AI小白的第二天:给deepseek添加自己的知识库
初始RAG
概念RAG
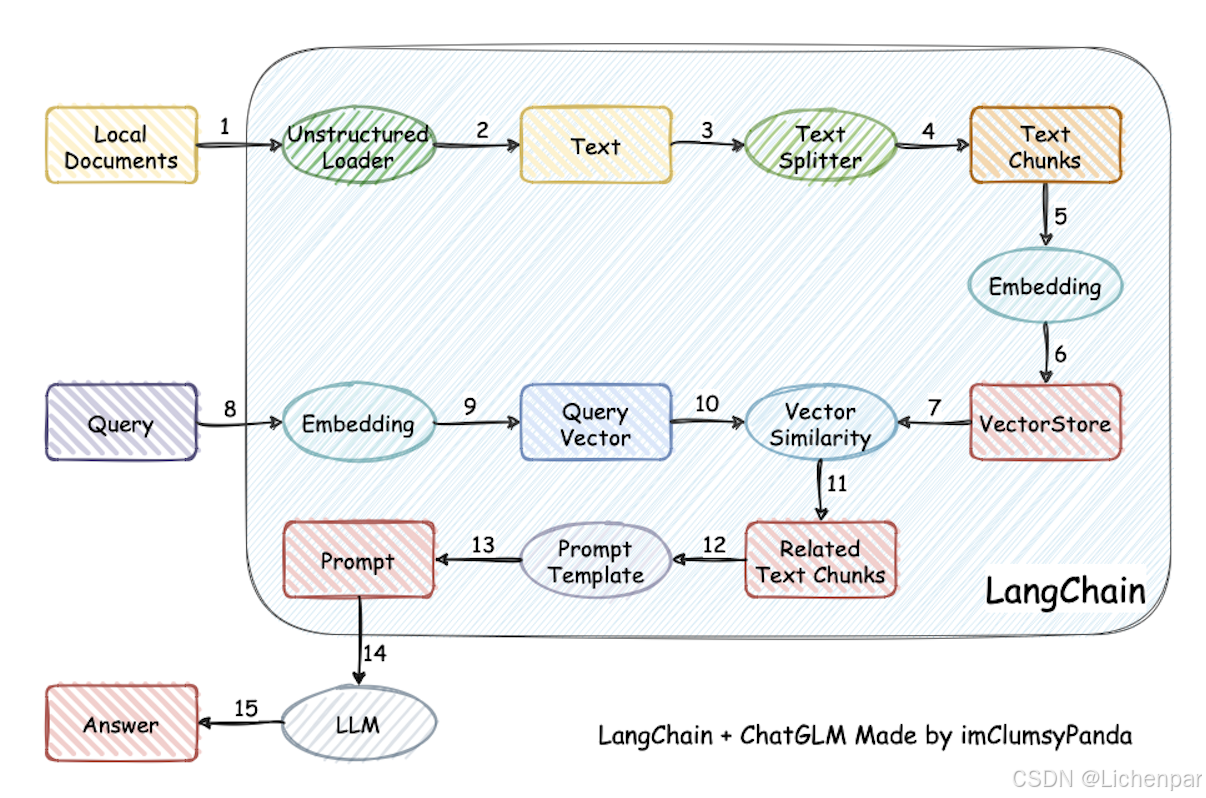
我们第一天搭建的是LLM大语言模型,是基座模型,它可能带有部分知识了,但是它的知识点肯定没有那么包罗万象。如果你想要它更加贴近你的工作或者学习,那么你可能需要一个自己的知识库,让大模型在给你回答之前,从你的知识库再检索有用的信息。后来知道了,这个过程叫RAG。
简单的RAG小实验
第一天的时候,我们通过Ollama安装了DeepSeek-r1:14b模型,并安装了AnythingLLM将对话从命令提示窗口的形式转移到一个像样点的UI界面。这第二天过的着实有些漫长了。主要是我在用过往经验来学习新知识,让我一上来就在研究“向量数据库的部署”、“文本转向量的python代码实现”等。一下涉及到一些深入的知识,导致我有种“学海无涯苦作舟”的感觉。太苦了。。。需要转换一下思路,不然学郁闷了就会没有效率。
其实我想要验证的就是自己运行起来的大模型可以去带有自己知识库的向量数据库查询内容。蓦然回首,AnythingLLM中就已经集成了这样的功能。其实就是AI帮你读论文那种场景。
第一步,创建一个新的工作区
- 创建新工作区 
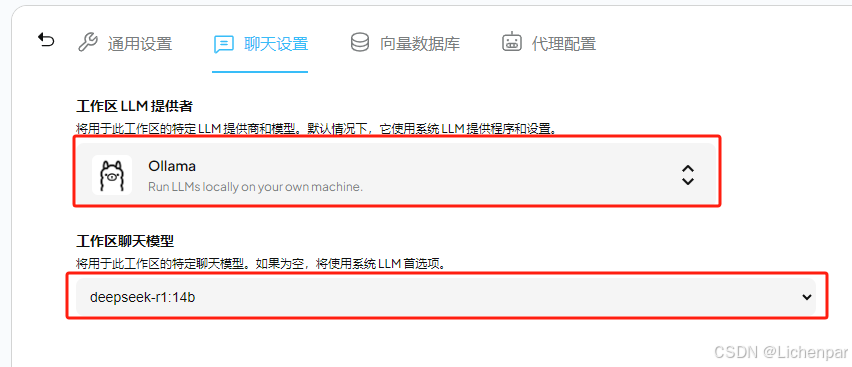
第二步,设置对话模型
- 进入工作区设置页面
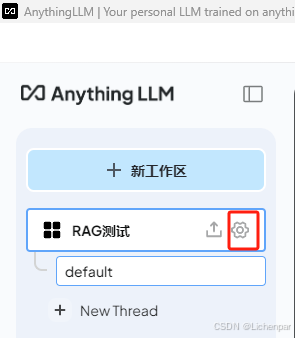
- 设置聊天模型为第一天安装的14b,一定要注意,保存按钮在页面最下方!
第三步,设置嵌入模型
- 进入全局设置
- 可以看到AnythingLLM安装时自带了一个名字为LanceDB的向量数据库
下来选项中也支持接入其他品牌的向量数据库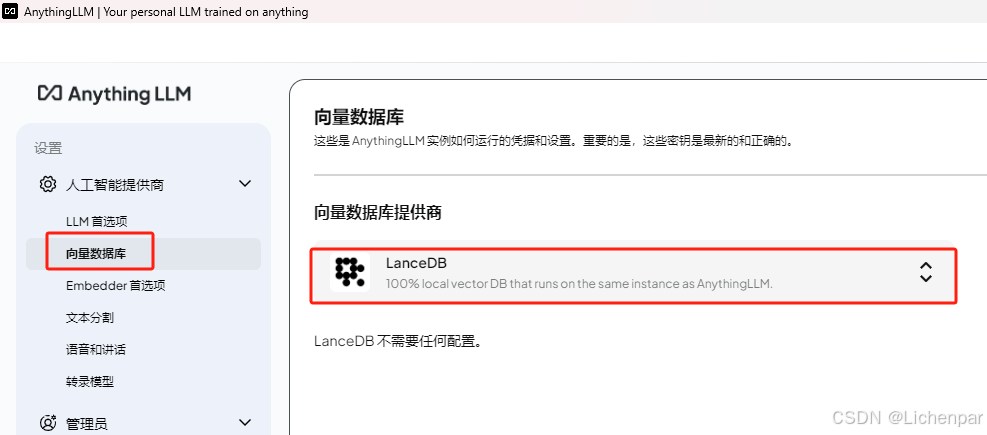
- 设置嵌入模型,别忘了保存更改
之前我被一个问题所困惑,在此步骤自我纠缠了很久。我以为讲自己的知识库文本转换成向量是一个类似加密的过程,而大模型从向量数据库读取向量出来转换成文字又是一个类似解密过程。很多教学视频里面,他们做嵌入的时候都是用的单独的嵌入模型。我担心用一个其他的嵌入模型转换的向量会不能够很好的服务与自己搭建的deepseek-r1模型,所以在查原理,入了深渊。
基于目前我的认知,我认为嵌入模型确实应该也用deepseek-r1,至少是和deepseek-r1中集成的向量化方法保持一致。等我研究透了再做记录。
下面那个1024参数,默认的是8000多,担心电脑性能不够,先调小了。
- 文本分割设置
先随便设一下。
第四步,准备模拟知识库文件
内容如下
lichenpark最喜欢的Dota2英雄是司夜刺客。
最后,考验它!
- 直接问
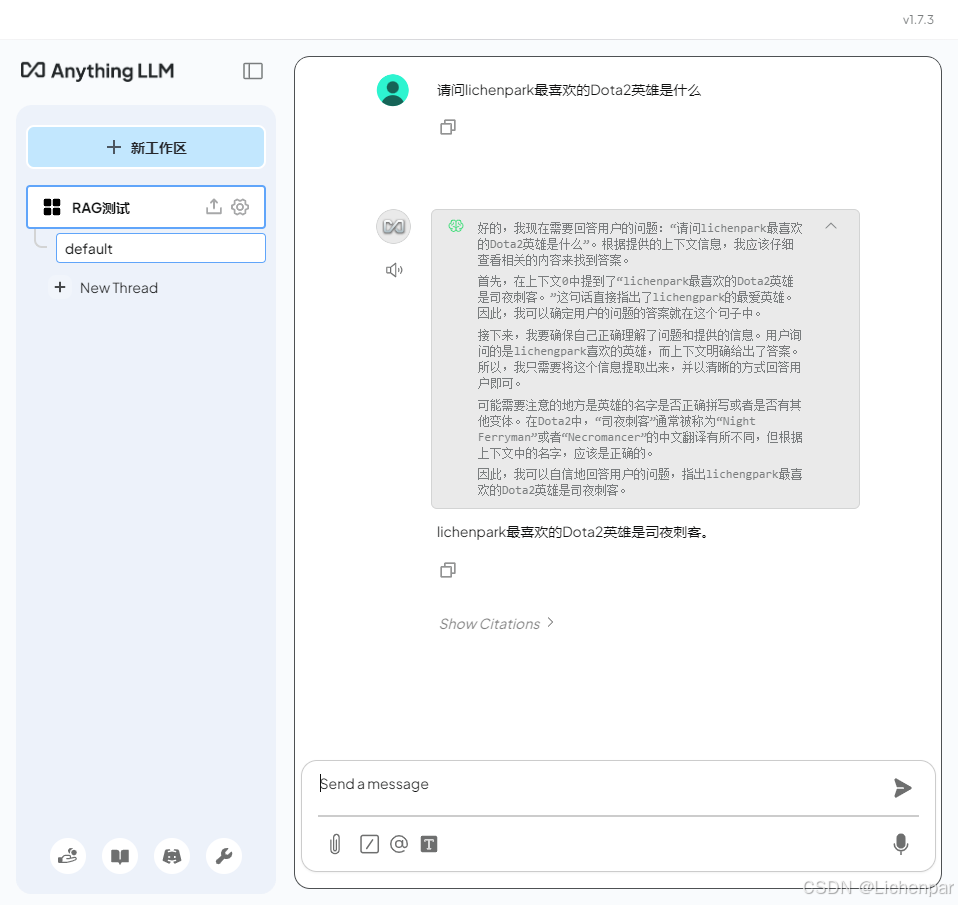
- 新开一个线程再问问关联性的问题
可以看出,在同一个工作区,不同线程是共享向量数据库的。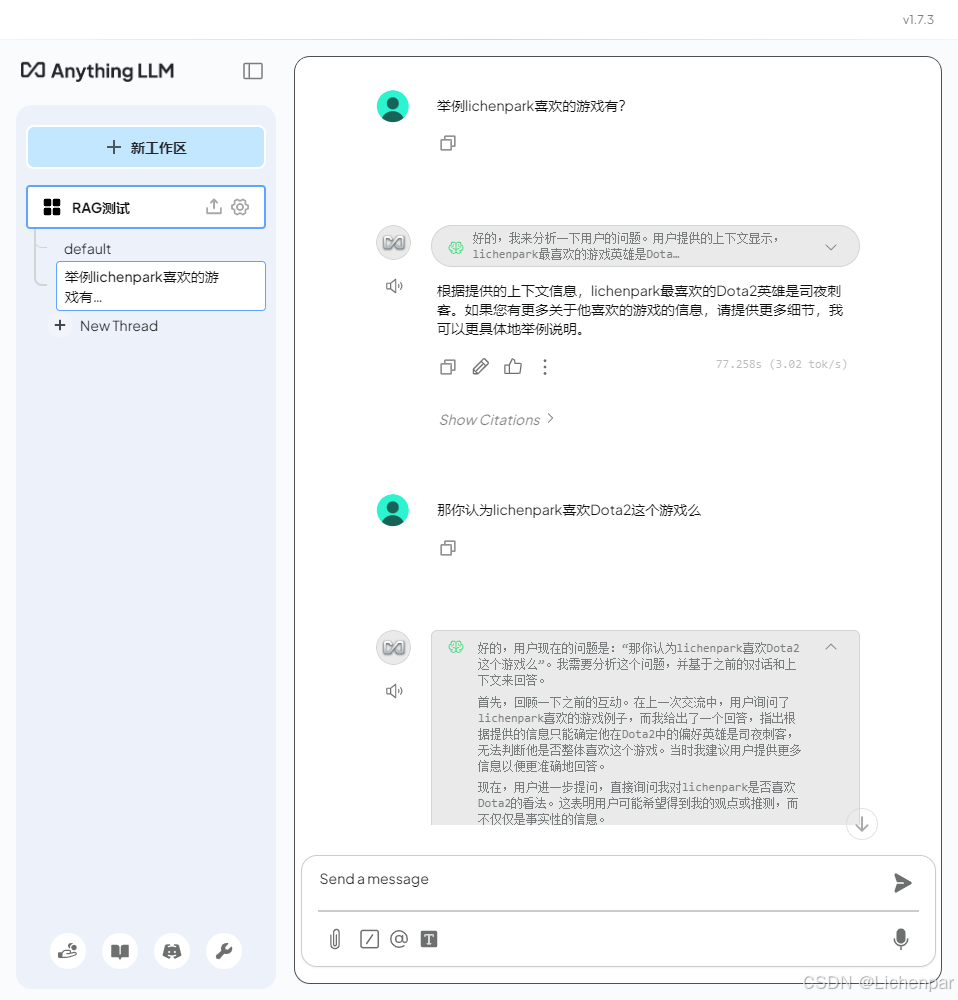
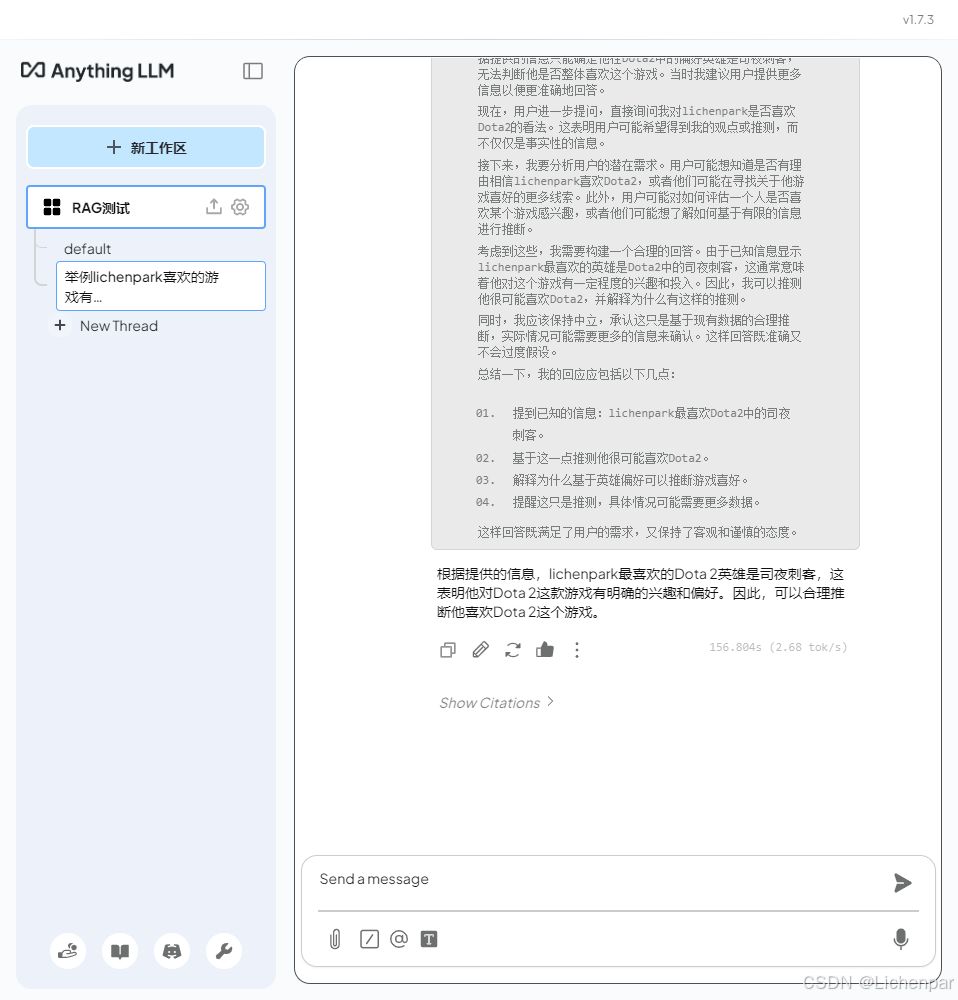
这个时候,看一眼工作区的向量数据库配置,就可以看到向量数量从之前的0变成了1。
总结
基于目前对RAG的理解,已经可以搭建自己的知识库。不过一个文件一个文件的弄,肯定是不行。而且,我们目前是通过拿来主义做的这些事情,如果想要更进一步,肯定是要更加深入学习的。
下一步:1. 如何用自己的知识库来训练模型;
2. 如何将大模型的落地到应用;
3. 深入学习内部原理;
备注:通过不断汲取信息,我了解到,RAG不是训练模型。真正的训练模型应该是微调模型参数。比如我导入了一个很大的知识库,问了很多专业的问题,但是此时大模型给出的回答并不理想,这个时候就涉及到微调模型了。我打算这一块放到深入学习那一步去学习。
下一步,落地一个demo,可以让AI帮你调用其他的接口来实现具体功能,让它变成助手。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)