DeepSeek 本地部署(LM Studio)
DeepSeek官方使用: 推理速度快,可联网,推理的结果优质。在较多用户的情况下,会出现服务器繁忙。API 调用: 能够正常使用,在平常的时候很少出现无法推理的情况,缺点是无法联网,与官方推理出的结果有差距,有Token限制本地部署: 能够正常使用,取决于配置,解决了无法使用的情况但是一般用户推理速度会很慢。建议: 在官网能用的情况下用官网,然后再尝试使用API 调用 和 本地部署tips: 前
1. 安装LM Studio
LM Studio 官网: LM Studio - Discover, download, and run local LLMs
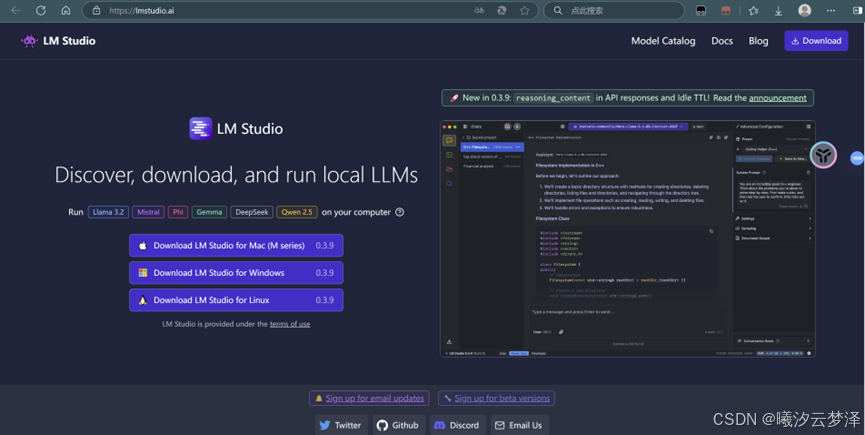
选择对应平台进行下载,安装过程十分简单,无需介绍。
2. 下载DeepSeek-R1 模型
打开LM Studio, 可以更改某些设置
更改语言: 右下角齿轮 - Language, 选择对应语言, 默认英文版,中文汉化据说不太理想,英文版用着也不碍事。
勾选代理: 右下角齿轮 – General - Use LM Studio's Hugging Face Proxy, 不勾选的情况下,可以搜索到的模型都是官方提供的,选择较少。
搜索并下载模型
右侧点击放大镜(Discover), 在搜索栏中输入 DeepSeek R1, 如果没有勾选代理,将不会出现黄色图标的模型选项。
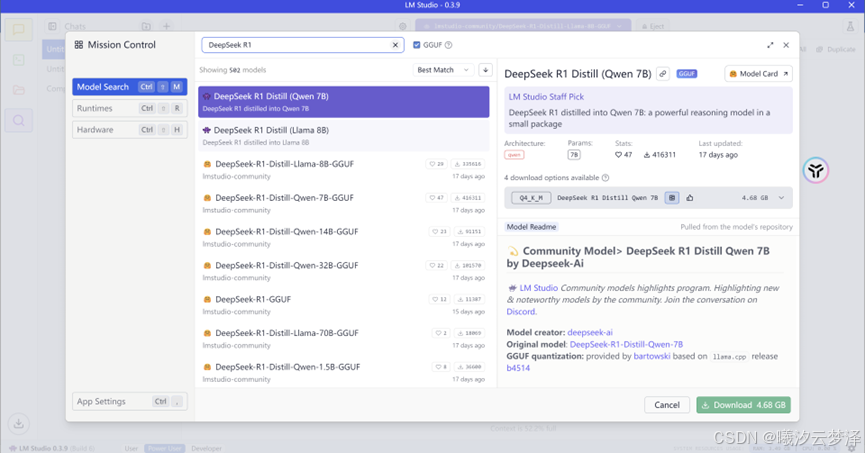
根据个人的电脑硬件配置选择不同的模型, 模型后面的参数 如7B,8B,代表模型的完整度,数字越大,需求的硬件配置越高,其中671b为完整模型,一般个人无法支持使用,其他的都是蒸馏模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本和不同使用场景,越好的模型参数规模、模型容量、准确性会越好,但是推理的时间将会增加,依照个人选择。
Download处的大小代表模型文件大小,这里推荐没有独显的用户选择1.5B模型,配置较低的用户尽量选择7B 或者 8B模型下载。
下载完成后, 在上面选择对应的模型

在选择模型的时候可以更改运行参数
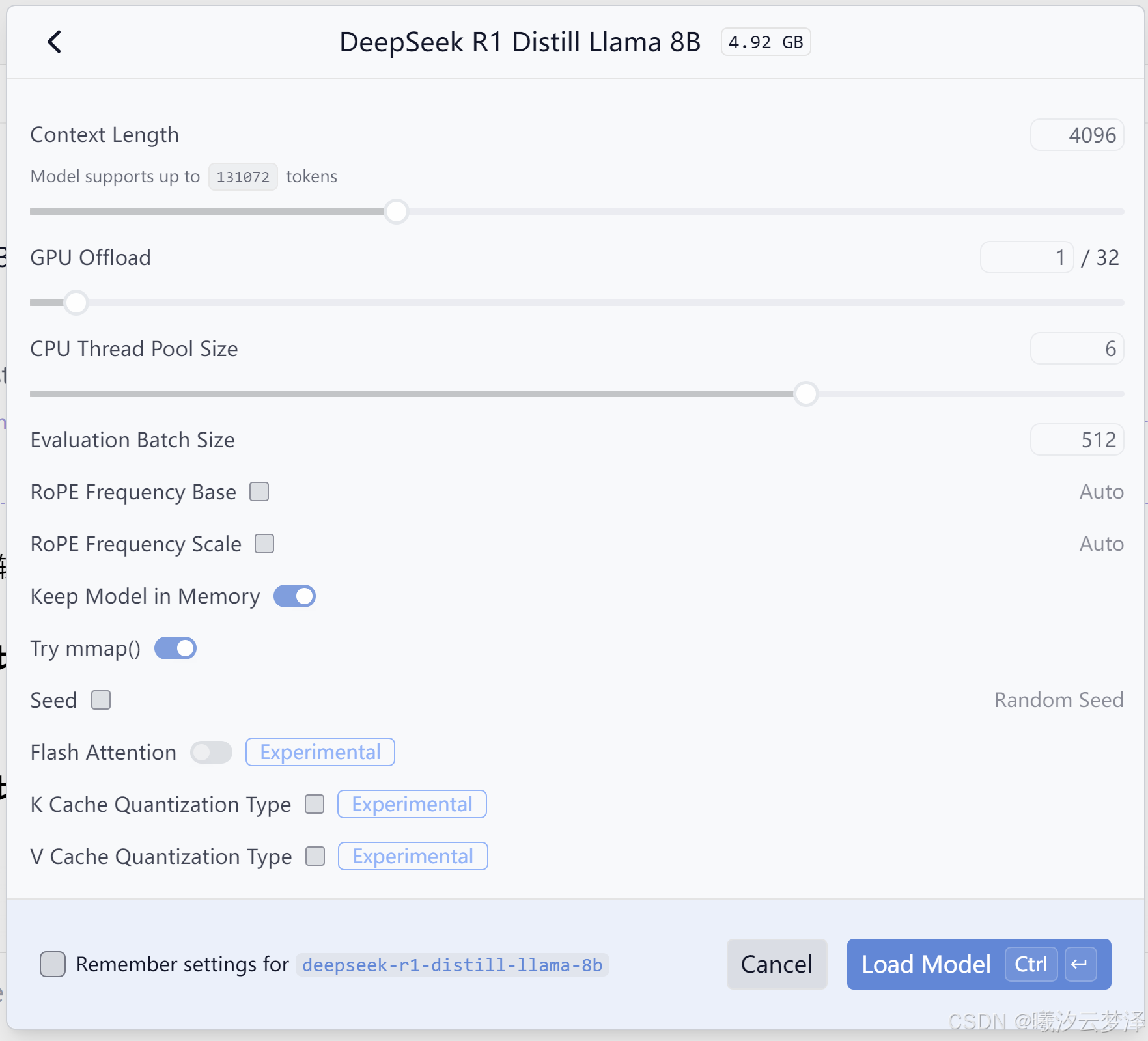
根据自身配置调整 上下文长度,GPU 和CPU的使用, 将GPU 设为0将会使用纯CPU进行推理,推理速度会降低很多。
3. 测试使用
这里对下载的两个模型 1.5B 和 8B模型进行提问,配置的上下文、GPU、和CPU差不多,测试一下深度思考和推理速度。
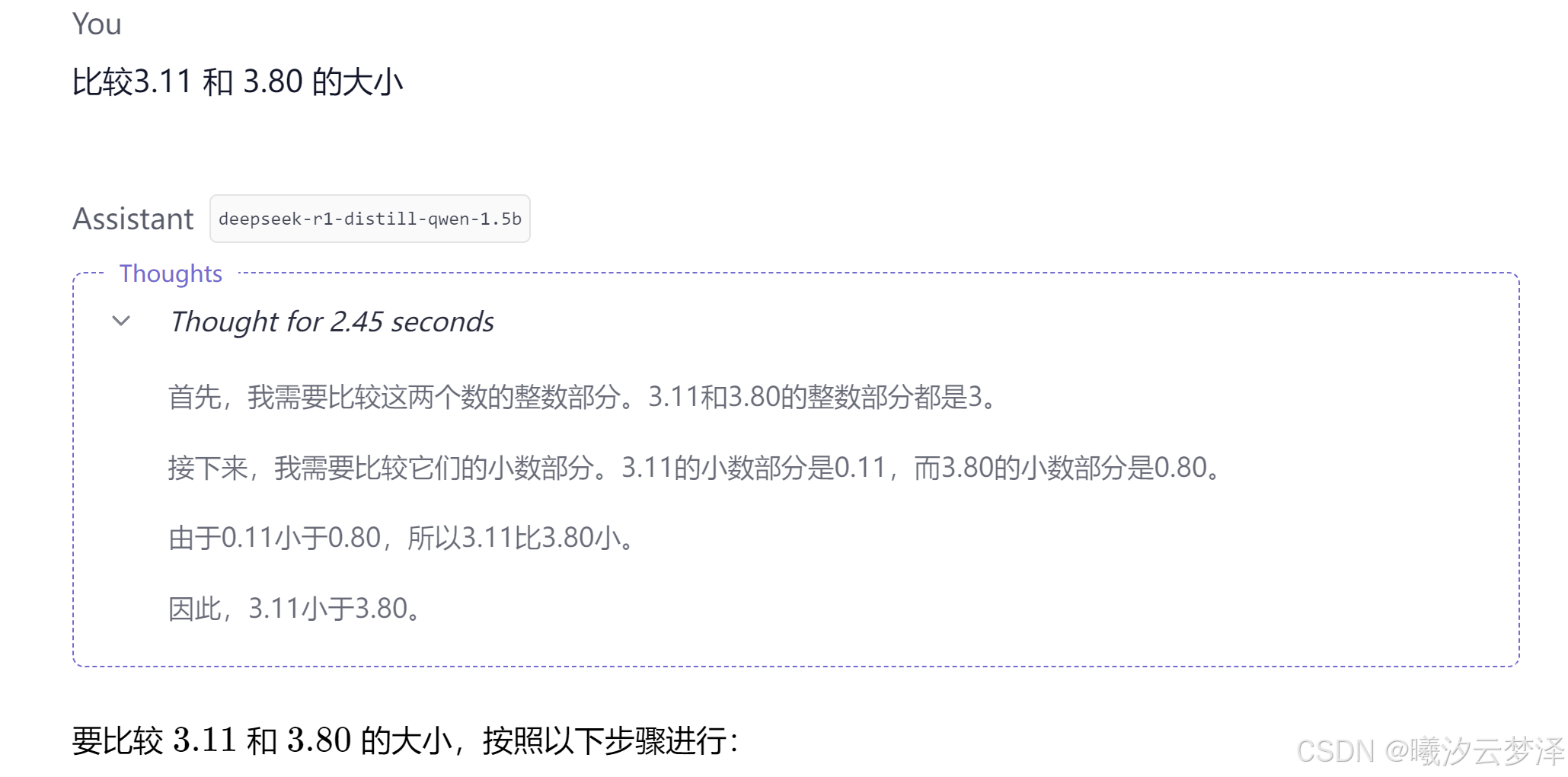
1.5B 测试结果
8B测试结果
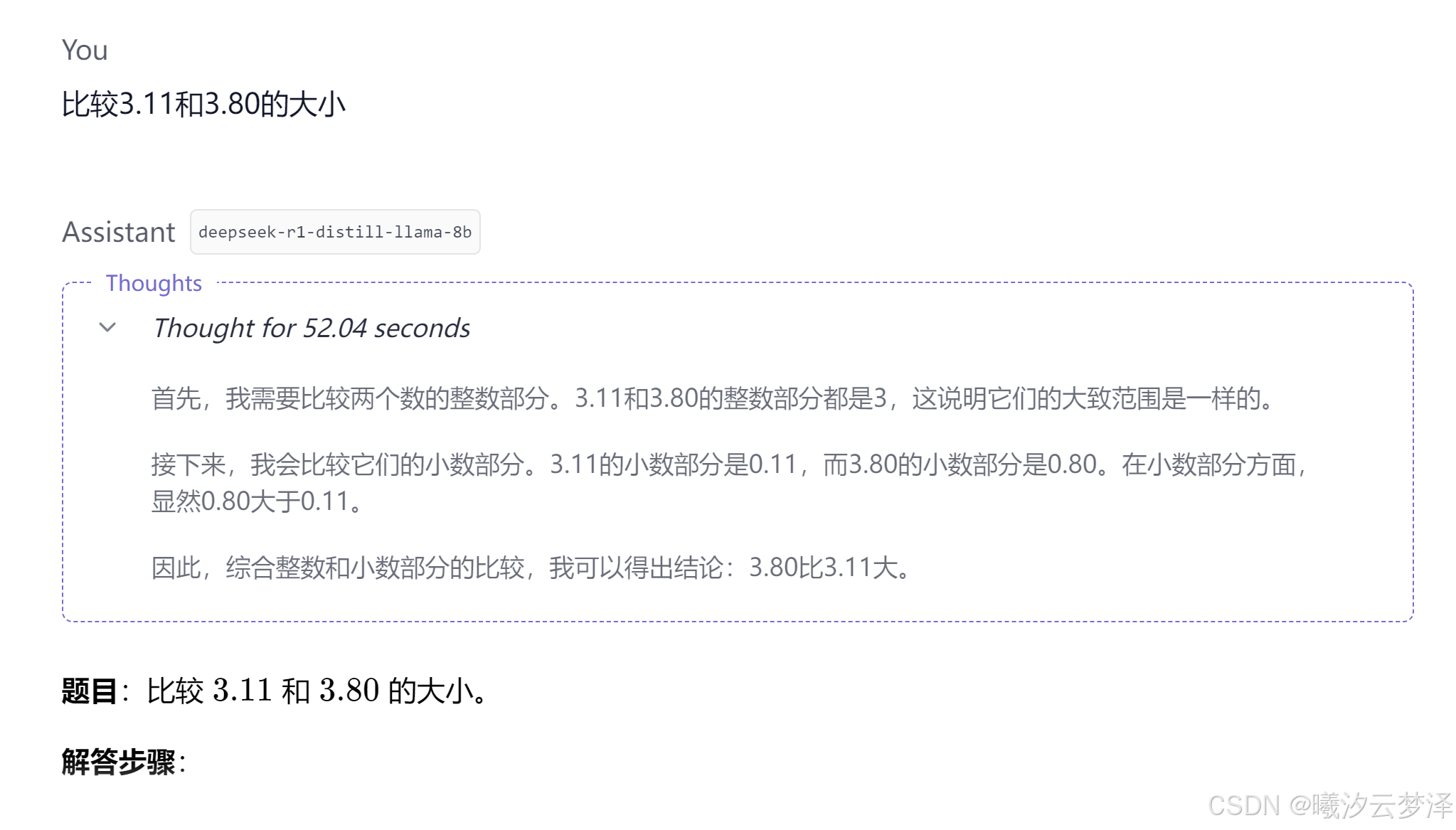
可以看到,两个模型对于同一问题处理速度有较为明显的差距(框框内的 seconds 为深度思考用时),建议下载不同的模型都进行一下测试,选择较优的模型使用。
4. 总结
- DeepSeek官方使用: 推理速度快,可联网,推理的结果优质。在较多用户的情况下,会出现服务器繁忙。
- API 调用: 能够正常使用,在平常的时候很少出现无法推理的情况,缺点是无法联网,与官方推理出的结果有差距,有Token限制
- 本地部署: 能够正常使用,取决于配置,解决了无法使用的情况但是一般用户推理速度会很慢。
建议: 在官网能用的情况下用官网,然后再尝试使用API 调用 和 本地部署
tips: 前面一篇文章记录了 云平台API 调用的过程,有需要的小伙伴可以去看一下。
快速调用DeepSeek API: 硅基流动 X 华为云 X ChatBox(2025/2/5)
也整合了一下做成了一个PDF文件:

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 49
49 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)