DeepSeek-V3/R1在昇腾硬件上的量化测试指南
可以帮助开发者在昇腾硬件上快速部署DeepSeek-V3/R1量化模型
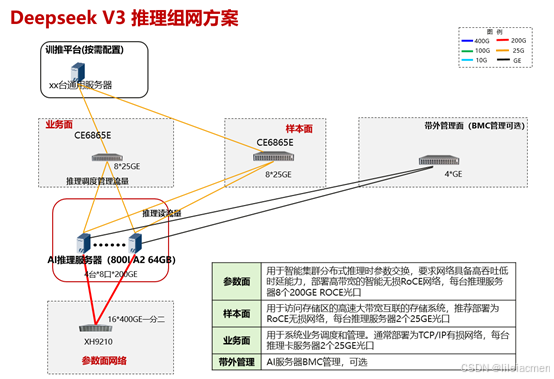
1、硬件要求及组网
部署DeepSeek-V3/R1量化模型至少需要2台Atlas 800I A2(8*64G)服务器。本文以DeepSeek-V3为主进行介绍,DeepSeek-R1与V3的模型结构和参数量一致,部署方式与V3相同。
测试组网如下:
2、模型权重
2.1 FP8原始权重下载
https://huggingface.co/deepseek-ai/DeepSeek-V3/tree/mai
2.2 权重转换(FP8 to BF16)
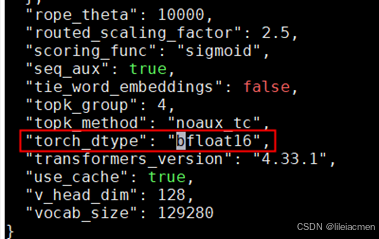
Deepseek-V3原始权重是FB8格式,在昇腾硬件上进行推理部署需要先转换成BF16格式
-
- 2.2.1 NPU侧权重转换
目前npu转换脚本不会自动复制tokenizer等文件
git clone https://modelers.cn/MindIE/deepseekv3.git
cd NPU_inference/
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/DeepSeek-V3 --output-bf16-hf-path /path/to/deepseek-v3-bf16说明:
1)权重FP8->BF16转换预计0.5~1小时,也可以直接下载见2.3章节;
2)/path/to/DeepSeek-V3 表示DeepSeek-V3原始权重路径,/path/to/deepseek-V3-bf16 表示权重转换后的新权重路径;
3)由于模型权重较大,需要确保您的磁盘有足够的空间放下所有权重,例如DeepSeek-V3在转换前权重约为640G左右,在转换后权重约为1.3T左右;
4)推理作业时,也请确保您的设备有足够的空间加载模型权重,并为推理计算预留空间。
2.3 BF16权重下载
也可以通过开源社区直接下载BF16的权重,通过HuggingFace,ModelScope以及Modelers等开源平台进行下载。
下载地址链接:魔搭社区
2.4 NPU侧(BF16 to INT8)权重转换
msit: 统一推理工具链入口,提供客户一体化开发工具,支持一站式调试调优 - Gitee.com,参考该链接,完成量化权重转换,安装对应版本modelslim,下载代码仓
python3 quant_deepseek_w8a8.py --model_path { 浮点权重路径} --save_path {W8A8量化权重路径}
说明:
1)权重BF16->INT8转换预计7~8小时
3、加载MindIE镜像
Step1:请前往昇腾社区/开发资源下载适配deepseekv3的镜像包:mindie:1.0.T71-800I-A2-py311-ubuntu22.04-arm64
说明:昇腾社区提供的官方镜像已具备模型运行所需的基础环境,包括:CANN、FrameworkPTAdapter、MindIE与ATB-Models,可实现模型快速上手推理。
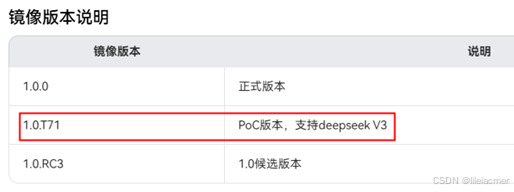
Step2:下载镜像前需要申请权限,耐心等待权限申请通过后,下载对应镜像文件。
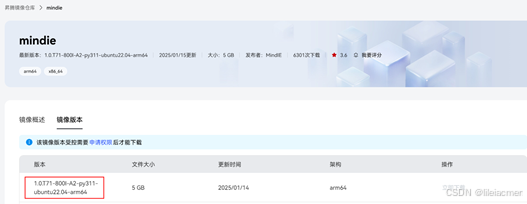
Step3:镜像下载完成后,使用docker load命令将下载好的镜像导入到昇腾主机上。
docker load -i mindie:1.0.T71-800I-A2-py311-ubuntu22.04-arm64Step4:导入成功后,使用docker images查看镜像名称与标签。

4、容器启动
4.1 准备模型
已完成章节2,获取到deepseek BF16格式模型权重。修改模型文件夹属组为1001,执行权限为750:
chown -R 1001:1001 /path-to-weights/deepseekv3
chmod -R 750 /path-to-weights/deepseekv3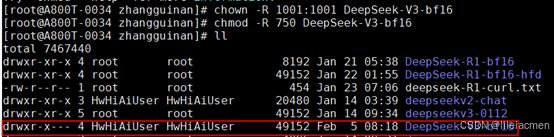
4.2 启动容器
参考以下容器创建命令,执行启动容器(路径、名称等信息根据实际情况修改):
docker run -itd --privileged --name=容器名称 --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /权重路径:/权重路径 \
mindie:1.0.0-XXX-800I-A2-arm64-py3.11(根据加载的镜像名称修改) \
bash4.3 进入容器
进入刚启动的容器:
docker exec -it 容器名称 /bin/bash5、纯模型测试
5.1 前置准备
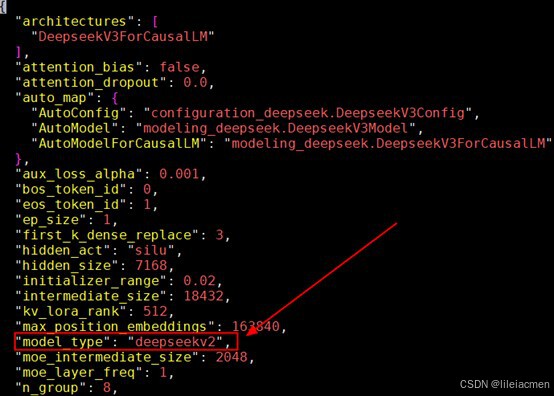
5.1.1 修改权重目录下config.json文件,将 model_type 更改为 deepseekv3或deepseekr1
当前还是沿用deepseekv2代码框架
5.1.2 检查机器之间网络情况(optional)
# 检查物理链接
for i in {0..7}; do hccn_tool -i $i -lldp -g | grep Ifname; done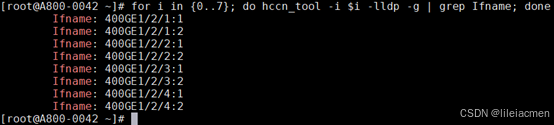
# 检查链接情况
for i in {0..7}; do hccn_tool -i $i -link -g ; done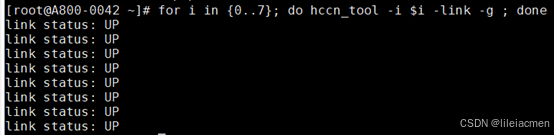
# 检查网络健康情况
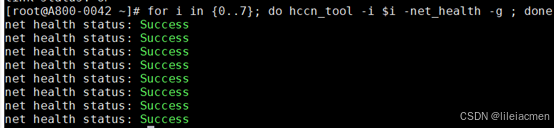
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done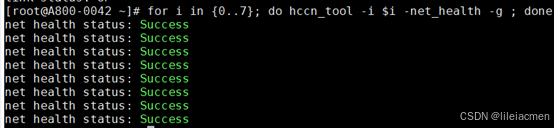
# 查看侦测ip的配置是否正确
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done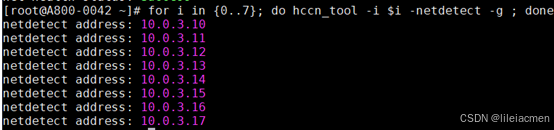
# 查看网关是否配置正确
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done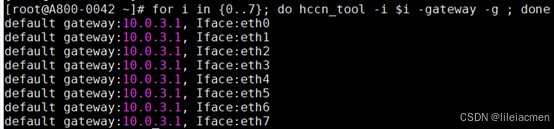
#获取每张卡的ip地址
for i in {0..7};do hccn_tool -i $i -ip -g; done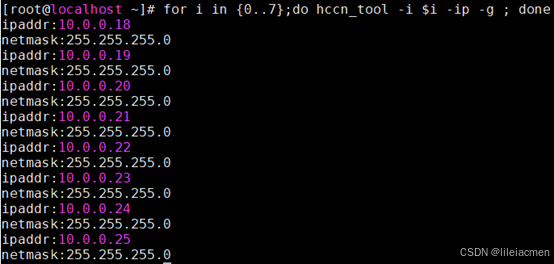
#本机ping其他主机,能ping通表示正常
###主机10.3.14.4的8卡地址ping主机10.3.14.15主机的8卡地址,其他主机ping操作命令类似
for j in {0..7}; do for i in {0..7}; do hccn_tool -i ${j} -ping -g address 10.0.3.1${i} ; done; done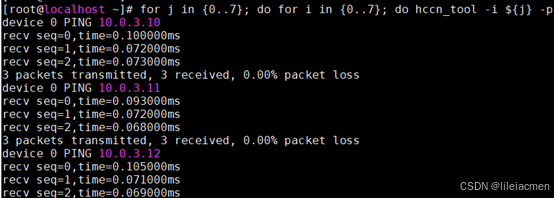
5.1.3 准备rank_table_file.json
使用多机推理时,需要将包含设备ip,服务器ip等信息的json文件地址传递给底层通信算子。参考如下格式,配置rank_table_file.json,附件也给出了本次部署使用的rank_table_file,参考:
{
"server_count": "...", # 总节点数
# server_list中第一个server为主节点
"server_list": [
{
"device": [
{
"device_id": "...", # 当前卡的本机编号,取值范围[0, 本机卡数)
"device_ip": "...", # 当前卡的ip地址,可通过hccn_tool命令获取
"rank_id": "..." # 当前卡的全局编号,取值范围[0, 总卡数)
},
...
],
"server_id": "...", # 当前节点的ip地址
"container_ip": "..." # 容器ip地址(服务化部署时需要),若无特殊配置,则与server_id相同
},
...
],
"status": "completed",
"version": "1.0"
}5.2 800I-A2双机测试
以下测试方案推荐使用TP+EP并行策略,当前EP比纯TP并行策略有优化提升。
800I-A2双机测试DeepSeekV3/R1模型,在进入了容器,前置准备都完成的前提下:
5.2.1 环境变量配置
双机分主节点与副节点,主副节点两台机器都先配置以下环境变量
cd /usr/local/Ascend/atb-models/tests/modeltest/
source /usr/local/Ascend/mindie/set_env.sh
source /usr/local/Ascend/ascend-toolkit/set_env.sh
source /usr/local/Ascend/nnal/atb/set_env.sh
source /usr/local/Ascend/atb-models/set_env.sh
export ASCEND_RT_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
export ATB_LLM_BENCHMARK_ENABLE=1
export ATB_LLM_ENABLE_AUTO_TRANSPOSE=0
export HCCL_OP_EXPANSION_MODE="AIV"
export MASTER_IP=主节点ip地址
export HCCL_CONNECT_TIMEOUT=7200
export HCCL_EXEC_TIMEOUT=05.2.2 设置并行参数
export PARALLEL_PARAMS=[ dp,tp,moe_tp,moe_ep,pp,microbatch_size]说明:
1. 使用pp前需要使能HCCL后端,export ATB_LLM_HCCL_ENABLE=1
2. 使用pp前需要设置ip_address和网卡,export MASTER_IP="ip地址",export NETWORK_ADAPTER="网卡",其中网卡可通过ifconfig查询到ip对应的网卡
3. pp和dp暂不支持混合
双机A2场景推荐TP+EP配置:
export PARALLEL_PARAMS=[ 1,16,1,16,-1,-1]5.2.3 性能测试
1)设置输入输出长度组合的集合
export ALL_IN_OUT_SETS=[[seq_in_1,seq_out_1],...,[seq_in_n,seq_out_n]]例: export ALL_IN_OUT_SETS=[[512,2048],[1024,128],[128,1024],[512,512]]
说明:以[512,2048]为例,512为输入长度,2048为输出长度,可设置不同输入输出长度组合为一个集合串行运行测试,格式为[[seq_in_1,seq_out_1],...,[seq_in_n,seq_out_n]], 中间不接受空格,如[[256,256],[512,512]];值得关注的是,当输入多组时,应按照seq_in + seq_out从大到小的顺序排列, 如[[2048,2048],[1024,1024],[512,512],[256,256]], 否则可能会导致测试性能不准确。
2)设置Batch Size组
export BS_GROUP=[[bs1,bs2,bs3…], [bs1,bs2,bs3…],….]说明: BS_GROUP可设置为单个,多个或多组输入,其中:
1. 单个输入:以数字或者[数字]格式输入,如1或[1]
2. 多个输入:以多个数字逗号隔开或者[多个数字逗号隔开]格式输入,如1,4或[1,4]
3. 多组输入:输入的组数要求与ALL_IN_OUT_SETS相同且一一对应,格式为[[bs1, bs2],...,[bs3,bs4]],如当前ALL_IN_OUT_SETS输入为[[256,256],[512,512]], batch_size输入为[[1,4],[1,8]],则对于[256,256]会测试 1,4 batch,对于[512,512]会测试 1,8 batch
例:以export ALL_IN_OUT_SETS=[[512,2048],[1024,128],[128,1024],[512,512]]为例,有[512,2048]、[1024,128]、[128,1024]、[512,512]共4种组合,
BS_GROUP可设置为[[1,2,4], [1,2,4,8], [1,2,4,8,16], [1,2,4,8,16,24]],其中[1,2,4]对应输入输出为[512,2048]场景分别执行bs=1、bs=2、bs=4的测试,以此类推,[1,2,4,8]对应[1024,128],[1,2,4,8,16]对应[128,1024],[1,2,4,8,16,24]对应[512,512]
3)运行性能测试
主副节点分别先清理残余进程:
pkill -9 python主节点副节点都运行:
bash run.sh pa_[数据类型] performance $ALL_IN_OUT_SETS $BS_GROUP ([prefill_batch_size]) [模型名] [模型权重路径] [ranktable文件路径] [总卡数] [节点数量] [rank_id起始值] $MASTER_IP $PARALLEL_PARAMS说明:
数据类型:根据权重目录下config.json的data_type选择fp16或者bf16,例:pa_fp16
prefill_batch_size:可选参数,设置后会固定Prefill的batch size
模型名:与权重目录下config.json的model_type一致
总卡数:多机卡数之和,800I-A2双机场景为16
节点数量:多机数量,双机为2
rank id起始值:800I-A2双机场景下,主节点为0,副节点为8
例:
主节点:
bash run.sh pa_fp16 performance [[256,256]] 64 1 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 0 90.90.122.1 [1,16,1,16,-1,-1]副节点:
bash run.sh pa_fp16 performance [[256,256]] 64 1 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 8 90.90.122.2 [1,16,1,16,-1,-1]说明:1)权重加载时间取决于磁盘读写速度及共享存储配置,预期5~30分钟,如果超出改时间,建议排查存储读取配置
5.2.4 精度测试
先清理进程:
pkill -9 python主节点副节点都运行:
bash run.sh pa_[数据类型] [数据集] ([Shots]) [Batch Size] [模型名] [模型权重路径] [ranktable文件路径] [总卡数] [节点数量] [rank_id起始值] $MASTER_IP $PARALLEL_PARAMS $PARALLEL_PARAMS说明:
数据类型:根据权重目录下config.json的data_type选择fp16或者bf16,例:pa_fp16
数据集:选择精度测试所采用的数据集,例如:full_CEval或full_GSM8K
Shots: 当测试full_CEval,full_MMLU和full_CMMLU时,shot为测试时使用的shot数,如0或5
Batch Size: 接收单个或多个输入,其中:
1. 单个输入:以数字或者[数字]格式输入,如1或[1]
2. 多个输入:以多个数字逗号隔开或者[多个数字逗号隔开]格式输入,如1,4或[1,4]
模型名:与权重目录下config.json的model_type一致
总卡数:多机卡数之和,800I-A2双机场景为16
节点数量:多机数量,双机为2
rank id起始值:800I-A2双机场景下,主节点为0,副节点为8
例:
CEval:
主节点:
bash run.sh pa_fp16 full_CEval 5 8 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 0 90.90.122.1 [1,16,1,16,-1,-1]副节点:
bash run.sh pa_fp16 full_CEval 5 8 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 8 90.90.122.2 [1,16,1,16,-1,-1]GSM8K:
主节点:
bash run.sh pa_fp16 full_GSM8K 8 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 0 90.90.122.1 [1,16,1,16,-1,-1]副节点:
bash run.sh pa_fp16 full_GSM8K 8 deepseekv3 /Path/to/deepseek_r1_w8a8/ /Path/to/ranktable_2.json 16 2 8 90.90.122.2 [1,16,1,16,-1,-1]6、FAQ
6.1 ranktable中的server id和container ip填写
ranktable中的server id和container ip均填写成主机IP,前提是起容器时需要设置成host模式:docker run --network host <image_name>,含义就是容器的ip地址=主机的ip地址,注意容器开放的端口不要和主机冲突。
"server_id": "10.3.14.15",
"container_ip": "10.3.14.15"
6.2 hccl execute failed
查看日志进行相关问题定位,日志相关环境变量:
#加速库日志相关环境变量
export ATB_LOG_LEVEL=ERROR
export ATB_LOG_TO_STDOUT=1
export ATB_LOG_TO_FILE=1##CANN日志相关环境变量
export ASDOPS_LOG_LEVEL=ERROR
export ASDOPS_LOG_TO_STDOUT=1
export ASDOPS_LOG_TO_FILE=1算子库&加速库&模型库日志保存路径:/root/atb/log
CANN日志保存路径:/root/ascend/log/debug/plog
查看日志发现出现hccl通信失败相关日志内容:


通过HCCN_tool 工具进行连通性检测,发现出现链路down
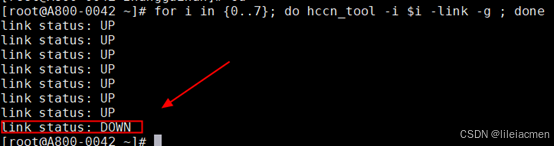
交换机侧也发现物理down
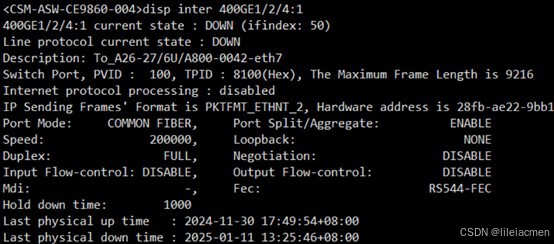
最终发现是光模块故障,更换光模块问题解决。
6.3 out of memory报错
在服务化拉起过程中,若出现out of memory报错,可适当调高NPU_MEMORY_FRACTION环境变量(默认值为0.8),适当调低mindie-service服务化配置文件config.json中maxSeqLen、maxInputTokenLen、maxPrefillBatchSize、maxPrefillTokens、maxBatchSize等参数
export NPU_MEMORY_FRACTION =0.966.4 hccl通信超时报错
可配置以下环境变量,增大超时等待时间。
export HCCL_CONNECT_TIMEOUT=7200
export HCCL_EXEC_TIMEOUT=06.5 权重路径和权限问题
注意保证权重路径是可用的,执行以下命令修改权限,注意是整个父级目录的权限:
chown -R HwHiAiUser:HwHiAiUser /path-to-weights
chmod -R 750 /path-to-weights
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)