一文读懂DeepSeek-R1私有化部署与本地部署
从上图可以看出,S1-32B模型在数学问题解决(MATH500)、竞赛数学(AIME24)和博士级科学问题(GPQA Diamond)三个任务上的表现。随着思考时间的增加,模型的准确率也有所提升。为了更好的服务企业OneThingAI支持使用vLLM 部署DeepSeek,vLLM版本为DeepSeek官方推荐的vLLM 版本0.6.6。下面会以部署一个32B的蒸馏版本为例,更多Ollama官方量
新年AI爆点!DeepSeek R1与Janus模型开启智能新篇
上一篇文章我们整理了一些DeepSeek-R1论文中提到的蒸馏相关知识
最近李飞飞团队也复刻了一个叫S1的模型,他们到底做了什么呢?

▲ 不同思考时长下的准确率变化(横轴:Token数量,纵轴:准确率)
从上图可以看出,S1-32B模型在数学问题解决(MATH500)、竞赛数学(AIME24)和博士级科学问题(GPQA Diamond)三个任务上的表现。随着思考时间的增加,模型的准确率也有所提升。
OneThingAI免费API接入
以下是一个简单的Python示例,展示如何接入OneThingAI免费的API:
from openai import OpenAIclient = OpenAI(base_url='http://llms.onethingai.com/v1',api_key='OnethingAI')completion_res = client.completions.create(model='deepseek-ai/deepseek-reasoner',prompt='onethingai是做什么的?',stream=True,max_tokens=4096,)
OneThingAI提供Ollama镜像
下面会以部署一个32B的蒸馏版本为例,更多Ollama官方量化的DeepSeek-R1 模型参考 Ollama 官方的模型中心。

进入OneThingAI平台。
登录OneThingAI:OneThingAI算力云 - 热门GPU算力平台
创建一个新的Ollama实例,选择1卡4090配置。





启动完成后进入webshell,运行如下命令:
ollama run deepseek-r1:32b
执行结果
对外提供服务
推荐使用TCP转发和HTTPS连接。需要独立公网IP的用户联系OneThingAI。

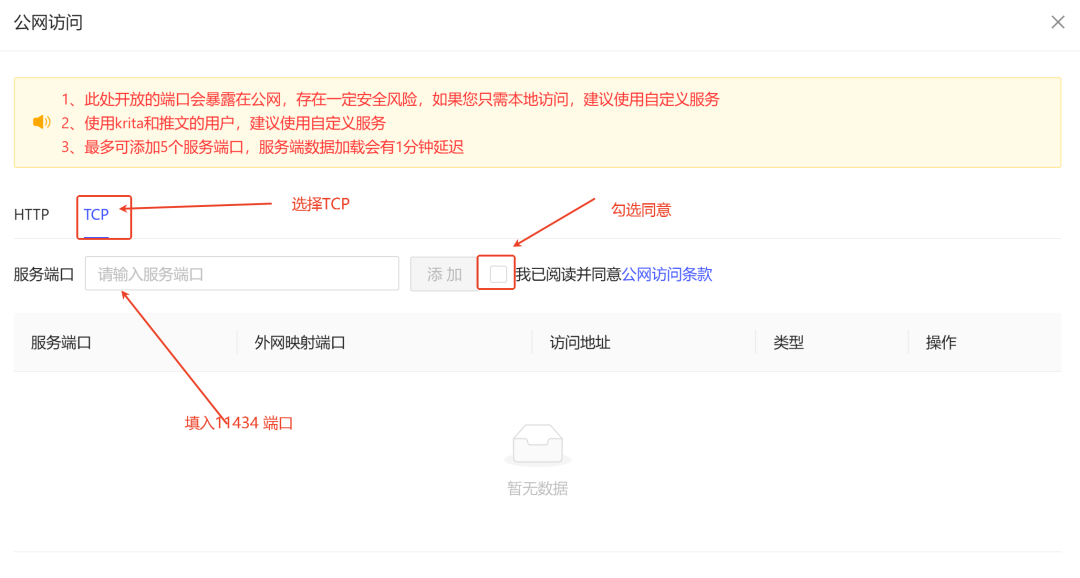

API访问方式
HTTP可直接访问API
(此处标红,着重:使用自己生成的地址替换命令里的url)
curl -v http://mars.onethingrobot.com:37793/api/chat \-H "Content-Type: application/json" \-d '{"model": "deepseek-ai/deepseek-reasoner","messages": [{"role": "user", "content": "这是一个测试"}],"stream": true}'
怎么访问https
申请自己的域名,实例里安装nginx并配置自己域名和证书。dns管理平台上CNAME到mars.onethingrobot.com(如有问题可联系OneThingAI或留言)

Tips:怎么选择显卡:根据模型所需显存大小来选择。单块4090 24GB显存,假设模型大小是 D GB, 所需卡数 n = D/ (24 * 0.8) 流出一定空间给kv cache。
创建一个2卡的实例,启动完成后执行:
ollama run deepseek-r1:70bvLLM的使用
为了更好的服务企业OneThingAI支持使用vLLM 部署DeepSeek,vLLM版本为DeepSeek官方推荐的vLLM 版本0.6.6


根据模型大小选择卡数创建实例
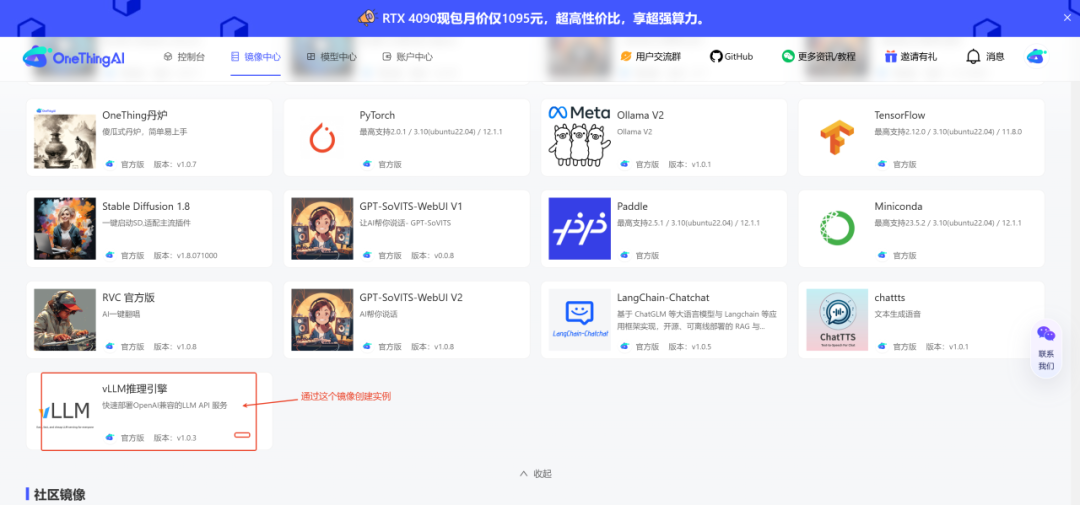


Qwen 14B 为例,创建2卡实例
打开webshell:

运行以下命令:
ls /app/deepseek/结果如下,目前已经预装4款以Qwen为底模的 DeepSeek-R1蒸馏模型

启动模型服务:
# 预装模型已经有模型文件,没有模型元数据,可用如下命令补全modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-14B --exclude *.safetensors --local_dir /app/deepseek/DeepSeek-R1-Distill-Qwen-14B# 启动fp8 量化的推理, 根据效果要求可以去掉参数 --quantization="fp8"vllm serve /app/deepseek/DeepSeek-R1-Distill-Qwen-14B \--host 0.0.0.0 --port 6006 --quantization="fp8" --tensor-parallel-size 2 --max_model_len 32384 \--served-model-name deepseek-ai/deepseek-r1:14b
启动完成结果如下

配置公网服务和使用API
操作Ollama节所述,参考(可以添加指向跳转),vLLM提供的API 兼容openai sdk(有问题联系OneThingAI)
from openai import OpenAIclient = OpenAI(base_url='http://{your_url_here}/v1',api_key='your_key_here')completion_res = client.completions.create(model='deepseek-ai/deepseek-r1:14b',prompt='onethingai是做什么的?',stream=True,max_tokens=4096,)
vLLM 的更多使用方式和参数参考:vLLM官方文档
如何本地化部署
如果公司有4090,H100等算力,怎么在公司内部算力上本地部署一套DeepSeek-R1模型给公司的使用。
在linux 服务器上使用docker方式比较容易(如运行过程遇到问题联系OneThingAI或留言)
# 拉取vllm 0.6.6 版本的镜像, 最新的0.7.1 可能会遇到问题# 如:https://github.com/vllm-project/vllm/issues/12769docker pull vllm/vllm-openai:v0.6.6# 启动vllm, 假设模型等文件已经放在 /data/deepseek 下# 假设4 块4090 跑32B的蒸馏模型docker run --network host \--name deepseek \--shm-size 32g \--gpus all \-v "/data/deepseek:/root/deepseek" \-it \--ipc=host \-e GLOO_SOCKET_IFNAME=eth1 -e NCCL_SOCKET_IFNAME=eth1 \vllm/vllm-openai:v0.6.6 \/root/deepseek/DeepSeek-R1-Distill-Qwen-32B \--host 0.0.0.0 --port 6006 --quantization="fp8" --tensor-parallel-size 4 \--max_model_len 32384 \--served-model-name deepseek-ai/deepseek-r1:32b
后续OneThingAI会推出vLLM、SGLang等推理引擎的Docker镜像和本地部署模型的方案。
END
关于我们
OneThingAI官网:OneThingAI算力云 - 热门GPU算力平台

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)