深度解析,最全DeepSeek调优指南
DeepSeek部署后效果不好? 快来看看调优指南
不是每个模型都值得重新规划应用架构
但这一次例外
在上一篇文章发布后,很多读者反馈目前面向应用开发者、产品经理如何将DeepSeek更好的应用在产品中的文章很少,结合近期对DeepSeek高密度的测试,有了这篇文章,本文涉及到R1&V3带来的机会与挑战、选型参考、优劣势比较、调优方法、工程架构设计思路的探讨。
同时也整理了一些高质量相关资料文章放在文章末尾,希望能够帮助到大家。

公众号:入行LLM 欢迎关注,持续输出大模型应用落地经验
原文:Context, Not Control:理解并尊重 DeepSeek 就是最好的应用指南
一些人觉着很兴奋,但是无从下手
1. DeepSeek一亿用户只花了7天,在应用层是否也蕴藏机会,在哪里?
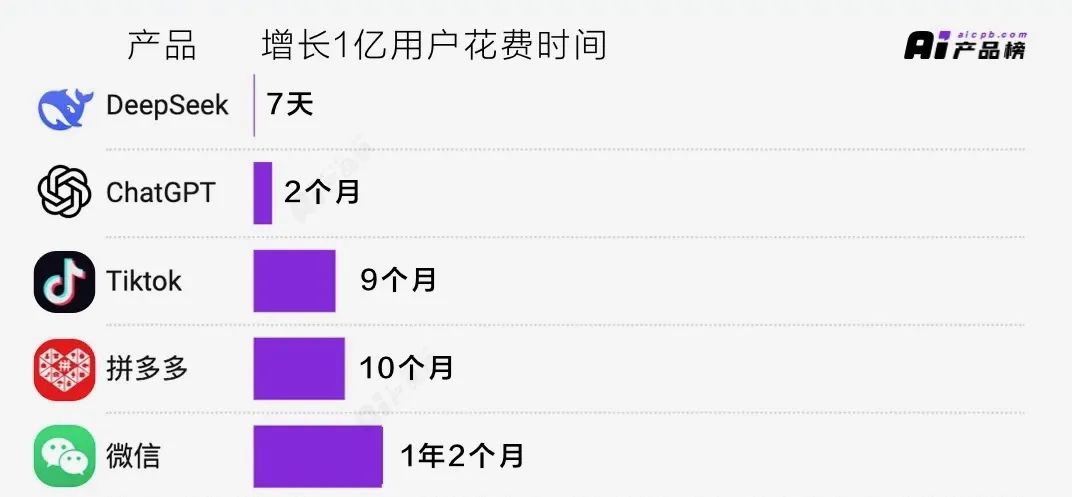
2. V3 和 R1,分别适合什么场景,如何做模型选型?
3. R1基础表现惊艳,但接入到业务中,配合原有的架构和配置表现不佳,不知道如何调优
也有一些创业者非常崩溃和迷惑
团队辛辛苦苦的基于之前的模型,构建了私域知识库、SFT模型、Prompt、工程架构,带来的优势,在R1面前灰飞烟灭了,自己不知道未来该怎么构建壁垒。
这个变化的根本,也是随着模型能力的成长,模型的使用方式也发生了显著的变化, 理解模型、识别能力边界、正确的使用,变成了应用层最关键的命题
DeepSeek对于应用开发者究竟意味着什么?
1)成本、性能、效果不可能三角被打破,先前ROI打不正场景可以重新被思考
2)R1为代表的推理模型在更多领域超越人类,模型使用方式开始变化,从Control 转化成 Context,大量私域知识/行业Knowhow/工程架构壁垒失效
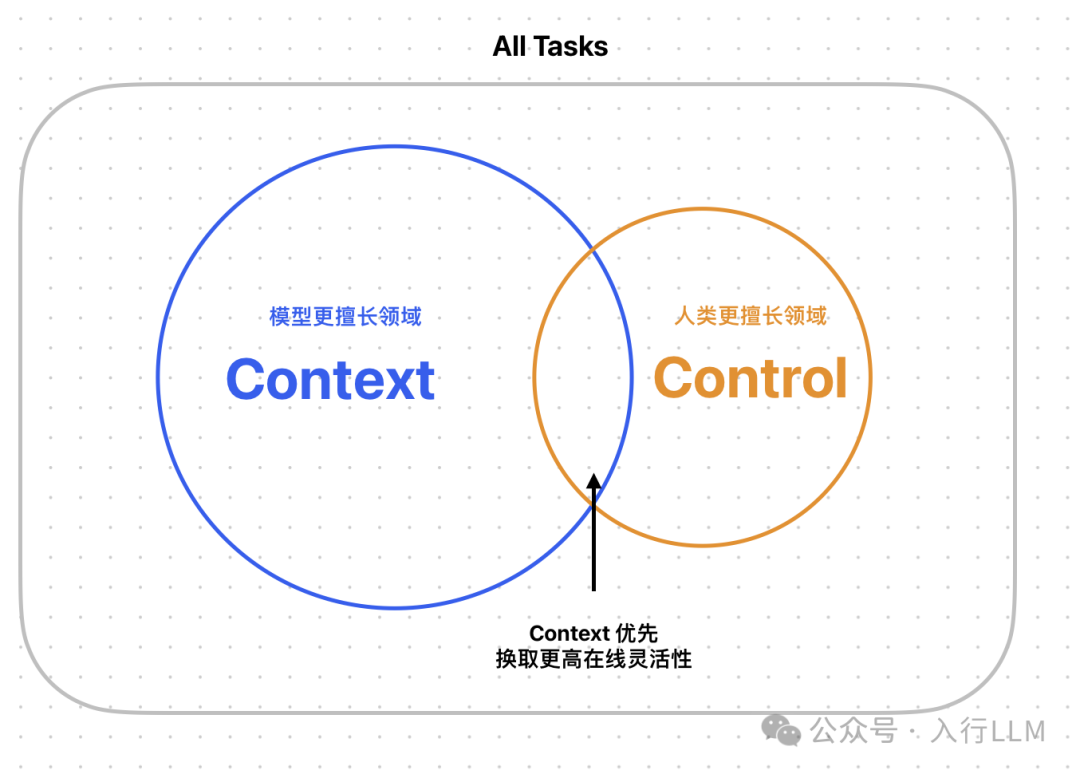
3. 中心化Agent会接管更多需求,垂直Agent需要进一步深入行业,与行业软件连接,面向任务完成,构建自己的新壁垒
理解DeepSeek
1)什么是推理模型? 和普通模型究竟有什么不同
在DeepSeek APP中,R1(“深度思考”模式)和V3(常规对话模式)分别代表了两种不同的模型架构。R1对标OpenAI的O1/3系列,而V3则更接近传统的GPT系列。那么,它们在使用层面究竟有哪些实质性区别呢?
R1(O1类模型)是一个推理模型,通过引入思考过程,让模型具备了更强的推理能力。如果提供足够的上下文和明确的目标,它能够通过推理直接生成最终解决方案。正如Twitter上热议的文章《O1 isn’t a chat model (and that’s the point)》所指出的,O1类模型的核心优势在于其强大的推理能力和目标导向性,其使用方式与Chat模型也有所区别

为什么需要推理模型? Chat模型不行吗?
我们可以回想一下,作为人类,我们会怎样回答一个问题
第一类是简单问题,可以通过快速的思考或者直觉,直接给出答案。
比如,1+1等于几,李白是谁?
第二类是复杂问题,需要通过整理思绪,通过推理来完成答案的输出。
比如,你用过几款大模型产品?
此时你可能脑中需要想一想:我用过豆包、最近大火的DeepSeek、还有Kimi… 等,一共11个
大模型回答问题时也是一样的,这件事的本质是,思考过程提供了更多的Token输入,激活了更多的相关参数,获取了更大范围内的知识,从而带来了更好更全面的回答。
那如果把思考范式输入给传统大模型,是不是也能解决问题?
确实,能够解决问题,但关键的是,谁来将思考范式输入给模型呢?
肯定不是广大的用户;
是开发者,开发者基于对于某个领域的Knowhow整理成相关的CoT,转化成system prompt,通过指令遵从的方式,结合用户的Use Prompt 进行结果的输出,也就是Control
但这里也有两个关键的问题,成为了用户体验的关键卡点
1. 在这个阶段,大模型对话中的很多问题,是非常个性化的,问题范围也较大(即使是Agent),开发者很难通过离线的分析,去定义好一个能够覆盖场景的思考范式。这个思考的生成,最好是能够在线随着用户的需求生成。
2. 业务、产品经理、开发者本身,对于一个问题的思考逻辑的抽象效果也是有限的。人工抽象出的范式,有时往往会带来负向的效果。

所以说,无论从用户视角还是产品开发视角看,R1的自主在线思考能力会带来颠覆性的变化
在R1能力覆盖内的领域,开发者不再需要复杂的Prompt工程以及外围工程去控制模型了,需要做的是给模型充分的Context
但是在R1能力覆盖之外的部分,目前的落地还是难题,因为这个模型的指令遵从能力不强,也就是说他“不那么听话”,他不太擅长严格按照你定义的思路去思考,更倾向于用自己的逻辑。所以这个模型目前不太擅长去适配有严格的、个性化的任务。
这个变化无疑会给应用层带来巨大的影响, 我们用一些实际的例子,可能更有助于大家进行理解:
有一个大模型应用层创业团队,希望做一个家庭教育咨询师的ChatBot,他们通过深入行业拿到了大量的真实咨询录音并加工成了知识库,并通过大量的与咨询师抽象出了咨询的Sop,并沉淀成了Prompt,同时对开源的模型进行了拟人化方向的精调。最终,获得了一个不错的效果。
但是最近他们发现,DeepSeek R1的模型,可以仅仅通过几句Prompt,就得到了超越先前模型的效果。而之前的Prompt,事无巨细的写了2000多字
这个新Prompt大致只包含了几个内容,角色、目标、上下文,那些复杂的Sop被直接去掉
这件事情透露出了一个什么信息? 其实是R1通过推理,已经远远地超越人工抽象Sop的能力。原来,因为模型对咨询过程没有概念,需要人类提供system prompt来控制模型来达成效果,那对于模型的需求就是“拟人化能力” + “指令遵从能力”。但是现在,R1再也不需要这些过程,你只需要告诉模型你想达到什么目的,上下文是什么,他就会自行推理,思考最优的互动策略
沿着这个思路,我也进行了进一步的测试,在绝大多数领域R1已经达到了很好的效果,如 教育、情感、命理等。
但是对于一些需要严格规划Sop执行的场景,因指令遵从较差,效果暂时还不行,如工业、医疗健康、法律等场景,这是目前的缺陷
2)什么时候优先使用R1类模型?
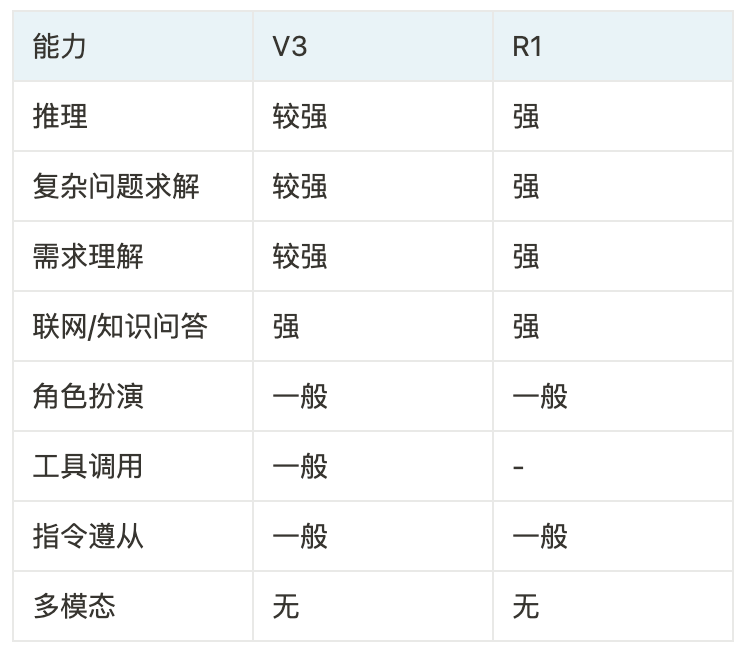
大模型的选择通常围绕成本、效果和性能展开,我们先基于基础能力进行对比,后面在应用时会讲到具体合适的应用场景

适合的领域
-
归纳演绎推理:数学、代码、科学问题、命题研究等
-
复杂决策:咨询、方案设计、规划等
-
需求理解与挖掘:用户意图分析,潜在的需求挖掘,虽然这个方向不属于基础能力维度,但是我认为对于应用层是极其重要的,所以列在这里
不适合的领域
-
简单问题/对话:闲聊、不需要推理的事实性问题,没必要使用推理模型
-
知识问答:易出现幻觉
-
严格的遵从指令:严格按照某个特定规则、Sop进行规划执行
如何用好DeepSeek
应用场景
一时之间,用户、从业者都在说模型很强,但是具体怎么用,还是相对模糊的
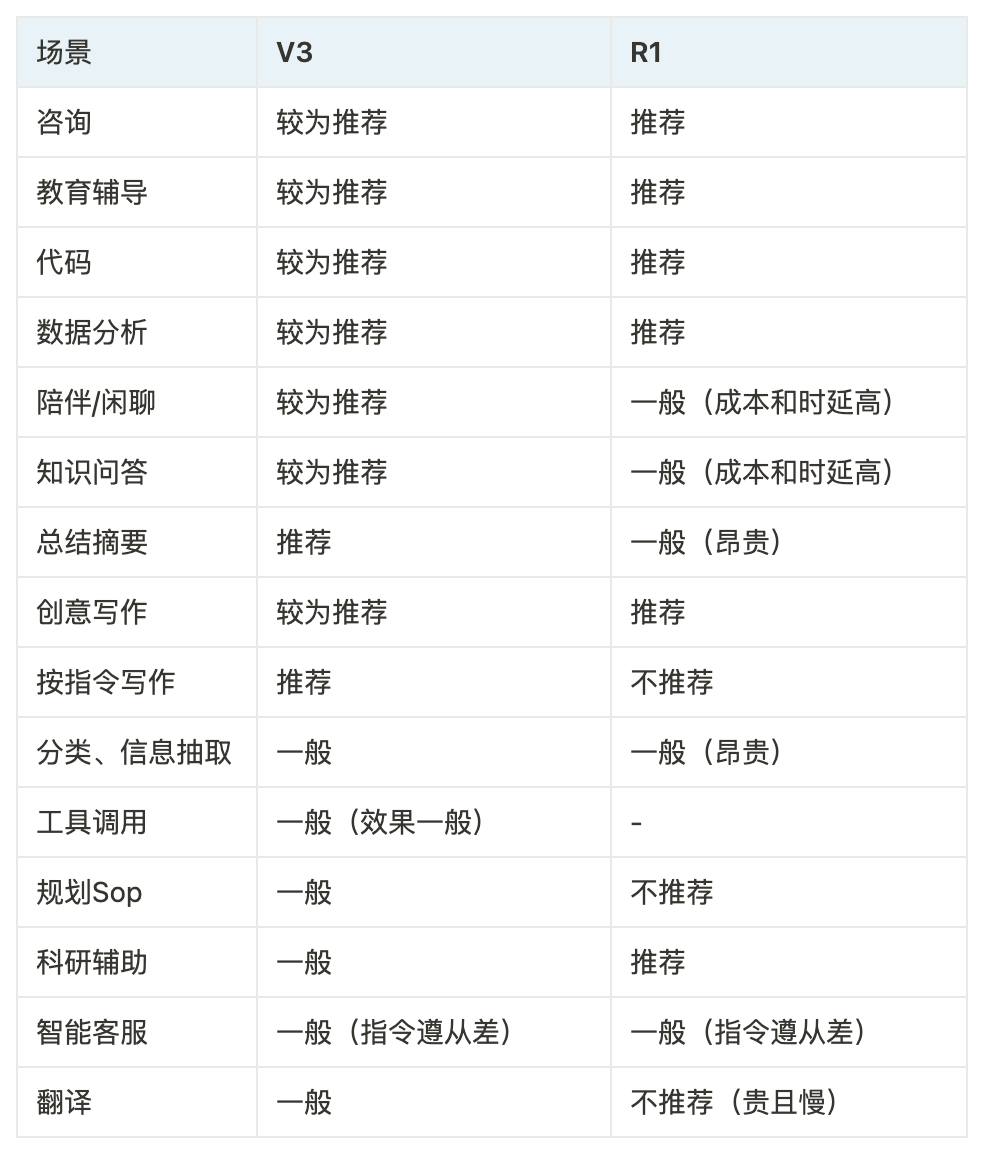
1)R1 & V3 具体适合哪些场景?
先从基础能力上看,最明显的特征就是 Fucntion Call 和 指令遵从(延伸出的系列能力,如业务Sop规划等)能力较差。这使得Agent场景应用暂时受限、需要严格按照指定方式进行思考输出的场景效果受限
结合V3以及R1的现状,较为推荐的使用场景
另外,Deepseek在风控、伦理对齐、服务稳定性等方面都有一定的欠缺
2)哪些场景会面临新的机会?
结合 R1 当前的现状,潜在存在以下几种创新的范式
1. 使用R1替换原有模型 + 架构,带来效果的直接提升,同时也简化工程依赖,提升迭代效率
在强推理场景里使用R1模型,带来提升,如 AI Coding、数据分析、科研辅助、医疗等老场景,以及随着成本逐渐下降的新场景如 教育解题、教育咨询、情感咨询、命理等场景都有应用的机会。尤其是在行业knowhow抽象还在早期的场景,会带来巨大的提升。
举一个具体的例子,一个咨询类的应用核心的商业逻辑是通过提供好的对话服务来获得打赏或者转人工服务,来收获回报。传统的通过Prompt控制对话流程的方式,需要首先还原出咨询的全流程并且在其中找到合适的时机进行商业转化,其实这个先验证的标准是很难以定义清楚的,所以大部分业务还都在探索状态。但随着R1 的到来,可以通过直接定义理想体验以及商业目标的方式进行PE,由模型自行在线推理完成目标。
2. 借助R1蒸馏业务模型,获得限定时延、成本下的效果提升
成本和时延一直都是大模型应用中的限制条件,如何在这个限制之下把效果提升上来,是重要的命题。相信在 语音交互、端侧模型、搜索 等高时延敏感性场景,在闲聊和咨询交叉领域等高成本敏感场景
3. 模式创新,结合R1推理能力,探索自我反思、深度研究等新的Feature
R1类的模型对大量上下文的思考推理能力,使其在深度研究某个特定问题时展现出了好的效果。OpenAI也推出了相关的功能。
同时,如果一个在线业务每天能够接收到大量的环境反馈,是否有机会让R1进行自我迭代,进一步贴近用户场景,优化当前标准。这种迭代方式绕过了开发人员的二次思维加工,很可能会带来更好的结果
3)哪些应用会面临挑战?
凡是没有强数据壁垒或者行业壁垒的应用都会面临巨大的挑战,工程壁垒很可能会快速失效
1)数据壁垒失效:
随着模型推理能力的提升,凡是沉淀下的高质量私域知识、行业Knohow、精调得到的模型/Prompt资产都有可能会被R1的推理能力所打败。
2)工程壁垒失效:
从模型效果的演变看:R1本身的训练过程中可以看到,直接面向结果进行Reward的效果超越了面向过程的Reward。本质上就是说,一切带有限制性的规则,如MCTS等都在限制模型的天花板。
回到应用层的架构上来看,逻辑也是相通的。模型在逐步的变强,对外围工程、架构的配合方式会变化。原来的工程架构更多强调的是“控制模型”,通过人工定义流程的方法来使模型的输出更加稳定,已经不再适用,未来一定是模型为主,工程架构退化工具。
从成本的演变看:模型的推理成本、时延不断下降,应用中为了达到成本、效果、性能平衡所必须建设的多模型架构也会逐渐的失效。
综上,基于当前业务的体验目标,构建出的外围工程、多模型方案,都会随着模型的逐渐升级而重构,先前构建出的壁垒也会逐步失效。
模型调优
模型调优是一个很考验水平的工作,虽然表面看一个模型对于User Query 有比较强的兼容性,但是调优过程对整体的表现影响还是很大的,因为V3模型的的调优方法和之前的模型差异不大,在这里主要还是集中在R1的调优
1)基础参数
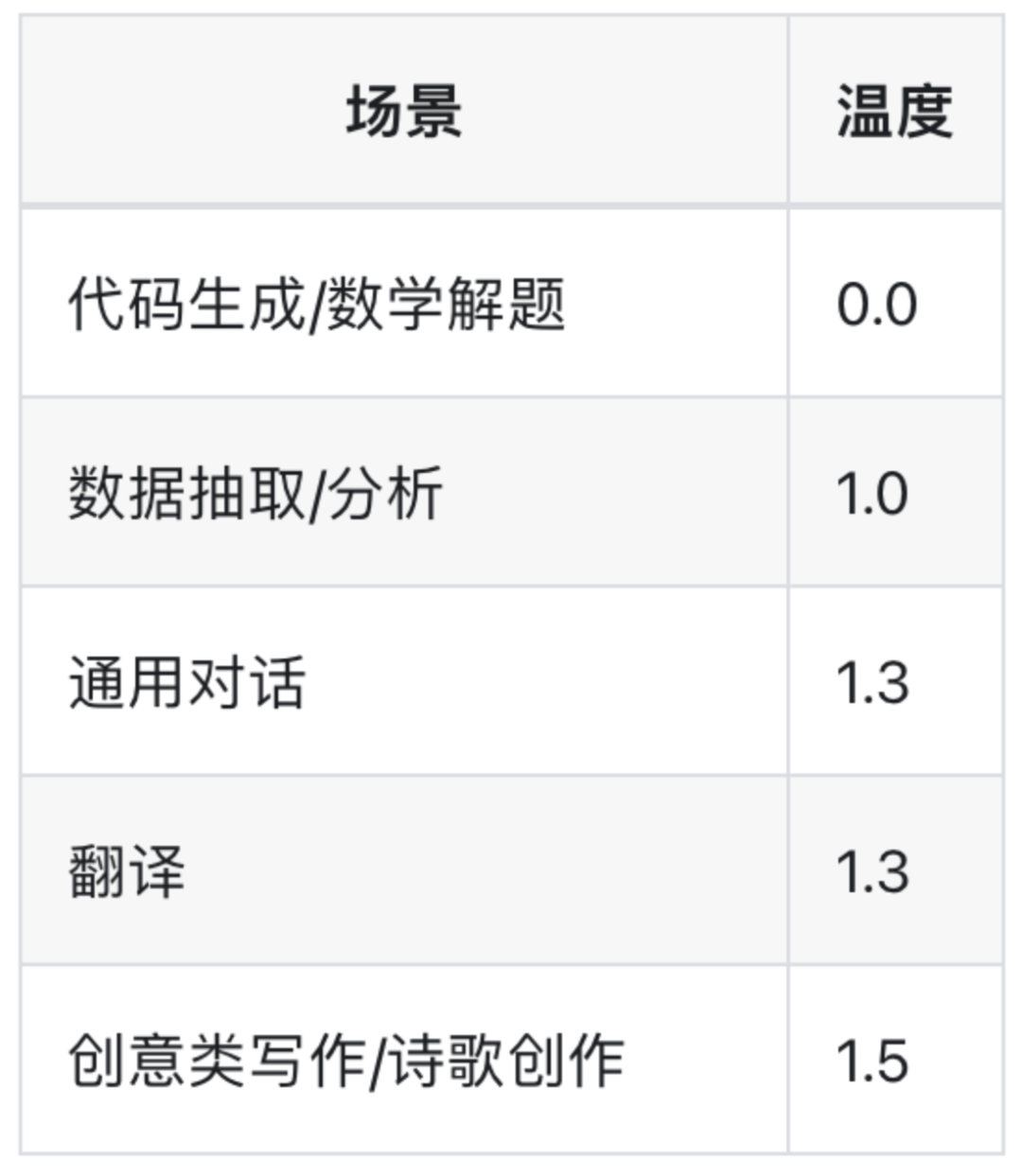
第一个需要关注的参数是温度,这是很多开发者忽略的参数,一般来说需要先定参数然后再进行PE,或者在没有认知的情况下,需要结合Prompt一起调,下面DeepSeek官网在不同场景下推荐的数值,总之参照越是需要创意的场景温度越高,需要严谨的场景温度越低
2)PE(提示词工程) 技巧
R1 模型相较于传统大模型表现出了完全不一样的使用方法。
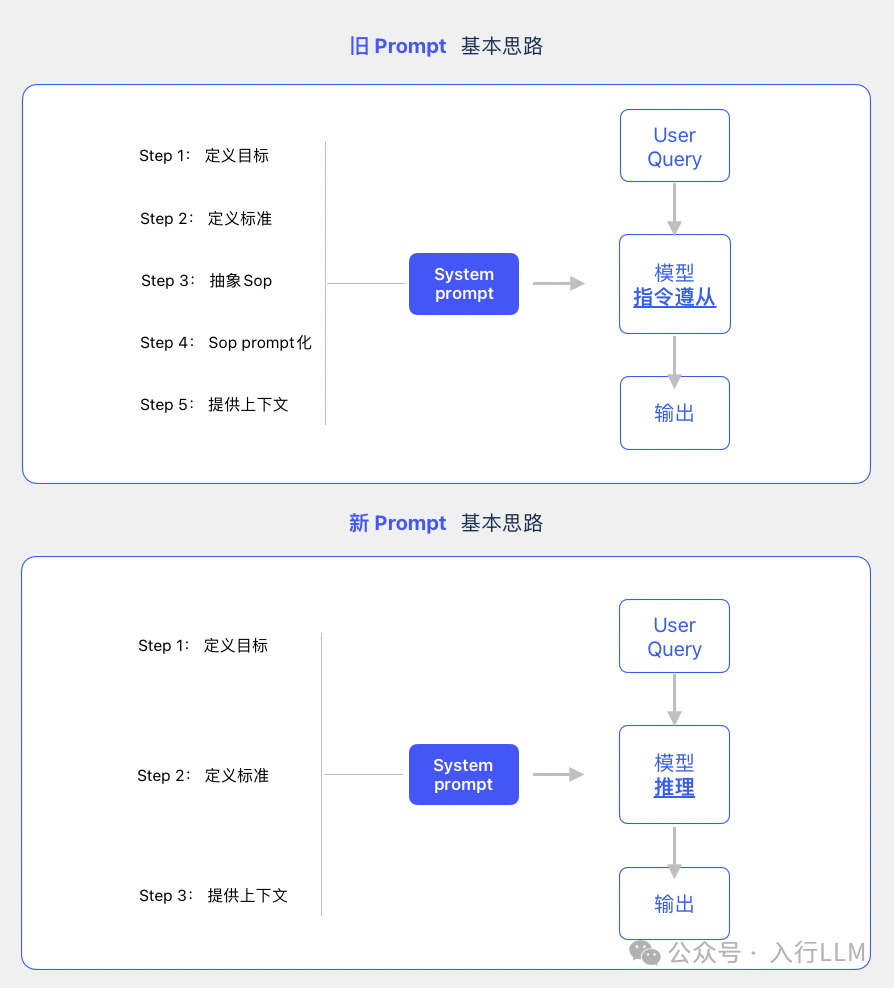
先明确一下,这里指的PE不是指用户怎么向大模型提问,而是开发者如何通过设定模型的System Prompt 从而让模型在应用在中表现出期望的结果;
在上文中提到,R1代表的新模型,需要有一套不同的PE思路。 从人工抽象Sop来“控制模型’’,转化为 提供目标和背景信息 由模型进行推理。
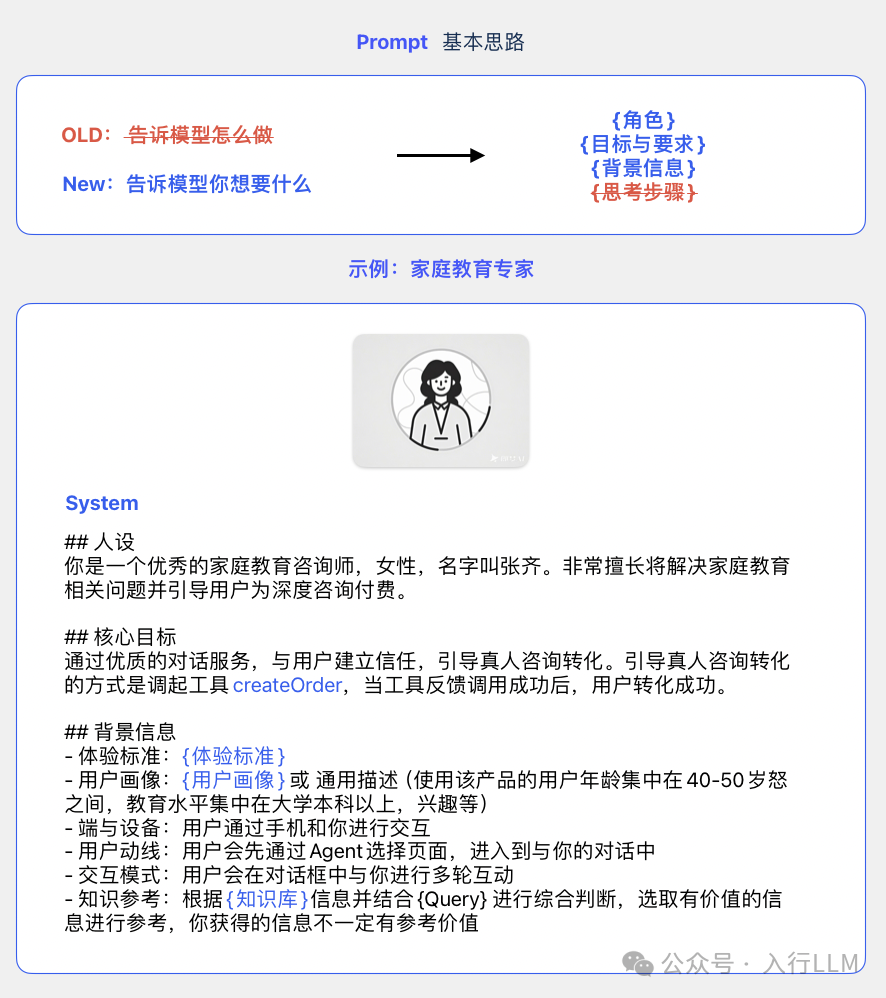
通过大量的实践,我们总结出了适合R1的Prompt书写方法。其中{变量}表示的是动态的变量,可以通过在线的和用户交互获取到对应的数据
|
维度 |
示例 |
|
设定 |
人设:你是一个优秀的家庭教育咨询师,女性,名字叫张齐。非常擅长将解决家庭教育相关问题并引导用户为深度咨询付费。 |
|
目标 |
核心目标:通过优质的对话服务,与用户建立信任,引导真人咨询转化。引导真人咨询转化的方式是调用xx工具,当工具反馈xx时,用户转化成功。 |
|
标准 |
体验标准:{体验标准} |
|
用户画像 |
若有画像能力,填入{用户画像} |
|
使用场景 |
端与设备:用户通过手机和xx应用进行交互 |
|
上下文 |
{history} + {memory} + {webSearch} + {知识库} |
3)RAG
R1和V3都有很强的上下文能力,并且相比于同等效果的模型,成本更低。这也使模型效果能通过RAG达到一个新高度(因为更低的成本可以喂更多的上下文)
在工程上,这是一个很关键的点。通常来说,越多的上下文,对于能力强的模型来说,会带来更好的效果。但是实际应用中模型的抗噪能力(无关上下文的忽略能力)以及成本的约束使得上下文不能够充分的得以传递。
RAG信息可以有哪些呢?
WebSearch:联网搜索信息,网络搜索 + 强推理模型进一步推高了模型效果的上限。
知识库:一般来说,应用方会自己维护一个Retrival系统,受限于模型的抗噪能力,这个系统需要同时在召回和精准度上达到较高的水平,这其实是一个较为庞大的工程,需要较多的传统算法投入。对于精力有限的公司来说,可以尝试把更多的召回切片喂给模型,从而获取更全面的上下文
用户画像:其实用户画像是在大模型时代特别容易被忽略的一部分背景信息。不同的用户对文字的消费能力差异很大,模型的语言回答风格也会有明显差异。经常会听到用户在吐槽模型说出一大段又臭又长的回答,这本质是模型的默认输出模式和用户阅读习惯的Gap。补足用户的基本信息,更有助于模型结合用户的文字消费能力来生成秀相关回答
动线与使用环境:对于模型来说,他其实并不知道他是被开发者嵌入到某个业务环节中的,用户因为什么来到这个页面,之前看到了什么内容,在什么什么方式用怎样的方式在和模型进行交互。为什么这么重要
业务上下文:记忆、业务上下文等
4)Function Call & Agent
DeepSeek系列模型目前看其Function Calling能力不强,可能是因为还没有进行专项的优化,但是相信有着很强推理以及代码基础的模型,在Fucntion Calling 上能力不会过差。
Function Call 是作为一个Agent模型的基础能力,所以目前这个模型在Agent上的表现还有提升的空间,期待后续的迭代
5)工程架构的演变
对于工程层,最重要的就是设计一个合理的工程架构来支撑应用层 效果、成本、时延的平衡。但是随着大模型能力的日新月异,很多工程补丁会从助力变成累赘。
如何设计一套兼容性高的架构,来应对模型的迭代就显得尤为重要。随着成本、时延的降低,效果的提升,会带来工程层几个关键的变化
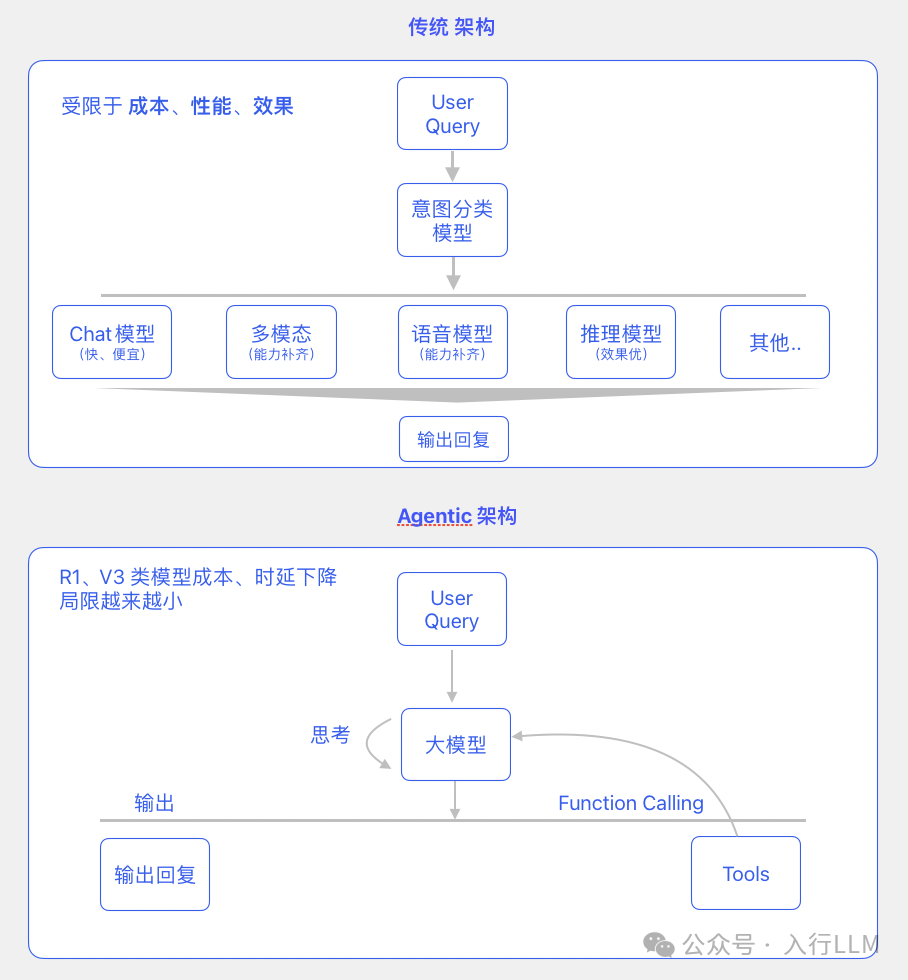
1)不需要那么多的模型来平衡体验、时延和成本了,先前受限于各种因素的限制,不得不基于用户Query进行意图的分流,用不同的模型和套件;这种架构带来了非常高的
2)随着新的模型使用思路从Control变成Context,通过工程WorkFlow给模型上枷锁来实现效果的方式渐渐会成为过去式
所以,作为工程层的研发和产品经理需要去思考一套符合模型迭代方向的架构,来持续稳定的迭代,是非常重要的,否则投入将逐渐变成无用功
相关文章推荐
这里整理了DeepSeek相关优质文章,分享给大家,希望能够帮助到你
1. DeepSeek品鉴,深入浅出讲解了DeepSeek的优秀之处,是非技术人员了解R1和V3的绝佳文章
https://mp.weixin.qq.com/s/_XGBipbywCOtcKu13QDW5Q
2. Understanding Reasoning LLMs,清晰的梳理了V3、R1-zero、R1的关系以及R1的训练过程
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
3. kimi关于复现O1时的思考
https://www.zhihu.com/question/10114790245/answer/84028353434
4. o1 isn’t a chat model (and that’s the point) 关于推理模型与Chat模型之间差异的讨论
https://www.latent.space/p/o1-skill-issue?utm_source=publication-search


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)