deepseek里使用的多头潜在注意力MLA技术浅解
多头潜在注意力(Multi-head Latent Attention, MLA)是一种改进的注意力机制,旨在解决传统多头注意力(Multi-head Attention)在计算效率和内存占用上的瓶颈。,具体的需要看技术报告了。为了降低训练过程中的激活内存activation memory,还对queries进行低秩压缩(虽然这并不能降低KV Cache),其对Q的压缩方式和K、V一致,依然是先降
多头潜在注意力(Multi-head Latent Attention, MLA)是一种改进的注意力机制,旨在解决传统多头注意力(Multi-head Attention)在计算效率和内存占用上的瓶颈。MLA通过引入潜在变量(Latent Variables)对Key-Value(KV)缓存进行压缩和优化,显著提升模型训练和推理的效率,同时保持甚至增强模型性能。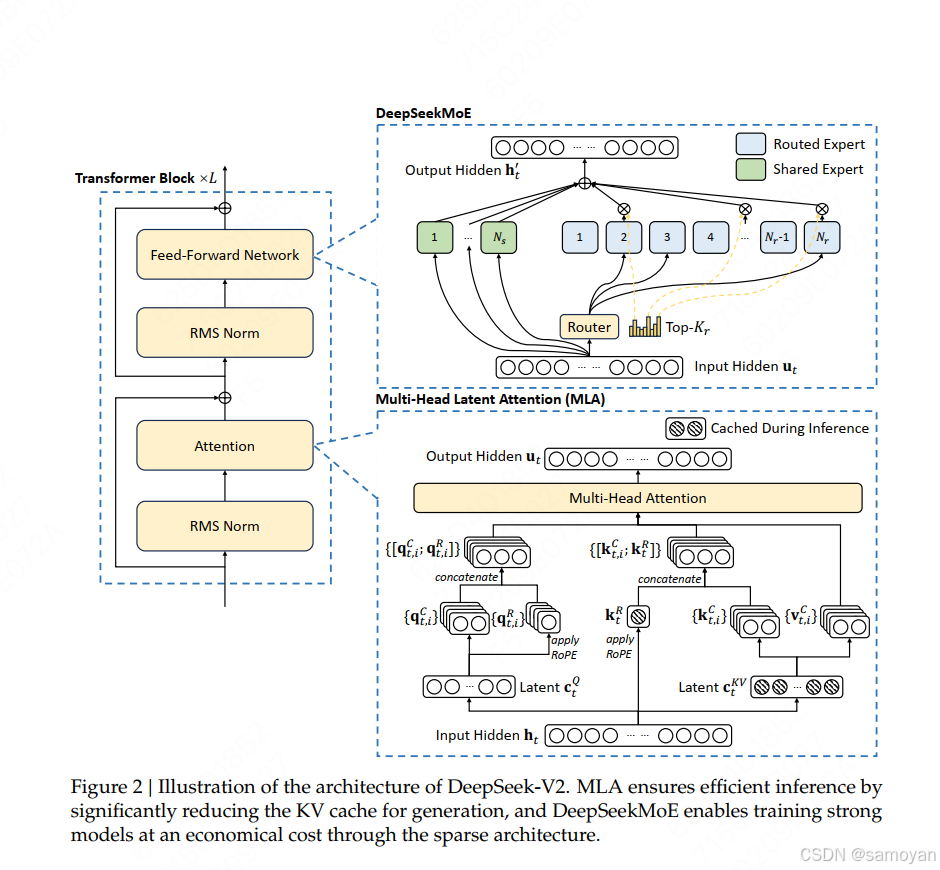
deepseek 中分别对kv 和q 都进行了 MLA,注意的是对k 应用rope 时采用的是hth_tht,具体的需要看技术报告了。为了降低训练过程中的激活内存activation memory,还对queries进行低秩压缩(虽然这并不能降低KV Cache),其对Q的压缩方式和K、V一致,依然是先降维再升维。
以下是MLA技术的解析:
1. 传统多头注意力的瓶颈
传统多头注意力的计算复杂度为 O(n2d)O(n^2 d)O(n2d)(nnn 是序列长度,ddd是特征维度),其核心问题包括:
- 内存开销大:KV缓存需要存储每个头的Key和Value矩阵,占用大量显存。
- 计算冗余:多头并行计算时,不同头之间的部分计算存在重复。
2. MLA的核心思想
MLA通过以下方式优化注意力机制:
- 潜在变量低秩压缩:将高维的Key和Value矩阵投影到低维潜在空间。
- 稀疏化计算:在潜在空间中计算注意力权重,减少矩阵运算的维度。
- 多头并行优化:保持多头的并行性,但通过潜在变量共享减少参数冗余。
3. MLA的技术实现
3.1 潜在空间投影
-
Key-Value压缩:
- 原始Key K∈Rn×dK \in \mathbb{R}^{n \times d}K∈Rn×d 和 Value V∈Rn×dV \in \mathbb{R}^{n \times d}V∈Rn×d 被投影到低维潜在空间:
Klatent=KWK,Vlatent=VWVK_{\text{latent}} = K W_K, \quad V_{\text{latent}} = V W_VKlatent=KWK,Vlatent=VWV
其中 WK,WV∈Rd×kW_K, W_V \in \mathbb{R}^{d \times k}WK,WV∈Rd×k是可学习的投影矩阵,k≪dk \ll dk≪d是潜在空间维度(如 k=d/4k = d/4k=d/4)。
- 原始Key K∈Rn×dK \in \mathbb{R}^{n \times d}K∈Rn×d 和 Value V∈Rn×dV \in \mathbb{R}^{n \times d}V∈Rn×d 被投影到低维潜在空间:
-
潜在空间重构:
- 注意力权重计算后,通过逆投影将结果重构回原始维度:
Attention=Softmax(QKlatentTd)VlatentWO \text{Attention} = \text{Softmax}\left( \frac{Q K_{\text{latent}}^T}{\sqrt{d}} \right) V_{\text{latent}} W_O Attention=Softmax(dQKlatentT)VlatentWO
其中 WO∈Rk×dW_O \in \mathbb{R}^{k \times d}WO∈Rk×d 是输出投影矩阵。
- 注意力权重计算后,通过逆投影将结果重构回原始维度:
3.2 多头潜在注意力
-
共享潜在空间:
- 不同头共享同一潜在空间投影矩阵 $W_K, W_V$,但保留独立的查询(Query)投影矩阵 WQW_QWQ。
- 每个头的计算过程独立,但通过共享潜在空间减少参数数量。
-
计算复杂度降低:
- 原始复杂度:O(n2d⋅h)O(n^2 d \cdot h)O(n2d⋅h)(hhh 为头数)。
- MLA复杂度:O(n2k⋅h+nkd)O(n^2 k \cdot h + n k d)O(n2k⋅h+nkd),显著降低内存和计算需求。
4. MLA的关键优势
4.1 效率提升
- 内存占用减少:
- KV缓存从 2ndh2n d h2ndh 降至 2nkh2n k h2nkh (k≪d(k \ll d(k≪d)。
- 计算加速:
- 矩阵乘法维度降低,适用于长序列和大模型。
4.2 性能保持
- 信息保留:
- 潜在空间保留了原始Key-Value的主要特征,注意力权重仍能捕捉长距离依赖。
- 灵活性:
- 可调整潜在维度 kkk,平衡效率与性能(如 k=d/4k = d/4k=d/4 时,性能接近原始注意力)。
5. 与传统多头注意力的对比
| 特性 | 传统多头注意力 | MLA |
|---|---|---|
| 参数数量 | O(d2h)O(d^2 h)O(d2h) | O(dkh+kd)O(d k h + k d)O(dkh+kd) |
| KV缓存内存 | 2ndh2n d h2ndh | 2nkh2n k h2nkh |
| 计算复杂度 | O(n2dh)O(n^2 d h)O(n2dh) | O(n2kh+nkd)O(n^2 k h + n k d)O(n2kh+nkd) |
| 长序列支持 | 受限(内存瓶颈) | 显著优化 |
| 多任务适应性 | 固定维度 | 可动态调整潜在维度 kkk |
6. 实际应用与效果
- 案例:在DeepSeek-VL2模型中,MLA被用于语言模型部分,结合MoE架构(Mixture-of-Experts),实现了:
- 训练速度提升:相比传统注意力,训练吞吐量提升约 30%。
- 内存占用降低:KV缓存减少 75%(当 k=d/4k = d/4k=d/4时)。
- 性能保持:在视觉-语言任务(如VQA、OCR)中,精度损失小于 1%。
7. 总结
MLA通过引入潜在变量压缩技术,在保持模型性能的同时,显著降低了注意力机制的计算和内存开销。其核心思想是用低维潜在空间近似高维特征,适用于需要高效处理长序列或多模态数据的场景(如大语言模型、视觉-语言模型)。MLA的技术路线为未来大规模模型的优化提供了重要参考。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)