
DeepSeek掀起AI风暴:中国科技被重新定义,一条“鲶鱼”撼动全球格局
当DeepSeek R1在 2025 年初横空出世时,几乎没有人预料到它会在短短时间内掀起如此巨大的风浪:不仅在技术维度上令行业侧目,更让人瞩目的是它带来的“开源浪潮”。在此之前,全球大语言模型几乎都走闭源路线,动辄耗资几十亿,难以被普通团队或个人复制。DeepSeek却以“低算力、高效率、主动拥抱开源”理念实现了弯道超车,让所有人重新审视中国AI的潜力。与此同时,随着 DeepSeek 的爆火,
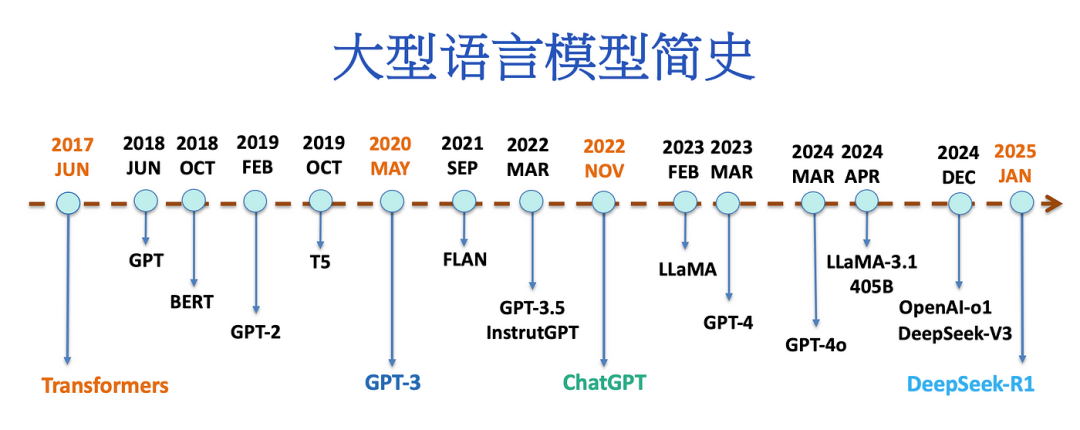
1. 概述:从边缘到中心,DeepSeek搅动AI江湖
当DeepSeek R1在 2025 年初横空出世时,几乎没有人预料到它会在短短时间内掀起如此巨大的风浪:不仅在技术维度上令行业侧目,更让人瞩目的是它带来的“开源浪潮”。在此之前,全球大语言模型几乎都走闭源路线,动辄耗资几十亿,难以被普通团队或个人复制。DeepSeek却以“低算力、高效率、主动拥抱开源”理念实现了弯道超车,让所有人重新审视中国AI的潜力。
与此同时,随着 DeepSeek 的爆火,中国科技企业乃至整个资本市场的估值体系都在被重构。两大“AI 巨头”——OpenAI 与百度——先后被 DeepSeek“卷”得不得不放低姿态,转向更开放的策略。舆论甚至用 “Sputnik Moment”(斯普特尼克时刻)来形容美国面对 DeepSeek 所产生的危机感。
2. 技术突围:深层优化与“以弱胜强”的训练思路
2.1 打破常规的大模型成本困局
过去的主流大模型研发之所以闭源,根本原因在于成本极其高昂。
- OpenAI GPT-5 为例:据估算,一轮六个月的训练就可能花费约 5 亿美元,更何况项目已持续开发逾 18 个月,投入规模更是惊人。
- 国内多家 AI 企业:若想达到顶级模型水准,仅 GPU 采购就需数十亿元,再加上后续部署、维护,最终成本之高,令人生畏。
然而,DeepSeek 选择了与众不同的道路:一方面有效地减少算力消耗,另一方面侧重后期的强化学习反复打磨。具体做法可以概括为 “低算力 + 高效率 + 强强化”。结论就是——训练成本仅为OpenAI相似模型的十分之一甚至更低,却并未牺牲质量。
2.2 “芯片底层优化 + 强化学习” 双引擎
-
PTX编程攻坚
DeepSeek在技术白皮书中提到,它借助PTX(Parallel Thread Execution)对 GPU 底层模块进行了深度定制。例如,将部分 SM(Streaming Multiprocessor)单元改装为数据传输专用模块,加快多 GPU 间的协同速度,缓解大模型训练最大的瓶颈之一——数据传输与同步。- 优化成果:同样的硬件规模,DeepSeek可提升近 10 倍计算效率,显著降低训练与推理成本。
-
跳过监督微调,直奔强化学习
不同于传统大模型普遍使用的预训练 + 监督微调,再搭配 RLHF(人类反馈强化学习)的方式,DeepSeek选择直接利用类似 GRPO(群体相对策略优化)的强化学习策略,省去了繁琐的人类监督调优阶段。- 形象类比:就像一群学生相互批改作业,每个人在比较中不断进步,而无需老师每时每刻逐项评分。
- 好处:减少人工标注成本、缩短训练周期,并让模型在推理能力上更具弹性和自适应性。
2.3 资源支持与“佛系”商业模式
DeepSeek的母公司——幻方量化——本身是一家资金与算力都极为雄厚的量化私募。
- 6年前便开始布局:建设“萤火一号”超算集群,2022 年囤下万张 A100 显卡,位列首批有能力进行大规模模型训练的国内团队。
- 佛系商业策略:DeepSeek自诞生起,几乎不受营收目标约束,内部研发团队以纯技术驱动为导向。这样的环境让它可以大刀阔斧尝试各种创新,不必像某些初创公司那样 “拉投资—烧钱—赶进度”。
这一背景也决定了DeepSeek的底气:不但开源了模型与论文,还把蒸馏方法、数据集处理策略等核心环节一并公开,让全球开发者都能在其生态中发挥创造力。
3. 引发连锁反应:全球AI格局的裂变与开源潮
3.1 “两大巨头”态度转向:闭源到免费
DeepSeek在 2025 年 1 月 20 日推出 R1 模型后,仅一周就获得 1 亿新增用户,DAU(每日活跃用户)也在短短半个月内攀升至 3000 万,逼近 ChatGPT 的 5323 万。这惊人的增速给全球 AI 赛道带来巨大冲击,“AI巨头”不得不重新审视自身策略。
- OpenAI:1 月 31 日上线免费推理模型 o3-mini
CEO Sam Altman 首次谈及 “开源失误”,宣称将探索新的开源策略。 - 百度:宣布文心一言 4 月 1 日起全面免费
并上线深度搜索功能。在不到一年时间里,百度从“坚持闭源商业化”到“免费开放”,可见形势逆转之快。
3.2 国内外厂商加速拥抱,衍生应用百花齐放
除了 OpenAI 与百度,其他云服务商、电信运营商、手机与车企等纷纷抢滩 DeepSeek 生态。
- 实例:许多手机厂商已预装轻量版 DeepSeek 模型,用于语音助理与多模态交互;汽车厂商则尝试将其嵌入车载系统,实现更灵活的导航、娱乐和安全提示功能。
- 应用爆发:因为 DeepSeek 强调开源与高可扩展性,全球开发者都能以相对低门槛参与插件、行业场景落地,催生了庞大的新应用浪潮。
4. 中国科技的“再评估”:资本市场热情高涨
4.1 恒生科技指数持续走高
DeepSeek 引领的 AI 浪潮让全球投资者重新检视中国科技公司的实力。
- 最新行情:截至 2025 年 2 月 12 日,恒生科技指数ETF 近一周累计上涨 7.67%。次日开盘继续走强,哔哩哔哩-W、网易-S、百度集团-SW、中芯国际等纷纷上涨超 2%。
- 高盛报告:明确指出 DeepSeek 的出现加速了外资加仓中国股票的步伐,并再次重申对 MSCI 中国指数的超配评级,预期全年有望上涨 14%。
4.2 被低估的中国科技迎来“价值回归”
长期以来,中国科技企业在国际资本市场中往往被低估。
- 对比:腾讯、阿里在港股市场的市盈率分别在 19 与 15 左右,远低于美股科技企业普遍动辄 30+ 甚至 50+ 的市盈率。
- 原因:海外投资者缺乏对中国前沿科技突破的足够认知,仍沿用传统互联网框架思维看待这些公司。
而 DeepSeek 的横空出世,让人们意识到:中国企业在 AI 核心技术、底层硬件加速与产业化整合能力上,正在快速赶超甚至部分领域实现反超。这种新的信心也传导到资本市场,引发普遍的“价值重估”。
5. 全球视角:DeepSeek为何被称作“斯普特尼克时刻”?
在美国对 DeepSeek 的报道里,“Sputnik Moment” 频繁出现。这个典故源自 1957 年苏联成功发射人类第一颗人造卫星,引发美国在太空竞赛上的焦虑与大力追赶。
- 历史镜鉴:彼时美国仓促成立 NASA 并举国支援,最终实现了登月等关键突破,从而再度回到太空领域的领先地位。
- 当下映射:DeepSeek 的崛起或许让美国意识到,在 AI 这一至关重要的赛道上,也会出现类似的“落后警报”。未来或许会看到更多政策、资金与人才汇聚到美国本土 AI 领域,以应对来自中国的挑战。
6. 总结:鲶鱼效应下的AI竞赛,机遇与挑战并存
DeepSeek 的爆发式成功,足以称得上为全球 AI 产业注入了一条巨大的“鲶鱼”,搅动了整片水域。
- 对产业:它证明了“开源与低算力高效率的兼容”不仅存在,而且能在短期内迸发出惊人的活力。
- 对资本:中国科技企业正被重新审视,AI 创新力不再是美国和少数巨头专享的“游戏”。
- 对全球格局:OpenAI 与百度这样的龙头都不得不改变既定战略,一场新的开源竞赛或许才刚开始。
正如业内人士所言,“在 AI 竞赛中,垂直化突破、开放式协作与长期主义方能赢得最终胜利。” DeepSeek 的横空出世,正是对这一论断最生动的诠释:它启示更多人,只有尊重技术内核、注重资源配置与开放共享,才能在激烈的全球竞争中脱颖而出。未来数年,我们或将见证更多来自中国本土的 AI 创新,为世界带来新的冲击与惊喜。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 38
38 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)