Unsloth:仅需7GB显存就能训练自己的DeepSeek-R1!
随着 LLM 应用的广泛普及,如何提高模型的推理效率并降低资源消耗成为了技术发展中的一大挑战。Unsloth 通过引入多个强化学习(RL)算法和最新的量化技术,显著提高了 LLM 在推理和微调过程中的性能,并大幅降低了显存消耗。
前言
随着 LLM 应用的广泛普及,如何提高模型的推理效率并降低资源消耗成为了技术发展中的一大挑战。Unsloth 通过引入多个强化学习(RL)算法和最新的量化技术,显著提高了 LLM 在推理和微调过程中的性能,并大幅降低了显存消耗。

DeepSeek 的研究人员在用纯强化学习(RL)训练 R1-Zero 时观察到了一个“灵光一现”的时刻。模型学会了通过重新评估最初的思路来延长思考时间,而无需任何人工指导或预定义指令。
Unsloth 对整个 GRPO 过程进行了增强,使其比 Hugging Face + FA2 减少了 80% 的显存使用。这意味着我们可以使用 7GB 显存,通过Qwen2.5(1.5B)复现了 R1-Zero “灵光一现”的时刻。
💡 主要细节
使用15GB显存,Unsloth 允许我们将任何最多 15B 参数的模型(如Llama 3.1(8B)、Phi-4(14B)、Mistral(7B)或 Qwen2.5(7B))转变为推理模型。
最低要求:仅需 7GB 显存即可在本地训练自己的推理模型。
Tiny-Zero 的团队展示了如何用 Qwen2.5(1.5B)复现 R1-Zero “灵光一现”的时刻——但之前需要2个A100 GPU(160GB显存)。而现在,通过 Unsloth,我们只需一个 7GB 显存的 GPU 即可实现同样的效果。
请注意,这不是对 DeepSeek 的 R1 精炼模型进行微调,也不是使用 R1 的精炼数据进行微调,而是通过 GRPO 将标准模型转换为一个完整的推理模型。
这种魔法可以通过 GRPO 重新创建,GRPO 是一种强化学习(RL)算法,能够高效优化响应,而不需要值函数,这与依赖值函数的近端策略优化(PPO)不同。在我们的笔记本中,我们使用 GRPO 训练一个模型,旨在使其自主开发自我验证和搜索能力——创造一个迷你“灵光一现”时刻。
工作原理:
-
模型生成一组响应。
-
每个响应根据正确性或由某个奖励函数创建的其他度量标准进行评分,而不是使用 LLM 奖励模型。
-
计算该组的平均得分。
-
将每个响应的得分与该组平均得分进行比较。
-
强化模型,使其倾向于选择得分更高的响应。
例如,假设我们希望模型解决以下问题:
1+1 等于多少? >> 思考链/推理过程 >> 答案是2。
2+2 等于多少?>> 思考链/推理过程 >> 答案是4。
最初,必须收集大量数据来填充推理过程。但 GRPO(DeepSeek 使用的算法)或其他 RL 算法可以引导模型自动展示推理能力并生成推理痕迹。相反,我们需要创建良好的奖励函数或验证器。例如,如果答案正确,就给它打 1 分;如果有拼写错误,扣 0.1 分,依此类推!我们可以提供许多奖励过程的函数。
GRPO 在 Unsloth 中的应用
如果你在本地使用 GRPO 与 Unsloth,请确保“pip install diffusers”,因为它是一个依赖项。
等待至少 300 步才能看到奖励的实际增长,请使用最新版本的 vLLM。为了获得良好的结果,你需要训练至少 12 小时(这就是 GRPO 的工作方式),但请记住,这不是强制性的,你可以随时停止。
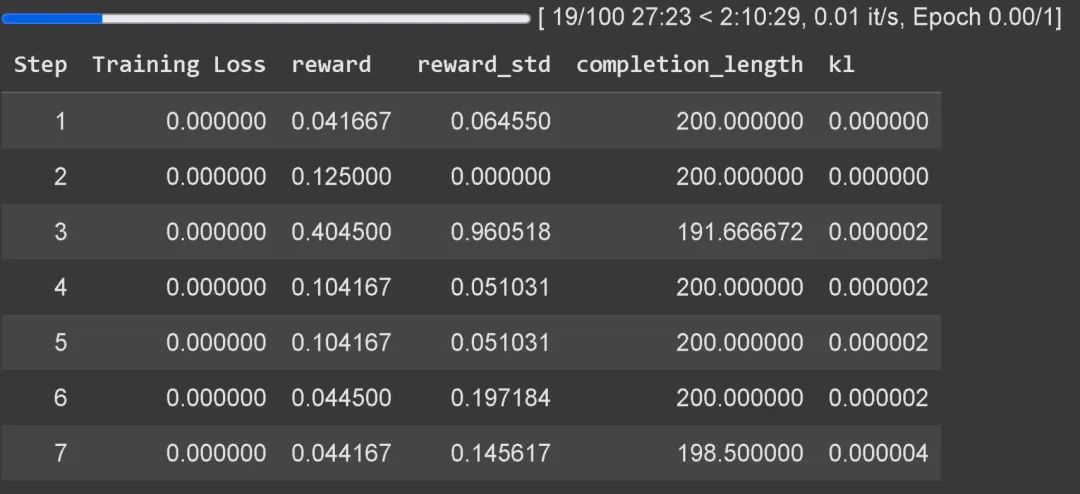
建议将 GRPO 应用于至少 1.5B 参数的模型,以便正确生成思考 token,因为较小的模型可能无法做到。如果你使用的是基础模型,请确保拥有聊天模板。GRPO 的训练损失追踪功能现在已直接内置于 Unsloth 中,无需像 wandb 等外部工具。
除了增加 GRPO 支持外,Unsloth 随后还支持了在线 DPO、PPO 和 RLOO!请查看下图,比较 Unsloth 的在线 DPO 显存消耗与标准 Hugging Face + FA2 的差异。
Unsloth x vLLM
20 倍吞吐量,节省 50% 显存。
现在,你可以直接在微调堆栈中使用 vLLM,这大大提高了吞吐量,并且允许你在同一时间进行微调和推理!在 1x A100 40GB 显卡上,使用 Unsloth 的动态 4bit 量化的 Llama 3.2 3B Instruct,预期吞吐量约为 4000 tokens/s。在 16GB 的Tesla T4(免费 Colab GPU)上,你可以获得约 300 tokens/s 的吞吐量。
Unsloth 去除了加载 vLLM 和 Unsloth 时的双倍内存使用,从而节省了约 5GB 的显存(对于 Llama 3.1 8B)和 3GB 的显存(对于 Llama 3.2 3B)。原本,Unsloth 可以在 1x 48GB GPU 上微调 Llama 3.3 70B Instruct,其中 Llama 3.3 70B 的权重占用了 40GB 的显存。如果不去除双倍内存使用,当加载 Unsloth 和 vLLM 一起使用时,我们将需要至少 80GB 的显存。
但是使用 Unsloth,我们仍然可以在不到 48GB 显存的情况下,同时享受微调和快速推理的好处!要使用快速推理,首先安装 vllm,并通过 fast_inference 实例化 Unsloth:
# pip install unsloth vllm
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-3B-Instruct",
fast_inference = True,
)
model.fast_generate(["Hello!"])
什么是 GRPO?
GRPO(Group Relative Policy Optimization,群体相对策略优化)是一种强化学习(RL)算法,旨在优化模型的响应质量,而不依赖传统的值函数。这种算法通过一种群体相对优化方法,对模型的每个生成的响应进行评分,并根据这些评分来引导模型的学习过程。
具体来说,GRPO 算法的主要特点如下:
-
无值函数:与依赖值函数的强化学习算法(如 PPO)不同,GRPO 不使用值函数来评估状态或行为的质量,而是通过对模型输出的响应进行评分,并基于这些评分来优化模型。
-
响应评分与群体平均:在 GRPO 中,模型生成一组可能的响应,每个响应都会根据正确性或其他预定义的奖励函数进行评分。然后,计算这些响应的平均得分,并将每个响应的得分与群体平均得分进行比较。模型会得到强化,倾向于生成得分较高的响应。
-
自我优化:GRPO 能够帮助模型自主地进行推理和自我验证。例如,模型可以在没有人工干预的情况下,通过不断调整思维过程来提高推理结果的准确性。
-
适用于多种任务:GRPO 不仅可以用于常见的分类任务,也可以应用于更复杂的任务,如生成具有自我验证和推理能力的模型(例如,解答问题时展示推理过程)。
总的来说,GRPO通过强化学习的方式,不仅优化模型的回答,还能改善其推理过程,使模型在没有人工反馈的情况下,能够不断自我改进,从而在处理复杂任务时展现出更强的推理能力。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

DeepSeek全套安装部署资料

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 14
14 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)