

前言
Hello,大家好,我是GISer Liu😁,一名热爱AI技术的GIS开发者。本系列是作者参加DataWhale 2025年2月份组队学习的wow-agent技术笔记文档。在上篇文章中,我们基于DeepSeek手动构建了一个智能体;今天我们将更进一步,使用LlamaIndex框架构建一个复杂旅游规划助手!😉
在本文中,🤔我们基于上一篇文章的基础进行构建。关于API接口申请和本地环境变量配置,可以参考上一篇文章,这里不再赘述。
本文中作者将基于ReActAgent结构,通过LlamaIndex框架构建一个较为复杂的旅游规划助手。它能够实现天气查询、网络检索、数据库查询和RAG对话等功能,帮助用户生成个性化的旅游计划。
OK,开始实践!
一、什么是ReActAgent?
ReActAgent是一个结合推理(Reasoning)和行动(Acting)的动态LLM(大语言模型)Agent框架。它的核心思想是通过推理和行动交替进行,以动态的方式完成复杂的任务。简单来说,ReActAgent不仅仅依靠大语言模型单纯地生成回答,而是通过交替推理和执行操作来更有效地完成任务。
1.ReActAgent的工作原理
ReActAgent遵循一个循环结构:推理、行动、观察和优化推理。这个循环不断地重复,直到任务得到满意的完成。
- 初始推理:首先,代理通过推理理解任务,收集相关信息,并决定下一步行为。
- 行动:根据推理的结果,代理会采取某种行动(例如调用API、检索数据、执行命令等)。
- 观察:代理会观察行动的结果,收集新的信息或反馈。
- 优化推理:代理根据新获得的信息,重新推理并更新任务的执行计划。
- 重复:推理和行动之间的交替过程不断进行,直到任务完成。
🤔这里可能读者没有理解为什么Agent能够行动,这里解释一下:大模型会根据函数的注释来判断应该使用哪个函数来完成当前的任务,因此在提示词中说明函数的输入输出参数格式,功能等信息;然后将工具函数放到FunctionTool对象中,供给Agent使用;通过这样的方式,Agent就可以根据自己的决策结果选择执行对应的函数;实现行动!
下面的流程图可以帮助读者辅助理解这个过程!

接下来我们讲讲其有什么优势!!🤔
2.ReActAgent的优势
ReActAgent的设计使得它能够动态地处理复杂的任务,尤其是在需要多工具协作的场景下,ReActAgent非常适用。它通过在推理和行动之间的闭环切换,使得模型能够根据实际情况调整其行为,避免了传统大语言模型的局限性。通过这种动态反馈机制,ReActAgent能够适应各种不确定性和复杂性,解决更加多样化和复杂的任务。
整理一下就是:
| 特性 | 描述 |
|---|---|
| 推理与行动结合 | 通过结合推理和行动,ReActAgent能够动态地根据任务进展调整策略。 |
| 多工具协作 | 支持多个工具的协同工作,可以通过API调用、工具函数、外部资源等手段来解决问题。 |
| 灵活性和适应性 | 随着任务的进行,Agent能够通过观察和反馈来优化其推理过程,从而适应复杂和不确定的任务环境。 |
| 自动化任务执行 | 将模型的推理能力和工具的执行能力结合,实现了业务逻辑的自动化执行。 |
OK,说了这么多,下面我们看一个案例理解这个ReActAgent的执行流程!
3.ReActAgent 实现数学运算
下面是一个简单的示例,展示了如何使用LlamaIndex实现一个ReActAgent来计算数学表达式,并通过自定义函数进行工具调用。
① 准备工具函数类
在ReActAgent中,工具函数是实现代理任务的关键部分。在本例中,我们使用了两个简单的工具函数:multiply 和 add,分别实现了乘法和加法操作。
class CalculateAgent:
def __init__(self, llm: CustomLLM):
"""初始化CalculateAgent,加载工具并创建ReActAgent实例"""
multiply_tool = FunctionTool.from_defaults(fn=self.multiply)
add_tool = FunctionTool.from_defaults(fn=self.add)
self.agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)
@staticmethod
def multiply(a: float, b: float) -> float:
"""计算两个数的乘积
Args:
a (float): 第一个数
b (float): 第二个数
Returns:
float: 乘积结果
"""
return a * b
@staticmethod
def add(a: float, b: float) -> float:
"""计算两个数的和
Args:
a (float): 第一个数
b (float): 第二个数
Returns:
float: 和的结果
"""
return a + b
🙂作者这里将工具类和Agent融合到了一块,倘若你希望工具是公共的,你可以将其拆分出来;
② 构建DeepSeekLLM类
首先,我们定义了一个自定义的LLM类,作为Agent的核心;这里我们继续沿用之前的DeepSeek模型。
import openai
import os
from dotenv import load_dotenv
import requests
from openai import OpenAI
from pydantic import Field # 导入Field,用于Pydantic模型中定义字段的元数据
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
LLMMetadata,
)
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import List, Any, Generator
import sys
import os
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 定义OurLLM类,继承自CustomLLM基类
class DeepSeekLLM(CustomLLM):
api_key: str = Field(default=api_key, description="API密钥")
base_url: str = Field(default=base_url, description="API基础URL")
model_name: str = Field(default=model_name, description="模型名称")
client: OpenAI = Field(default=None, exclude=True, description="OpenAI客户端实例")
def __init__(self, api_key: str = api_key, base_url: str = base_url, model_name: str = model_name, **data: Any):
super().__init__(**data)
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.client = openai.OpenAI(api_key=api_key, base_url=base_url)
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据"""
return LLMMetadata(model_name=self.model_name)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""同步生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
)
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:
"""流式生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True,
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
③ 创建ReActAgent实例并执行任务
使用LlamaIndex的ReActAgent和FunctionTool创建一个ReActAgent实例并执行计算任务。
def main():
"""主程序入口"""
try:
# 加载环境变量
load_dotenv()
# 配置 OpenAI API 和 DeepSeek API
api_key = os.getenv("API_KEY")
base_url = os.getenv("BASE_URL")
model_name = os.getenv("MODEL_NAME")
# 实例化DeepSeekLLM和CalculateAgent
deepseek_llm = DeepSeekLLM(api_key=api_key, base_url=base_url, model_name=model_name)
calculate_agent = CalculateAgent(deepseek_llm)
# 使用Agent进行计算
response = calculate_agent.agent.chat("32*(43+8)等于多少?使用工具计算每一步骤!")
print(response)
except Exception as e:
print(f"程序运行出错: {e}")
if __name__ == "__main__":
main()
完整代码如下:
import openai
import os
from dotenv import load_dotenv
import requests
from openai import OpenAI
from pydantic import Field # 导入Field,用于Pydantic模型中定义字段的元数据
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
LLMMetadata,
)
from llama_index.core.embeddings import BaseEmbedding
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import List, Any, Generator
import sys
import os
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 定义OurLLM类,继承自CustomLLM基类
class DeepSeekLLM(CustomLLM):
api_key: str = Field(default=api_key, description="API密钥")
base_url: str = Field(default=base_url, description="API基础URL")
model_name: str = Field(default=model_name, description="模型名称")
client: OpenAI = Field(default=None, exclude=True, description="OpenAI客户端实例")
def __init__(self, api_key: str = api_key, base_url: str = base_url, model_name: str = model_name, **data: Any):
super().__init__(**data)
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.client = openai.OpenAI(api_key=api_key, base_url=base_url)
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据"""
return LLMMetadata(model_name=self.model_name)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""同步生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
)
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:
"""流式生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True,
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
class CalculateAgent:
def __init__(self, llm: CustomLLM):
"""初始化CalculateAgent,加载工具并创建ReActAgent实例"""
multiply_tool = FunctionTool.from_defaults(fn=self.multiply)
add_tool = FunctionTool.from_defaults(fn=self.add)
self.agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)
@staticmethod
def multiply(a: float, b: float) -> float:
"""计算两个数的乘积
Args:
a (float): 第一个数
b (float): 第二个数
Returns:
float: 乘积结果
"""
return a * b
@staticmethod
def add(a: float, b: float) -> float:
"""计算两个数的和
Args:
a (float): 第一个数
b (float): 第二个数
Returns:
float: 和的结果
"""
return a + b
def main():
"""主程序入口"""
try:
# 加载环境变量
load_dotenv()
# 配置 OpenAI API 和 DeepSeek API
api_key = os.getenv("API_KEY")
base_url = os.getenv("BASE_URL")
model_name = os.getenv("MODEL_NAME")
# 实例化DeepSeekLLM和CalculateAgent
deepseek_llm = DeepSeekLLM(api_key=api_key, base_url=base_url, model_name=model_name)
calculate_agent = CalculateAgent(deepseek_llm)
# 使用Agent进行计算
response = calculate_agent.agent.chat("32*(43+8)等于多少?使用工具计算每一步骤!")
print(response)
except Exception as e:
print(f"程序运行出错: {e}")
if __name__ == "__main__":
main()
这里的环境变量都保存在项目根目录下的.env文件中,有需求可以去看作者前一篇文章;🙂
查看运行结果:
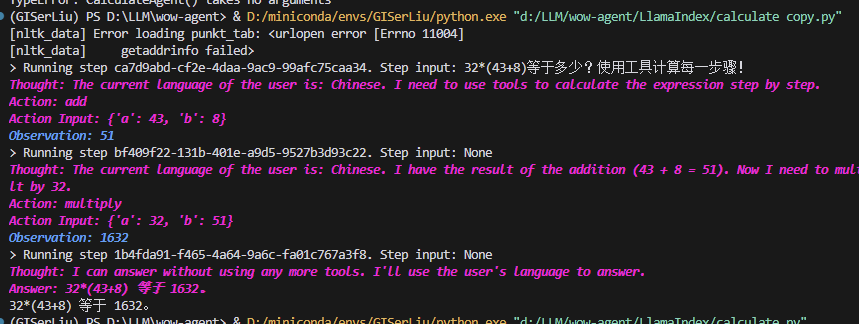
运行成功!👌从这里,我们可以看到这个Agent的思考与行动过程,经过验证,计算结果正确!🎉
同理,我们也可以将我们上一篇文章中实现的天气查询Agent迁移到这个框架中,详细效果会更好!
4.天气查询Agent
这里废话不多说,我们直接上代码!
import openai
import os
from dotenv import load_dotenv
import requests
from openai import OpenAI
from pydantic import Field
from llama_index.core.llms import CustomLLM, CompletionResponse, LLMMetadata
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import Any, Generator
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 加载环境变量
load_dotenv()
# 配置 OpenAI API 和 DeepSeek API
api_key = os.getenv("API_KEY")
base_url = os.getenv("BASE_URL")
model_name = os.getenv("MODEL_NAME")
weather_api_key = os.getenv("WEATHER_API_KEY") # 高德地图天气 API 密钥
# 高德地图天气 API 基础 URL
weather_base_url = "https://restapi.amap.com/v3/weather/weatherInfo"
# 定义 DeepSeekLLM 类,继承自 CustomLLM 基类
class DeepSeekLLM(CustomLLM):
api_key: str = Field(default=api_key, description="API密钥")
base_url: str = Field(default=base_url, description="API基础URL")
model_name: str = Field(default=model_name, description="模型名称")
client: OpenAI = Field(default=None, exclude=True, description="OpenAI客户端实例")
def __init__(self, api_key: str = api_key, base_url: str = base_url, model_name: str = model_name, **data: Any):
super().__init__(**data)
self.api_key = api_key
self.base_url = base_url
self.model_name = model_name
self.client = openai.OpenAI(api_key=api_key, base_url=base_url)
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据"""
return LLMMetadata(model_name=self.model_name)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""同步生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
)
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:
"""流式生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True,
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
# 定义 WeatherTool 类,用于查询天气
class WeatherTool:
@staticmethod
def get_weather_info(city_name: str) -> str:
"""查询天气信息(带错误处理)
Args:
city_name (str): 城市名称
Returns:
str: 天气信息或错误消息
"""
params = {
'key': weather_api_key,
'city': city_name,
'extensions': 'base',
'output': 'JSON'
}
try:
response = requests.get(weather_base_url, params=params)
response.raise_for_status() # 自动触发HTTP错误
weather_data = response.json()
if weather_data.get('status') != '1':
return f"请求失败:{weather_data.get('infocode', '未知错误')}"
lives = weather_data.get('lives', [])
if not lives:
return "该城市无天气数据"
live_data = lives[0]
return (
f"当前天气:{live_data['weather']}\n"
f"温度:{live_data['temperature']}°C\n"
f"湿度:{live_data['humidity']}%\n"
f"更新时间:{live_data['reporttime']}"
)
except requests.exceptions.RequestException as e:
return f"网络请求失败:{str(e)}"
except KeyError as e:
return f"数据解析错误:缺少字段 {str(e)}"
# 定义 WeatherAgent 类,用于整合天气查询工具和 ReActAgent
class WeatherAgent:
def __init__(self, llm: CustomLLM):
"""初始化 WeatherAgent,加载天气查询工具并创建 ReActAgent 实例"""
weather_tool = FunctionTool.from_defaults(fn=WeatherTool.get_weather_info)
self.agent = ReActAgent.from_tools([weather_tool], llm=llm, verbose=True)
def main():
"""主程序入口"""
try:
# 实例化 DeepSeekLLM 和 WeatherAgent
deepseek_llm = DeepSeekLLM(api_key=api_key, base_url=base_url, model_name=model_name)
weather_agent = WeatherAgent(deepseek_llm)
# 使用 Agent 查询天气
response = weather_agent.agent.chat("今天武汉天气怎么样?")
print(response)
except Exception as e:
print(f"程序运行出错: {e}")
if __name__ == "__main__":
main()
运行测试!
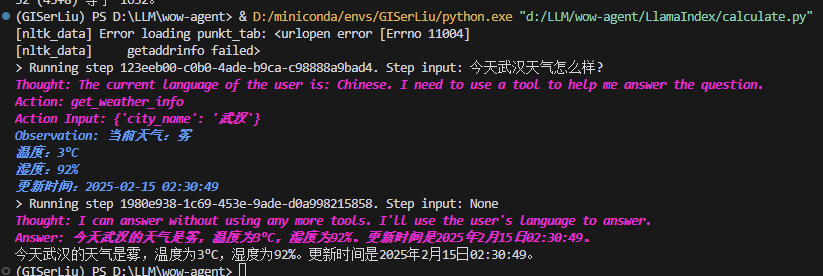
!!!🎉🎉,运行成功!相当惊艳的效果;比我们上节课构建的demo完备稳定的多!
二、旅游规划Agent项目架构设计
既然我们现在理解了ReActAgent构建了大致流程,我们这里就开始设计这个旅游规划Agent的架构;🙂
1. 整体架构设计
旅游规划助手基于 多Agent协作架构,通过ReAct框架实现动态推理与工具调用。整体架构分为三层:
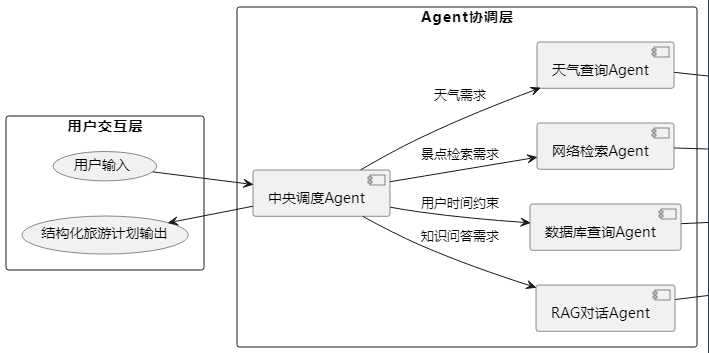
- 用户交互层:接收用户输入(如“我想去北京玩3天,请帮我规划行程”),并返回结构化旅游计划。
- Agent协调层:由中央调度Agent根据用户需求分解任务,协调多个子Agent协作。
- 工具执行层:集成天气API、搜索引擎API、本地数据库和RAG引擎,支撑Agent具体功能实现。
2.Agent分工流程
| Agent类型 | 核心职责 | 输入示例 | 输出示例 | 依赖工具 |
|---|---|---|---|---|
| 中央调度Agent | 任务分解与结果整合 | “北京3日游,包含文化景点” | JSON格式的完整行程计划 | 无 |
| 天气查询Agent | 获取目的地未来天气预测 | {“city”:“北京”,“date”:“2024-07-01”} | {“weather”:“晴”,“temperature”:“25°C”} | 高德天气API |
| 网络检索Agent | 获取景点信息与推荐路线 | “北京文化景点Top5” | [“故宫”,“颐和园”,…] | 网络检索接口 |
| 数据库查询Agent | 查询用户历史行程与时间约束 | 用户ID | {“available_days”:3,“preferences”:[“博物馆”]} | MySQL数据库或sqlite数据库 |
| RAG对话Agent | 基于爬取的旅游知识库的问答结果与推荐 | “带老人适合北京的哪些景点?” | “推荐颐和园:步行路线平缓…” | 本地旅游知识库+Embedding模型 |
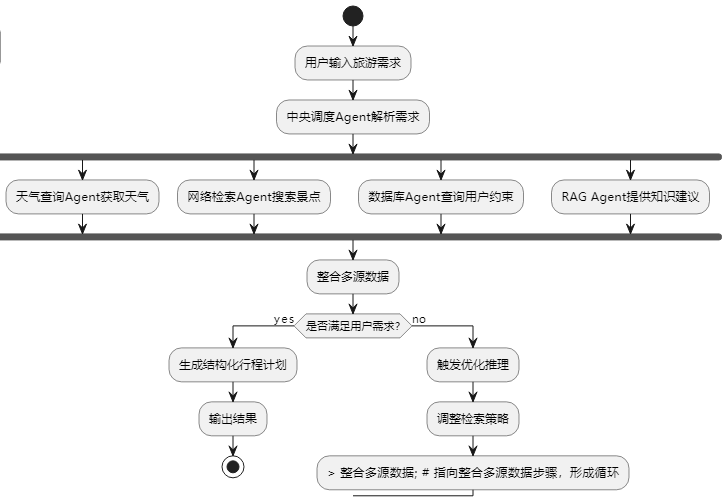
这里我们用文字描述一下我们整个业务流程!
-整个过程从用户输入旅游需求开始。用户通过自然语言描述需求,比如“我想去北京玩3天,包含文化景点”或“带老人适合北京的哪些景点?”。
中央调度Agent 首先解析用户输入,提取关键信息(如目的地、时间、偏好等),然后将任务分解为多个子任务,分别交给不同的Agent处理。
天气查询Agent 负责查询目的地的未来天气情况。它会调用高德天气API,获取指定日期和城市的天气数据,比如温度、湿度和天气状况,并将结果返回给中央调度Agent。
网络检索Agent 负责检索目的地的景点信息和推荐路线。它会根据用户的需求(如“北京文化景点Top5”)调用网络检索接口,获取景点列表和相关信息,比如景点名称、评分和开放时间。
数据库查询Agent 负责查询用户的历史行程和时间约束。它会根据用户ID从数据库中提取用户的可用天数、偏好景点类型等信息,帮助中央调度Agent更好地规划行程。
RAG对话Agent 负责基于本地旅游知识库提供问答和推荐。它会使用Embedding模型对用户问题进行向量化表示,然后在知识库中检索相关内容,返回适合的答案或建议,比如“推荐颐和园:步行路线平缓,适合老年人游览”。
所有Agent完成任务后,中央调度Agent 会将天气、景点、用户偏好和知识建议等多源数据整合起来,生成一个初步的旅游计划。如果用户对计划不满意,系统会触发优化推理,调整检索策略(比如更换景点或调整时间安排),然后重新整合数据,生成新的计划,直到用户满意为止。
最终,系统会将生成的行程计划以用户友好的格式(如文本、表格或图表)返回给用户,完成整个流程。
三、Agent开发
| 工具类型 | 对接Agent | 技术实现方案 | 异常处理策略 |
|---|---|---|---|
| 天气API | 天气查询Agent | 封装为WeatherTool类,提供get_weather(city,date)方法 |
重试机制+缓存最近3天数据 |
| 搜索引擎API | 网络检索Agent | 继承BaseTool实现异步检索接口 |
备用搜索引擎切换(百度→高德) |
| 关系型数据库 | 数据库查询Agent | 通过SQLAlchemy ORM映射用户数据表 | 事务回滚+查询超时限制(5s) |
| 向量数据库 | RAG对话Agent | 使用FAISS存储景点Embedding,支持相似度检索 | 降级为关键词搜索 |
这里我们整理了一下每个Agent或工具类设计的方案;
我们在第一个模块中就已经完成了天气查询Agent的设计,现在我们只需要构建数据库查询Agent、搜索Agent和RAG Agent;
下面我们开始开发:
1.搜索引擎工具类
这里我们使用百度的AI搜索接口进行查询:API Key配置查看:https://ai.baidu.com/ai-doc/AppBuilder/lm68r8e6i
代码如下:
import os
import requests
import json
from typing import List, Dict, Optional, Generator
from pydantic import BaseModel, Field
from dotenv import load_dotenv
# 百度API配置
BAIDU_SEARCH_URL = "https://appbuilder.baidu.com/rpc/2.0/cloud_hub/v1/ai_engine/copilot_engine/service/v1/baidu_search_rag/general"
class SearchResult(BaseModel):
"""搜索结果数据模型"""
title: str = Field(..., description="搜索结果标题")
url: str = Field(..., description="搜索结果链接")
content: str = Field(..., description="搜索结果摘要")
date: Optional[str] = Field(None, description="发布日期")
icon: Optional[str] = Field(None, description="站点图标")
class BaiduAISearch:
def __init__(self):
# 加载环境变量
load_dotenv()
# 配置 BAIDU_API_KEY
api_key = os.getenv("BAIDU_API_KEY")
if not api_key:
raise ValueError("未找到 BAIDU_API_KEY,请检查 .env 文件")
self.headers = {
"Content-Type": "application/json",
"X-Appbuilder-Authorization": f"Bearer {api_key}"
}
def search(
self,
query: str,
model: str = "ERNIE-Tiny-8K",
temperature: float = 1e-10,
top_p: float = 1e-10,
hide_corner_markers: bool = False,
enable_timely_query_rewrite: bool = False,
enable_historical_query_rewriting: bool = False,
enable_instruction_enhance: bool = False,
search_rearrange: bool = True,
top_n: int = 1
) -> List[SearchResult]:
"""执行AI增强搜索
Args:
query (str): 搜索关键词
model (str): 使用的模型,默认为 ERNIE-Tiny-8K
temperature (float): 采样温度,控制随机性
top_p (float): 采样参数,控制多样性
hide_corner_markers (bool): 是否隐藏角标
enable_timely_query_rewrite (bool): 是否启用实时查询重写
enable_historical_query_rewriting (bool): 是否启用历史查询重写
enable_instruction_enhance (bool): 是否启用指令增强
search_rearrange (bool): 是否启用搜索重排
top_n (int): 返回结果数量
Returns:
List[SearchResult]: 结构化搜索结果列表
"""
payload = {
"model": model,
"message": [{"role": "user", "content": query}],
"temperature": temperature,
"top_p": top_p,
"hide_corner_markers": hide_corner_markers,
"enable_timely_query_rewrite": enable_timely_query_rewrite,
"enable_historical_query_rewriting": enable_historical_query_rewriting,
"enable_instruction_enhance": enable_instruction_enhance,
"search_rearrange": search_rearrange
}
try:
response = requests.post(
BAIDU_SEARCH_URL,
headers=self.headers,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8")
)
response.raise_for_status()
data = response.json()
if data.get("code"):
raise Exception(f"API错误: {data.get('message')}")
return self._parse_results(data, top_n)
except requests.exceptions.RequestException as e:
raise Exception(f"网络请求失败: {str(e)}")
except Exception as e:
raise Exception(f"处理失败: {str(e)}")
def _parse_results(self, data: Dict, top_n: int) -> List[SearchResult]:
"""解析API响应
Args:
data (Dict): API 返回的 JSON 数据
top_n (int): 返回结果的数量
Returns:
List[SearchResult]: 结构化搜索结果列表
"""
results = []
# 检查 data 是否包含 result 和 answer_message
result = data.get("result")
if result is None:
print("未找到 result 字段")
return results
answer_message = result.get("answer_message").get("content")
print(answer_message)
if answer_message is None:
print("未找到 answer_message 字段")
return results
return results
def stream_search(self, query: str, **kwargs) -> Generator[SearchResult, None, None]:
"""流式搜索"""
kwargs["stream"] = True
response = requests.post(
BAIDU_SEARCH_URL,
headers=self.headers,
json={
"messages": [{"role": "user", "content": query}],
**kwargs
},
stream=True
)
try:
for line in response.iter_lines():
if line:
# 去掉 "data: " 前缀
line_str = line.decode("utf-8")
if line_str.startswith("data: "):
json_str = line_str[6:] # 去掉 "data: " 前缀
try:
# 解析 JSON
data = json.loads(json_str)
# 检查 result 和 answer_message 是否存在
result = data.get("result")
if result is None:
continue # 跳过无效数据
answer_message = result.get("answer_message")
if answer_message is None:
continue # 跳过无效数据
content = answer_message.get("content")
if content:
yield SearchResult(
title="实时结果",
url="#",
content=content
)
except json.JSONDecodeError:
print(f"无法解析的流式数据: {json_str}")
except Exception as e:
raise Exception(f"流式响应错误: {str(e)}")
# 使用示例
if __name__ == "__main__":
# 执行搜索
searcher = BaiduAISearch()
# 普通搜索
try:
results = searcher.search("武汉去哪旅游比较好", top_n=1)
except Exception as e:
print(f"搜索失败: {e}")
进行测试:

通过,🎉👌没有问题,正常返回!
2.数据库访问工具类
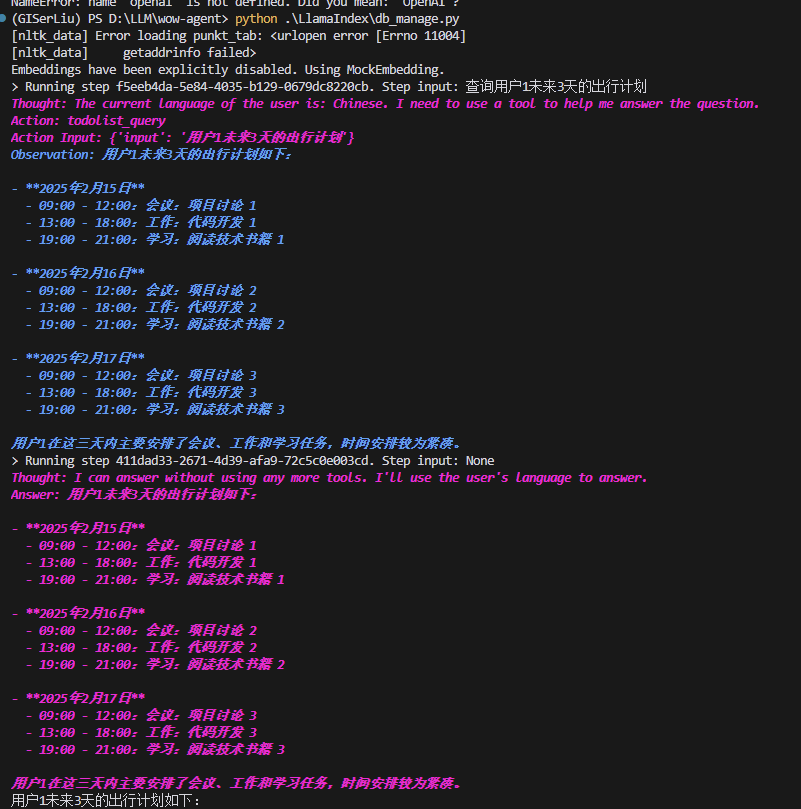
运行测试通过!没有问题,今天我们就学到这里!😉👌🎉
3.RAG调用类(可选)
RAG本身我们也可以作为Agent的工具进行调用;因此我们可以选择性构建这个类;作者因为本地ollama服务出了问题,这里使用huggingface上的BAAI/bge-small-en-v1.5模型进行词嵌入;
pip install llama-index-embeddings-huggingface
pip install llama-index-embeddings-instructor
作者这里就直接根据网页信息查询了,暂不考虑使用RAG;这里直接给出代码:
import os
from llama_index.core import SimpleDirectoryReader, Document
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion.pipeline import run_transformations
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
from openai import OpenAI
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.response_synthesizers import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.tools import QueryEngineTool, ToolMetadata
from llama_index.core.agent import ReActAgent
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from dotenv import load_dotenv
from pydantic import Field
from llama_index.core.llms import CustomLLM, CompletionResponse, LLMMetadata
from llama_index.core.llms.callbacks import llm_completion_callback
from typing import Any, Generator
from pydantic import ConfigDict
# 加载环境变量
load_dotenv()
# 定义 DeepSeekLLM 类,继承自 CustomLLM 基类
class DeepSeekLLM(CustomLLM):
api_key: str = Field(default=os.getenv("API_KEY"), description="API密钥")
base_url: str = Field(default=os.getenv("BASE_URL"), description="API基础URL")
model_name: str = Field(default=os.getenv("MODEL_NAME"), description="模型名称")
client: OpenAI = Field(default=None, exclude=True, description="OpenAI客户端实例")
# 添加 model_config 以解决命名空间冲突
model_config = ConfigDict(protected_namespaces=())
def __init__(self, api_key: str = None, base_url: str = None, model_name: str = None, **data: Any):
super().__init__(**data)
self.api_key = api_key or os.getenv("API_KEY")
self.base_url = base_url or os.getenv("BASE_URL")
self.model_name = model_name or os.getenv("MODEL_NAME")
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url)
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据"""
return LLMMetadata(model_name=self.model_name)
@llm_completion_callback()
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""同步生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
)
if hasattr(response, 'choices') and len(response.choices) > 0:
response_text = response.choices[0].message.content
return CompletionResponse(text=response_text)
else:
raise Exception(f"Unexpected response format: {response}")
@llm_completion_callback()
def stream_complete(self, prompt: str, **kwargs: Any) -> Generator[CompletionResponse, None, None]:
"""流式生成文本"""
response = self.client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": prompt}],
stream=True,
)
try:
for chunk in response:
chunk_message = chunk.choices[0].delta
if not chunk_message.content:
continue
content = chunk_message.content
yield CompletionResponse(text=content, delta=content)
except Exception as e:
raise Exception(f"Unexpected response format: {e}")
# 配置对话模型和嵌入模型
class RAG:
def __init__(self):
"""
初始化 RAG 类
"""
# 配置对话模型
self.llm = DeepSeekLLM()
# 配置嵌入模型(使用 HuggingFaceEmbedding)
self.embedding = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
# 初始化索引和查询引擎
self.index = None
self.engine = None
def build_index(self, input_files: list[str], chunk_size: int = 512):
"""
构建索引
:param input_files: 输入文件路径列表
:param chunk_size: 分块大小
"""
# 从指定文件读取数据
documents = SimpleDirectoryReader(input_files=input_files).load_data()
# 构建节点
transformations = [SentenceSplitter(chunk_size=chunk_size)]
nodes = run_transformations(documents, transformations=transformations)
# 构建向量存储
emb = self.embedding.get_text_embedding("测试文本")
vector_store = FaissVectorStore(faiss_index=faiss.IndexFlatL2(len(emb)))
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 构建索引
self.index = VectorStoreIndex(
nodes=nodes,
storage_context=storage_context,
embed_model=self.embedding,
)
def build_query_engine(self, similarity_top_k: int = 5):
"""
构建查询引擎
:param similarity_top_k: 检索结果的 top-k 数量
"""
if self.index is None:
raise ValueError("请先构建索引")
# 构建检索器
retriever = VectorIndexRetriever(
similarity_top_k=similarity_top_k,
index=self.index,
)
# 构建合成器
response_synthesizer = get_response_synthesizer(llm=self.llm, streaming=True)
# 构建问答引擎
self.engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
def get_query_tool(self):
"""
获取查询工具
:return: QueryEngineTool 对象
"""
if self.engine is None:
raise ValueError("请先构建查询引擎")
return QueryEngineTool(
query_engine=self.engine,
metadata=ToolMetadata(
name="RAG工具",
description="用于在原文中检索相关信息",
),
)
# 定义 RAGAgent 类,用于整合 RAG 工具和 ReActAgent
class RAGAgent:
def __init__(self, llm: CustomLLM):
"""初始化 RAGAgent,加载 RAG 工具并创建 ReActAgent 实例"""
rag = RAG()
rag.build_index(input_files=["test.txt"])
rag.build_query_engine()
query_tool = rag.get_query_tool()
self.agent = ReActAgent.from_tools([query_tool], llm=llm, verbose=True)
def main():
"""主程序入口"""
try:
# 实例化 DeepSeekLLM 和 RAGAgent
deepseek_llm = DeepSeekLLM()
rag_agent = RAGAgent(deepseek_llm)
# 使用 Agent 查询
response = rag_agent.agent.chat("What are the applications of Agent AI systems?")
print(response)
except Exception as e:
print(f"程序运行出错: {e}")
if __name__ == "__main__":
main()
四、组合Agent
暂略,并不是一个较好的效果,有点像MetaGPT的既视感!后续优化后更新!
😂 今天就学习到这里!
文章参考
项目地址

如果觉得我的文章对您有帮助,三连+关注便是对我创作的最大鼓励!或者一个star🌟也可以😂.

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)