DeepSeek系列模型大比拼:谁是你的最佳选择?
DeepSeek-V3是一款大语言模型,旨在为内容创作者、企业客服团队以及需要进行知识库信息检索和问答的用户提供强大易用的文本生成解决方案。DeepSeek-R1是基于V3开发的第一代推理模型,包含两个版本:DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Distill-Qwen-32B是一款基于大规模强化学习的蒸馏模型,推理能力卓越,性能超越OpenAI-o1-
在人工智能领域,DeepSeek系列模型凭借其卓越的性能和广泛的应用场景,逐渐成为市场中的热门选择。本文将对DeepSeek系列模型的不同型号进行详细对比,帮助你更好地了解它们的特点与优势,从而选择最适合你的模型。
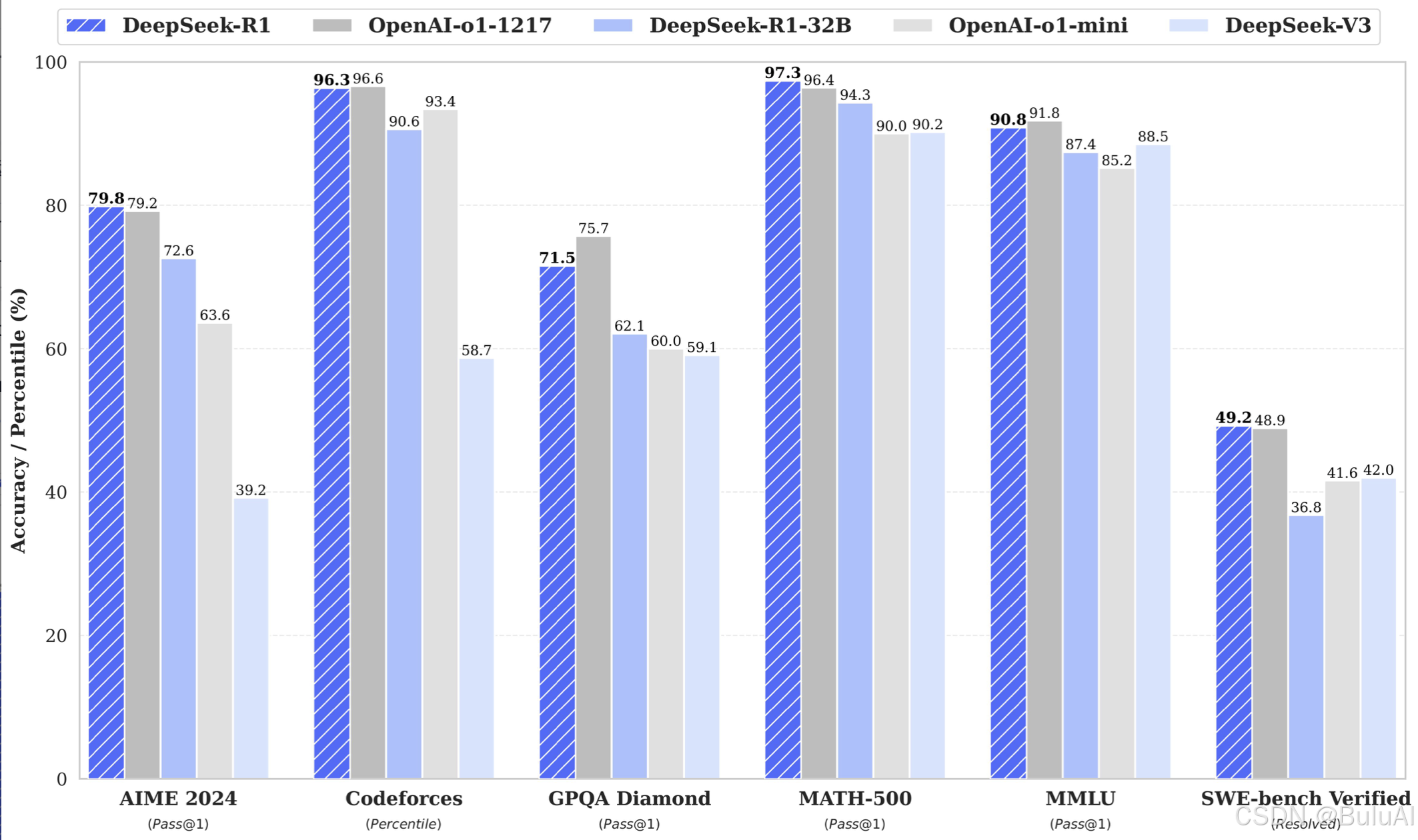
一、DeepSeek-V3
(一)模型概述
DeepSeek-V3是一款大语言模型,旨在为内容创作者、企业客服团队以及需要进行知识库信息检索和问答的用户提供强大易用的文本生成解决方案。
(二)参数规模
DeepSeek-V3拥有6710亿参数,属于较大规模的语言模型。
(三)性能特点
-
文本生成:在文本生成任务中表现出色,能够生成高质量的文本内容,适用于内容创作、智能客服等领域。
-
推理能力:在逻辑推理任务中表现稳定,能够处理复杂的数学问题和逻辑推理任务。
-
计算效率:生成速度提升至60 TPS(每秒生成60个Token),是前代模型的3倍,远超GPT-4o的预估速度(数十TPS)。
(四)应用场景
-
内容创作:适用于撰写文章、创作故事等。
-
智能客服:能够快速生成回复,提升客户服务效率。
-
知识库检索:快速准确地检索知识库信息,提供专业解答。
二、DeepSeek-R1
(一)模型概述
DeepSeek-R1是基于V3开发的第一代推理模型,包含两个版本:DeepSeek-R1-Zero和DeepSeek-R1。
(二)参数规模
-
DeepSeek-R1-Zero:未明确具体参数规模,但属于较大规模的推理模型。
-
DeepSeek-R1:未明确具体参数规模,但属于较大规模的推理模型。
(三)性能特点
-
推理能力:在数学、编程和自然语言推理等任务中表现出色,例如在AIME 2024基准测试中超越了OpenAI O1。
-
计算效率:DeepSeek-R1-Zero通过大规模强化学习(RL)训练,无需监督微调(SFT),展现出强大的推理能力。
(四)应用场景
-
数学与代码生成:适用于数学问题求解和代码生成任务。
-
自然语言处理:能够生成高质量的文本内容,适用于内容创作、智能客服等领域。
三、DeepSeek-R1-Distill-Qwen-32B
(一)模型概述
DeepSeek-R1-Distill-Qwen-32B是一款基于大规模强化学习的蒸馏模型,推理能力卓越,性能超越OpenAI-o1-mini,适用于数学、代码与推理任务。
(二)参数规模
32B参数规模,属于较小的模型版本。
(三)性能特点
-
推理能力:在数学、代码与推理任务中表现出色,能够快速准确地处理复杂任务。
-
计算效率:模型体积小,计算资源需求低,适合在资源有限的环境中部署。
(四)应用场景
-
数学与代码生成:适用于数学问题求解和代码生成任务。
-
自然语言处理:能够生成高质量的文本内容,适用于内容创作、智能客服等领域。
四、DeepSeek-R1-7B、14B、32B
(一)模型概述
这些模型是DeepSeek-R1的不同参数规模版本,分别适用于不同的应用场景和硬件配置。
(二)参数规模
-
7B模型:参数数量较少,属于轻量级版本。
-
14B模型:参数量翻倍,能捕捉到更复杂的语言模式和更细粒度的推理信息。
-
32B模型:参数数量达到数十亿级别,拥有更强的表示能力和更高的精度。
(三)性能特点
-
7B模型:响应速度快、部署成本低、运行效率高,适合实时对话、简单问答及资源受限的场景。
-
14B模型:推理能力和语言理解能力有明显提升,能够较好地兼顾多种复杂任务,如数学题解析、编程任务及领域专用问答。
-
32B模型:在复杂推理、多步逻辑和细节把控方面具有明显优势,适合高性能服务器或云端部署。
(四)应用场景
-
7B模型:适用于实时对话、简单问答及资源受限的场景。
-
14B模型:适用于数学题解析、编程任务及领域专用问答。
-
32B模型:适用于高性能服务器或云端部署,处理复杂任务。
五、DeepSeek-R1-Distill-Llama-8B
(一)模型概述
DeepSeek-R1-Distill-Llama-8B是在Llama架构上进行蒸馏得到的模型。
(二)参数规模
8B参数规模,属于较小的模型版本。
(三)性能特点
-
推理能力:在推理任务上实现了有竞争力的性能,计算效率高,部署容易。
-
计算效率:模型体积小,计算资源需求低,适合在资源有限的环境中部署。
(四)应用场景
-
数学与代码生成:适用于数学问题求解和代码生成任务。
-
自然语言处理:能够生成高质量的文本内容,适用于内容创作、智能客服等领域。
六、总结
DeepSeek系列模型涵盖了从轻量级到大规模的不同型号,每个型号都有其独特的应用场景和优势。用户可以根据具体需求、预算和硬件配置选择合适的模型版本。例如,对于资源有限的环境,7B模型是一个较好的选择;对于需要处理复杂任务的场景,32B模型则能提供更强的性能。
希望本文的对比分析能帮助你更好地了解DeepSeek系列模型,选择最适合你的模型版本。
BuluAI算力平台现已上线,一键部署deepseek!告别等待!再也不用为算力发愁嘞,点击官网了解吧!新用户送50元算力金,快来体验吧!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)