超实用!蓝耘智算平台 DeepSeek 编程使用完全指南
蓝耘GPU智算云平台是一个现代化的、基于Kubernetes的云平台,基于行业领先的灵活的基础设施及大规模的GPU 算力资源,为客户提供开放、高性能、高性价比的算力云服务,助力AI客户模型构建、训练和推理的业务全流程,以及教科研客户科研创新加速。旨在为科研工作者、工程师和创新者提供无与伦比的计算解决方案,其 速度可比传统云服务提供商快35倍,成本降低30%。

目录
一、引言
在当今人工智能快速发展的时代,深度学习模型的应用越来越广泛。DeepSeek 作为一款强大的语言模型,在文本生成、知识问答等领域展现出了卓越的性能。而蓝耘智算平台则为我们提供了便捷、高效的计算资源,让我们能够轻松地使用 DeepSeek 进行各种任务。本教程将详细介绍如何在蓝耘智算平台上使用 DeepSeek,从环境搭建到模型推理,再到模型训练,一步步带你深入了解整个过程。
二、蓝耘智算平台简介
蓝耘GPU智算云平台是一个现代化的、基于Kubernetes的云平台,基于行业领先的灵活的基础设施及大规模的GPU 算力资源,为客户提供开放、高性能、高性价比的算力云服务,助力AI客户模型构建、训练和推理的业务全流程,以及教科研客户科研创新加速。旨在为科研工作者、工程师和创新者提供无与伦比的计算解决方案,其 速度可比传统云服务提供商快35倍,成本降低30%。
针对大模型训练场景,蓝耘算力云平台将运行环境、模型、 训练框架等打包到容器中,并通过定制化Kubernetes容器 编排工具进行容器的调度、管理和扩展,可以解决开发环 境设置以及运维和管理问题,让算法工程师能够使用统一 的环境模板进行开发,免除了初期大量的开发环境设置, 以及在新的环境中管理新的算力资源的问题,为用户提供 开箱即用的大模型训练、推理平台。 除此之外,针对大模型训练中遇到的容器进程死机、大规 模分布式训练中GPU驱动丢失、GPU硬件损坏、甚至是计 算节点宕机等难题,都做了定制化设计,为以上难题提供 了自动化调度和强大的自愈能力,实现了更高的开发和训 练效率以及整体资源利用率。
2.1 平台注册与登录
首先,访问蓝耘智算平台的官方网站,点击注册按钮,填写相关信息完成注册。注册成功后,使用用户名和密码登录平台。
2.2 创建计算实例
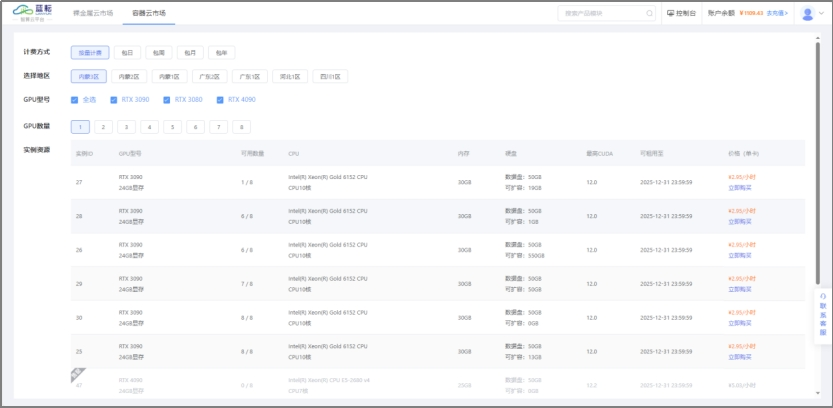
登录平台后,进入控制台,点击 “创建实例” 按钮。在实例创建页面,选择合适的 GPU 资源,如 NVIDIA V100、A100 等,同时选择操作系统镜像,如 Ubuntu 20.04。设置好实例名称、登录密码等信息后,点击 “创建” 按钮,等待实例创建完成。
| 计费项 | 付费方式 | 计费规则 | 计费公式 | 停止计费 |
|---|---|---|---|---|
| 实例付费 | 按量计费(后付费) | 1、开机开始计费,关机结束计费,最低计费0.01元 (关机所有数据会保留) 2、整点扣费一次和关机时扣费一次,扣费金额为扣费周期内的费用,使用时长精确到秒 | 账单费用=(实例定价/60)*使用时长 | 实例关机 |
| 实例付费 | 包年包月(预付费) | 1、租用时一次性付清 2、转换计费方式后,按照按量计费方式收取转换计费方式之前的费用 3、实例续费,按照续费周期进行单独计价收费 | 账单费用=实例定价*购买时长 | 实例到期 |
| 磁盘扩容费用 | 按量计费(后付费) | 1、付费数据盘(如果有)会在当日23:59:59结算当天的费用,每日结算一次,无论实例是否开机,均会计费 2、整点扣费一次和关机时扣费一次,扣费金额为扣费周期内的费用,使用时长精确到秒 | 账单费用=磁盘单价付费数据盘1 日单价:0.01/GB/日 | 缩容至免费容量以下或释放实例 |
| 磁盘扩容费用 | 包年包月(预付费) | 1、租用时一次性付清 2、转换计费方式后,按照按量计费方式收取转换计费方式之前的费用 3、实例续费,按照续费周期进行单独计价收费 | 账单费用=磁盘单价付费数据盘购买时长 年单价:1.83/GB/年 月单价:0.18/GB/月 周单价:0.14/GB/周 | 缩容至免费容量以下或释放实例 |
| 我的云存储费用/自建镜像费用 | 后付费 | 以当日(自然日)使用的最大容量为计费容量,超出免费20GB容量的费用(元/日)=超出容量(GB) × 0.01元/GB/日,扣费时间为次日凌晨扣除当日费用。如有超出免费容量,最低费用0.01元 | 账单费用=磁盘单价付费数据盘1 日单价:0.01/GB/日 | 降至免费容量以下 |
三、DeepSeek 简介
DeepSeek 是字节跳动旗下云雀模型团队基于 Transformer 架构开发的新一代开源大语言模型,以其强大的语言理解与生成能力在自然语言处理领域崭露头角。
在模型架构上,DeepSeek 创新性地优化了 Transformer 架构,大幅提升了模型的学习效率和性能表现。它能够更高效地处理和分析大规模文本数据,从而为各类自然语言处理任务提供坚实的基础。在预训练阶段,DeepSeek 在海量的文本数据上进行了深度训练,涵盖新闻资讯、学术论文、文学作品、社交媒体等丰富多样的数据源,使其具备了广泛的知识储备和强大的语言理解能力。
DeepSeek 在多种自然语言处理任务中都展现出卓越的性能。在文本生成方面,无论是创作故事、撰写文章还是生成对话,它都能生成连贯、富有逻辑且语义准确的文本;在智能问答任务中,DeepSeek 能快速理解问题含义,并从海量知识中提取准确答案;在文本分类、情感分析等任务中,也能凭借其精准的理解能力给出可靠的结果。
此外,DeepSeek 具备高度的可定制性和扩展性。开发者可以根据自身需求对模型进行微调,使其更好地适应特定领域或任务,从而为不同行业的应用提供了极大的便利。凭借这些优势,DeepSeek 在智能客服、内容创作、智能写作辅助、信息检索等领域有着广泛的应用前景,正助力各行业在自然语言处理领域取得新的突破 。
在实际应用中,DeepSeek 与其他大语言模型相比,具有以下独特优势:
技术架构方面
- 混合专家架构优势:采用混合专家(MoE)架构,如 DeepSeek-V3 能通过路由机制按需激活专家处理任务4。相比传统大模型,避免了不必要的计算,减少了计算量和内存消耗4。还可根据输入数据特性和不同任务,动态选择最合适的专家,灵活分配计算资源,优化处理效率4。
- 指令集创新3:采用 PTX 指令集,与 NVIDIA 的 CUDA 不同,PTX 可与 GPU 驱动函数直接交互,开发者能进行更深层次的硬件操作和定制,极大提高运行效率。
性能表现方面
- 推理与计算能力突出4:在编程任务中,DeepSeek-V3 的通过率较高,在数学推理任务中,超过了大部分开源和闭源模型,展示出强大的问题解决能力。
- 多语言理解出色:作为中国团队开发的模型,更符合中文语言习惯和文化背景5。在中文多语言理解测试中得分较高,远超 Llama 3.14。
- 生成速度快4:DeepSeek-V3 支持多单词预测,生成效率提升了 3 倍,从原本每秒 20 个 token 的生成速率提升至 60 个 token,能更迅速高效地处理大规模文本生成任务。
- 多模态处理能力强2:DeepSeek-VL 能够在不丢失语言能力的情况下处理多种类型的数据,包括逻辑图、网页、公式识别、科学文献、自然图像等,还能接受高达 1024x1024 的大尺寸分辨率图片输入,提高了对细节的识别能力。
成本与资源利用方面
- 训练成本低34:如 DeepSeek-V3 的训练成本仅为 557 万美元,远低于 GPT-4 的约 1 亿美元以及 Meta 的 Llama 3.1 的 5 亿美元,在计算资源和硬件资源上的利用效率更高。
- 推理成本优势3:DeepSeek 的使用成本为 0.0012 美元 / 千 token,成本效益优势明显,对于资源有限的企业或研究团队更具吸引力。
开源与生态方面
- 开源与商用授权2:提供开源商用授权政策,允许开发者自行部署、训练、微调和应用模型,为开发者和研究者提供了技术支持。
- 开发者友好5:开源使开发者能够根据自己的需求调整和改进模型,在大规模分布式系统上部署时,能更好地掌控资源和计算效率,有效吸引开发者参与优化和定制,利于形成活跃的开发社区和丰富的应用生态。
四、环境搭建与配置
4.1 连接到计算实例
创建好计算实例后,我们需要使用 SSH 工具连接到实例。在本地终端中,输入以下命令:
ssh username@实例 IP 地址其中,
username是你在创建实例时设置的用户名,实例 IP 地址可以在平台控制台中查看。输入登录密码后,即可成功连接到实例。
4.2 安装必要的系统依赖库
在实例中,我们需要安装一些必要的系统依赖库,以支持后续的深度学习开发。执行以下命令:
sudo apt update
sudo apt install -y build-essential python3-dev python3-pip libjpeg-dev zlib1g-dev4.3 安装 Python 虚拟环境
为了避免不同项目之间的依赖冲突,我们建议使用 Python 虚拟环境。安装
virtualenv工具:
pip3 install virtualenv创建并激活虚拟环境
virtualenv -p python3 deepseek_env
source deepseek_env/bin/activate4.4 安装深度学习框架和 DeepSeek 相关库
在虚拟环境中,安装 PyTorch 和 DeepSeek 相关库。根据你的 GPU 类型和 CUDA 版本选择合适的 PyTorch 版本,例如:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113然后安装 DeepSeek 相关库,这里假设 DeepSeek 提供了 Python SDK:
pip install deepseek-sdk五、模型加载与推理
5.1 本地模型加载
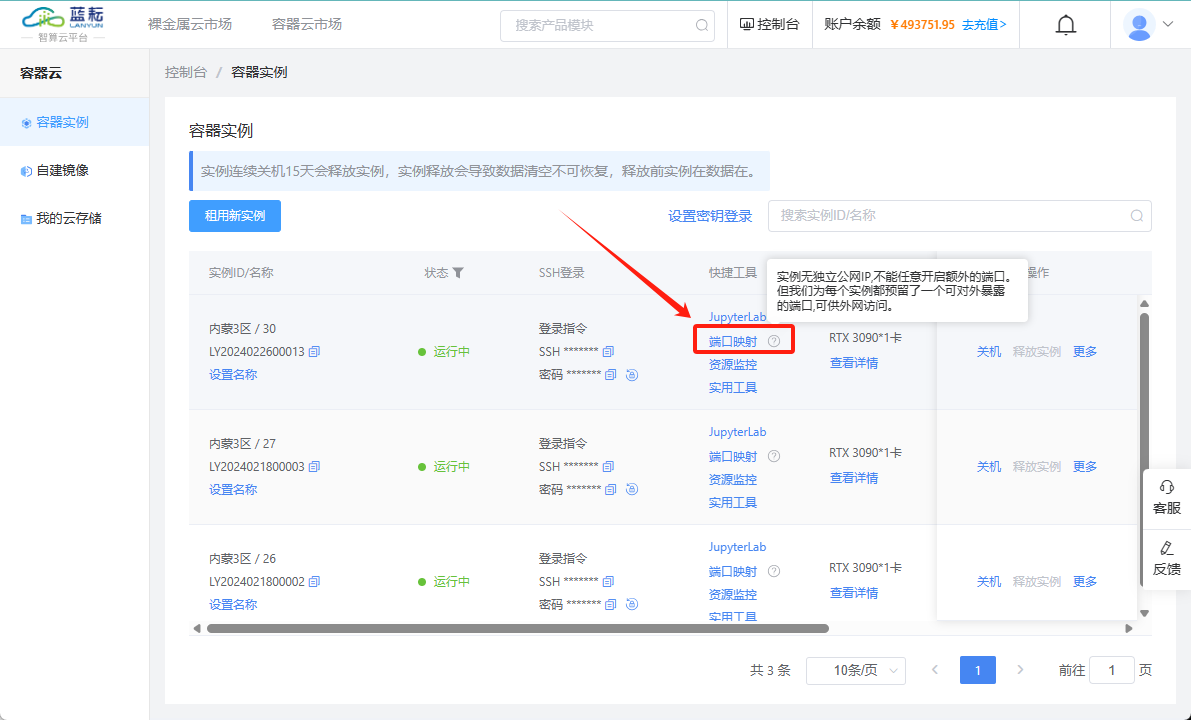
如果我们已经下载了 DeepSeek 的预训练模型文件,可以使用以下代码在 Python 中加载模型:
import torch
from deepseek_model import DeepSeekModel
# 加载模型
model = DeepSeekModel()
model.load_state_dict(torch.load('deepseek_model.pth'))
model.eval()5.2 输入数据预处理
在进行推理之前,需要对输入数据进行预处理。以文本输入为例,我们可以使用分词工具对文本进行分词,并将分词结果转换为模型可以接受的输入格式:
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
def preprocess_text(text):
tokens = word_tokenize(text)
# 这里可以添加更多的预处理步骤,如去除停用词等
return tokens
input_text = "这是一个测试文本"
input_tokens = preprocess_text(input_text)5.3 进行推理
将预处理后的输入数据传入模型进行推理:
import torch
# 将输入转换为模型所需的张量
input_tensor = torch.tensor([input_tokens])
# 进行推理
with torch.no_grad():
output = model(input_tensor)
# 处理输出结果
result = postprocess_output(output)
print(result)5.4 API 调用实现推理
如果蓝耘智算平台提供了 DeepSeek 的 API,我们可以使用以下代码通过 API 进行推理:
import requests
url = "https://蓝耘智算平台的 API 地址"
data = {
"input": "这是一个测试文本"
}
response = requests.post(url, json=data)
result = response.json()
print(result)六、数据处理与准备
6.1 文本数据清洗与预处理
在使用 DeepSeek 进行训练或推理时,需要对文本数据进行清洗和预处理。常见的预处理步骤包括去除特殊字符、转换大小写、分词等。以下是一个简单的文本清洗函数:
import re
def clean_text(text):
# 去除特殊字符
text = re.sub(r'[^\w\s]', '', text)
# 转换为小写
text = text.lower()
return text
input_text = "这是一个包含特殊字符!@# 的文本。"
cleaned_text = clean_text(input_text)6.2 数据加载与批量处理
如果我们有大量的文本数据,需要将其加载到内存中并进行批量处理。可以使用 Python 的
DataLoader类(在 PyTorch 中)来实现数据的批量加载和处理:
from torch.utils.data import Dataset, DataLoader
class TextDataset(Dataset):
def __init__(self, texts, labels):
self.texts = texts
self.labels = labels
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
return text, label
# 示例数据
texts = ["文本 1", "文本 2", "文本 3"]
labels = [0, 1, 0]
dataset = TextDataset(texts, labels)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
for batch_texts, batch_labels in dataloader:
# 处理批量数据
print(batch_texts, batch_labels)七、模型训练与优化
7.1 自定义训练流程
在蓝耘智算平台上,我们可以使用 DeepSeek 模型进行自定义训练。以下是一个简单的训练循环示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型、损失函数和优化器
model = DeepSeekModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}')7.2 超参数调优
超参数调优是提高模型性能的关键步骤。常见的超参数调优方法包括网格搜索、随机搜索、贝叶斯优化等。以下是一个简单的随机搜索示例:
import random
# 定义超参数搜索空间
learning_rates = [0.001, 0.0001, 0.01]
batch_sizes = [16, 32, 64]
best_loss = float('inf')
best_lr = None
best_bs = None
for _ in range(10):
lr = random.choice(learning_rates)
bs = random.choice(batch_sizes)
# 重新创建 DataLoader 和优化器
dataloader = DataLoader(dataset, batch_size=bs, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=lr)
# 训练模型
for epoch in range(5):
for inputs, labels in dataloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if loss.item() < best_loss:
best_loss = loss.item()
best_lr = lr
best_bs = bs
print(f'Best learning rate: {best_lr}, Best batch size: {best_bs}, Best loss: {best_loss}')八、模型部署与应用
8.1 模型部署到蓝耘平台
训练好的模型可以部署到蓝耘智算平台上,以便提供推理服务。平台通常提供了模型部署的工具和接口,我们可以按照平台的文档进行操作。一般步骤包括:
1.保存训练好的模型:
torch.save(model.state_dict(), 'trained_deepseek_model.pth')2.将模型文件上传到平台指定的存储位置。
3.创建推理服务,指定模型文件和推理代码
8.2 实际应用案例:智能问答系统
我们可以使用部署在蓝耘平台上的 DeepSeek 模型构建一个简单的智能问答系统。以下是一个示例代码:
import requests
def ask_question(question):
url = "https://蓝耘智算平台部署的推理服务地址"
data = {
"input": question
}
response = requests.post(url, json=data)
answer = response.json()['answer']
return answer
question = "今天天气怎么样?"
answer = ask_question(question)
print(answer)九、错误处理与性能优化
1.系统盘空间不足
为了确定系统盘空间的使用情况,首先需要识别哪些目录占用了大量空间。如果您不熟悉什么是系统盘,您可以查询帮助文档以获得更多信息。
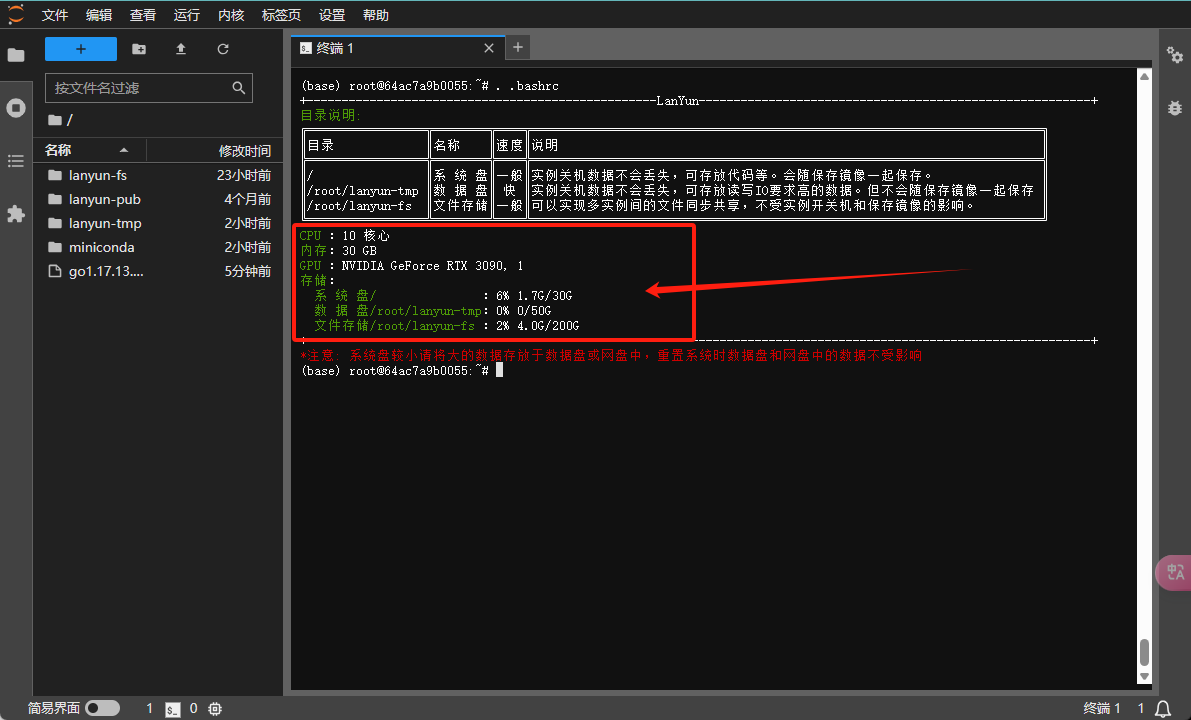
要查看系统盘和数据盘的使用情况,请在终端中执行以下命令:
source ~/.bashrc
该命令将展示各个磁盘分区的总空间、已用空间、剩余空间以及挂载点。
以下列出的目录是您可以安全删除的,它们的移除不会影响系统的正常运行。因此,您可以首先从这些目录开始清理以释放空间。
# 查看conda历史包占用的空间并清除这些包
du -sh /root/miniconda3/pkgs/
rm -rf /root/miniconda3/pkgs/*
# 查看JupyterLab回收站占用的空间并清空回收站
du -sh /root/.local/share/Trash
rm -rf /root/.local/share/Trash/*
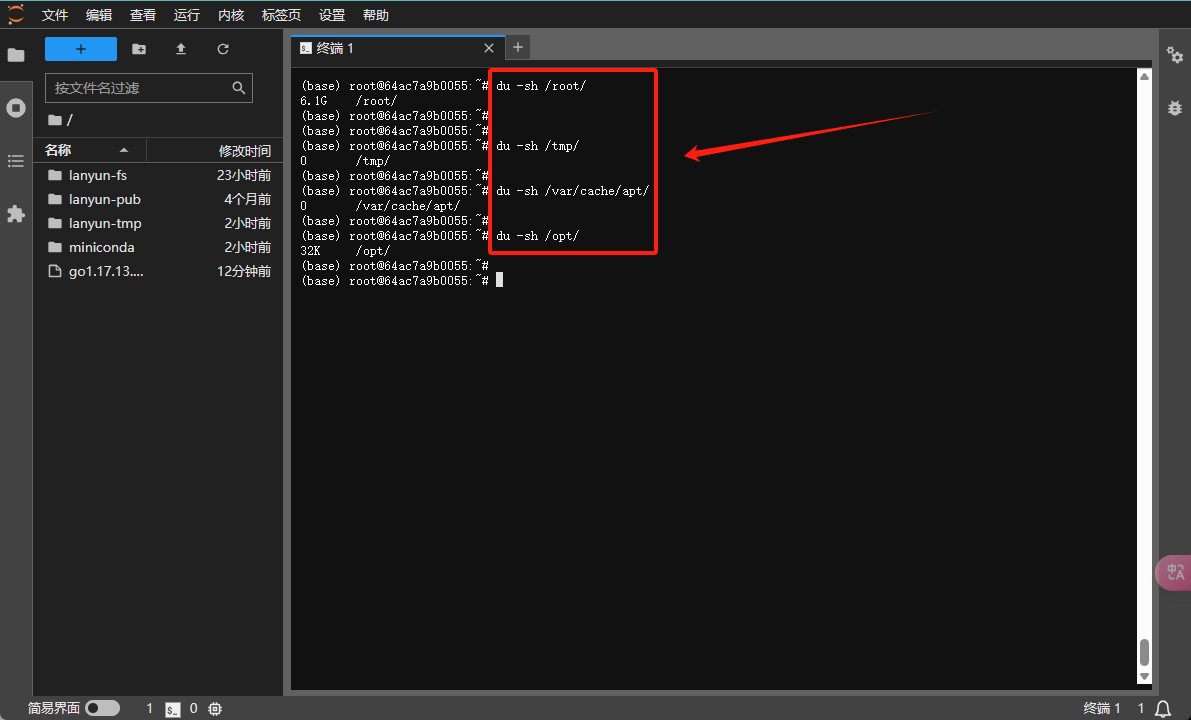
如果这样做仍未能获得足够的空间,请继续审查下面提到的可能占用较大空间的目录,并根据您的实际使用情况谨慎进行清理:
du -sh /tmp/
du -sh /root/.cache
du -sh /var/cache/apt/
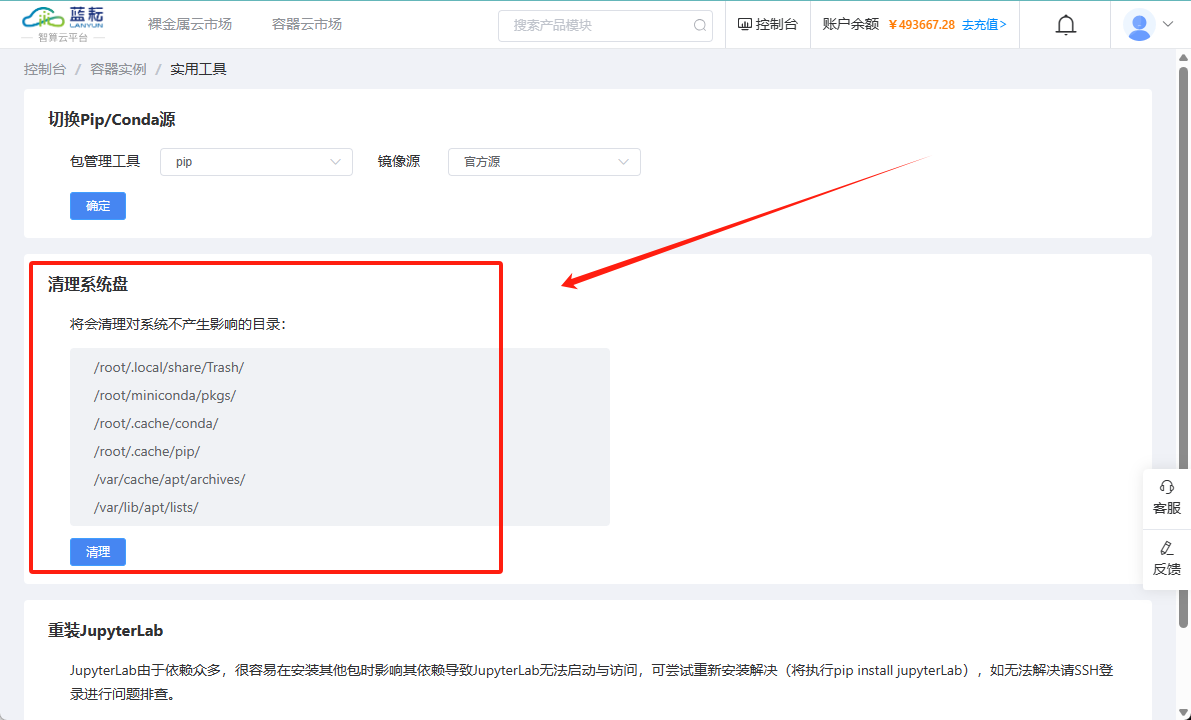
您还可以通过平台提供的"清理系统盘"按钮来快速进行清理操作,这是一个更为便捷的选项。
标准的空间清理流程
开始之前,先检查文件和目录所占用的空间。通常系统根目录(
/)下的文件夹不会消耗大量磁盘空间,所以重点关注您自己创建的目录或文件。
文件大小
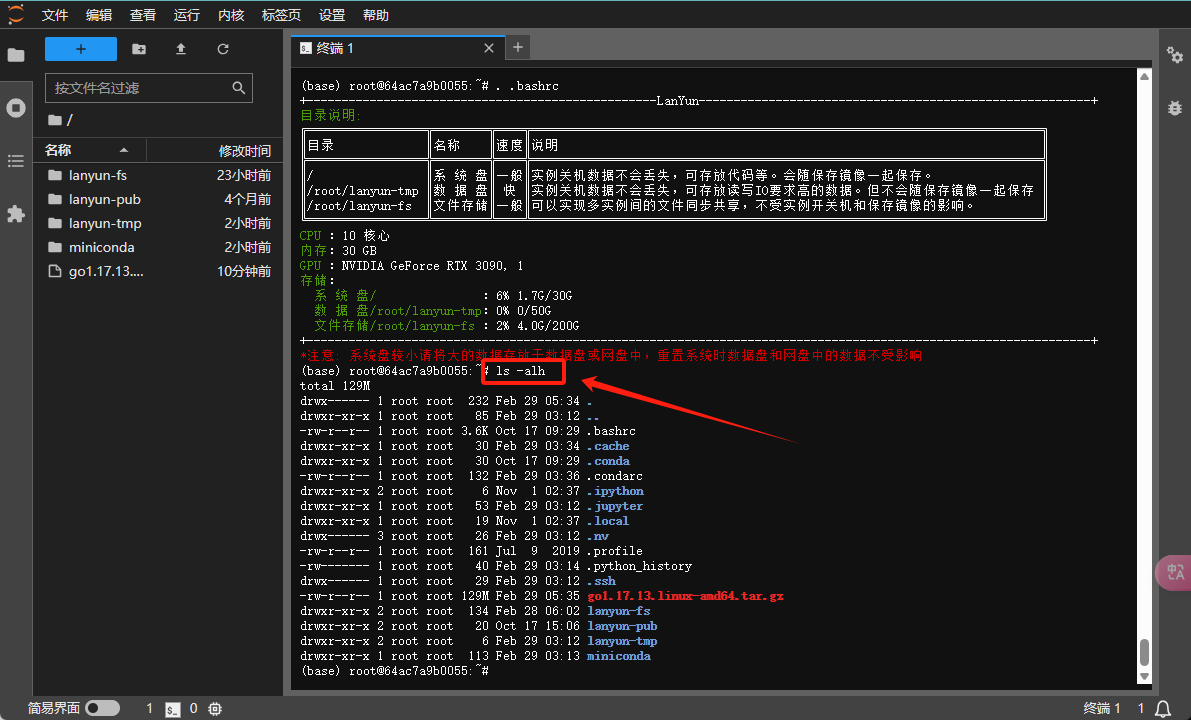
为了查看当前目录下的文件和文件夹大小,您可以运行
ls -alh命令,这样可以列出所有文件和文件夹以及它们的大小。例如,您可以检查.bashrc或.profile等文件占用的空间。需要注意的是,通过ls命令显示的文件夹大小指的是文件夹本身的大小,并不包括其中内容的总大小。
目录大小
要递归统计某个文件夹及其子文件夹下所有文件的总大小,您可以使用
du -sh <directory>命令,其中<directory>代表您想要检查的文件夹名称。
删除
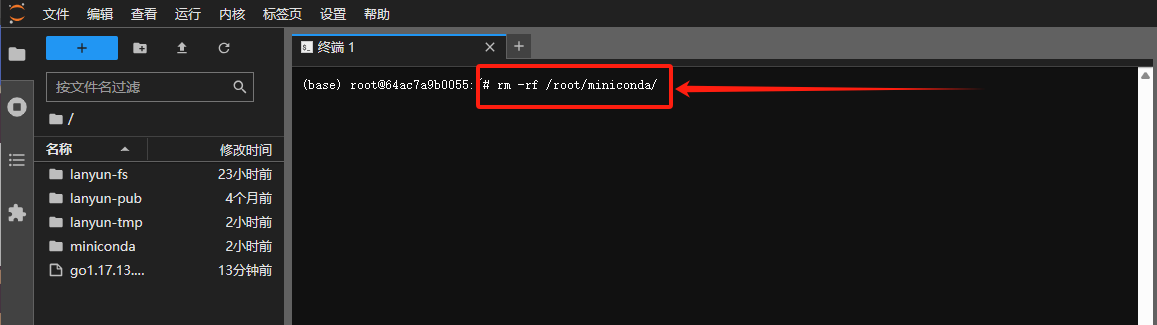
要删除文件或文件夹并释放空间,您可以执行
rm -rf <path>命令,其中<path>是您希望删除的文件或文件夹的路径。请谨慎使用此命令,因为它会永久移除指定的内容,且无法恢复
特定不影响系统盘空间的文件夹
以下目录由系统特别设定,它们不会占用系统盘的空间:
lanyun-pub
lanyun-fs
lanyun-tmp
2.希望彻底清楚内容怎么做
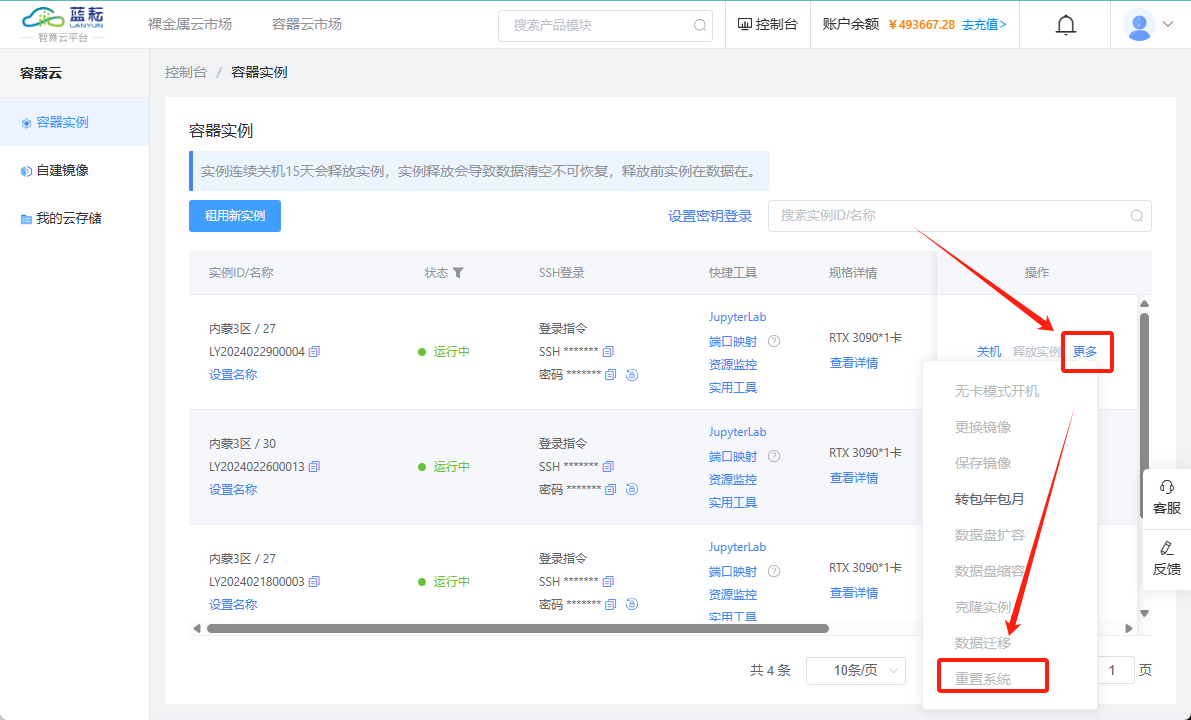
如果您确定不再需要存储的数据,并希望彻底清理所有内容,怎么办呢?可以在实例的"更多"操作菜单中选择"重置系统"功能。执行这个操作将会抹除系统盘上的所有数据。请确保您已备份任何重要数据,因为此操作不可逆转。
3.注意事项
在蓝耘智算平台上使用 DeepSeek 时,以下这些注意事项值得关注:
环境搭建方面
1. 系统与依赖兼容性
- 操作系统:确保选择与 DeepSeek 及相关依赖库兼容的操作系统版本。比如 DeepSeek 某些版本可能对 Ubuntu 20.04 支持更好,使用其他系统可能会出现未知问题。
- CUDA 与驱动:若使用 GPU 加速,要严格匹配 CUDA 版本和 GPU 驱动。不同版本的 PyTorch(若 DeepSeek 基于 PyTorch)对 CUDA 版本有特定要求,不匹配可能导致 GPU 无法正常使用,甚至程序崩溃。
2. 虚拟环境管理
- 环境隔离:为每个使用 DeepSeek 的项目创建独立的虚拟环境,防止不同项目的依赖冲突。在激活虚拟环境后,再进行 DeepSeek 及相关库的安装。
- 依赖记录:及时记录虚拟环境中的依赖库及其版本,可使用
pip freeze > requirements.txt命令,方便后续环境复现和问题排查。
模型加载与推理方面
1. 模型文件完整性
- 下载校验:从官方或可靠渠道下载 DeepSeek 模型文件,并进行完整性校验,如检查文件大小、哈希值等,避免因文件损坏导致模型加载失败。
- 存储安全:将模型文件妥善存储在蓝耘智算平台的可靠存储位置,防止文件丢失或损坏。
2. 推理资源分配
- 内存管理:在进行推理时,注意监控内存使用情况。若输入数据量过大或模型参数较多,可能会导致内存溢出。可适当调整批量大小或采用分批次推理的方式。
- GPU 利用率:通过平台提供的监控工具,观察 GPU 的利用率。若利用率过低,可能是代码中存在性能瓶颈,需要进行优化;若过高,可能会影响系统稳定性,可考虑降低推理负载。
数据处理与准备方面
1. 数据质量与清洗
- 数据标注准确性:如果使用有标注的数据进行训练或微调,要确保标注的准确性。错误的标注会导致模型学习到错误的信息,影响模型性能。
- 数据去重与归一化:对输入数据进行去重处理,避免重复数据对模型训练产生干扰。同时,进行必要的归一化操作,如文本数据的大小写统一、去除特殊字符等。
2. 数据隐私与合规
- 数据来源合法性:确保使用的数据来源合法合规,避免使用未经授权的数据。在处理敏感数据时,要遵循相关的法律法规和隐私政策。
- 数据加密与存储:对于敏感数据,在传输和存储过程中要进行加密处理,保护数据安全。
模型训练方面
1. 超参数调整
- 谨慎调整:超参数对模型训练效果影响较大,如学习率、批量大小等。在调整超参数时,要进行充分的实验和分析,避免盲目调整导致模型性能下降。
- 记录实验结果:记录不同超参数组合下的训练结果,包括损失值、准确率等指标,以便后续对比和选择最优参数。
2. 训练中断处理
- 定期保存模型:在训练过程中,定期保存模型的中间状态,如每训练一定的轮数保存一次。若训练过程中出现中断,可从最近保存的模型继续训练,避免数据丢失和重复训练。
- 异常处理机制:在训练代码中添加异常处理机制,如捕获硬件故障、网络中断等异常情况,并进行相应的处理,保证训练的稳定性。
成本与资源管理方面
1. 资源使用监控
- 实时监控:通过蓝耘智算平台提供的监控工具,实时监控计算资源的使用情况,如 CPU、GPU、内存、网络带宽等。根据监控结果合理调整资源配置,避免资源浪费。
- 成本预估:在进行大规模训练或长时间推理任务前,预估所需的资源成本。可以参考平台的计费标准,选择合适的资源规格和使用时长。
2. 任务调度优化
- 错峰使用:尽量选择在平台资源空闲时段进行大规模训练任务,以获得更好的性能和更低的成本。
- 资源共享:如果多个任务可以共享计算资源,可考虑进行合理的任务调度,提高资源利用率。
十、总结
通过本教程,我们详细介绍了如何在蓝耘智算平台上使用 DeepSeek 进行环境搭建、模型加载与推理、数据处理与准备、模型训练与优化、模型部署与应用等操作。希望本教程能够帮助你快速上手,利用蓝耘智算平台和 DeepSeek 开展高效的人工智能开发工作。在实际应用中,你可以根据具体需求对代码进行修改和扩展,不断探索和创新。
注册链接:https://cloud.lanyun.net//#/registerPage?promoterCode=0131

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 132
132 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)